Cara Mengajari AI untuk Ragu: Komputasi Saat Inferensi dan Seni Penerjemahan yang Dipertimbangkan


Lompat ke bagian
Lompat ke bagian
Bagikan
Bagikan
Bagikan

Alat Penerjemah Video AI, Lokalisasi, dan Dubbing
Coba secara Gratis
Cara Mengajari AI untuk Ragu-ragu
Beberapa hari yang lalu, saya menemukan sebuah klip YouTube. Seorang pembawa berita Sohn Suk-hee sedang mewawancarai novelis Kim Ae-ran. Pertanyaannya adalah "Apa yang dimiliki manusia yang tidak dimiliki AI?", dan jawabannya adalah "Keraguan."
Novelis tersebut mengungkit sebuah momen dari salah satu siaran lama sang pembawa berita. Saat menyampaikan berita kematian mendiang Roh Hoe-chan, seorang aktivis buruh yang beralih menjadi politisi, ia kehilangan kata-kata selama dua puluh detik. Momen menahan kata-kata, bimbang, dan membedakan—keraguan. AI tidak mampu melakukan ini. Namun, keraguan seseorang pun menjadi penghiburan dan kesopanan.
Itu terjadi sekitar dua puluh tahun yang lalu, saat saya sedang fokus mengembangkan game menembak. Seorang rekan tim dalam pemodelan karakter 3D menyerahkan sebuah buku kepada saya dan berkata, "Teman SMA saya adalah seorang novelis; kamu harus membaca ini." Pengamatan mendalam yang dibalut dengan humor. Saya benar-benar terhanyut. Buku itu adalah kumpulan cerita pendek karya Kim Ae-ran yang berjudul Run, Daddy, Run (달려라 아비). Sejak saat itu saya menjadi penggemarnya.
Keraguan Membutuhkan Waktu dan Kepastian yang Lebih Rendah
Kim Ae-ran mengatakan otot-otot menulisnya menguat melalui ketelitian yang melelahkan dan pertanyaan mandiri pada setiap baris tulisan. Ia mengatakan waktu yang dihabiskan di antara kalimat-kalimat menjadi wujud kepedulian terhadap sesama. Ia juga menyarankan bahwa nilai sejati sastra tidak terletak pada isi melainkan pada bentuknya. Lalu, jika bentuk juga penting, mungkinkah AI dapat menirunya setidaknya secara kasar?
Dari sudut pandang fisika, waktu adalah perubahan dalam keadaan fisik. Dalam fisika, waktu belum berlalu jika keadaannya belum berubah. Dengan demikian, perubahan keadaan yang lebih sedikit berarti waktu yang lebih lambat dan perubahan yang lebih banyak berarti waktu yang lebih lama. Detik yang berlalu begitu cepat bagi manusia adalah keabadian bagi AI yang membentang di ratusan miliar, bahkan triliunan, operasi titik mengambang (FLOPs). Dibandingkan dengan perangkat lunak terdahulu, jawaban AI baru-baru ini adalah produk dari kerja keras yang panjang dan penuh perjuangan. Ini juga menjadi alasan mengapa industri AI dapat tumbuh dalam pendapatan sementara berjuang dalam keuntungan. Dalam sudut pandang perangkat lunak lama, AI jauh terlalu lambat untuk sebuah mesin. Bahkan sesuatu yang sederhana seperti validasi format JSON, ketika dijalankan melalui inferensi model bahasa besar, menelan biaya ratusan juta komputasi dibandingkan dengan perangkat lunak lama.
Model bahasa besar (LLM), motor penggerak kemajuan AI baru-baru ini, adalah program yang memprediksi kata berikutnya dalam sebuah kalimat. AI menjalankan arus listrik untuk menemukan kata berikutnya. AI berulang kali mengalikan dan menjumlahkan matriks yang sangat besar. Komputasi AI membutuhkan konsumsi fisik dari perangkat keras. Untuk membekali AI dengan setidaknya bentuk keraguan, waktu pergulatan manusia, Anda harus melewatinya melalui komputasi yang intens. Ratusan miliar operasi untuk menghasilkan satu kata berikutnya. Ratusan miliar operasi lainnya menyusul untuk menghasilkan kata setelah itu.
Sebagian besar komputasi pembelajaran mendalam kontemporer melibatkan penjumlahan berbobot, dan nilai-nilai pra-perhitungan yang digunakan dalam penjumlahan ini dikenal sebagai parameter.
Ketika kita berbicara tentang model 'Qwen 3.6 27B', itu berarti ada 27 miliar parameter yang siap untuk penjumlahan bobot, membutuhkan sekitar 27 miliar perkalian untuk memprediksi satu token berikutnya saja. Dan itu baru permulaan. Terlebih lagi, satu perkalian bilangan bulat melibatkan puluhan operasi logika dan titik mengambang membutuhkan ribuan. Mengingat kerumitan seperti itu, orang mungkin menyebutnya sangat mencengangkan.
Menurunkan Suhu Memperjelas Bias
Mari kita lihat lebih dalam bagaimana cara kerja LLM. Sudah menjadi pengetahuan umum bahwa pembelajaran mendalam, fondasi dari LLM, adalah mesin pencocokan pola yang menerapkan pola yang dihafal selama pelatihan ke penggunaan di dunia nyata. Dua hal yang mengatur proses regurgitasi itu adalah: pengambilan sampel token (token sampling) dan suhu (temperature).
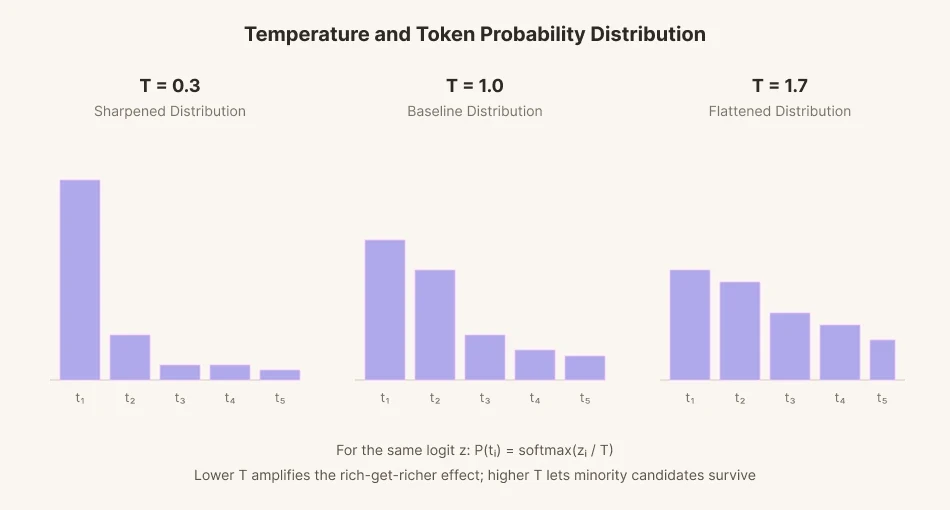
Untuk memprediksi satu kata berikutnya, model memberikan skor (logit) ke masing-masing dari puluhan ribu kandidat kata. Skor tersebut kemudian diubah menjadi probabilitas, dan sebuah kata dipilih secara proporsional dengan masing-masing probabilitas. Proses ini disebut pengambilan sampel (sampling).
Untuk menambahkan variasi pada pengambilan sampel, sebuah parameter matematika yang disebut 'suhu' diperkenalkan. Turunkan suhu dan kesenjangan antara skor kandidat membentang ke titik ekstrem. Kata-kata dengan probabilitas tinggi terpilih lebih sering daripada kata-kata di garis dasar. Kata-kata dengan probabilitas rendah bahkan semakin jarang terpilih. Ini mirip dengan bagaimana yang kaya semakin kaya dan yang miskin semakin miskin. Sebaliknya, kesenjangan menyempit ketika suhu meningkat. Kesenjangan tersebut merosot, dan menjadi rata. Kata-kata dengan probabilitas rendah yang biasanya akan dilewati, dapat dipilih pada tingkat yang lebih tinggi ketika suhu naik.
Bahasa manusia mirip dengan ini. Kelompok dan budaya tempat saya bernaung tercermin dalam distribusi probabilitas bahasa saya. Bahasa yang lebih dingin dan tajam menghasilkan ucapan yang lebih rasional, lebih optimal, dan lebih sejalan dengan mayoritas. Bahasa yang lebih hangat dan bulat kurang rasional dan kurang optimal, tetapi mempertimbangkan kaum minoritas.
Pertimbangan adalah tindakan menghabiskan energi ekstra untuk keluar dari distribusi probabilitas pikiran sendiri. Ini berarti memperhatikan apa yang dikaburkan oleh mayoritas, dan menemukan kalimat yang biasanya tidak digunakan. Apa yang digambarkan penulis sebagai proses penulisan yang melelahkan, bagi AI, harus menjadi tindakan menolak tanggapan yang semata-mata didasarkan pada pelatihan yang bias, dan mengerahkan upaya untuk melangkah melampauinya.
Kecemasan Mekanis
Bagaimana kita bisa mengajari AI untuk penuh pertimbangan? Anda tidak bisa membiarkannya langsung mengeluarkan kata dengan probabilitas tertinggi. Itu hanya akan mengekspor bias yang melekat dalam data pelatihan.
Alasan mengapa model AI saat ini mencapai hasil yang sangat mencolok adalah karena bidang ini telah memajukan teknologi yang berfokus pada 'Inference-Time Compute'. Ini adalah teknologi untuk memberikan AI lebih banyak waktu komputasi sebelum ia menjawab. Model AI di masa lalu hanya mengeluarkan jawaban pertama yang dihitung, dengan kata lain jawaban yang pertama kali terlintas di pikiran. Sebaliknya, model penalaran saat ini menghasilkan beberapa jalur penalaran.
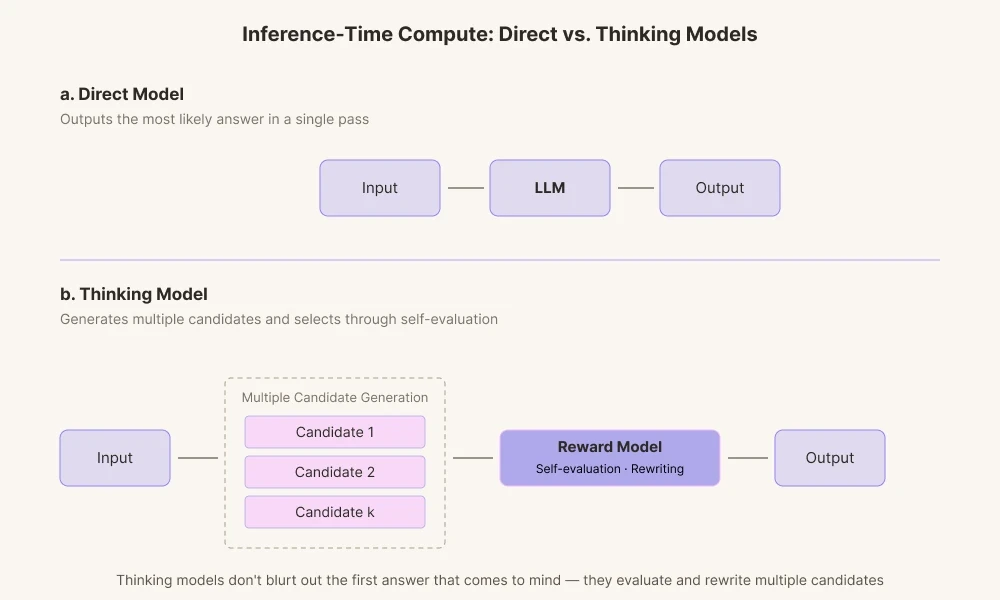
Mereka menghasilkan berbagai kandidat jawaban dan menilainya melalui model penghargaan intrinsik mereka. Proses tersebut berjalan melalui pemeriksaan apakah kata-kata tersebut sesuai dengan konteks dan apakah kata-kata itu terkesan terlalu definitif untuknya, lalu membuangnya secara internal jika diperlukan.
Ini mirip dengan bagaimana manusia merevisi kalimat dalam pikiran sebelum berbicara. Alih-alih menuntut AI untuk memberikan jawaban seakurat mungkin berdasarkan distribusi probabilitas, sumber daya komputasi dihabiskan untuk memberinya waktu untuk merevisi. Kita membiarkannya mengembara dari pusat massa probabilitas ke tepian: sejenis kecemasan mekanis.
Kecemasan dalam Penerjemahan Video
Penerjemahan biasa selesai setelah maknanya sesuai, tetapi penerjemahan video tidak hanya membutuhkan makna yang akurat, tetapi juga panjang dan waktu gerakan bibir harus cocok.
Jika seorang aktor di layar menggerakkan mulut mereka selama 1,8 detik dan mengucapkan 11 suku kata bahasa Inggris, penerjemah harus membuat dialog bahasa Korea yang pas di dalam 1,8 detik tersebut. Pertahankan maknanya, maka panjangnya akan rusak. Cocokkan panjangnya, maka maknanya akan kabur. Ketika konsonan penutup dan vokal terbuka berbeda dari aslinya, penonton merasakan ada sesuatu yang salah saat mereka melihatnya. Subtitel membawa batasan lain: kecepatan membaca 12 hingga 15 karakter per detik. Jadi seorang penerjemah yang bekerja dengan sulih suara menyusun lima baris dengan makna yang setara, menghitung suku kata, mencocokkan tekanan kata, dan memilih bukan terjemahan yang paling akurat tetapi terjemahan yang paling sedikit kehilangan maknanya di bawah batasan tersebut.
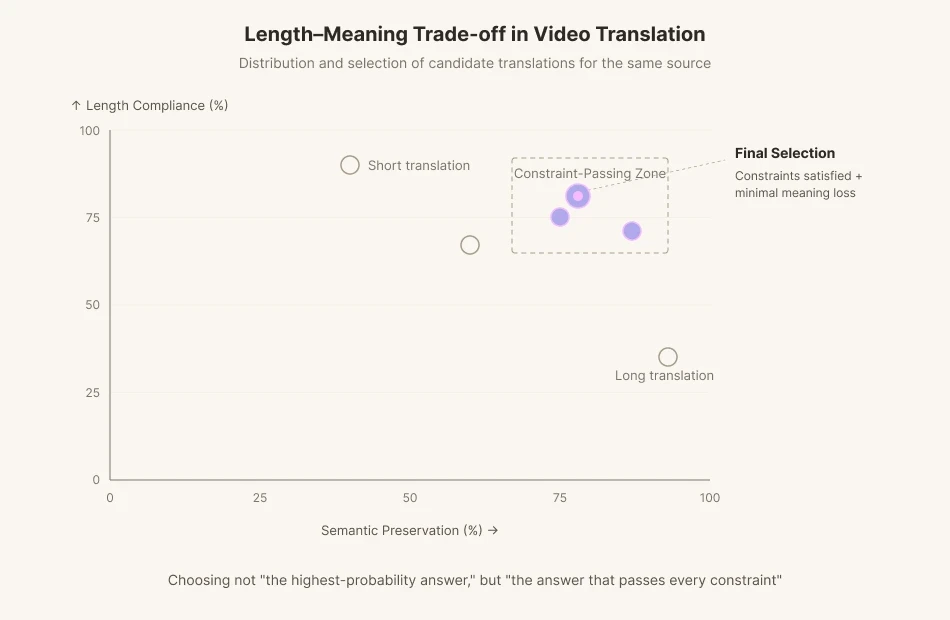
Tim penerjemahan Perso Dubbing telah berupaya mengatasi masalah ini. Tim tersebut menerbitkan sebuah makalah di EMNLP (https://aclanthology.org/2025.emnlp-demos.37) yang mengukur trade-off antara Isochrony (kepatuhan panjang) dan Penyelarasan Semantik dalam penerjemahan video.
EMNLP (Empirical Methods in Natural Language Processing) adalah wadah papan atas dalam pemrosesan bahasa alami. Sesuai dengan namanya, wadah ini menghargai penelitian empiris yang membuktikan keefektifan teknologi di dunia nyata melalui data dan eksperimen, bukan sekadar hipotesis teoritis murni. Sesuai dengan karakter tersebut, makalah tim peneliti ESTsoft mengambil masalah sulit dalam penerjemahan video, mengukurnya dengan data, dan menyelesaikannya dengan algoritma. Sebuah kontribusi yang praktis dan nyata di dunia nyata.
Pertanyaan kunci yang dipertimbangkan oleh alur kerja sulih suara Perso Dubbing terletak di sini. Bukan karakter, bukan suku kata, melainkan fonem yang merupakan unit terkecil dari ucapan. Karakter dan suku kata adalah unit di layar; fonem sesuai dengan waktu yang sebenarnya dihabiskan di dalam mulut. Algoritma yang diusulkan dalam makalah tersebut, CountPhonemes, menghitung jumlah fonem dari kalimat yang diterjemahkan, membandingkannya dengan jumlah fonem target, dan merevisi kalimat tersebut untuk menyelaraskan keduanya.
Model penerjemahan mesin yang ada saat ini dioptimalkan untuk metrik pelestarian makna seperti BLEU dan COMET. Mereka dilatih untuk memberikan terjemahan yang paling masuk akal, secepat mungkin. Namun penerjemahan video terkadang harus menolak terjemahan yang paling masuk akal sekalipun. Ketika fonem tidak mencukupi, Anda harus mengorbankan sebagian makna dan mencari ungkapan lain. Kita meminta AI bukan untuk "jawaban dengan probabilitas tertinggi" melainkan untuk "jawaban yang lolos dari setiap batasan."
Cara Mengajari AI untuk Ragu-ragu
Beberapa hari yang lalu, saya menemukan sebuah klip YouTube. Seorang pembawa berita Sohn Suk-hee sedang mewawancarai novelis Kim Ae-ran. Pertanyaannya adalah "Apa yang dimiliki manusia yang tidak dimiliki AI?", dan jawabannya adalah "Keraguan."
Novelis tersebut mengungkit sebuah momen dari salah satu siaran lama sang pembawa berita. Saat menyampaikan berita kematian mendiang Roh Hoe-chan, seorang aktivis buruh yang beralih menjadi politisi, ia kehilangan kata-kata selama dua puluh detik. Momen menahan kata-kata, bimbang, dan membedakan—keraguan. AI tidak mampu melakukan ini. Namun, keraguan seseorang pun menjadi penghiburan dan kesopanan.
Itu terjadi sekitar dua puluh tahun yang lalu, saat saya sedang fokus mengembangkan game menembak. Seorang rekan tim dalam pemodelan karakter 3D menyerahkan sebuah buku kepada saya dan berkata, "Teman SMA saya adalah seorang novelis; kamu harus membaca ini." Pengamatan mendalam yang dibalut dengan humor. Saya benar-benar terhanyut. Buku itu adalah kumpulan cerita pendek karya Kim Ae-ran yang berjudul Run, Daddy, Run (달려라 아비). Sejak saat itu saya menjadi penggemarnya.
Keraguan Membutuhkan Waktu dan Kepastian yang Lebih Rendah
Kim Ae-ran mengatakan otot-otot menulisnya menguat melalui ketelitian yang melelahkan dan pertanyaan mandiri pada setiap baris tulisan. Ia mengatakan waktu yang dihabiskan di antara kalimat-kalimat menjadi wujud kepedulian terhadap sesama. Ia juga menyarankan bahwa nilai sejati sastra tidak terletak pada isi melainkan pada bentuknya. Lalu, jika bentuk juga penting, mungkinkah AI dapat menirunya setidaknya secara kasar?
Dari sudut pandang fisika, waktu adalah perubahan dalam keadaan fisik. Dalam fisika, waktu belum berlalu jika keadaannya belum berubah. Dengan demikian, perubahan keadaan yang lebih sedikit berarti waktu yang lebih lambat dan perubahan yang lebih banyak berarti waktu yang lebih lama. Detik yang berlalu begitu cepat bagi manusia adalah keabadian bagi AI yang membentang di ratusan miliar, bahkan triliunan, operasi titik mengambang (FLOPs). Dibandingkan dengan perangkat lunak terdahulu, jawaban AI baru-baru ini adalah produk dari kerja keras yang panjang dan penuh perjuangan. Ini juga menjadi alasan mengapa industri AI dapat tumbuh dalam pendapatan sementara berjuang dalam keuntungan. Dalam sudut pandang perangkat lunak lama, AI jauh terlalu lambat untuk sebuah mesin. Bahkan sesuatu yang sederhana seperti validasi format JSON, ketika dijalankan melalui inferensi model bahasa besar, menelan biaya ratusan juta komputasi dibandingkan dengan perangkat lunak lama.
Model bahasa besar (LLM), motor penggerak kemajuan AI baru-baru ini, adalah program yang memprediksi kata berikutnya dalam sebuah kalimat. AI menjalankan arus listrik untuk menemukan kata berikutnya. AI berulang kali mengalikan dan menjumlahkan matriks yang sangat besar. Komputasi AI membutuhkan konsumsi fisik dari perangkat keras. Untuk membekali AI dengan setidaknya bentuk keraguan, waktu pergulatan manusia, Anda harus melewatinya melalui komputasi yang intens. Ratusan miliar operasi untuk menghasilkan satu kata berikutnya. Ratusan miliar operasi lainnya menyusul untuk menghasilkan kata setelah itu.
Sebagian besar komputasi pembelajaran mendalam kontemporer melibatkan penjumlahan berbobot, dan nilai-nilai pra-perhitungan yang digunakan dalam penjumlahan ini dikenal sebagai parameter.
Ketika kita berbicara tentang model 'Qwen 3.6 27B', itu berarti ada 27 miliar parameter yang siap untuk penjumlahan bobot, membutuhkan sekitar 27 miliar perkalian untuk memprediksi satu token berikutnya saja. Dan itu baru permulaan. Terlebih lagi, satu perkalian bilangan bulat melibatkan puluhan operasi logika dan titik mengambang membutuhkan ribuan. Mengingat kerumitan seperti itu, orang mungkin menyebutnya sangat mencengangkan.
Menurunkan Suhu Memperjelas Bias
Mari kita lihat lebih dalam bagaimana cara kerja LLM. Sudah menjadi pengetahuan umum bahwa pembelajaran mendalam, fondasi dari LLM, adalah mesin pencocokan pola yang menerapkan pola yang dihafal selama pelatihan ke penggunaan di dunia nyata. Dua hal yang mengatur proses regurgitasi itu adalah: pengambilan sampel token (token sampling) dan suhu (temperature).
Untuk memprediksi satu kata berikutnya, model memberikan skor (logit) ke masing-masing dari puluhan ribu kandidat kata. Skor tersebut kemudian diubah menjadi probabilitas, dan sebuah kata dipilih secara proporsional dengan masing-masing probabilitas. Proses ini disebut pengambilan sampel (sampling).
Untuk menambahkan variasi pada pengambilan sampel, sebuah parameter matematika yang disebut 'suhu' diperkenalkan. Turunkan suhu dan kesenjangan antara skor kandidat membentang ke titik ekstrem. Kata-kata dengan probabilitas tinggi terpilih lebih sering daripada kata-kata di garis dasar. Kata-kata dengan probabilitas rendah bahkan semakin jarang terpilih. Ini mirip dengan bagaimana yang kaya semakin kaya dan yang miskin semakin miskin. Sebaliknya, kesenjangan menyempit ketika suhu meningkat. Kesenjangan tersebut merosot, dan menjadi rata. Kata-kata dengan probabilitas rendah yang biasanya akan dilewati, dapat dipilih pada tingkat yang lebih tinggi ketika suhu naik.
Bahasa manusia mirip dengan ini. Kelompok dan budaya tempat saya bernaung tercermin dalam distribusi probabilitas bahasa saya. Bahasa yang lebih dingin dan tajam menghasilkan ucapan yang lebih rasional, lebih optimal, dan lebih sejalan dengan mayoritas. Bahasa yang lebih hangat dan bulat kurang rasional dan kurang optimal, tetapi mempertimbangkan kaum minoritas.
Pertimbangan adalah tindakan menghabiskan energi ekstra untuk keluar dari distribusi probabilitas pikiran sendiri. Ini berarti memperhatikan apa yang dikaburkan oleh mayoritas, dan menemukan kalimat yang biasanya tidak digunakan. Apa yang digambarkan penulis sebagai proses penulisan yang melelahkan, bagi AI, harus menjadi tindakan menolak tanggapan yang semata-mata didasarkan pada pelatihan yang bias, dan mengerahkan upaya untuk melangkah melampauinya.
Kecemasan Mekanis
Bagaimana kita bisa mengajari AI untuk penuh pertimbangan? Anda tidak bisa membiarkannya langsung mengeluarkan kata dengan probabilitas tertinggi. Itu hanya akan mengekspor bias yang melekat dalam data pelatihan.
Alasan mengapa model AI saat ini mencapai hasil yang sangat mencolok adalah karena bidang ini telah memajukan teknologi yang berfokus pada 'Inference-Time Compute'. Ini adalah teknologi untuk memberikan AI lebih banyak waktu komputasi sebelum ia menjawab. Model AI di masa lalu hanya mengeluarkan jawaban pertama yang dihitung, dengan kata lain jawaban yang pertama kali terlintas di pikiran. Sebaliknya, model penalaran saat ini menghasilkan beberapa jalur penalaran.
Mereka menghasilkan berbagai kandidat jawaban dan menilainya melalui model penghargaan intrinsik mereka. Proses tersebut berjalan melalui pemeriksaan apakah kata-kata tersebut sesuai dengan konteks dan apakah kata-kata itu terkesan terlalu definitif untuknya, lalu membuangnya secara internal jika diperlukan.
Ini mirip dengan bagaimana manusia merevisi kalimat dalam pikiran sebelum berbicara. Alih-alih menuntut AI untuk memberikan jawaban seakurat mungkin berdasarkan distribusi probabilitas, sumber daya komputasi dihabiskan untuk memberinya waktu untuk merevisi. Kita membiarkannya mengembara dari pusat massa probabilitas ke tepian: sejenis kecemasan mekanis.
Kecemasan dalam Penerjemahan Video
Penerjemahan biasa selesai setelah maknanya sesuai, tetapi penerjemahan video tidak hanya membutuhkan makna yang akurat, tetapi juga panjang dan waktu gerakan bibir harus cocok.
Jika seorang aktor di layar menggerakkan mulut mereka selama 1,8 detik dan mengucapkan 11 suku kata bahasa Inggris, penerjemah harus membuat dialog bahasa Korea yang pas di dalam 1,8 detik tersebut. Pertahankan maknanya, maka panjangnya akan rusak. Cocokkan panjangnya, maka maknanya akan kabur. Ketika konsonan penutup dan vokal terbuka berbeda dari aslinya, penonton merasakan ada sesuatu yang salah saat mereka melihatnya. Subtitel membawa batasan lain: kecepatan membaca 12 hingga 15 karakter per detik. Jadi seorang penerjemah yang bekerja dengan sulih suara menyusun lima baris dengan makna yang setara, menghitung suku kata, mencocokkan tekanan kata, dan memilih bukan terjemahan yang paling akurat tetapi terjemahan yang paling sedikit kehilangan maknanya di bawah batasan tersebut.
Tim penerjemahan Perso Dubbing telah berupaya mengatasi masalah ini. Tim tersebut menerbitkan sebuah makalah di EMNLP (https://aclanthology.org/2025.emnlp-demos.37) yang mengukur trade-off antara Isochrony (kepatuhan panjang) dan Penyelarasan Semantik dalam penerjemahan video.
EMNLP (Empirical Methods in Natural Language Processing) adalah wadah papan atas dalam pemrosesan bahasa alami. Sesuai dengan namanya, wadah ini menghargai penelitian empiris yang membuktikan keefektifan teknologi di dunia nyata melalui data dan eksperimen, bukan sekadar hipotesis teoritis murni. Sesuai dengan karakter tersebut, makalah tim peneliti ESTsoft mengambil masalah sulit dalam penerjemahan video, mengukurnya dengan data, dan menyelesaikannya dengan algoritma. Sebuah kontribusi yang praktis dan nyata di dunia nyata.
Pertanyaan kunci yang dipertimbangkan oleh alur kerja sulih suara Perso Dubbing terletak di sini. Bukan karakter, bukan suku kata, melainkan fonem yang merupakan unit terkecil dari ucapan. Karakter dan suku kata adalah unit di layar; fonem sesuai dengan waktu yang sebenarnya dihabiskan di dalam mulut. Algoritma yang diusulkan dalam makalah tersebut, CountPhonemes, menghitung jumlah fonem dari kalimat yang diterjemahkan, membandingkannya dengan jumlah fonem target, dan merevisi kalimat tersebut untuk menyelaraskan keduanya.
Model penerjemahan mesin yang ada saat ini dioptimalkan untuk metrik pelestarian makna seperti BLEU dan COMET. Mereka dilatih untuk memberikan terjemahan yang paling masuk akal, secepat mungkin. Namun penerjemahan video terkadang harus menolak terjemahan yang paling masuk akal sekalipun. Ketika fonem tidak mencukupi, Anda harus mengorbankan sebagian makna dan mencari ungkapan lain. Kita meminta AI bukan untuk "jawaban dengan probabilitas tertinggi" melainkan untuk "jawaban yang lolos dari setiap batasan."
Lanjutkan Membaca
Jelajahi Semua




