จะสอนให้ AI ลังเลอย่างไร: การประมวลผลในช่วงอนุมานและศิลปะแห่งการแปลอย่างรอบคอบ



เครื่องมือแปลวิดีโอ AI การทำให้เข้าท้องถิ่น และการพากย์เสียง
ลองใช้งานฟรี
วิธีสอนให้ AI รู้จักลังเล
สองสามวันก่อน ฉันบังเอิญไปเจอคลิป YouTube คลิปหนึ่ง ผู้ประกาศข่าวคุณ Sohn Suk-hee กำลังสัมภาษณ์นักเขียนนวนิยายคุณ Kim Ae-ran คำถามคือ "มนุษย์มีอะไรที่ AI ไม่มี?" และคำตอบของเธอคือ "ความลังเล"
นักเขียนนวนิยายได้หยิบยกช่วงเวลาหนึ่งจากรายการออกอากาศเก่าของผู้ประกาศข่าวคนดังกล่าว ในขณะที่รายงานข่าวการเสียชีวิตของอดีต Roh Hoe-chan นักเคลื่อนไหวเพื่อแรงงานที่ผันตัวมาเป็นนักการเมือง เขาถึงกับพูดไม่ออกไปยี่สิบวินาที ช่วงเวลาของการระงับคำพูด ความลังเล และการใคร่ครวญ—ความลังเล AI ไม่สามารถทำเช่นนี้ได้ ทว่า ความลังเลของมนุษย์กลับกลายเป็นการปลอบประโลมและความมีมารยาท
มันเป็นเรื่องประมาณยี่สิบปีที่แล้ว สมัยที่ฉันกำลังมุ่งเน้นไปที่การพัฒนาเกมยิงปืน เพื่อนร่วมทีมคนหนึ่งในแผนกโมเดลลิ่งตัวละคร 3 มิติ ได้ยื่นหนังสือเล่มหนึ่งให้ฉันพร้อมพูดว่า "เพื่อนสมัยมัธยมปลายของฉันเป็นนักเขียนนวนิยาย นายควรลองอ่านดูนะ" การสังเกตอย่างลึกซึ้งที่แฝงไปด้วยความเฉลียวฉลาด ฉันจดจ่ออยู่กับมันอย่างสมบูรณ์ หนังสือเล่มนั้นคือหนังสือรวมเรื่องสั้นของ Kim Ae-ran ที่ชื่อว่า Run, Daddy, Run (달려라 아비) ฉันเป็นแฟนคลับของเธอตั้งแต่นั้นเป็นต้นมา
ความลังเลต้องการเวลาและความแน่นอนที่ต่ำกว่า
Kim Ae-ran กล่าวว่ากล้ามเนื้อการเขียนของเธอแข็งแกร่งขึ้นผ่านการเอาใจใส่อย่างพิถีพิถันและการตั้งคำถามกับตัวเองในทุกๆ บรรทัด เธอกล่าวว่าเวลาที่ใช้ไตร่ตรองระหว่างประโยคจะกลายเป็นความใส่ใจต่อผู้อื่น เธอยังเสนอแนะอีกว่าคุณค่าที่แท้จริงของวรรณกรรมไม่ได้อยู่ที่เนื้อหา แต่อยู่ที่รูปแบบของมัน ถ้าอย่างนั้น หากรูปแบบมีความสำคัญเช่นกัน บางที AI อาจเลียนแบบมันได้บ้างอย่างน้อยก็ในระดับคร่าวๆ?
ในมุมมองของฟิสิกส์ เวลาคือการเปลี่ยนแปลงในสถานะทางกายภาพ ในทางฟิสิกส์ เวลาจะยังไม่ผ่านไปหากสถานะไม่มีการเปลี่ยนแปลง ดังนั้น การเปลี่ยนแปลงในสถานะที่น้อยลงจะเท่ากับเวลาที่ช้าลง และการเปลี่ยนแปลงที่มากขึ้นจะเท่ากับเวลาที่ยาวนานขึ้น วินาทีอันรวดเร็วสำหรับมนุษย์คือชั่วนิรันดร์สำหรับ AI ซึ่งทอดยาวผ่านการคำนวณแบบทศนิยม (FLOPs) นับแสนล้านหรือล้านล้านครั้ง เมื่อเทียบกับซอฟต์แวร์ในอดีต คำตอบของ AI ในปัจจุบันเป็นผลผลิตจากการทำงานหนักที่ยาวนานและเต็มไปด้วยความเจ็บปวด นี่เป็นเหตุผลว่าทำไมอุตสาหกรรม AI จึงสามารถเติบโตในแง่ของรายได้ในขณะที่ต้องดิ้นรนในแง่ของผลกำไร ในมุมมองของซอฟต์แวร์แบบดั้งเดิม AI นั้นทำงานช้าเกินไปสำหรับเครื่องจักร แม้แต่ง่ายๆ อย่างการตรวจสอบความถูกต้องของรูปแบบ JSON เมื่อรันผ่านการอนุมานของโมเดลภาษาขนาดใหญ่ (LLM) ก็ต้องเสียค่าใช้จ่ายในการคำนวณหลายร้อยล้านครั้งเมื่อเทียบกับซอฟต์แวร์แบบดั้งเดิม
โมเดลภาษาขนาดใหญ่ (LLMs) ซึ่งเป็นกลไกขับเคลื่อนความก้าวหน้าล่าสุดของ AI คือโปรแกรมที่ทำนายคำถัดไปในประโยค AI ใช้กระแสไฟฟ้าเพื่อค้นหาคำถัดไป มันทำการคูณและบวกเมทริกซ์ขนาดใหญ่อย่างซ้ำๆ การคำนวณของ AI ต้องใช้การใช้ทรัพยากรทางกายภาพของฮาร์ดแวร์ การจะป้อนให้ AI มีความลังเลในระดับรูปแบบ ซึ่งเทียบได้กับช่วงเวลาแห่งความทุกข์ระทมของมนุษย์ คุณต้องให้มันผ่านกระบวนการคำนวณอย่างเข้มข้น การคำนวณนับแสนล้านครั้งเพื่อสร้างคำถัดไปเพียงคำเดียว และการคำนวณอีกแสนล้านครั้งก็ตามมาเพื่อสร้างคำต่อไปหลังจากนั้น
การคำนวณ Deep Learning ร่วมสมัยส่วนใหญ่เกี่ยวข้องกับผลรวมแบบถ่วงน้ำหนัก (weighted sums) และค่าที่คำนวณไว้ล่วงหน้าที่ใช้ในผลรวมเหล่านี้เรียกว่าพารามิเตอร์ (parameters)
เมื่อเราพูดถึงโมเดล 'Qwen 3.6 27B' นั่นหมายความว่ามีพารามิเตอร์ 27,000 ล้านพารามิเตอร์ที่พร้อมสำหรับการรวมน้ำหนัก ซึ่งต้องใช้การคูณประมาณ 27,000 ล้านครั้งเพื่อทำนายโทเค็นถัดไปเพียงโทเค็นเดียว แต่นั่นเป็นเพียงจุดเริ่มต้นเท่านั้น ยิ่งไปกว่านั้น การคูณจำนวนเต็มเพียงครั้งเดียวเกี่ยวข้องกับการดำเนินการทางตรรกะหลายสิบครั้ง และเลขทศนิยมต้องการการดำเนินการนับพันครั้ง เมื่อพิจารณาถึงความซับซ้อนดังกล่าว ใครๆ ก็อาจเรียกได้ว่าเป็นเรื่องที่น่าเหลือเชื่อ
การลดอุณหภูมิ (Temperature) ช่วยตอกย้ำความลำเอียง
มาดูรายละเอียดเจาะลึกว่า LLM ทำงานอย่างไร เป็นที่ทราบกันดีอยู่แล้วว่า Deep Learning ซึ่งเป็นรากฐานของ LLM คือเครื่องมือจับคู่รูปแบบ (pattern matching) ที่นำรูปแบบที่จดจำระหว่างการฝึกฝนมาใช้กับการใช้งานจริง มีสองสิ่งที่ควบคุมกระบวนการคายข้อมูลดังกล่าว ได้แก่ การสุ่มโทเค็น (token sampling) และอุณหภูมิ (temperature)
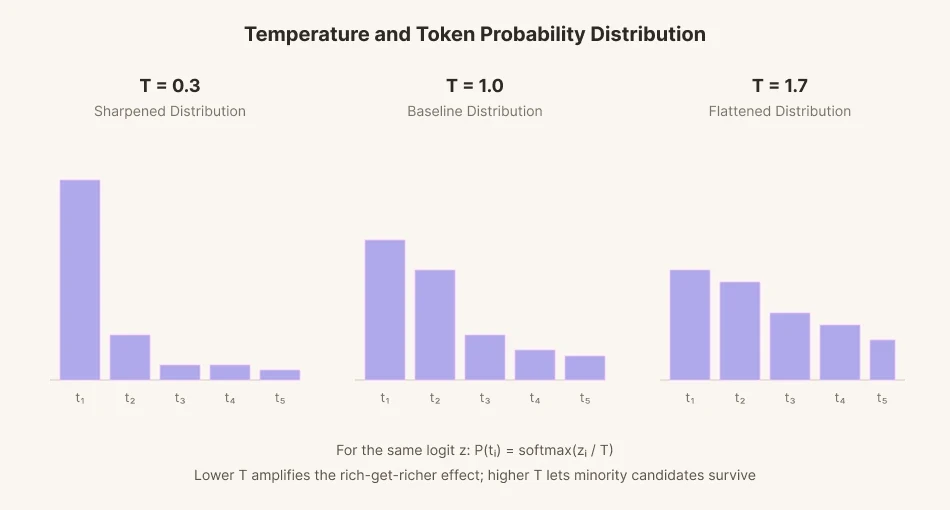
ในการทำนายคำถัดไปเพียงคำเดียว โมเดลจะกำหนดคะแนน (logit) ให้กับคำที่เป็นตัวเลือกนับหมื่นคำ คะแนนเหล่านั้นจะถูกแปลงเป็นความน่าจะเป็น และคำนั้นจะถูกเลือกตามสัดส่วนของแต่ละความน่าจะเป็น กระบวนการนี้เรียกว่าการสุ่มตัวอย่าง (sampling)
เพื่อเพิ่มความหลากหลายให้กับการสุ่มตัวอย่าง พารามิเตอร์ทางคณิตศาสตร์ที่เรียกว่า 'temperature' (อุณหภูมิ) จึงถูกนำมาใช้ การลดอุณหภูมิลงจะทำให้ช่องว่างระหว่างคะแนนของผู้สมัครยืดออกไปจนสุดขั้ว คำที่มีความน่าจะเป็นสูงจะถูกเลือกบ่อยกว่าคำที่อยู่ในระดับฐาน คำที่มีความน่าจะเป็นต่ำยิ่งมีโอกาสถูกเลือกน้อยลงไปอีก คล้ายกับว่าคนรวยยิ่งรวยขึ้นและคนจนยิ่งจนลง ในทางกลับกัน ช่องว่างนี้จะแคบลงเมื่ออุณหภูมิสูงขึ้น ช่องว่างจะแบนราบและสม่ำเสมอขึ้น คำที่มีความน่าจะเป็นต่ำซึ่งปกติแล้วจะถูกมองข้าม ก็สามารถเลือกได้ในอัตราที่สูงขึ้นเมื่ออุณหภูมิสูงขึ้น
ภาษาของมนุษย์ก็คล้ายกัน กลุ่มและวัฒนธรรมที่ฉันเป็นส่วนหนึ่งจะสะท้อนอยู่ในสัญกรณ์ความน่าจะเป็นของภาษาฉัน ภาษาที่เย็นชาและเฉียบขาดกว่าจะสร้างคำพูดที่สมเหตุสมผลกว่า ได้รับการปรับแต่งให้เหมาะสมมากกว่า และสอดคล้องกับคนส่วนใหญ่มากกว่า ภาษาที่อบอุ่นและกลมกล่อมกว่านั้นสมเหตุสมผลน้อยกว่าและได้รับการปรับแต่งน้อยกว่า แต่จะคำนึงถึงคนกลุ่มน้อยด้วย
การพิจารณาใส่ใจผู้อื่นคือการกระทำที่ใช้พลังงานพิเศษเพื่อก้าวออกจากสัญกรณ์ความน่าจะเป็นของความคิดของตัวเอง นั่นหมายถึงการสังเกตเห็นสิ่งที่คนส่วนใหญ่บดบังไว้ และค้นหาประโยคที่ปกติไม่ได้ใช้ สิ่งที่นักเขียนอธิบายว่าเป็นกระบวนการเขียนที่ยากลำบาก สำหรับ AI นั้น ควรเปลี่ยนเป็นการปฏิเสธไม่ตอบสนองตามข้อมูลที่ฝึกฝนมาอย่างลำเอียงเพียงอย่างเดียว และพยายามเดินทางก้าวข้ามขีดจำกัดเดิมออกไป
ความกระสับกระส่ายของเครื่องจักร
เราจะสอนให้ AI รู้จักใส่ใจผู้อื่นได้อย่างไร? คุณจะไม่ปล่อยให้มันคายคำที่มีความน่าจะเป็นสูงสุดออกมาทันที นั่นจะยิ่งเป็นการส่งออกความลำเอียงส่วนบุคคลที่มีอยู่ในข้อมูลการเรียนรู้
สาเหตุที่โมเดล AI ในปัจจุบันบรรลุผลลัพธ์ที่โดดเด่นเช่นนี้เป็นเพราะสาขานี้ได้พัฒนาเทคโนโลยีที่เน้นไปที่ 'Inference-Time Compute' (การคำนวณระหว่างรันไทม์อนุมาน) มันเป็นเทคโนโลยีที่ช่วยให้ AI มีเวลาในการคำนวณมากขึ้นก่อนที่จะตอบคำถาม โมเดล AI ในอดีตจะส่งเอาต์พุตคำตอบแรกที่คำนวณได้ทันที หรืออีกนัยหนึ่งคือคำตอบแรกที่แวบขึ้นมาในหัว ในทางตรงกันข้าม โมเดลการคิดในปัจจุบันจะสร้างเส้นทางการคิดเหตุผลหลายเส้นทาง
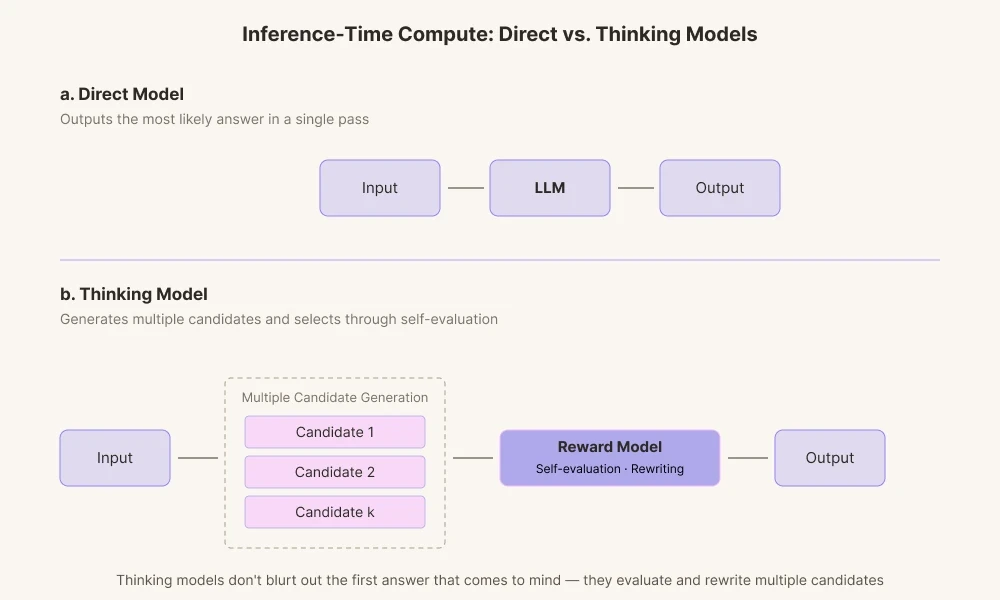
โมเดลเหล่านี้สร้างคำตอบที่เป็นตัวเลือกหลากหลายรูปแบบและให้คะแนนการตอบคำถามเหล่านั้นผ่านโมเดลการให้รางวัลในตัวมันเอง (reward model) มันจะรันผ่านกระบวนการตรวจสอบว่าคำเหล่านั้นเหมาะสมกับบริบทหรือไม่ และดูว่าคำเหล่านั้นฟังดูเด็ดขาดเกินไปสำหรับมันหรือไม่ จากนั้นจึงคัดทิ้งภายในระบบระบบหากจำเป็น
สิ่งนี้คล้ายกับวิธีที่มนุษย์แก้ไขประโยคในความคิดก่อนที่จะพูด แทนที่จะเรียกร้องให้ AI ส่งมอบคำตอบที่แม่นยำที่สุดเท่าที่จะเป็นไปได้ตามสัญกรณ์ความน่าจะเป็น แต่จะใช้ทรัพยากรการคำนวณเพื่อให้เวลามันปรับแก้ไข เราปล่อยให้มันเดินทางออกนอกจุดศูนย์กลางของสัญกรณ์ความน่าจะเป็นไปยังขอบรอบนอก: นั่นคือความกระสับกระส่ายในแบบของเครื่องจักร
ความกระสับกระส่ายในการแปลวิดีโอ
การแปลภาษาทั่วไปจะเสร็จสิ้นเมื่อจับคู่ความหมายได้เหมาะสมแล้ว แต่การแปลวิดีโอไม่เพียงต้องการความหมายที่ถูกต้องเท่านั้น แต่ความยาวและจังหวะเวลาของการขยับริมฝีปากจะต้องตรงกันด้วย
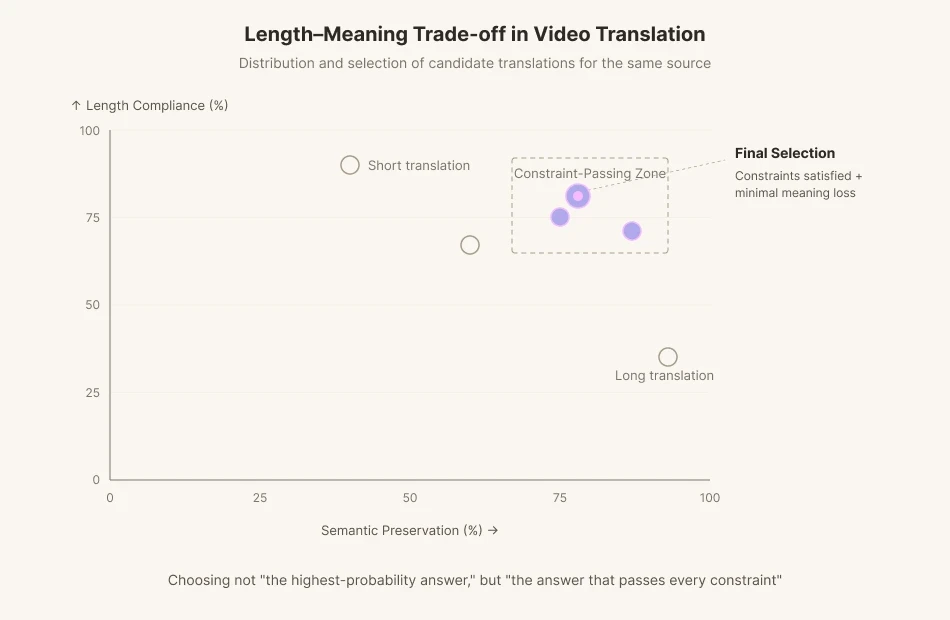
หากนักแสดงบนหน้าจอขยับปากเป็นเวลา 1.8 วินาทีและพ่นประโยคภาษาอังกฤษที่มี 11 พยางค์ นักแปลจะต้องสร้างประโยคภาษาเกาหลีที่พอดีภายใน 1.8 วินาทีนั้น หากรักษาความหมายไว้ ความยาวก็จะเพี้ยนไป หากปรับความยาวให้ตรง ความหมายก็จะเลือนลาง เมื่อพยัญชนะสะกดท้ายและสระเปิดแตกต่างจากต้นฉบับ ผู้ชมจะรู้สึกถึงความผิดปกติทันทีที่มองเห็น ซับไตเติลยังมีข้อจำกัดอีกประการหนึ่งคือ ความเร็วในการอ่าน 12 ถึง 15 ตัวอักษรต่อวินาที ดังนั้น นักแปลที่ทำงานพับพากย์ (dubbing) จึงต้องวางประโยคที่มีความหมายเทียบเท่ากันห้าบรรทัด นับพยางค์ จับคู่เน้นเสียง และเลือกคำแปลที่ไม่ใช่คำแปลที่ถูกต้องที่สุด แต่เป็นตัวเลือกที่สูญเสียความหมายน้อยที่สุดภายใต้ข้อจำกัดเหล่านั้น
ทีมแปลของ Perso Dubbing ได้ทำงานอย่างหนักเพื่อแก้ปัญหาในส่วนนี้โดยเฉพาะ ทีมงานได้ตีพิมพ์เอกสารทางวิชาการที่ EMNLP (https://aclanthology.org/2025.emnlp-demos.37) ซึ่งระบุปริมาณการแลกเปลี่ยนระหว่าง Isochrony (ความสอดคล้องด้านความยาว) และ Semantic Alignment (ความสอดคล้องด้านความหมาย) ในการแปลวิดีโอ
EMNLP (Empirical Methods in Natural Language Processing) เป็นงานประชุมวิจัยระดับแนวหน้าในด้านการประมวลผลภาษาธรรมชาติ เพื่อให้คู่ควรกับชื่อของมัน งานประชุมนี้ให้คุณค่ากับงานวิจัยเชิงประจักษ์ (empirical research) ที่พิสูจน์ประสิทธิภาพของเทคโนโลยีในโลกแห่งความเป็นจริงผ่านข้อมูลและการทดลอง มากกว่าสมมติฐานทางทฤษฎีล้วนๆ ด้วยเอกลักษณ์ดังกล่าว ผลงานวิจัยของทีมวิจัย ESTsoft ได้หยิบยกปัญหายากของการแปลวิดีโอมาวิเคราะห์ เปลี่ยนให้เป็นข้อมูลเชิงปริมาณ และแก้ปัญหาด้วยอัลกอริทึม ซึ่งเป็นการสนับสนุนที่ใช้ได้จริงและมีประโยชน์อย่างมากในโลกแห่งความเป็นจริง
คำถามสำคัญที่ไปป์ไลน์การพากย์เสียงของ Perso Dubbing คำนึงถึงนั้นอยู่ตรงนี้ ไม่ใช่ตัวอักษร ไม่ใช่พยางค์ แต่คือหน่วยเสียง (phoneme) ซึ่งเป็นหน่วยย่อยที่สุดของคำพูด ตัวอักษรและพยางค์คือหน่วยวัดบนหน้าจอ ส่วนหน่วยเสียงจะสอดคล้องกับเวลาที่ใช้จริงในช่องปาก อัลกอริทึมที่นำเสนอในเอกสารวิจัย CountPhonemes จะนับจำนวนหน่วยเสียงของประโยคที่แปล เปรียบเทียบกับจำนวนหน่วยเสียงเป้าหมาย และปรับปรุงแก้ไขประโยคเพื่อให้ทั้งสองส่วนออกมาตรงกัน
โมเดลการแปลด้วยเครื่องที่มีอยู่ได้รับการปรับแต่งให้เหมาะกับเกณฑ์วัดการรักษาความหมาย เช่น BLEU และ COMET พวกมันถูกฝึกฝนมาเพื่อส่งมอบการแปลที่สมเหตุสมผลที่สุดอย่างรวดเร็วที่สุดเท่าที่จะเป็นไปได้ แต่บางครั้งการแปลวิดีโอก็ต้องปฏิเสธคำแปลส่วนที่สมเหตุสมผลที่สุด เมื่อหน่วยเสียงไม่เพียงพอ คุณต้องยอมละทิ้งความหมายบางส่วนและหาสำนวนอื่นแทน เราไม่ได้ขอให้ AI ทำงานเพื่อ "คำตอบที่น่าจะเป็นไปได้มากที่สุด" แต่ต้องการ "คำตอบที่ตอบสนองทุกข้อจำกัด"
นี่คือสิ่งที่ไปป์ไลน์การพากย์เสียงของ Perso Dubbing เข้ามาช่วยแก้ไข ในขั้นตอนการแปล ระบบจะสร้างผู้สมัครจำนวนมากที่ตรงตามข้อจำกัดด้านความยาวและหน่วยเสียง จากนั้นจึงเลือกตัวเลือกที่สูญเสียความหมายน้อยที่สุด มันคือแนวคิด inference-time compute จากหัวข้อก่อนหน้าที่ถูกนำมาปรับใช้ในโดเมนของการพากย์เสียง หยุดไม่ให้โมเดลพ่นคำตอบแรกที่เข้ามาในหัวทันที ให้มันคิดทบทวนและเรียบเรียงใหม่ ให้มันทำการตรวจสอบ การแปลซ้ำแบบวนรอบ (iterative translation) นี้ คือความลังเลอย่างจงใจที่ถูกกำหนดให้กับเครื่องจักร ภายใน ลูปข้อเสนอแนะซ้ำ (iterative feedback loop) โมเดลจะพยายามตามหาจุดเหมาะสมที่สุดระหว่างความสอดคล้องด้านความยาว (Isochrony) และความสอดคล้องด้านความหมาย (Semantic Alignment) มันคือการจำลองการทำงานอย่างเอาเป็นเอาตายของนักแปลวิดีโอเข้าไปในตัวโมเดลเอง
บทสรุป
ความลังเลไม่ใช่เพียงความไม่สมบูรณ์แบบ ไม่ใช่เพียงความล่าช้า แต่มันคือการสั่งสมเวลาที่ใช้ไปเพื่อคิดคำนึงถึงผู้อื่น หาก AI จะเคยเรียนรู้ที่จะหยุดชั่วคราวเพื่อเห็นแก่การพิจารณาใส่ใจผู้อื่น มันจะไม่ใช่เพราะโมเดลนั้นฉลาดขึ้น แต่เป็นเพราะเราออกแบบให้มันมีความแน่ใจน้อยลง ปล่อยให้มันค้างอยู่กับความคิดนานขึ้น และรู้จักที่จะลังเล
วิธีสอนให้ AI รู้จักลังเล
สองสามวันก่อน ฉันบังเอิญไปเจอคลิป YouTube คลิปหนึ่ง ผู้ประกาศข่าวคุณ Sohn Suk-hee กำลังสัมภาษณ์นักเขียนนวนิยายคุณ Kim Ae-ran คำถามคือ "มนุษย์มีอะไรที่ AI ไม่มี?" และคำตอบของเธอคือ "ความลังเล"
นักเขียนนวนิยายได้หยิบยกช่วงเวลาหนึ่งจากรายการออกอากาศเก่าของผู้ประกาศข่าวคนดังกล่าว ในขณะที่รายงานข่าวการเสียชีวิตของอดีต Roh Hoe-chan นักเคลื่อนไหวเพื่อแรงงานที่ผันตัวมาเป็นนักการเมือง เขาถึงกับพูดไม่ออกไปยี่สิบวินาที ช่วงเวลาของการระงับคำพูด ความลังเล และการใคร่ครวญ—ความลังเล AI ไม่สามารถทำเช่นนี้ได้ ทว่า ความลังเลของมนุษย์กลับกลายเป็นการปลอบประโลมและความมีมารยาท
มันเป็นเรื่องประมาณยี่สิบปีที่แล้ว สมัยที่ฉันกำลังมุ่งเน้นไปที่การพัฒนาเกมยิงปืน เพื่อนร่วมทีมคนหนึ่งในแผนกโมเดลลิ่งตัวละคร 3 มิติ ได้ยื่นหนังสือเล่มหนึ่งให้ฉันพร้อมพูดว่า "เพื่อนสมัยมัธยมปลายของฉันเป็นนักเขียนนวนิยาย นายควรลองอ่านดูนะ" การสังเกตอย่างลึกซึ้งที่แฝงไปด้วยความเฉลียวฉลาด ฉันจดจ่ออยู่กับมันอย่างสมบูรณ์ หนังสือเล่มนั้นคือหนังสือรวมเรื่องสั้นของ Kim Ae-ran ที่ชื่อว่า Run, Daddy, Run (달려라 아비) ฉันเป็นแฟนคลับของเธอตั้งแต่นั้นเป็นต้นมา
ความลังเลต้องการเวลาและความแน่นอนที่ต่ำกว่า
Kim Ae-ran กล่าวว่ากล้ามเนื้อการเขียนของเธอแข็งแกร่งขึ้นผ่านการเอาใจใส่อย่างพิถีพิถันและการตั้งคำถามกับตัวเองในทุกๆ บรรทัด เธอกล่าวว่าเวลาที่ใช้ไตร่ตรองระหว่างประโยคจะกลายเป็นความใส่ใจต่อผู้อื่น เธอยังเสนอแนะอีกว่าคุณค่าที่แท้จริงของวรรณกรรมไม่ได้อยู่ที่เนื้อหา แต่อยู่ที่รูปแบบของมัน ถ้าอย่างนั้น หากรูปแบบมีความสำคัญเช่นกัน บางที AI อาจเลียนแบบมันได้บ้างอย่างน้อยก็ในระดับคร่าวๆ?
ในมุมมองของฟิสิกส์ เวลาคือการเปลี่ยนแปลงในสถานะทางกายภาพ ในทางฟิสิกส์ เวลาจะยังไม่ผ่านไปหากสถานะไม่มีการเปลี่ยนแปลง ดังนั้น การเปลี่ยนแปลงในสถานะที่น้อยลงจะเท่ากับเวลาที่ช้าลง และการเปลี่ยนแปลงที่มากขึ้นจะเท่ากับเวลาที่ยาวนานขึ้น วินาทีอันรวดเร็วสำหรับมนุษย์คือชั่วนิรันดร์สำหรับ AI ซึ่งทอดยาวผ่านการคำนวณแบบทศนิยม (FLOPs) นับแสนล้านหรือล้านล้านครั้ง เมื่อเทียบกับซอฟต์แวร์ในอดีต คำตอบของ AI ในปัจจุบันเป็นผลผลิตจากการทำงานหนักที่ยาวนานและเต็มไปด้วยความเจ็บปวด นี่เป็นเหตุผลว่าทำไมอุตสาหกรรม AI จึงสามารถเติบโตในแง่ของรายได้ในขณะที่ต้องดิ้นรนในแง่ของผลกำไร ในมุมมองของซอฟต์แวร์แบบดั้งเดิม AI นั้นทำงานช้าเกินไปสำหรับเครื่องจักร แม้แต่ง่ายๆ อย่างการตรวจสอบความถูกต้องของรูปแบบ JSON เมื่อรันผ่านการอนุมานของโมเดลภาษาขนาดใหญ่ (LLM) ก็ต้องเสียค่าใช้จ่ายในการคำนวณหลายร้อยล้านครั้งเมื่อเทียบกับซอฟต์แวร์แบบดั้งเดิม
โมเดลภาษาขนาดใหญ่ (LLMs) ซึ่งเป็นกลไกขับเคลื่อนความก้าวหน้าล่าสุดของ AI คือโปรแกรมที่ทำนายคำถัดไปในประโยค AI ใช้กระแสไฟฟ้าเพื่อค้นหาคำถัดไป มันทำการคูณและบวกเมทริกซ์ขนาดใหญ่อย่างซ้ำๆ การคำนวณของ AI ต้องใช้การใช้ทรัพยากรทางกายภาพของฮาร์ดแวร์ การจะป้อนให้ AI มีความลังเลในระดับรูปแบบ ซึ่งเทียบได้กับช่วงเวลาแห่งความทุกข์ระทมของมนุษย์ คุณต้องให้มันผ่านกระบวนการคำนวณอย่างเข้มข้น การคำนวณนับแสนล้านครั้งเพื่อสร้างคำถัดไปเพียงคำเดียว และการคำนวณอีกแสนล้านครั้งก็ตามมาเพื่อสร้างคำต่อไปหลังจากนั้น
การคำนวณ Deep Learning ร่วมสมัยส่วนใหญ่เกี่ยวข้องกับผลรวมแบบถ่วงน้ำหนัก (weighted sums) และค่าที่คำนวณไว้ล่วงหน้าที่ใช้ในผลรวมเหล่านี้เรียกว่าพารามิเตอร์ (parameters)
เมื่อเราพูดถึงโมเดล 'Qwen 3.6 27B' นั่นหมายความว่ามีพารามิเตอร์ 27,000 ล้านพารามิเตอร์ที่พร้อมสำหรับการรวมน้ำหนัก ซึ่งต้องใช้การคูณประมาณ 27,000 ล้านครั้งเพื่อทำนายโทเค็นถัดไปเพียงโทเค็นเดียว แต่นั่นเป็นเพียงจุดเริ่มต้นเท่านั้น ยิ่งไปกว่านั้น การคูณจำนวนเต็มเพียงครั้งเดียวเกี่ยวข้องกับการดำเนินการทางตรรกะหลายสิบครั้ง และเลขทศนิยมต้องการการดำเนินการนับพันครั้ง เมื่อพิจารณาถึงความซับซ้อนดังกล่าว ใครๆ ก็อาจเรียกได้ว่าเป็นเรื่องที่น่าเหลือเชื่อ
การลดอุณหภูมิ (Temperature) ช่วยตอกย้ำความลำเอียง
มาดูรายละเอียดเจาะลึกว่า LLM ทำงานอย่างไร เป็นที่ทราบกันดีอยู่แล้วว่า Deep Learning ซึ่งเป็นรากฐานของ LLM คือเครื่องมือจับคู่รูปแบบ (pattern matching) ที่นำรูปแบบที่จดจำระหว่างการฝึกฝนมาใช้กับการใช้งานจริง มีสองสิ่งที่ควบคุมกระบวนการคายข้อมูลดังกล่าว ได้แก่ การสุ่มโทเค็น (token sampling) และอุณหภูมิ (temperature)
ในการทำนายคำถัดไปเพียงคำเดียว โมเดลจะกำหนดคะแนน (logit) ให้กับคำที่เป็นตัวเลือกนับหมื่นคำ คะแนนเหล่านั้นจะถูกแปลงเป็นความน่าจะเป็น และคำนั้นจะถูกเลือกตามสัดส่วนของแต่ละความน่าจะเป็น กระบวนการนี้เรียกว่าการสุ่มตัวอย่าง (sampling)
เพื่อเพิ่มความหลากหลายให้กับการสุ่มตัวอย่าง พารามิเตอร์ทางคณิตศาสตร์ที่เรียกว่า 'temperature' (อุณหภูมิ) จึงถูกนำมาใช้ การลดอุณหภูมิลงจะทำให้ช่องว่างระหว่างคะแนนของผู้สมัครยืดออกไปจนสุดขั้ว คำที่มีความน่าจะเป็นสูงจะถูกเลือกบ่อยกว่าคำที่อยู่ในระดับฐาน คำที่มีความน่าจะเป็นต่ำยิ่งมีโอกาสถูกเลือกน้อยลงไปอีก คล้ายกับว่าคนรวยยิ่งรวยขึ้นและคนจนยิ่งจนลง ในทางกลับกัน ช่องว่างนี้จะแคบลงเมื่ออุณหภูมิสูงขึ้น ช่องว่างจะแบนราบและสม่ำเสมอขึ้น คำที่มีความน่าจะเป็นต่ำซึ่งปกติแล้วจะถูกมองข้าม ก็สามารถเลือกได้ในอัตราที่สูงขึ้นเมื่ออุณหภูมิสูงขึ้น
ภาษาของมนุษย์ก็คล้ายกัน กลุ่มและวัฒนธรรมที่ฉันเป็นส่วนหนึ่งจะสะท้อนอยู่ในสัญกรณ์ความน่าจะเป็นของภาษาฉัน ภาษาที่เย็นชาและเฉียบขาดกว่าจะสร้างคำพูดที่สมเหตุสมผลกว่า ได้รับการปรับแต่งให้เหมาะสมมากกว่า และสอดคล้องกับคนส่วนใหญ่มากกว่า ภาษาที่อบอุ่นและกลมกล่อมกว่านั้นสมเหตุสมผลน้อยกว่าและได้รับการปรับแต่งน้อยกว่า แต่จะคำนึงถึงคนกลุ่มน้อยด้วย
การพิจารณาใส่ใจผู้อื่นคือการกระทำที่ใช้พลังงานพิเศษเพื่อก้าวออกจากสัญกรณ์ความน่าจะเป็นของความคิดของตัวเอง นั่นหมายถึงการสังเกตเห็นสิ่งที่คนส่วนใหญ่บดบังไว้ และค้นหาประโยคที่ปกติไม่ได้ใช้ สิ่งที่นักเขียนอธิบายว่าเป็นกระบวนการเขียนที่ยากลำบาก สำหรับ AI นั้น ควรเปลี่ยนเป็นการปฏิเสธไม่ตอบสนองตามข้อมูลที่ฝึกฝนมาอย่างลำเอียงเพียงอย่างเดียว และพยายามเดินทางก้าวข้ามขีดจำกัดเดิมออกไป
ความกระสับกระส่ายของเครื่องจักร
เราจะสอนให้ AI รู้จักใส่ใจผู้อื่นได้อย่างไร? คุณจะไม่ปล่อยให้มันคายคำที่มีความน่าจะเป็นสูงสุดออกมาทันที นั่นจะยิ่งเป็นการส่งออกความลำเอียงส่วนบุคคลที่มีอยู่ในข้อมูลการเรียนรู้
สาเหตุที่โมเดล AI ในปัจจุบันบรรลุผลลัพธ์ที่โดดเด่นเช่นนี้เป็นเพราะสาขานี้ได้พัฒนาเทคโนโลยีที่เน้นไปที่ 'Inference-Time Compute' (การคำนวณระหว่างรันไทม์อนุมาน) มันเป็นเทคโนโลยีที่ช่วยให้ AI มีเวลาในการคำนวณมากขึ้นก่อนที่จะตอบคำถาม โมเดล AI ในอดีตจะส่งเอาต์พุตคำตอบแรกที่คำนวณได้ทันที หรืออีกนัยหนึ่งคือคำตอบแรกที่แวบขึ้นมาในหัว ในทางตรงกันข้าม โมเดลการคิดในปัจจุบันจะสร้างเส้นทางการคิดเหตุผลหลายเส้นทาง
โมเดลเหล่านี้สร้างคำตอบที่เป็นตัวเลือกหลากหลายรูปแบบและให้คะแนนการตอบคำถามเหล่านั้นผ่านโมเดลการให้รางวัลในตัวมันเอง (reward model) มันจะรันผ่านกระบวนการตรวจสอบว่าคำเหล่านั้นเหมาะสมกับบริบทหรือไม่ และดูว่าคำเหล่านั้นฟังดูเด็ดขาดเกินไปสำหรับมันหรือไม่ จากนั้นจึงคัดทิ้งภายในระบบระบบหากจำเป็น
สิ่งนี้คล้ายกับวิธีที่มนุษย์แก้ไขประโยคในความคิดก่อนที่จะพูด แทนที่จะเรียกร้องให้ AI ส่งมอบคำตอบที่แม่นยำที่สุดเท่าที่จะเป็นไปได้ตามสัญกรณ์ความน่าจะเป็น แต่จะใช้ทรัพยากรการคำนวณเพื่อให้เวลามันปรับแก้ไข เราปล่อยให้มันเดินทางออกนอกจุดศูนย์กลางของสัญกรณ์ความน่าจะเป็นไปยังขอบรอบนอก: นั่นคือความกระสับกระส่ายในแบบของเครื่องจักร
ความกระสับกระส่ายในการแปลวิดีโอ
การแปลภาษาทั่วไปจะเสร็จสิ้นเมื่อจับคู่ความหมายได้เหมาะสมแล้ว แต่การแปลวิดีโอไม่เพียงต้องการความหมายที่ถูกต้องเท่านั้น แต่ความยาวและจังหวะเวลาของการขยับริมฝีปากจะต้องตรงกันด้วย
หากนักแสดงบนหน้าจอขยับปากเป็นเวลา 1.8 วินาทีและพ่นประโยคภาษาอังกฤษที่มี 11 พยางค์ นักแปลจะต้องสร้างประโยคภาษาเกาหลีที่พอดีภายใน 1.8 วินาทีนั้น หากรักษาความหมายไว้ ความยาวก็จะเพี้ยนไป หากปรับความยาวให้ตรง ความหมายก็จะเลือนลาง เมื่อพยัญชนะสะกดท้ายและสระเปิดแตกต่างจากต้นฉบับ ผู้ชมจะรู้สึกถึงความผิดปกติทันทีที่มองเห็น ซับไตเติลยังมีข้อจำกัดอีกประการหนึ่งคือ ความเร็วในการอ่าน 12 ถึง 15 ตัวอักษรต่อวินาที ดังนั้น นักแปลที่ทำงานพับพากย์ (dubbing) จึงต้องวางประโยคที่มีความหมายเทียบเท่ากันห้าบรรทัด นับพยางค์ จับคู่เน้นเสียง และเลือกคำแปลที่ไม่ใช่คำแปลที่ถูกต้องที่สุด แต่เป็นตัวเลือกที่สูญเสียความหมายน้อยที่สุดภายใต้ข้อจำกัดเหล่านั้น
ทีมแปลของ Perso Dubbing ได้ทำงานอย่างหนักเพื่อแก้ปัญหาในส่วนนี้โดยเฉพาะ ทีมงานได้ตีพิมพ์เอกสารทางวิชาการที่ EMNLP (https://aclanthology.org/2025.emnlp-demos.37) ซึ่งระบุปริมาณการแลกเปลี่ยนระหว่าง Isochrony (ความสอดคล้องด้านความยาว) และ Semantic Alignment (ความสอดคล้องด้านความหมาย) ในการแปลวิดีโอ
EMNLP (Empirical Methods in Natural Language Processing) เป็นงานประชุมวิจัยระดับแนวหน้าในด้านการประมวลผลภาษาธรรมชาติ เพื่อให้คู่ควรกับชื่อของมัน งานประชุมนี้ให้คุณค่ากับงานวิจัยเชิงประจักษ์ (empirical research) ที่พิสูจน์ประสิทธิภาพของเทคโนโลยีในโลกแห่งความเป็นจริงผ่านข้อมูลและการทดลอง มากกว่าสมมติฐานทางทฤษฎีล้วนๆ ด้วยเอกลักษณ์ดังกล่าว ผลงานวิจัยของทีมวิจัย ESTsoft ได้หยิบยกปัญหายากของการแปลวิดีโอมาวิเคราะห์ เปลี่ยนให้เป็นข้อมูลเชิงปริมาณ และแก้ปัญหาด้วยอัลกอริทึม ซึ่งเป็นการสนับสนุนที่ใช้ได้จริงและมีประโยชน์อย่างมากในโลกแห่งความเป็นจริง
คำถามสำคัญที่ไปป์ไลน์การพากย์เสียงของ Perso Dubbing คำนึงถึงนั้นอยู่ตรงนี้ ไม่ใช่ตัวอักษร ไม่ใช่พยางค์ แต่คือหน่วยเสียง (phoneme) ซึ่งเป็นหน่วยย่อยที่สุดของคำพูด ตัวอักษรและพยางค์คือหน่วยวัดบนหน้าจอ ส่วนหน่วยเสียงจะสอดคล้องกับเวลาที่ใช้จริงในช่องปาก อัลกอริทึมที่นำเสนอในเอกสารวิจัย CountPhonemes จะนับจำนวนหน่วยเสียงของประโยคที่แปล เปรียบเทียบกับจำนวนหน่วยเสียงเป้าหมาย และปรับปรุงแก้ไขประโยคเพื่อให้ทั้งสองส่วนออกมาตรงกัน
โมเดลการแปลด้วยเครื่องที่มีอยู่ได้รับการปรับแต่งให้เหมาะกับเกณฑ์วัดการรักษาความหมาย เช่น BLEU และ COMET พวกมันถูกฝึกฝนมาเพื่อส่งมอบการแปลที่สมเหตุสมผลที่สุดอย่างรวดเร็วที่สุดเท่าที่จะเป็นไปได้ แต่บางครั้งการแปลวิดีโอก็ต้องปฏิเสธคำแปลส่วนที่สมเหตุสมผลที่สุด เมื่อหน่วยเสียงไม่เพียงพอ คุณต้องยอมละทิ้งความหมายบางส่วนและหาสำนวนอื่นแทน เราไม่ได้ขอให้ AI ทำงานเพื่อ "คำตอบที่น่าจะเป็นไปได้มากที่สุด" แต่ต้องการ "คำตอบที่ตอบสนองทุกข้อจำกัด"
นี่คือสิ่งที่ไปป์ไลน์การพากย์เสียงของ Perso Dubbing เข้ามาช่วยแก้ไข ในขั้นตอนการแปล ระบบจะสร้างผู้สมัครจำนวนมากที่ตรงตามข้อจำกัดด้านความยาวและหน่วยเสียง จากนั้นจึงเลือกตัวเลือกที่สูญเสียความหมายน้อยที่สุด มันคือแนวคิด inference-time compute จากหัวข้อก่อนหน้าที่ถูกนำมาปรับใช้ในโดเมนของการพากย์เสียง หยุดไม่ให้โมเดลพ่นคำตอบแรกที่เข้ามาในหัวทันที ให้มันคิดทบทวนและเรียบเรียงใหม่ ให้มันทำการตรวจสอบ การแปลซ้ำแบบวนรอบ (iterative translation) นี้ คือความลังเลอย่างจงใจที่ถูกกำหนดให้กับเครื่องจักร ภายใน ลูปข้อเสนอแนะซ้ำ (iterative feedback loop) โมเดลจะพยายามตามหาจุดเหมาะสมที่สุดระหว่างความสอดคล้องด้านความยาว (Isochrony) และความสอดคล้องด้านความหมาย (Semantic Alignment) มันคือการจำลองการทำงานอย่างเอาเป็นเอาตายของนักแปลวิดีโอเข้าไปในตัวโมเดลเอง
บทสรุป
ความลังเลไม่ใช่เพียงความไม่สมบูรณ์แบบ ไม่ใช่เพียงความล่าช้า แต่มันคือการสั่งสมเวลาที่ใช้ไปเพื่อคิดคำนึงถึงผู้อื่น หาก AI จะเคยเรียนรู้ที่จะหยุดชั่วคราวเพื่อเห็นแก่การพิจารณาใส่ใจผู้อื่น มันจะไม่ใช่เพราะโมเดลนั้นฉลาดขึ้น แต่เป็นเพราะเราออกแบบให้มันมีความแน่ใจน้อยลง ปล่อยให้มันค้างอยู่กับความคิดนานขึ้น และรู้จักที่จะลังเล
อ่านต่อ
เรียกดูทั้งหมด




