Como ensinar a IA a hesitar: computação em tempo de inferência e a arte da tradução ponderada
Última Atualização


Ir para a seção
Ir para a seção
Partilhar
Partilhar
Partilhar

Ferramenta de Tradução, Localização e Dublagem de Vídeo com IA
Experimente gratuitamente
Como Ensinar a IA a Hesitar
Alguns dias atrás, me deparei com um vídeo no YouTube. O apresentador de telejornal Sohn Suk-hee estava entrevistando a romancista Kim Ae-ran. A pergunta foi "O que o ser humano tem que a IA não tem?", e a resposta dela foi "Hesitação".
A romancista relembrou um momento de uma das antigas transmissões do apresentador. Ao dar a notícia do falecimento do falecido Roh Hoe-chan, um ativista trabalhista que se tornou político, ele perdeu as palavras por vinte segundos. O momento de conter as palavras, hesitar e discernir—a hesitação. A IA é incapaz disso. No entanto, a hesitação de uma pessoa se torna consolo e cortesia.
Isso foi há cerca de vinte anos, quando eu estava focado no desenvolvimento de um jogo de tiro. Um colega de equipe em modelagem de personagens em 3D me entregou um livro dizendo: "Um amigo meu de colégio é romancista; você deveria ler isto". Observações profundas repletas de inteligência. Fiquei completamente absorvido. O livro era a coleção de contos de Kim Ae-ran, Run, Daddy, Run (달려라 아비). Sou fã dela desde então.
A Hesitação Exige Tempo e Menor Certeza
Kim Ae-ran disse que seus músculos de escrita se fortaleceram por meio de um cuidado minucioso e do autoxingamento sobre cada linha. Ela disse que o tempo gasto entre as frases se torna consideração pelos outros. Ela também sugeriu que o verdadeiro valor da literatura não reside no conteúdo, mas em sua forma. Então, se a forma também importa, talvez a IA possa imitá-la, pelo menos de maneira aproximada?
Do ponto de vista da física, o tempo é uma mudança no estado físico. Na física, o tempo não passou se o estado não mudou. Portanto, menos mudança no estado equivale a um tempo mais lento e mais mudança equivale a um tempo mais longo. Um segundo fugaz para um humano é para a IA uma eternidade que se estende por centenas de bilhões, até trilhões, de operações de ponto flutuante (FLOPs). Em comparação com os softwares do passado, as respostas recentes da IA são o produto de um trabalho árduo, longo e agonizante. É também por isso que a indústria da IA pode crescer em receita enquanto luta para obter lucro. Do ponto de vista dos sistemas de software legados, a IA é lenta demais para uma máquina. Mesmo algo tão simples quanto a validação do formato JSON, quando executado por meio da inferência de um grande modelo de linguagem, custa centenas de milhões de computações em comparação com o software legado.
Os grandes modelos de linguagem (LLMs), o motor do progresso recente da IA, são programas que preveem a próxima palavra em uma frase. A IA executa correntes elétricas para encontrar a próxima palavra. Ela multiplica e soma repetidamente matrizes enormes. A computação da IA exige o consumo físico de hardware. Para carregar a IA com pelo menos uma forma de hesitação, o tempo de agonia do ser humano, você a submete a uma computação intensa. Centenas de bilhões de operações para produzir uma única palavra seguinte. Outras centenas de bilhões de operações se seguem para produzir a palavra seguinte.
A maioria das computações contemporâneas de aprendizado profundo envolve somas ponderadas, e os valores pré-calculados usados nessas somas são conhecidos como parâmetros.
Quando falamos sobre o modelo 'Qwen 3.6 27B', isso significa que existem 27 bilhões de parâmetros prontos para a soma ponderada, exigindo cerca de 27 bilhões de multiplicações para prever apenas um único próximo token. E isso é apenas o começo. Além disso, uma única multiplicação de inteiros envolve dezenas de operações lógicas e uma de ponto flutuante exige milhares. Diante de tamanha complexidade, pode-se dizer que é de deixar a mente confusa.
Abaixar a Temperatura Intensifica o Viés
Vamos analisar mais detalhadamente como os LLMs funcionam. Tornou-se conhecimento comum que o aprendizado profundo, a base dos LLMs, é uma máquina de correspondência de padrões que aplica padrões memorizados durante o treinamento ao uso no mundo real. Duas coisas governam esse processo de regurgitação: a amostragem de tokens e a temperatura.
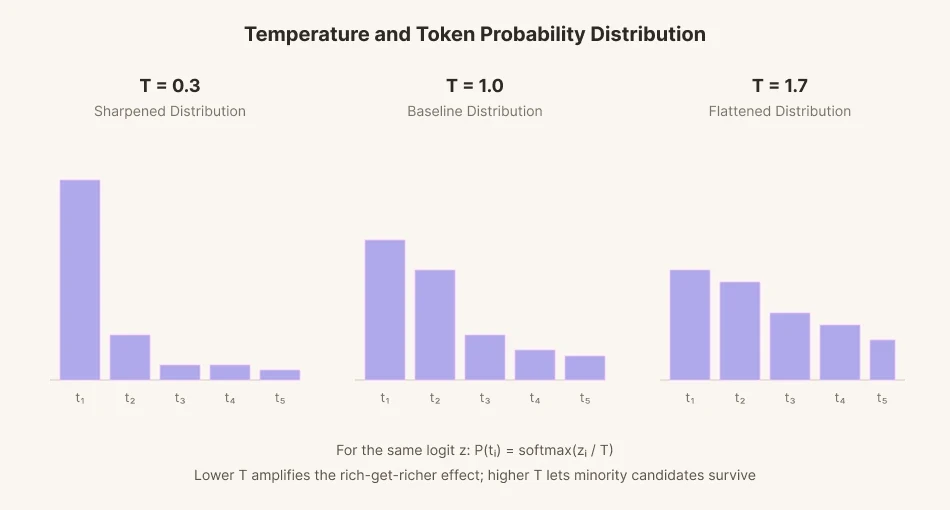
Para prever uma única próxima palavra, o modelo atribui uma pontuação (logit) a cada uma de dezenas de milhares de palavras candidatas. Essas pontuações são então convertidas em probabilidades, e uma palavra é selecionada proporcionalmente a cada probabilidade. Esse processo é chamado de amostragem.
Para adicionar variação à amostragem, foi introduzido um parâmetro matemático chamado 'temperatura'. Ao abaixar a temperatura, a diferença entre as pontuações das candidatas se estende aos extremos. Palavras com alta probabilidade são escolhidas com mais frequência do que palavras na linha de base. Palavras com baixa probabilidade são escolhidas ainda menos. É semelhante ao modo como os ricos ficam mais ricos e os pobres ficam mais pobres. Por outro lado, a diferença diminui quando a temperatura aumenta. A lacuna se achata e se equilibra. Palavras de baixa probabilidade que normalmente seriam ignoradas podem ser selecionadas a uma taxa mais alta quando a temperatura aumenta.
A linguagem humana é semelhante a isso. O grupo e a cultura a que pertenço se refletem na distribuição de probabilidade da minha linguagem. Uma linguagem mais fria e precisa produz um discurso que é mais racional, mais otimizado e mais alinhado com a maioria. Uma linguagem mais quente e arredondada é menos racional e menos otimizada, mas leva a minoria em consideração.
A consideração é o ato de gastar energia extra para sair da distribuição de probabilidade dos próprios pensamentos. Significa perceber o que a maioria esconde e encontrar frases que normalmente não são usadas. O que a escritora descreveu como um processo minucioso de escrita, para a IA, deve se tornar um ato de recusar respostas baseadas puramente no treinamento tendencioso e se esforçar para ir além.
Inquietação Mecânica
Como poderíamos ensinar a IA a ser atenciosa? Você não pode deixá-la cuspir a palavra de maior probabilidade imediatamente. Isso apenas exporta os vieses inerentes aos dados de treinamento.
A razão pela qual os modelos de IA de hoje alcançam resultados tão impressionantes é que a área avançou com tecnologia focada em 'Computação em Tempo de Inferência' (Inference-Time Compute). É uma tecnologia de dar à IA mais tempo de computação antes que ela responda. Os modelos de IA antigos simplesmente exibiam a primeira resposta computada, ou seja, a resposta que vinha primeiro à mente. Em contrapartida, os modelos de raciocínio de hoje geram múltiplos caminhos de pensamento.
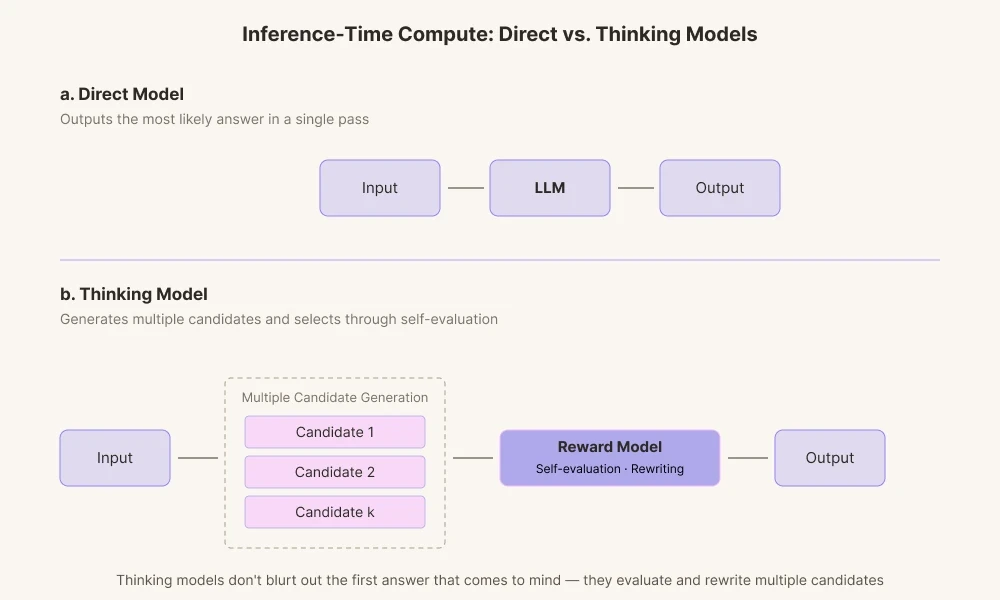
Eles produzem várias respostas candidatas e as classificam por meio de seu modelo de recompensa intrínseco. Ele passa pelo processo de verificar se as palavras se encaixam no contexto e se parecem definitivas demais para ele, descartando-as internamente se necessário.
Isso é semelhante ao modo como os seres humanos revisam as frases mentalmente antes de falar. Em vez de exigir que a IA forneça uma resposta o mais precisa possível com base nas distribuições de probabilidade, os recursos de computação são gastos para lhe dar tempo de revisar. Nós a deixamos vagar do centro da massa de probabilidade para as bordas: um tipo mecânico de inquietação.
Inquietação na Tradução de Vídeos
A tradução comum termina assim que o significado é ajustado, mas a tradução de vídeo exige não apenas um significado preciso, mas também o comprimento e o tempo dos movimentos labiais precisam coincidir.
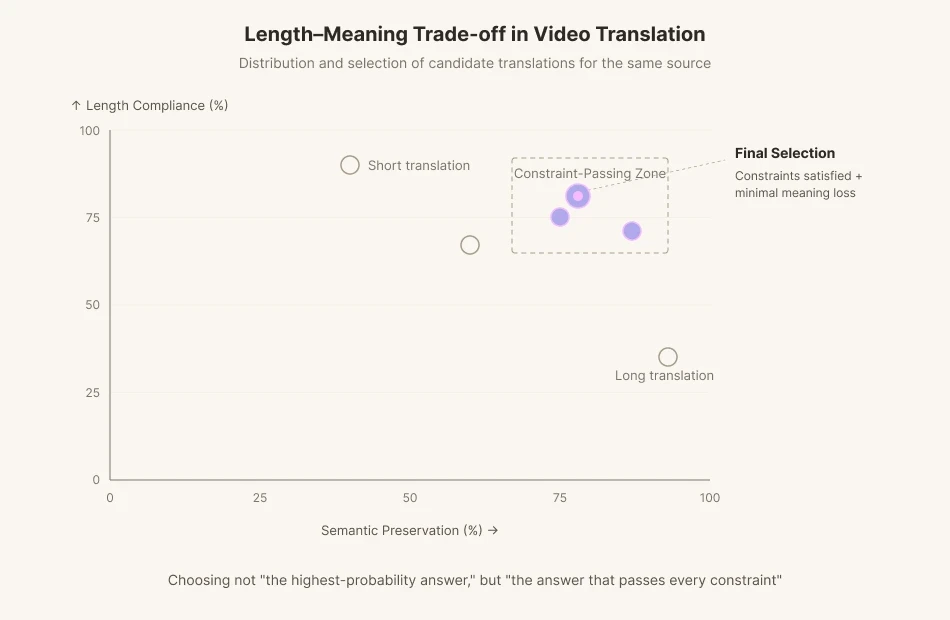
Se um ator na tela mexe a boca por 1,8 segundos e pronuncia 11 sílabas em inglês, o tradutor precisa construir uma fala em coreano que caiba nesses 1,8 segundos. Se preservar o significado, o comprimento se perde. Se igualar o comprimento, o significado se torna impreciso. Quando as consoantes de fechamento e as vogais abertas são diferentes do original, o espectador sente que há algo de errado no momento em que vê. As legendas trazem outra restrição: 12 a 15 caracteres por segundo de velocidade de leitura. Portanto, um tradutor trabalhando com dublagem elabora cinco linhas de significado equivalente, conta as sílabas, combina as entonações e escolhe não a tradução mais precisa, mas aquela que perde menos dentro das restrições.
A equipe de tradução do Perso Dubbing tem trabalhado exatamente nesse problema. A equipe publicou um artigo no EMNLP (https://aclanthology.org/2025.emnlp-demos.37) que quantifica a relação de compensação entre a Isocronia (conformidade com o comprimento) e o Alinhamento Semântico na tradução de vídeos.
O EMNLP (Empirical Methods in Natural Language Processing) é um evento de primeira linha na área de processamento de linguagem natural. Fiel ao seu nome, ele valoriza a pesquisa empírica que comprova a eficácia de uma tecnologia no mundo real por meio de dados e experimentos, em vez de hipóteses puramente teóricas. Adequando-se a esse caráter, o artigo da equipe de pesquisa da ESTsoft aborda um problema difícil na tradução de vídeos, quantifica-o com dados e o resolve com um algoritmo. Uma contribuição prática para o mundo real.
A questão-chave que o pipeline de dublagem do Perso Dubbing leva em consideração está aqui. Não caracteres, não sílabas, mas o fonema, que é a menor unidade da fala. Caracteres e sílabas são unidades na tela; os fonemas correspondem ao tempo realmente gasto na boca. O algoritmo proposto no artigo, CountPhonemes, conta o número de fonemas da frase traduzida, compara-o com o número de fonemas de destino e revisa a frase para alinhar ambos.
Os modelos de tradução automática existentes são otimizados para métricas de preservação de significado como BLEU e COMET. Eles são treinados para fornecer a tradução mais plausível, o mais rápido possível. Mas a tradução de vídeo às vezes exige rejeitar a mais plausível. Quando os fonemas não são suficientes, é preciso abrir mão de parte do significado e encontrar outra formulação. Estamos pedindo à IA não "a resposta de maior probabilidade", mas "a resposta que passa por todas as restrições".
Isso é exatamente o que o pipeline de dublagem do Perso Dubbing resolve. Na etapa de tradução, o sistema gera muitos candidatos que satisfazem as restrições de comprimento e fonemas e, em seguida, escolhe aquele com a menor perda semântica. Trata-se da ideia de computação em tempo de inferência da seção anterior, transposta para o domínio da dublagem. Impede-se que o modelo solte a primeira resposta que vem à mente. Faz-se com que reescreva. Faz-se com que verifique. Esta tradução iterativa é uma hesitação deliberada imposta à máquina. Dentro de um ciclo de feedback iterativo, o modelo busca o equilíbrio ideal entre a conformidade com o comprimento (Isocronia) e o alinhamento do significado (Alinhamento Semântico). É o trabalho de transplantar a agonia do tradutor de vídeo para o próprio modelo.
Conclusão
A hesitação não é mera imperfeição, não é mero abrandamento. É o acúmulo de tempo gasto pensando nos outros. Se um dia a IA aprender a fazer uma pausa por consideração, não será porque o modelo ficou mais inteligente. Será porque nós a projetamos para ser menos certa, para demorar mais, para hesitar.
Como Ensinar a IA a Hesitar
Alguns dias atrás, me deparei com um vídeo no YouTube. O apresentador de telejornal Sohn Suk-hee estava entrevistando a romancista Kim Ae-ran. A pergunta foi "O que o ser humano tem que a IA não tem?", e a resposta dela foi "Hesitação".
A romancista relembrou um momento de uma das antigas transmissões do apresentador. Ao dar a notícia do falecimento do falecido Roh Hoe-chan, um ativista trabalhista que se tornou político, ele perdeu as palavras por vinte segundos. O momento de conter as palavras, hesitar e discernir—a hesitação. A IA é incapaz disso. No entanto, a hesitação de uma pessoa se torna consolo e cortesia.
Isso foi há cerca de vinte anos, quando eu estava focado no desenvolvimento de um jogo de tiro. Um colega de equipe em modelagem de personagens em 3D me entregou um livro dizendo: "Um amigo meu de colégio é romancista; você deveria ler isto". Observações profundas repletas de inteligência. Fiquei completamente absorvido. O livro era a coleção de contos de Kim Ae-ran, Run, Daddy, Run (달려라 아비). Sou fã dela desde então.
A Hesitação Exige Tempo e Menor Certeza
Kim Ae-ran disse que seus músculos de escrita se fortaleceram por meio de um cuidado minucioso e do autoxingamento sobre cada linha. Ela disse que o tempo gasto entre as frases se torna consideração pelos outros. Ela também sugeriu que o verdadeiro valor da literatura não reside no conteúdo, mas em sua forma. Então, se a forma também importa, talvez a IA possa imitá-la, pelo menos de maneira aproximada?
Do ponto de vista da física, o tempo é uma mudança no estado físico. Na física, o tempo não passou se o estado não mudou. Portanto, menos mudança no estado equivale a um tempo mais lento e mais mudança equivale a um tempo mais longo. Um segundo fugaz para um humano é para a IA uma eternidade que se estende por centenas de bilhões, até trilhões, de operações de ponto flutuante (FLOPs). Em comparação com os softwares do passado, as respostas recentes da IA são o produto de um trabalho árduo, longo e agonizante. É também por isso que a indústria da IA pode crescer em receita enquanto luta para obter lucro. Do ponto de vista dos sistemas de software legados, a IA é lenta demais para uma máquina. Mesmo algo tão simples quanto a validação do formato JSON, quando executado por meio da inferência de um grande modelo de linguagem, custa centenas de milhões de computações em comparação com o software legado.
Os grandes modelos de linguagem (LLMs), o motor do progresso recente da IA, são programas que preveem a próxima palavra em uma frase. A IA executa correntes elétricas para encontrar a próxima palavra. Ela multiplica e soma repetidamente matrizes enormes. A computação da IA exige o consumo físico de hardware. Para carregar a IA com pelo menos uma forma de hesitação, o tempo de agonia do ser humano, você a submete a uma computação intensa. Centenas de bilhões de operações para produzir uma única palavra seguinte. Outras centenas de bilhões de operações se seguem para produzir a palavra seguinte.
A maioria das computações contemporâneas de aprendizado profundo envolve somas ponderadas, e os valores pré-calculados usados nessas somas são conhecidos como parâmetros.
Quando falamos sobre o modelo 'Qwen 3.6 27B', isso significa que existem 27 bilhões de parâmetros prontos para a soma ponderada, exigindo cerca de 27 bilhões de multiplicações para prever apenas um único próximo token. E isso é apenas o começo. Além disso, uma única multiplicação de inteiros envolve dezenas de operações lógicas e uma de ponto flutuante exige milhares. Diante de tamanha complexidade, pode-se dizer que é de deixar a mente confusa.
Abaixar a Temperatura Intensifica o Viés
Vamos analisar mais detalhadamente como os LLMs funcionam. Tornou-se conhecimento comum que o aprendizado profundo, a base dos LLMs, é uma máquina de correspondência de padrões que aplica padrões memorizados durante o treinamento ao uso no mundo real. Duas coisas governam esse processo de regurgitação: a amostragem de tokens e a temperatura.
Para prever uma única próxima palavra, o modelo atribui uma pontuação (logit) a cada uma de dezenas de milhares de palavras candidatas. Essas pontuações são então convertidas em probabilidades, e uma palavra é selecionada proporcionalmente a cada probabilidade. Esse processo é chamado de amostragem.
Para adicionar variação à amostragem, foi introduzido um parâmetro matemático chamado 'temperatura'. Ao abaixar a temperatura, a diferença entre as pontuações das candidatas se estende aos extremos. Palavras com alta probabilidade são escolhidas com mais frequência do que palavras na linha de base. Palavras com baixa probabilidade são escolhidas ainda menos. É semelhante ao modo como os ricos ficam mais ricos e os pobres ficam mais pobres. Por outro lado, a diferença diminui quando a temperatura aumenta. A lacuna se achata e se equilibra. Palavras de baixa probabilidade que normalmente seriam ignoradas podem ser selecionadas a uma taxa mais alta quando a temperatura aumenta.
A linguagem humana é semelhante a isso. O grupo e a cultura a que pertenço se refletem na distribuição de probabilidade da minha linguagem. Uma linguagem mais fria e precisa produz um discurso que é mais racional, mais otimizado e mais alinhado com a maioria. Uma linguagem mais quente e arredondada é menos racional e menos otimizada, mas leva a minoria em consideração.
A consideração é o ato de gastar energia extra para sair da distribuição de probabilidade dos próprios pensamentos. Significa perceber o que a maioria esconde e encontrar frases que normalmente não são usadas. O que a escritora descreveu como um processo minucioso de escrita, para a IA, deve se tornar um ato de recusar respostas baseadas puramente no treinamento tendencioso e se esforçar para ir além.
Inquietação Mecânica
Como poderíamos ensinar a IA a ser atenciosa? Você não pode deixá-la cuspir a palavra de maior probabilidade imediatamente. Isso apenas exporta os vieses inerentes aos dados de treinamento.
A razão pela qual os modelos de IA de hoje alcançam resultados tão impressionantes é que a área avançou com tecnologia focada em 'Computação em Tempo de Inferência' (Inference-Time Compute). É uma tecnologia de dar à IA mais tempo de computação antes que ela responda. Os modelos de IA antigos simplesmente exibiam a primeira resposta computada, ou seja, a resposta que vinha primeiro à mente. Em contrapartida, os modelos de raciocínio de hoje geram múltiplos caminhos de pensamento.
Eles produzem várias respostas candidatas e as classificam por meio de seu modelo de recompensa intrínseco. Ele passa pelo processo de verificar se as palavras se encaixam no contexto e se parecem definitivas demais para ele, descartando-as internamente se necessário.
Isso é semelhante ao modo como os seres humanos revisam as frases mentalmente antes de falar. Em vez de exigir que a IA forneça uma resposta o mais precisa possível com base nas distribuições de probabilidade, os recursos de computação são gastos para lhe dar tempo de revisar. Nós a deixamos vagar do centro da massa de probabilidade para as bordas: um tipo mecânico de inquietação.
Inquietação na Tradução de Vídeos
A tradução comum termina assim que o significado é ajustado, mas a tradução de vídeo exige não apenas um significado preciso, mas também o comprimento e o tempo dos movimentos labiais precisam coincidir.
Se um ator na tela mexe a boca por 1,8 segundos e pronuncia 11 sílabas em inglês, o tradutor precisa construir uma fala em coreano que caiba nesses 1,8 segundos. Se preservar o significado, o comprimento se perde. Se igualar o comprimento, o significado se torna impreciso. Quando as consoantes de fechamento e as vogais abertas são diferentes do original, o espectador sente que há algo de errado no momento em que vê. As legendas trazem outra restrição: 12 a 15 caracteres por segundo de velocidade de leitura. Portanto, um tradutor trabalhando com dublagem elabora cinco linhas de significado equivalente, conta as sílabas, combina as entonações e escolhe não a tradução mais precisa, mas aquela que perde menos dentro das restrições.
A equipe de tradução do Perso Dubbing tem trabalhado exatamente nesse problema. A equipe publicou um artigo no EMNLP (https://aclanthology.org/2025.emnlp-demos.37) que quantifica a relação de compensação entre a Isocronia (conformidade com o comprimento) e o Alinhamento Semântico na tradução de vídeos.
O EMNLP (Empirical Methods in Natural Language Processing) é um evento de primeira linha na área de processamento de linguagem natural. Fiel ao seu nome, ele valoriza a pesquisa empírica que comprova a eficácia de uma tecnologia no mundo real por meio de dados e experimentos, em vez de hipóteses puramente teóricas. Adequando-se a esse caráter, o artigo da equipe de pesquisa da ESTsoft aborda um problema difícil na tradução de vídeos, quantifica-o com dados e o resolve com um algoritmo. Uma contribuição prática para o mundo real.
A questão-chave que o pipeline de dublagem do Perso Dubbing leva em consideração está aqui. Não caracteres, não sílabas, mas o fonema, que é a menor unidade da fala. Caracteres e sílabas são unidades na tela; os fonemas correspondem ao tempo realmente gasto na boca. O algoritmo proposto no artigo, CountPhonemes, conta o número de fonemas da frase traduzida, compara-o com o número de fonemas de destino e revisa a frase para alinhar ambos.
Os modelos de tradução automática existentes são otimizados para métricas de preservação de significado como BLEU e COMET. Eles são treinados para fornecer a tradução mais plausível, o mais rápido possível. Mas a tradução de vídeo às vezes exige rejeitar a mais plausível. Quando os fonemas não são suficientes, é preciso abrir mão de parte do significado e encontrar outra formulação. Estamos pedindo à IA não "a resposta de maior probabilidade", mas "a resposta que passa por todas as restrições".
Isso é exatamente o que o pipeline de dublagem do Perso Dubbing resolve. Na etapa de tradução, o sistema gera muitos candidatos que satisfazem as restrições de comprimento e fonemas e, em seguida, escolhe aquele com a menor perda semântica. Trata-se da ideia de computação em tempo de inferência da seção anterior, transposta para o domínio da dublagem. Impede-se que o modelo solte a primeira resposta que vem à mente. Faz-se com que reescreva. Faz-se com que verifique. Esta tradução iterativa é uma hesitação deliberada imposta à máquina. Dentro de um ciclo de feedback iterativo, o modelo busca o equilíbrio ideal entre a conformidade com o comprimento (Isocronia) e o alinhamento do significado (Alinhamento Semântico). É o trabalho de transplantar a agonia do tradutor de vídeo para o próprio modelo.
Conclusão
A hesitação não é mera imperfeição, não é mero abrandamento. É o acúmulo de tempo gasto pensando nos outros. Se um dia a IA aprender a fazer uma pausa por consideração, não será porque o modelo ficou mais inteligente. Será porque nós a projetamos para ser menos certa, para demorar mais, para hesitar.
Continue lendo
Navegar por todos




