Wie man KI das Zögern beibringt: Inferenzzeit-Computing und die Kunst der wohlüberlegten Übersetzung


Jump to section
Jump to section
Teilen
Teilen
Teilen

AI Video-Übersetzer, Lokalisierung und Synchronisationswerkzeug
Probieren Sie es kostenlos aus
Wie man einer KI das Zögern beibringt
Vor ein paar Tagen stieß ich auf einen YouTube-Clip. Der Nachrichtensprecher Sohn Suk-hee interviewte die Schriftstellerin Kim Ae-ran. Die Frage lautete: „Was hat ein Mensch, was eine KI nicht hat?“, und ihre Antwort war: „Das Zögern.“
Die Schriftstellerin erinnerte an einen Moment aus einer alten Sendung des Sprechers. Als er die Nachricht vom Tod des verstorbenen Roh Hoe-chan, eines Gewerkschaftsaktivisten und Politikers, verkündete, verlor er für zwanzig Sekunden die Worte. Der Moment des Innehaltens, des Abwägens und des Unterscheidens – das Zögern. Eine KI ist dazu nicht in der Lage. Doch das Zögern eines Menschen wird zu Trost und Höflichkeit.
Es ist etwa zwanzig Jahre her, als ich mich auf die Entwicklung eines Ballerspiels konzentrierte. Ein Teamkollege aus der 3D-Charaktermodellierung drückte mir ein Buch in die Hand und sagte: „Ein Highschool-Freund von mir ist Schriftsteller, das solltest du lesen.“ Tiefe Beobachtungen, gepaart mit Witz. Ich war völlig gefesselt. Das Buch war Kim Ae-rans Kurzgeschichten-Sammlung Run, Daddy, Run (달려라 아비). Seitdem bin ich ein Fan von ihr.
Zögern erfordert Zeit und geringere Gewissheit
Kim Ae-ran sagte, dass sich ihre Schreibmuskeln durch akribische Sorgfalt und das Hinterfragen jeder einzelnen Zeile gestärkt haben. Sie sagte, dass die Zeit, die zwischen den Sätzen vergeht, zur Rücksichtnahme auf die anderen wird. Sie deutete auch an, dass der wahre Wert der Literatur nicht im Inhalt, sondern in ihrer Form liegt. Wenn also auch die Form eine Rolle spielt, kann die KI sie dann nicht zumindest ansatzweise imitieren?
Aus physikalischer Sicht ist Zeit eine Veränderung des physikalischen Zustands. In der Physik ist keine Zeit vergangen, wenn sich der Zustand nicht verändert hat. Weniger Zustandsänderung entspricht also einer langsameren Zeit und mehr Änderung einer längeren Zeit. Eine flüchtige Sekunde für einen Menschen ist für eine KI eine Ewigkeit, die sich über Hunderte von Milliarden oder sogar Billionen von Gleitkommaoperationen (FLOPs) erstreckt. Im Vergleich zu früherer Software sind die Antworten heutiger KI das Produkt langer, mühsamer Arbeit. Dies ist auch der Grund, warum die KI-Branche zwar umsatzmäßig wachsen kann, aber mit den Gewinnen kämpft. Aus der Sicht herkömmlicher Software ist KI viel zu langsam für eine Maschine. Selbst so etwas Einfaches wie die Validierung des JSON-Formats kostet bei der Ausführung über ein großes Sprachmodell im Vergleich zu herkömmlicher Software hunderte Millionen Rechenschritte.
Große Sprachmodelle (LLMs), der Motor des jüngsten KI-Fortschritts, sind Programme, die das nächste Wort in einem Satz vorhersagen. Die KI lässt elektrischen Strom fließen, um das nächste Wort zu finden. Sie multipliziert und addiert wiederholt riesige Matrizen. Die Berechnung der KI erfordert den physischen Verbrauch von Hardware. Um der KI zumindest eine Form des Zögerns – die Zeit der menschlichen Qual – beizubringen, schickt man sie durch intensive Berechnungen. Hunderte Milliarden von Operationen, um ein einziges nächstes Wort zu erzeugen. Weitere Hunderte Milliarden von Operationen folgen, um das darauffolgende Wort zu erzeugen.
Die Mehrheit der heutigen Deep-Learning-Berechnungen beinhaltet gewichtete Summen, und die in diesen Summen verwendeten vorberechneten Werte werden als Parameter bezeichnet.
Wenn wir vom Modell „Qwen 3.6 27B“ sprechen, bedeutet dies, dass 27 Milliarden Parameter für die Gewichtungssumme bereitstehen, was etwa 27 Milliarden Multiplikationen erfordert, um nur ein einziges nächstes Token vorherzusagen. Und das ist erst der Anfang. Rechnet man hinzu, dass eine einzelne Ganzzahl-Multiplikation Dutzende von logischen Operationen erfordert und eine Gleitkomma-Multiplikation Tausende, so kann man dies angesichts einer solchen Komplexität getrost als schwindelerregend bezeichnen.
Das Senken der Temperatur schärft den Bias
Lassen Sie uns genauer betrachten, wie LLMs funktionieren. Es ist mittlerweile allgemein bekannt, dass Deep Learning, das Fundament von LLMs, eine Mustererkennungsmaschine ist, die während des Trainings gelernte Muster auf die reale Praxis anwendet. Zwei Dinge steuern diesen Prozess des Wiedergebens: Token-Sampling und Temperatur.
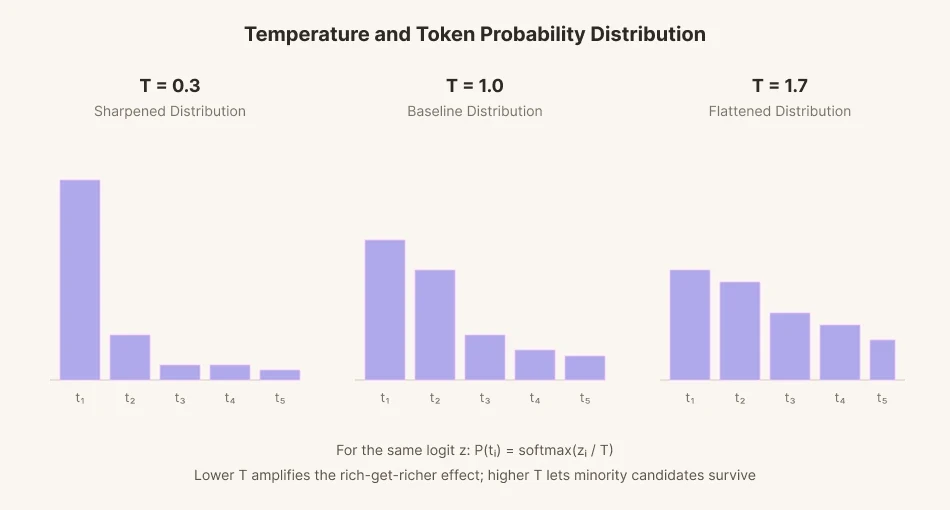
Um ein einziges nächstes Wort vorherzusagen, weist das Modell jedem von Zehntausenden von Kandidatenwörtern eine Punktzahl (Logit) zu. Diese Punktzahlen werden dann in Wahrscheinlichkeiten umgewandelt, und ein Wort wird im Verhältnis zu jeder Wahrscheinlichkeit ausgewählt. Dieser Prozess wird als Sampling bezeichnet.
Um das Sampling zu variieren, wurde ein mathematischer Parameter namens „Temperatur“ eingeführt. Senkt man die Temperatur, vergrößert sich der Abstand zwischen den Kandidaten-Scores ins Extreme. Wörter mit hoher Wahrscheinlichkeit werden viel häufiger gewählt als Wörter an der Baseline. Wörter mit geringer Wahrscheinlichkeit werden noch seltener gewählt. Das ist so ähnlich wie „Wer hat, dem wird gegeben“. Umgekehrt verringert sich der Abstand, wenn die Temperatur steigt. Der Abstand flacht ab und gleicht sich aus. Wörter mit geringer Wahrscheinlichkeit, die normalerweise übergangen worden wären, können bei steigender Temperatur mit einer höheren Rate ausgewählt werden.
Die menschliche Sprache verhält sich ähnlich. Die Gruppe und die Kultur, der ich angehöre, spiegeln sich in der Wahrscheinlichkeitsverteilung meiner Sprache wider. Eine kältere, schärfere Sprache bringt Reden hervor, die rationaler, optimierter und mehr im Einklang mit der Mehrheit sind. Eine wärmere, rundere Sprache ist weniger rational und weniger optimiert, berücksichtigt aber die Minderheit.
Rücksichtnahme ist der Akt, zusätzliche Energie aufzuwenden, um aus der Wahrscheinlichkeitsverteilung der eigenen Gedanken herauszutreten. Es bedeutet, zu bemerken, was die Mehrheit ausblendet, und Sätze zu finden, die normalerweise nicht verwendet werden. Was die Autorin als mühsamen Schreibprozess beschrieb, sollte für die KI zu einem Akt werden, Antworten zu verweigern, die ausschließlich auf voreingenommenem Training basieren, und sich zu bemühen, darüber hinauszugehen.
Mechanisches Grübeln
Wie könnten wir einer KI beibringen, rücksichtsvoll zu sein? Man darf sie das Wort mit der höchsten Wahrscheinlichkeit nicht sofort ausspucken lassen. Das exportiert nur die im Trainingsdatenbestand verankerten Vorurteile.
Der Grund, warum heutige KI-Modelle so verblüffende Ergebnisse erzielen, liegt darin, dass die Technologie im Bereich des „Inference-Time Compute“ (Rechenzeit bei der Inferenz) fortgeschritten ist. Es ist eine Technologie, die der KI mehr Rechenzeit einräumt, bevor sie antwortet. Frühere KI-Modelle gaben einfach die erste berechnete Antwort aus, also die Antwort, die ihnen als Erstes in den Sinn kam. Im Gegensatz dazu generieren die heutigen Denkmodelle mehrere Denkpfade.
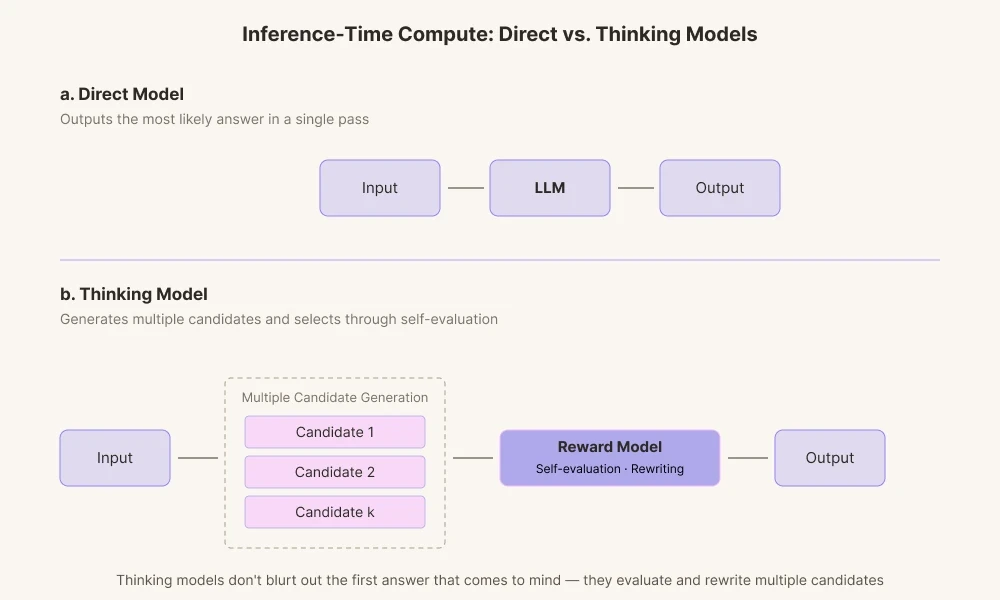
Sie generieren verschiedene Antwortkandidaten und bewerten sie durch ihr internes Belohnungsmodell. Sie prüfen, ob die Wörter in den Kontext passen und ob sie zu endgültig wirken, und verwerfen sie gegebenenfalls intern.
Dies ähnelt der Art und Weise, wie Menschen Sätze im Kopf überarbeiten, bevor sie sprechen. Anstatt von der KI eine möglichst genaue Antwort auf der Grundlage von Wahrscheinlichkeitsverteilungen zu verlangen, werden Rechenressourcen aufgewendet, um ihr Zeit für die Überarbeitung zu geben. Wir lassen sie aus dem Zentrum der Wahrscheinlichkeitsmasse an die Ränder wandern: eine Art mechanisches Grübeln.
Grübeln bei der Videoübersetzung
Eine gewöhnliche Übersetzung ist abgeschlossen, sobald die Bedeutung stimmt. Bei einer Videoübersetzung muss jedoch nicht nur die Bedeutung korrekt sein, sondern auch die Länge und das Timing der Lippenbewegungen müssen übereinstimmen.
Wenn ein Schauspieler auf dem Bildschirm 1,8 Sekunden lang den Mund bewegt und 11 englische Silben spricht, muss der Übersetzer einen koreanischen Satz bauen, der in diese 1,8 Sekunden passt. Bewahrt man die Bedeutung, bricht die Länge. Passt man die Länge an, verschwimmt die Bedeutung. Wenn sich die schließenden Konsonanten und offenen Vokale vom Original unterscheiden, spürt der Zuschauer im selben Moment, in dem er es sieht, dass etwas nicht stimmt. Untertitel bringen eine weitere Einschränkung mit sich: 12 bis 15 Zeichen pro Sekunde Lesegeschwindigkeit. Ein Übersetzer, der mit Synchronisation arbeitet, entwirft also fünf Zeilen mit gleicher Bedeutung, zählt Silben, gleicht Betonungen ab und wählt nicht die korrekteste Übersetzung, sondern diejenige, die innerhalb der Einschränkungen am wenigsten verliert.
Das Übersetzungsteam von Perso Dubbing hat genau an diesem Problem gearbeitet. Das Team hat auf der EMNLP ein Paper veröffentlicht (https://aclanthology.org/2025.emnlp-demos.37), das den Kompromiss zwischen Isochronie (Einhaltung der Länge) und semantischer Ausrichtung bei der Videoübersetzung quantifiziert.
Die EMNLP (Empirical Methods in Natural Language Processing) ist eine der führenden Konferenzen im Bereich der natürlichen Sprachverarbeitung. Getreu ihrem Namen schätzt sie empirische Forschung, die die Wirksamkeit einer Technologie in der Praxis durch Daten und Experimente beweist, anstatt sich auf rein theoretische Hypothesen zu stützen. Passend zu diesem Charakter greift das Paper des ESTsoft-Forschungsteams ein schwieriges Problem der Videoübersetzung auf, quantifiziert es mit Daten und löst es mit einem Algorithmus. Ein praktischer Beitrag für die reale Welt.
Die Kernfrage, die die Synchronisations-Pipeline von Perso Dubbing berücksichtigt, liegt hier. Nicht Zeichen, nicht Silben, sondern das Phonem, die kleinste Einheit der Sprache. Zeichen und Silben sind Einheiten auf dem Bildschirm; Phoneme entsprechen der Zeit, die tatsächlich im Mund verbracht wird. Der in dem Paper vorgeschlagene Algorithmus, CountPhonemes, zählt die Phonemanzahl des übersetzten Satzes, vergleicht sie mit der Ziel-Phonemanzahl und überarbeitet den Satz, um beide in Einklang zu bringen.
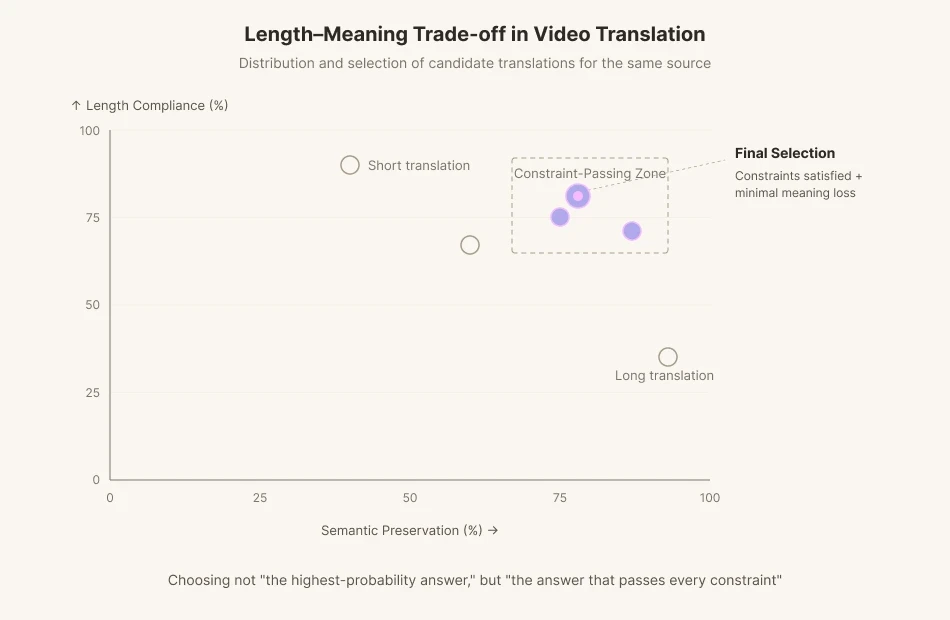
Bestehende maschinelle Übersetzungsmodelle sind für Metriken zur Erhaltung der Bedeutung wie BLEU und COMET optimiert. Sie sind darauf trainiert, so schnell wie möglich die plausibelste Übersetzung zu liefern. Bei der Videoübersetzung muss die plausibelste Übersetzung jedoch manchmal abgelehnt werden. Wenn Phoneme fehlen, muss man auf einen Teil der Bedeutung verzichten und eine andere Formulierung finden. Wir fragen die KI nicht nach „der Antwort mit der höchsten Wahrscheinlichkeit“, sondern nach „der Antwort, die jede Einschränkung erfüllt“.
Genau das löst die Synchronisations-Pipeline von Perso Dubbing. Im Übersetzungsschritt generiert das System viele Kandidaten, die die Längen- und Phonemeinschränkungen erfüllen, und wählt dann denjenigen mit dem geringsten semantischen Verlust. Es ist die Idee des Inference-Time Compute aus dem vorherigen Abschnitt, übertragen auf den Synchronisationsbereich. Hindern Sie das Modell daran, die erste Antwort auszuspucken, die ihm in den Sinn kommt. Lassen Sie es neu schreiben. Lassen Sie es verifizieren. Diese iterative Übersetzung ist ein bewusstes Zögern, das der Maschine auferlegt wird. Innerhalb einer iterativen Feedbackschleife sucht das Modell nach dem Optimum zwischen Längeneinhaltung (Isochronie) und Bedeutungsabgleich (semantische Ausrichtung). Es ist die Arbeit, das Grübeln des Videoübersetzers in das Modell selbst zu verpflanzen.
Schlusswort
Zögern ist nicht bloße Unvollkommenheit, nicht bloße Verlangsamung. Es ist die Ansammlung von Zeit, die man mit der Rücksichtnahme auf andere verbringt. Wenn die KI jemals lernt, um der Rücksichtnahme willen innezuhalten, dann nicht, weil das Modell klüger geworden ist. Sondern weil wir es so konzipiert haben, dass es sich weniger sicher ist, länger verweilt, zögert.
Wie man einer KI das Zögern beibringt
Vor ein paar Tagen stieß ich auf einen YouTube-Clip. Der Nachrichtensprecher Sohn Suk-hee interviewte die Schriftstellerin Kim Ae-ran. Die Frage lautete: „Was hat ein Mensch, was eine KI nicht hat?“, und ihre Antwort war: „Das Zögern.“
Die Schriftstellerin erinnerte an einen Moment aus einer alten Sendung des Sprechers. Als er die Nachricht vom Tod des verstorbenen Roh Hoe-chan, eines Gewerkschaftsaktivisten und Politikers, verkündete, verlor er für zwanzig Sekunden die Worte. Der Moment des Innehaltens, des Abwägens und des Unterscheidens – das Zögern. Eine KI ist dazu nicht in der Lage. Doch das Zögern eines Menschen wird zu Trost und Höflichkeit.
Es ist etwa zwanzig Jahre her, als ich mich auf die Entwicklung eines Ballerspiels konzentrierte. Ein Teamkollege aus der 3D-Charaktermodellierung drückte mir ein Buch in die Hand und sagte: „Ein Highschool-Freund von mir ist Schriftsteller, das solltest du lesen.“ Tiefe Beobachtungen, gepaart mit Witz. Ich war völlig gefesselt. Das Buch war Kim Ae-rans Kurzgeschichten-Sammlung Run, Daddy, Run (달려라 아비). Seitdem bin ich ein Fan von ihr.
Zögern erfordert Zeit und geringere Gewissheit
Kim Ae-ran sagte, dass sich ihre Schreibmuskeln durch akribische Sorgfalt und das Hinterfragen jeder einzelnen Zeile gestärkt haben. Sie sagte, dass die Zeit, die zwischen den Sätzen vergeht, zur Rücksichtnahme auf die anderen wird. Sie deutete auch an, dass der wahre Wert der Literatur nicht im Inhalt, sondern in ihrer Form liegt. Wenn also auch die Form eine Rolle spielt, kann die KI sie dann nicht zumindest ansatzweise imitieren?
Aus physikalischer Sicht ist Zeit eine Veränderung des physikalischen Zustands. In der Physik ist keine Zeit vergangen, wenn sich der Zustand nicht verändert hat. Weniger Zustandsänderung entspricht also einer langsameren Zeit und mehr Änderung einer längeren Zeit. Eine flüchtige Sekunde für einen Menschen ist für eine KI eine Ewigkeit, die sich über Hunderte von Milliarden oder sogar Billionen von Gleitkommaoperationen (FLOPs) erstreckt. Im Vergleich zu früherer Software sind die Antworten heutiger KI das Produkt langer, mühsamer Arbeit. Dies ist auch der Grund, warum die KI-Branche zwar umsatzmäßig wachsen kann, aber mit den Gewinnen kämpft. Aus der Sicht herkömmlicher Software ist KI viel zu langsam für eine Maschine. Selbst so etwas Einfaches wie die Validierung des JSON-Formats kostet bei der Ausführung über ein großes Sprachmodell im Vergleich zu herkömmlicher Software hunderte Millionen Rechenschritte.
Große Sprachmodelle (LLMs), der Motor des jüngsten KI-Fortschritts, sind Programme, die das nächste Wort in einem Satz vorhersagen. Die KI lässt elektrischen Strom fließen, um das nächste Wort zu finden. Sie multipliziert und addiert wiederholt riesige Matrizen. Die Berechnung der KI erfordert den physischen Verbrauch von Hardware. Um der KI zumindest eine Form des Zögerns – die Zeit der menschlichen Qual – beizubringen, schickt man sie durch intensive Berechnungen. Hunderte Milliarden von Operationen, um ein einziges nächstes Wort zu erzeugen. Weitere Hunderte Milliarden von Operationen folgen, um das darauffolgende Wort zu erzeugen.
Die Mehrheit der heutigen Deep-Learning-Berechnungen beinhaltet gewichtete Summen, und die in diesen Summen verwendeten vorberechneten Werte werden als Parameter bezeichnet.
Wenn wir vom Modell „Qwen 3.6 27B“ sprechen, bedeutet dies, dass 27 Milliarden Parameter für die Gewichtungssumme bereitstehen, was etwa 27 Milliarden Multiplikationen erfordert, um nur ein einziges nächstes Token vorherzusagen. Und das ist erst der Anfang. Rechnet man hinzu, dass eine einzelne Ganzzahl-Multiplikation Dutzende von logischen Operationen erfordert und eine Gleitkomma-Multiplikation Tausende, so kann man dies angesichts einer solchen Komplexität getrost als schwindelerregend bezeichnen.
Das Senken der Temperatur schärft den Bias
Lassen Sie uns genauer betrachten, wie LLMs funktionieren. Es ist mittlerweile allgemein bekannt, dass Deep Learning, das Fundament von LLMs, eine Mustererkennungsmaschine ist, die während des Trainings gelernte Muster auf die reale Praxis anwendet. Zwei Dinge steuern diesen Prozess des Wiedergebens: Token-Sampling und Temperatur.
Um ein einziges nächstes Wort vorherzusagen, weist das Modell jedem von Zehntausenden von Kandidatenwörtern eine Punktzahl (Logit) zu. Diese Punktzahlen werden dann in Wahrscheinlichkeiten umgewandelt, und ein Wort wird im Verhältnis zu jeder Wahrscheinlichkeit ausgewählt. Dieser Prozess wird als Sampling bezeichnet.
Um das Sampling zu variieren, wurde ein mathematischer Parameter namens „Temperatur“ eingeführt. Senkt man die Temperatur, vergrößert sich der Abstand zwischen den Kandidaten-Scores ins Extreme. Wörter mit hoher Wahrscheinlichkeit werden viel häufiger gewählt als Wörter an der Baseline. Wörter mit geringer Wahrscheinlichkeit werden noch seltener gewählt. Das ist so ähnlich wie „Wer hat, dem wird gegeben“. Umgekehrt verringert sich der Abstand, wenn die Temperatur steigt. Der Abstand flacht ab und gleicht sich aus. Wörter mit geringer Wahrscheinlichkeit, die normalerweise übergangen worden wären, können bei steigender Temperatur mit einer höheren Rate ausgewählt werden.
Die menschliche Sprache verhält sich ähnlich. Die Gruppe und die Kultur, der ich angehöre, spiegeln sich in der Wahrscheinlichkeitsverteilung meiner Sprache wider. Eine kältere, schärfere Sprache bringt Reden hervor, die rationaler, optimierter und mehr im Einklang mit der Mehrheit sind. Eine wärmere, rundere Sprache ist weniger rational und weniger optimiert, berücksichtigt aber die Minderheit.
Rücksichtnahme ist der Akt, zusätzliche Energie aufzuwenden, um aus der Wahrscheinlichkeitsverteilung der eigenen Gedanken herauszutreten. Es bedeutet, zu bemerken, was die Mehrheit ausblendet, und Sätze zu finden, die normalerweise nicht verwendet werden. Was die Autorin als mühsamen Schreibprozess beschrieb, sollte für die KI zu einem Akt werden, Antworten zu verweigern, die ausschließlich auf voreingenommenem Training basieren, und sich zu bemühen, darüber hinauszugehen.
Mechanisches Grübeln
Wie könnten wir einer KI beibringen, rücksichtsvoll zu sein? Man darf sie das Wort mit der höchsten Wahrscheinlichkeit nicht sofort ausspucken lassen. Das exportiert nur die im Trainingsdatenbestand verankerten Vorurteile.
Der Grund, warum heutige KI-Modelle so verblüffende Ergebnisse erzielen, liegt darin, dass die Technologie im Bereich des „Inference-Time Compute“ (Rechenzeit bei der Inferenz) fortgeschritten ist. Es ist eine Technologie, die der KI mehr Rechenzeit einräumt, bevor sie antwortet. Frühere KI-Modelle gaben einfach die erste berechnete Antwort aus, also die Antwort, die ihnen als Erstes in den Sinn kam. Im Gegensatz dazu generieren die heutigen Denkmodelle mehrere Denkpfade.
Sie generieren verschiedene Antwortkandidaten und bewerten sie durch ihr internes Belohnungsmodell. Sie prüfen, ob die Wörter in den Kontext passen und ob sie zu endgültig wirken, und verwerfen sie gegebenenfalls intern.
Dies ähnelt der Art und Weise, wie Menschen Sätze im Kopf überarbeiten, bevor sie sprechen. Anstatt von der KI eine möglichst genaue Antwort auf der Grundlage von Wahrscheinlichkeitsverteilungen zu verlangen, werden Rechenressourcen aufgewendet, um ihr Zeit für die Überarbeitung zu geben. Wir lassen sie aus dem Zentrum der Wahrscheinlichkeitsmasse an die Ränder wandern: eine Art mechanisches Grübeln.
Grübeln bei der Videoübersetzung
Eine gewöhnliche Übersetzung ist abgeschlossen, sobald die Bedeutung stimmt. Bei einer Videoübersetzung muss jedoch nicht nur die Bedeutung korrekt sein, sondern auch die Länge und das Timing der Lippenbewegungen müssen übereinstimmen.
Wenn ein Schauspieler auf dem Bildschirm 1,8 Sekunden lang den Mund bewegt und 11 englische Silben spricht, muss der Übersetzer einen koreanischen Satz bauen, der in diese 1,8 Sekunden passt. Bewahrt man die Bedeutung, bricht die Länge. Passt man die Länge an, verschwimmt die Bedeutung. Wenn sich die schließenden Konsonanten und offenen Vokale vom Original unterscheiden, spürt der Zuschauer im selben Moment, in dem er es sieht, dass etwas nicht stimmt. Untertitel bringen eine weitere Einschränkung mit sich: 12 bis 15 Zeichen pro Sekunde Lesegeschwindigkeit. Ein Übersetzer, der mit Synchronisation arbeitet, entwirft also fünf Zeilen mit gleicher Bedeutung, zählt Silben, gleicht Betonungen ab und wählt nicht die korrekteste Übersetzung, sondern diejenige, die innerhalb der Einschränkungen am wenigsten verliert.
Das Übersetzungsteam von Perso Dubbing hat genau an diesem Problem gearbeitet. Das Team hat auf der EMNLP ein Paper veröffentlicht (https://aclanthology.org/2025.emnlp-demos.37), das den Kompromiss zwischen Isochronie (Einhaltung der Länge) und semantischer Ausrichtung bei der Videoübersetzung quantifiziert.
Die EMNLP (Empirical Methods in Natural Language Processing) ist eine der führenden Konferenzen im Bereich der natürlichen Sprachverarbeitung. Getreu ihrem Namen schätzt sie empirische Forschung, die die Wirksamkeit einer Technologie in der Praxis durch Daten und Experimente beweist, anstatt sich auf rein theoretische Hypothesen zu stützen. Passend zu diesem Charakter greift das Paper des ESTsoft-Forschungsteams ein schwieriges Problem der Videoübersetzung auf, quantifiziert es mit Daten und löst es mit einem Algorithmus. Ein praktischer Beitrag für die reale Welt.
Die Kernfrage, die die Synchronisations-Pipeline von Perso Dubbing berücksichtigt, liegt hier. Nicht Zeichen, nicht Silben, sondern das Phonem, die kleinste Einheit der Sprache. Zeichen und Silben sind Einheiten auf dem Bildschirm; Phoneme entsprechen der Zeit, die tatsächlich im Mund verbracht wird. Der in dem Paper vorgeschlagene Algorithmus, CountPhonemes, zählt die Phonemanzahl des übersetzten Satzes, vergleicht sie mit der Ziel-Phonemanzahl und überarbeitet den Satz, um beide in Einklang zu bringen.
Bestehende maschinelle Übersetzungsmodelle sind für Metriken zur Erhaltung der Bedeutung wie BLEU und COMET optimiert. Sie sind darauf trainiert, so schnell wie möglich die plausibelste Übersetzung zu liefern. Bei der Videoübersetzung muss die plausibelste Übersetzung jedoch manchmal abgelehnt werden. Wenn Phoneme fehlen, muss man auf einen Teil der Bedeutung verzichten und eine andere Formulierung finden. Wir fragen die KI nicht nach „der Antwort mit der höchsten Wahrscheinlichkeit“, sondern nach „der Antwort, die jede Einschränkung erfüllt“.
Genau das löst die Synchronisations-Pipeline von Perso Dubbing. Im Übersetzungsschritt generiert das System viele Kandidaten, die die Längen- und Phonemeinschränkungen erfüllen, und wählt dann denjenigen mit dem geringsten semantischen Verlust. Es ist die Idee des Inference-Time Compute aus dem vorherigen Abschnitt, übertragen auf den Synchronisationsbereich. Hindern Sie das Modell daran, die erste Antwort auszuspucken, die ihm in den Sinn kommt. Lassen Sie es neu schreiben. Lassen Sie es verifizieren. Diese iterative Übersetzung ist ein bewusstes Zögern, das der Maschine auferlegt wird. Innerhalb einer iterativen Feedbackschleife sucht das Modell nach dem Optimum zwischen Längeneinhaltung (Isochronie) und Bedeutungsabgleich (semantische Ausrichtung). Es ist die Arbeit, das Grübeln des Videoübersetzers in das Modell selbst zu verpflanzen.
Schlusswort
Zögern ist nicht bloße Unvollkommenheit, nicht bloße Verlangsamung. Es ist die Ansammlung von Zeit, die man mit der Rücksichtnahme auf andere verbringt. Wenn die KI jemals lernt, um der Rücksichtnahme willen innezuhalten, dann nicht, weil das Modell klüger geworden ist. Sondern weil wir es so konzipiert haben, dass es sich weniger sicher ist, länger verweilt, zögert.
Weiterlesen
Alle durchsuchen




