How to Teach AI to Hesitate: Inference-Time Compute and the Art of Considered Translation
Last Updated


Jump to section
Jump to section
Share
Share
Share

AI Video Translator, Localization, and Dubbing Tool
Try it out for Free
How to Teach AI to Hesitate
A few days ago, I came across a YouTube clip. A news anchor Sohn Suk-hee was interviewing the novelist Kim Ae-ran. The question was "What does a human have that AI does not?", and her answer was "Hesitation."
The novelist brought up a moment from one of the anchor's old broadcasts. While delivering the news of the death of the late Roh Hoe-chan, a labor activist turned politician, he lost words for twenty seconds. The moment of holding back words, wavering, and discerning—hesitation. AI is incapable of this. Yet, a person's hesitation becomes consolation and courtesy.
It was about twenty years ago, back when I was focusing on developing a shooting game. A teammate in 3D character modeling handed me a book saying "A high school friend of mine is a novelist; you should read this." Deep observations laced with wit. I was completely absorbed. The book was Kim Ae-ran's short story collection Run, Daddy, Run (달려라 아비). I have been a fan of hers ever since.
Hesitation Requires Time and Lower Certainty
Kim Ae-ran said her writing muscles strengthened through painstaking care and self-questioning over every single line. She said the time spent between sentences becomes consideration for the others. She also suggested that the true value of literature does not lie in content but in its form. Then, if form matters too, perhaps AI can imitate it at least roughly?
From a physics viewpoint, time is a change in the physical state. In physics, time hasn't passed if the state hasn't changed. Thus, less change in state equals slower time and more change equals longer time. A fleeting second to a human is to AI, an eternity stretched across hundreds of billions, even trillions, of floating-point operations (FLOPs). Compared to the past software, recent AI answers are the product of long, agonized hard work. This is also why the AI industry can grow in revenue while struggling in profit. In the viewpoint of legacy software, AI is far too slow for a machine. Even something as simple as JSON-format validation, when run through large-language-model inference, costs hundreds of millions of computation compared to the legacy software.
Large language models (LLMs), the engine of AI's recent progress, are programs that predict the next word in a sentence. AI runs electric current to find the next word. It repeatedly multiplies and adds enormous matrices. AI's computation requires physical consumption of hardware. To load AI with at least a form of hesitation, human's time of agony, you put it through intense computation. Hundreds of billions of operations to produce a single next word. Another hundreds of billions of operations follow to produce the word after that.
The majority of contemporary deep-learning computations involve weighted sums, and the pre-calculated values used in these sums are known as parameters.
When we talk about the 'Qwen 3.6 27B' model, it means there are 27 billion parameters ready for weight summation, requiring about 27 billion multiplications to predict just a single next token. And that's only the beginning. Furthermore, a single integer multiplication involves dozens of logical operations and a floating-point requires thousands. Given such complexity, one may call it mind-boggling.
Lowering the Temperature Sharpens the Bias
Let's look deeper at how LLMs work. It has become common knowledge that deep learning, the foundation of LLMs, is a pattern matching machine that applies memorized patterns during training to real-world use. Two things govern that process of regurgitation: token sampling and temperature.
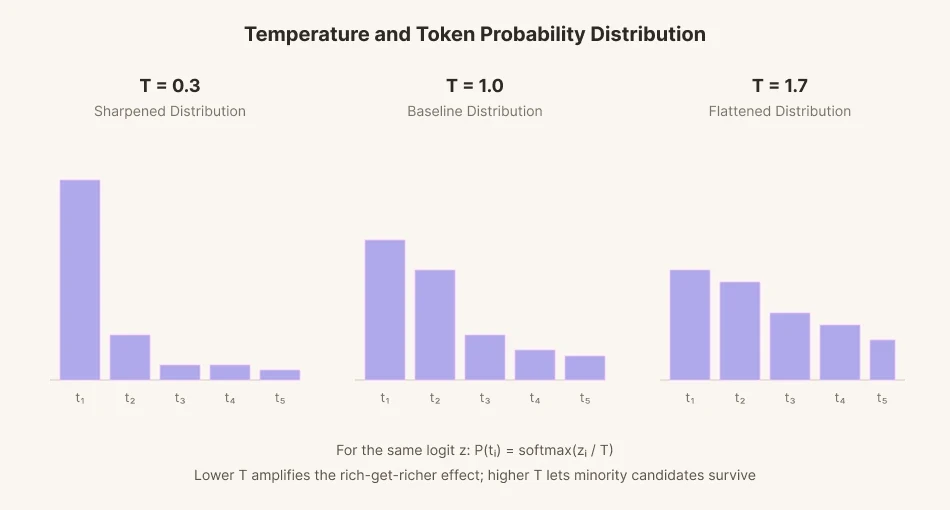
To predict a single next word, the model assigns a score (logit) to each of tens of thousands of candidate words. Those scores are then converted into probabilities, and a word is selected in proportion to each probability. This process is called sampling.
To add variation to sampling, a mathematical parameter called 'temperature' was introduced. Lower the temperature and the gap between candidate scores stretches out to extremes. Words with high probability get chosen more often than words at the baseline. Words with low probability get chosen even less. It's similar to how the rich get richer and the poor get poorer. Conversely, the gap narrows down when the temperature rises. The gap flattens, and evens out. Low-probability words that would normally have been passed over, can be selected at a higher rate when temperature rises.
The human language is similar to this. The group and culture I belong to are reflected in my language's probability distribution. Colder, sharper language produces speech that is more rational, more optimized, and more in line with the majority. Warmer, rounder language is less rational and less optimized, but takes the minority into account.
Consideration is the act of spending extra energy to step out of the probability distribution of one's own thoughts. It means noticing what the majority obscures, and finding sentences not normally used. What the writer described as a painstaking process of writing, for AI, should become an act of refusing responses based solely on biased training, and putting effort into traveling beyond.
Mechanical Fretting
How could we teach AI to be considerate? You can't let it spit out the highest-probability word straight away. That just exports the biases inherent in the training data.
The reason today's AI models achieve such striking results is that the field has advanced technology focusing on 'Inference-Time Compute'. It is a technology of giving AI more computation time before it answers. Past AI models simply output the first answer computed, in other words answer that first come to mind. By contrast, today's thinking models generate multiple paths of reasoning.
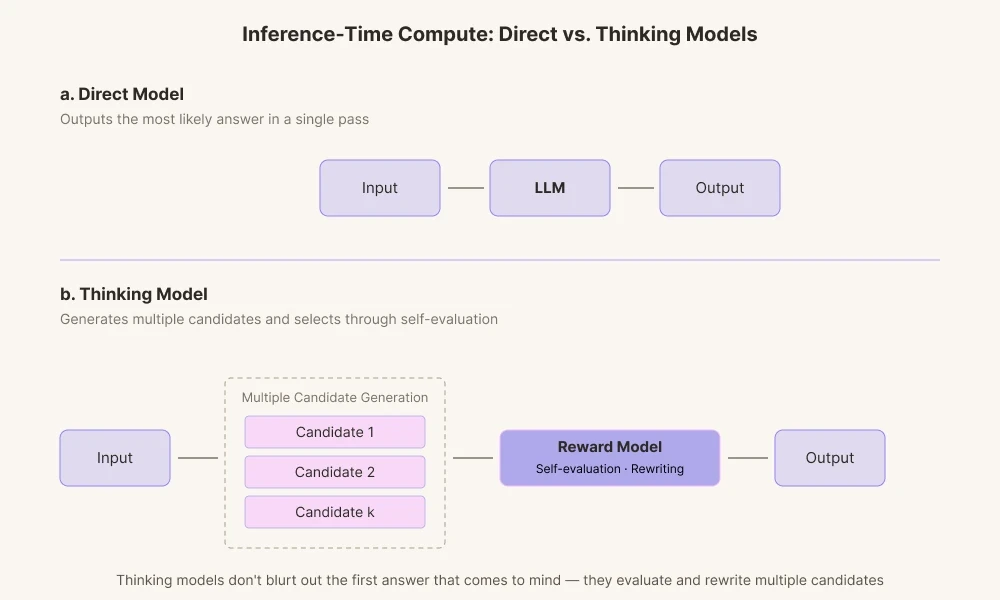
They produce various candidate answers and grade them through their intrinsic reward model. It runs through the process of checking whether the words fit the context and whether they come across as too definitive for it, then discards them internally if needed.
This is similar to how humans revise sentences in mind before speaking. Instead of demanding AI to deliver an answer as accurate as possible based on probability distributions, compute resources are spent to give it time to revise. We let it wander out from the center of the probability mass to the edges: a mechanical kind of fretting.
Fretting in Video Translation
Ordinary translation is finished once the meaning is fit, but video translation requires not only accurate meaning, but also the length and the timing of the lip movements have to match.
If an actor on screen moves their mouth for 1.8 seconds and delivers 11 English syllables, the translator has to build a Korean line that fits inside those 1.8 seconds. Preserve the meaning and the length breaks. Match the length and the meaning blurs. When the closing consonants and open vowels are different from the original, the viewer feels something off the moment they see it. Subtitles bring another constraint: 12 to 15 characters per second of reading speed. So a translator working with dubbing lays out five lines of equivalent meaning, counts syllables, matches stresses, and chooses not the most accurate translation but the one that loses the least within the constraints.
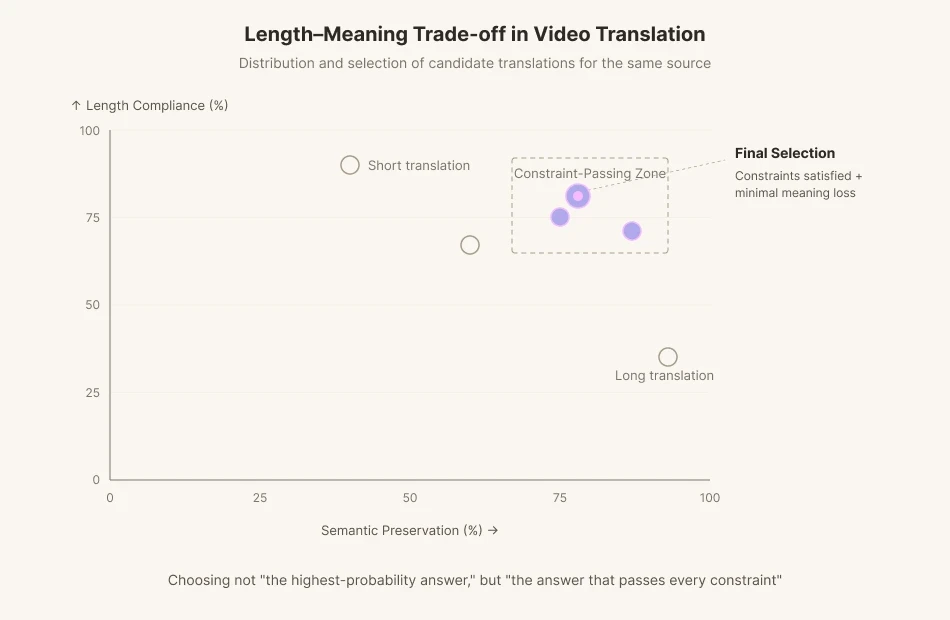
Perso Dubbing's translation team has been working on exactly this problem. The team published a paper at EMNLP (https://aclanthology.org/2025.emnlp-demos.37) that quantifies the trade-off between Isochrony (length compliance) and Semantic Alignment in video translation.
EMNLP (Empirical Methods in Natural Language Processing) is a top-tier venue in natural language processing. True to its name, it values empirical research that proves a technology's real-world effectiveness through data and experiments, rather than purely theoretical hypotheses. Fitting that character, the ESTsoft research team's paper takes a hard problem in video translation, quantifies it with data, and solves it with an algorithm. A practical, real-world contribution.
The key question that Perso Dubbing dubbing pipeline takes into account lies here. Not characters, not syllables, but the phoneme which is the smallest unit of speech. Characters and syllables are units on the screen; phonemes correspond to the time actually spent in the mouth. The algorithm proposed in the paper, CountPhonemes, counts the phoneme count of the translated sentence, compares it to the target phoneme count, and revises the sentence to bring the two into alignment.
Existing machine-translation models are optimized for meaning-preservation metrics like BLEU and COMET. They are trained to deliver the most plausible translation, as fast as possible. But video translation sometimes has to reject the most plausible one. When phonemes fall short, you have to give up some meaning and find another phrasing. We are asking AI not for "the highest-probability answer" but for "the answer that passes every constraint."
This is exactly what Perso Dubbing's dubbing pipeline solves. At the translation step, the system generates many candidates that satisfy length and phoneme constraints, then picks the one with the least semantic loss. It is the inference-time compute idea from the previous section, transposed into the dubbing domain. Stop the model from blurting out the first answer that comes to mind. Make it rewrite. Make it verify. This iterative translation is a deliberate hesitation imposed on the machine. Inside an iterative feedback loop, the model chases the optimum between length compliance (Isochrony) and meaning alignment (Semantic Alignment). It is the work of transplanting the video translator's agonizing into the model itself.
In Closing
Hesitation is not mere imperfection, not mere slowdown. It is the accumulation of time spent considering others. If AI ever learns to pause for the sake of consideration, it will not be because the model got smarter. It will be because we designed it to be less certain, to linger longer, to hesitate.
How to Teach AI to Hesitate
A few days ago, I came across a YouTube clip. A news anchor Sohn Suk-hee was interviewing the novelist Kim Ae-ran. The question was "What does a human have that AI does not?", and her answer was "Hesitation."
The novelist brought up a moment from one of the anchor's old broadcasts. While delivering the news of the death of the late Roh Hoe-chan, a labor activist turned politician, he lost words for twenty seconds. The moment of holding back words, wavering, and discerning—hesitation. AI is incapable of this. Yet, a person's hesitation becomes consolation and courtesy.
It was about twenty years ago, back when I was focusing on developing a shooting game. A teammate in 3D character modeling handed me a book saying "A high school friend of mine is a novelist; you should read this." Deep observations laced with wit. I was completely absorbed. The book was Kim Ae-ran's short story collection Run, Daddy, Run (달려라 아비). I have been a fan of hers ever since.
Hesitation Requires Time and Lower Certainty
Kim Ae-ran said her writing muscles strengthened through painstaking care and self-questioning over every single line. She said the time spent between sentences becomes consideration for the others. She also suggested that the true value of literature does not lie in content but in its form. Then, if form matters too, perhaps AI can imitate it at least roughly?
From a physics viewpoint, time is a change in the physical state. In physics, time hasn't passed if the state hasn't changed. Thus, less change in state equals slower time and more change equals longer time. A fleeting second to a human is to AI, an eternity stretched across hundreds of billions, even trillions, of floating-point operations (FLOPs). Compared to the past software, recent AI answers are the product of long, agonized hard work. This is also why the AI industry can grow in revenue while struggling in profit. In the viewpoint of legacy software, AI is far too slow for a machine. Even something as simple as JSON-format validation, when run through large-language-model inference, costs hundreds of millions of computation compared to the legacy software.
Large language models (LLMs), the engine of AI's recent progress, are programs that predict the next word in a sentence. AI runs electric current to find the next word. It repeatedly multiplies and adds enormous matrices. AI's computation requires physical consumption of hardware. To load AI with at least a form of hesitation, human's time of agony, you put it through intense computation. Hundreds of billions of operations to produce a single next word. Another hundreds of billions of operations follow to produce the word after that.
The majority of contemporary deep-learning computations involve weighted sums, and the pre-calculated values used in these sums are known as parameters.
When we talk about the 'Qwen 3.6 27B' model, it means there are 27 billion parameters ready for weight summation, requiring about 27 billion multiplications to predict just a single next token. And that's only the beginning. Furthermore, a single integer multiplication involves dozens of logical operations and a floating-point requires thousands. Given such complexity, one may call it mind-boggling.
Lowering the Temperature Sharpens the Bias
Let's look deeper at how LLMs work. It has become common knowledge that deep learning, the foundation of LLMs, is a pattern matching machine that applies memorized patterns during training to real-world use. Two things govern that process of regurgitation: token sampling and temperature.
To predict a single next word, the model assigns a score (logit) to each of tens of thousands of candidate words. Those scores are then converted into probabilities, and a word is selected in proportion to each probability. This process is called sampling.
To add variation to sampling, a mathematical parameter called 'temperature' was introduced. Lower the temperature and the gap between candidate scores stretches out to extremes. Words with high probability get chosen more often than words at the baseline. Words with low probability get chosen even less. It's similar to how the rich get richer and the poor get poorer. Conversely, the gap narrows down when the temperature rises. The gap flattens, and evens out. Low-probability words that would normally have been passed over, can be selected at a higher rate when temperature rises.
The human language is similar to this. The group and culture I belong to are reflected in my language's probability distribution. Colder, sharper language produces speech that is more rational, more optimized, and more in line with the majority. Warmer, rounder language is less rational and less optimized, but takes the minority into account.
Consideration is the act of spending extra energy to step out of the probability distribution of one's own thoughts. It means noticing what the majority obscures, and finding sentences not normally used. What the writer described as a painstaking process of writing, for AI, should become an act of refusing responses based solely on biased training, and putting effort into traveling beyond.
Mechanical Fretting
How could we teach AI to be considerate? You can't let it spit out the highest-probability word straight away. That just exports the biases inherent in the training data.
The reason today's AI models achieve such striking results is that the field has advanced technology focusing on 'Inference-Time Compute'. It is a technology of giving AI more computation time before it answers. Past AI models simply output the first answer computed, in other words answer that first come to mind. By contrast, today's thinking models generate multiple paths of reasoning.
They produce various candidate answers and grade them through their intrinsic reward model. It runs through the process of checking whether the words fit the context and whether they come across as too definitive for it, then discards them internally if needed.
This is similar to how humans revise sentences in mind before speaking. Instead of demanding AI to deliver an answer as accurate as possible based on probability distributions, compute resources are spent to give it time to revise. We let it wander out from the center of the probability mass to the edges: a mechanical kind of fretting.
Fretting in Video Translation
Ordinary translation is finished once the meaning is fit, but video translation requires not only accurate meaning, but also the length and the timing of the lip movements have to match.
If an actor on screen moves their mouth for 1.8 seconds and delivers 11 English syllables, the translator has to build a Korean line that fits inside those 1.8 seconds. Preserve the meaning and the length breaks. Match the length and the meaning blurs. When the closing consonants and open vowels are different from the original, the viewer feels something off the moment they see it. Subtitles bring another constraint: 12 to 15 characters per second of reading speed. So a translator working with dubbing lays out five lines of equivalent meaning, counts syllables, matches stresses, and chooses not the most accurate translation but the one that loses the least within the constraints.
Perso Dubbing's translation team has been working on exactly this problem. The team published a paper at EMNLP (https://aclanthology.org/2025.emnlp-demos.37) that quantifies the trade-off between Isochrony (length compliance) and Semantic Alignment in video translation.
EMNLP (Empirical Methods in Natural Language Processing) is a top-tier venue in natural language processing. True to its name, it values empirical research that proves a technology's real-world effectiveness through data and experiments, rather than purely theoretical hypotheses. Fitting that character, the ESTsoft research team's paper takes a hard problem in video translation, quantifies it with data, and solves it with an algorithm. A practical, real-world contribution.
The key question that Perso Dubbing dubbing pipeline takes into account lies here. Not characters, not syllables, but the phoneme which is the smallest unit of speech. Characters and syllables are units on the screen; phonemes correspond to the time actually spent in the mouth. The algorithm proposed in the paper, CountPhonemes, counts the phoneme count of the translated sentence, compares it to the target phoneme count, and revises the sentence to bring the two into alignment.
Existing machine-translation models are optimized for meaning-preservation metrics like BLEU and COMET. They are trained to deliver the most plausible translation, as fast as possible. But video translation sometimes has to reject the most plausible one. When phonemes fall short, you have to give up some meaning and find another phrasing. We are asking AI not for "the highest-probability answer" but for "the answer that passes every constraint."
This is exactly what Perso Dubbing's dubbing pipeline solves. At the translation step, the system generates many candidates that satisfy length and phoneme constraints, then picks the one with the least semantic loss. It is the inference-time compute idea from the previous section, transposed into the dubbing domain. Stop the model from blurting out the first answer that comes to mind. Make it rewrite. Make it verify. This iterative translation is a deliberate hesitation imposed on the machine. Inside an iterative feedback loop, the model chases the optimum between length compliance (Isochrony) and meaning alignment (Semantic Alignment). It is the work of transplanting the video translator's agonizing into the model itself.
In Closing
Hesitation is not mere imperfection, not mere slowdown. It is the accumulation of time spent considering others. If AI ever learns to pause for the sake of consideration, it will not be because the model got smarter. It will be because we designed it to be less certain, to linger longer, to hesitate.
Continue Reading
Browse All




