Dubbing AI vs Kloning Suara vs Avatar: Model 4-Lapisan


Lompat ke bagian
Lompat ke bagian
Bagikan
Bagikan
Bagikan

Alat Penerjemah Video AI, Lokalisasi, dan Dubbing
Coba secara Gratis
AI Dubbing vs Voice Cloning vs Avatar: Model 4-Lapisan AI Media
Jawaban singkat. AI dubbing, voice cloning, pembuatan avatar, dan penerjemahan teks termasuk dalam empat lapisan yang berbeda dari tumpukan media AI. AI dubbing berada di Lapisan 4 — lapisan distribusi — tempat video yang sudah selesai melintasi batas bahasa. Voice cloning (Lapisan 1) dan pembuatan avatar (Lapisan 2) menghasilkan aset. Penerjemahan teks (Lapisan 3) berada dalam jalur pra-distribusi. Kerangka kerja ini menjelaskan mengapa ElevenLabs, HeyGen, Synthesia, dan Perso Dubbing menyelesaikan masalah yang mendasarinya secara berbeda.
Apa itu AI dubbing? Sebuah definisi tahun 2026

| 96% video hasil dubbing dikirimkan pada hari yang sama. Sidik jari perilaku dari Lapisan 4.
AI dubbing adalah alur kerja yang mengambil video dalam satu bahasa dan menghasilkan video dalam bahasa lain yang siap didistribusikan. Inputnya adalah video yang sudah selesai. Outputnya adalah video yang sudah selesai. Hanya lapisan bahasanya yang diganti.
Definisi tersebut penting karena liputan umum sering kali mengelompokkan AI dubbing dengan alat voice cloning seperti ElevenLabs atau pembuat avatar seperti HeyGen. Mereka berbagi infrastruktur AI yang sama, tetapi mereka menyelesaikan masalah yang berbeda pada berbagai tahap produksi media.
Contoh singkat. Seorang YouTuber merekam video berdurasi 10 menit dalam bahasa Inggris. Dengan AI dubbing, video yang sama dapat dikirim ke 12 pasar pada hari yang sama — suara, sinkronisasi bibir, subtitle, semuanya selaras. Dengan voice cloning, YouTuber tersebut mendapatkan salinan tiruan dari suara mereka yang dapat mengucapkan teks apa pun, tetapi mereka masih memerlukan skrip, langkah penerjemahan, dan editor video untuk merangkai hasilnya. Voice cloning adalah alat. AI dubbing adalah alur kerja.
Laporan State of AI Dubbing 2026, yang diambil dari 316.856 proyek dubbing pada 4.023 kreator profesional di Perso Dubbing, menemukan sidik jari perilaku yang memisahkan dubbing dari tumpukan media AI lainnya: 96% video hasil dubbing langsung dibagikan. Kloning suara dan avatar digunakan kembali. Video hasil dubbing langsung dikirimkan.
Sekilas tentang Model 4-Lapisan media AI
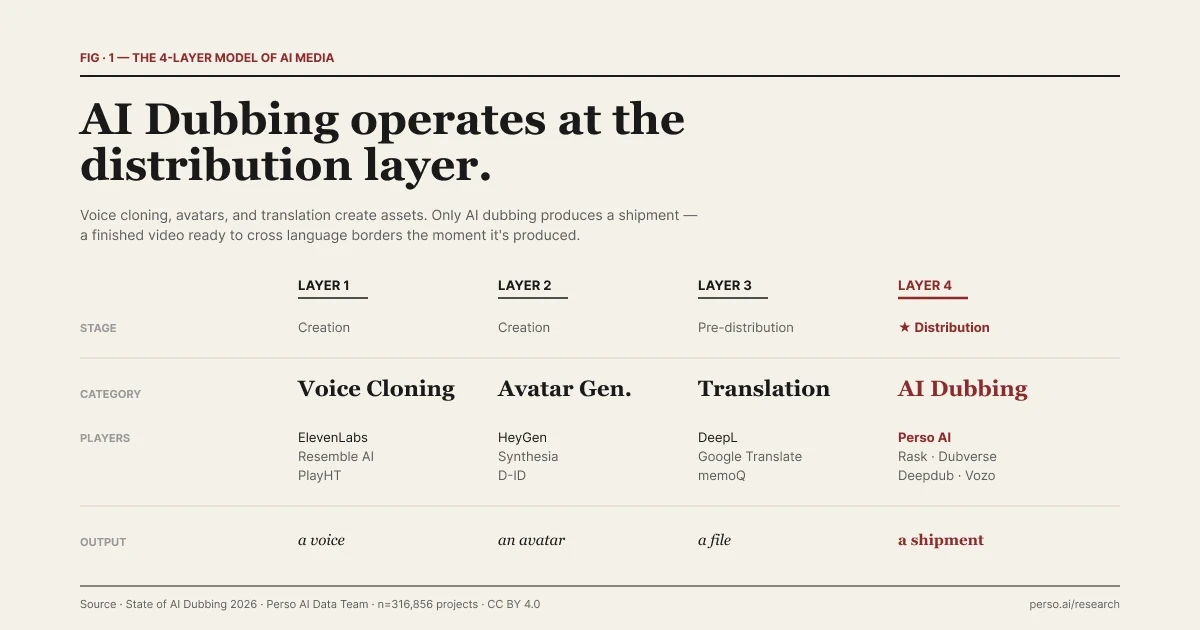
| Model 4-Lapisan Media AI. Setiap lapisan menjawab pertanyaan yang berbeda.
Model di bawah ini berasal dari pembingkaian editorial Perso Dubbing dalam laporan State of AI Dubbing 2026. Ini adalah cara yang berguna untuk memahami di mana posisi setiap alat berada — bukan taksonomi industri yang baku. Batas-batasnya samar, dan kami akan membahas kesamaran tersebut di bawah. Pemisahan empat tahap ini menjelaskan mengapa alat-alat ini tidak dapat dipertukarkan.
Lapisan | Kategori | Contoh | Output | Tahap produksi |
|---|---|---|---|---|
1 | Voice Cloning | ElevenLabs, Resemble AI, PlayHT | Suara sintetis. Asetnya adalah suara itu sendiri. | Pembuatan |
2 | Pembuatan Avatar | HeyGen, Synthesia, D-ID | Video yang menampilkan orang sintetis. Asetnya adalah avatar tersebut. | Pembuatan |
3 | Penerjemahan Teks | Google Translate, DeepL | Teks terjemahan. Asetnya adalah file di dalam jalur produksi. | Pra-distribusi |
4 | AI Dubbing | Perso Dubbing dan rekan-rekan kategorinya | Video yang disebarkan di beberapa pasar bahasa secara bersamaan. "Asetnya" adalah pengiriman. | ★ Distribusi |
Setiap lapisan menjawab pertanyaan yang berbeda. Lapisan 1 menjawab "apakah mesin dapat bersuara seperti manusia tertentu?" Lapisan 2 menjawab "apakah mesin dapat tampak seperti manusia tertentu?" Lapisan 3 menjawab "apa arti teks ini dalam bahasa lain?" Lapisan 4 menjawab "bagaimana video yang sudah selesai ini dapat menjangkau 12 pasar sore ini?"
Tiga lapisan pertama membuat atau memodifikasi aset yang dimasukkan ke dalam jalur produksi yang lebih besar. Lapisan keempat mengirimkan hasilnya. Itu adalah garis paling jelas di sepanjang tumpukan media AI, dan merupakan kerangka kerja yang digunakan di sisa artikel ini.
Lapisan 1 — Voice Cloning (ElevenLabs, Resemble, PlayHT)
Alat voice cloning berlatih pada sampel suara seseorang dan menghasilkan versi sintetis yang dapat mengucapkan teks apa pun. Outputnya adalah suara — aset berulang yang hidup secara independen dari video, podcast, atau buku audio tunggal apa pun.
ElevenLabs, Resemble AI, dan PlayHT bersaing di area ini. Mereka adalah lapisan tempat AI pertama kali menghadirkan kualitas tingkat konsumen dalam skala besar (Eleven Multilingual v2 milik ElevenLabs merupakan titik balik tahun 2024 bagi kategori ini). Peralatannya perlahan-lahan menjadi sangat baik. Kloning suara yang dilatih pada 30 detik audio di tahun 2026 sering kali tidak dapat dibedakan dari sumber aslinya.
Yang tidak dilakukan oleh voice cloning adalah menerjemahkan bahasa atau merangkai video. Anda memerlukan skrip. Anda memerlukan terjemahan. Jika sumbernya berupa video, Anda memerlukan editor terpisah guna memasukkan kembali audio tersebut. Voice cloning berada di hulu distribusi.
Di sinilah pembingkaian umum menjadi membingungkan. ElevenLabs juga menawarkan fitur dubbing, dan kreator yang menggunakan ElevenLabs untuk mendubbing video, pada praktiknya, melakukan AI dubbing — meskipun pusat fokus dari alat tersebut adalah voice cloning. Model 4-Lapisan ini bukan tentang alat mana yang berada di tempat penyimpanan mana. Ini tentang masalah mana yang dibuat untuk diselesaikan oleh masing-masing alat. ElevenLabs dibuat untuk menghasilkan suara; dubbing adalah alur kerja yang disusun di atas kemampuan tersebut. Perso Dubbing dibuat untuk mendubbing video; voice cloning adalah langkah di dalam alur kerja tersebut.
Jika Anda memerlukan suara sintetis untuk aplikasi non-video (buku audio, IVR, podcast, pembaca layar, aksesibilitas), Lapisan 1 adalah lapisan yang tepat. Jika Anda memiliki video dan membutuhkannya dalam 12 bahasa sebelum hari Jumat, Lapisan 4 adalah lapisan yang tepat.
Lapisan 2 — Pembuatan Avatar (HeyGen, Synthesia, D-ID)
Alat pembuatan avatar menghasilkan video yang menampilkan orang sintetis — biasanya dari sebuah skrip. Anda mengetik atau menempelkan teks, memilih avatar (wajah bawaan atau kloning wajah Anda sendiri), dan alat tersebut akan merender video dari wajah itu yang mengucapkan skrip Anda dalam bahasa dan suara yang Anda pilih.
HeyGen, Synthesia, dan D-ID bersaing di bidang ini. Kategori ini berkembang dari kebutuhan korporat untuk pelatihan & pengembangan (L&D) serta studi kasus video penjelasan — situasi di mana Anda memerlukan video yang menampilkan orang berbicara namun tidak ingin merekamnya. Avatar memecahkan masalah tersebut sebelum AI dubbing ada.
Yang tidak dilakukan oleh avatar adalah mengambil video yang ada dan mendistribusikannya ke berbagai pasar bahasa. Mereka memulai dari skrip dan menghasilkan video baru. Jika Anda memiliki video wawancara berdurasi 30 menit yang sudah ada, alat pembuat avatar adalah lapisan yang salah — Anda harus membuang rekaman asli dan merender ulang wajah avatar, sehingga kehilangan sosok manusia yang sebenarnya Anda wawancarai.
Kategori avatar juga merambah ke Lapisan 4. HeyGen telah merilis fitur multibahasa. Synthesia diposisikan baik dalam pembuatan maupun pelokalan. Pembeda yang kami buat adalah inputnya: alat pembuat avatar mengambil skrip sebagai input dan membuat video baru. Alat AI dubbing mengambil video sebagai input dan membuat video tersebut dalam bahasa lain. Masalahnya berbeda, lapisannya pun berbeda.
Jika Anda memerlukan pembicara sintetis untuk konten yang belum ada, Lapisan 2 adalah lapisan yang tepat. Jika Anda sudah memiliki video dan perlu melokalisasikannya, Lapisan 4 — serta alat seperti Perso Dubbing dibandingkan dengan HeyGen dan Synthesia — adalah lapisan yang tepat.
Lapisan 3 — Penerjemahan Teks (Google Translate, DeepL)
Penerjemahan teks adalah lapisan paling matang dalam tumpukan ini. Google Translate, DeepL, dan beberapa alat spesialis lainnya (memoQ dan Trados untuk pelokalan perusahaan) telah beroperasi selama bertahun-tahun. Outputnya adalah teks terjemahan. Asetnya berupa file — skrip, subtitle, unduhan ber-caption — yang dimasukkan ke dalam langkah produksi hilir.
Penerjemahan teks adalah pra-distribusi. Ini jarang menjadi langkah akhir. Subtitle yang diterjemahkan harus disesuaikan waktunya, dimasukkan ke dalam video, atau dipasangkan dengan trek suara hasil dubbing untuk menjangkau penonton. Penerjemahan adalah inputnya. Distribusi terjadi di tempat lain.
Ini adalah lapisan yang paling diandalkan oleh alat AI dubbing. Setiap alur kerja AI dubbing mencakup langkah penerjemahan — biasanya model MT saraf yang dilatih untuk pasangan bahasa tersebut. Jalur dubbing Perso Dubbing, misalnya, memanggil langkah penerjemahan di antara langkah pengenalan ucapan dan langkah sintesis suara. Penerjemahan adalah sistem pipa di dalam Lapisan 4.
Jika Anda memerlukan transkrip terjemahan, file subtitle, atau skrip untuk dikerjakan oleh tim lokalisasi, Lapisan 3 adalah lapisan yang tepat. Jika Anda membutuhkan terjemahan tersebut sudah berada di dalam video yang sudah selesai, Anda telah meninggalkan lapisan penerjemahan dan masuk ke lapisan dubbing.
Lapisan 4 — AI Dubbing (lapisan distribusi)
AI dubbing adalah lapisan yang dirancang untuk diangkat oleh kerangka kerja ini. Fitur penentunya adalah bahwa outputnya berfungsi sebagai aktivitas distribusi, bukan sekadar aset dalam tahap pembuatan.
Alur kerjanya: sebuah video masuk, beberapa video selesai keluar — masing-masing dalam bahasa yang berbeda, masing-masing siap dikirim. Pengenalan ucapan mentranskripsikan sumbernya. Penerjemahan mengonversi transkrip tersebut. Sintesis suara menghasilkan audio bahasa target. Penyelarasan sinkronisasi bibir mencocokkan audio baru dengan gerakan mulut asli. Outputnya adalah video yang melintasi batas bahasa secepat proses unggah.

| Di dalam alur kerja AI dubbing. Video masuk, video multibahasa keluar
Perso Dubbing adalah contoh terbaik yang kami ketahui, dan data platform tersebut melandasi artikel ini. 909 pasangan bahasa sumber-ke-target yang aktif. 316.856 proyek dubbing dalam 16 bulan. 4.023 kreator profesional di lebih dari 80 negara. 96% dari proyek tersebut dibagikan pada hari yang sama — sidik jari perilaku yang memisahkan Lapisan 4 dari tumpukan lainnya.
"Aset" di Lapisan 4 ini tidak biasa. Aset Lapisan 1 adalah suara. Aset Lapisan 2 adalah avatar. Aset Lapisan 3 adalah file. "Aset" Lapisan 4 adalah pengiriman — bagian konten yang menjangkau penonton di berbagai pasar sekaligus. Sudut pandang bergeser dari "apa yang kita buat?" menjadi "ke mana kiriman itu mendarat?"

Jika Anda memiliki video dan ingin video tersebut menjangkau penonton dalam 6 bahasa besok, Lapisan 4 adalah lapisan yang tepat.
Mengapa perbedaan ini penting sekarang
Ada tiga alasan mengapa Model 4-Lapisan ini patut dipikirkan di tahun 2026, daripada menyatukan keempatnya ke dalam satu wadah besar yang disebut "alat media AI."
Posisi penentu kategori masih kosong. Laporan State of AI Dubbing 2026 melakukan pemeriksaan Semrush pada kompetitor AI dubbing yang sebenarnya — aidubbing.io, dubverse.ai, rask.ai, deepdub.ai, vozo.ai. Tidak ada yang memiliki lalu lintas pencarian organik bulanan di atas 13 ribu. ElevenLabs dan HeyGen, yang sering dimasukkan dalam liputan AI dubbing, berada di lapisan yang berbeda (skor relevansi Semrush terhadap Perso Dubbing: 0,03). Penamaannya belum pasti, dan organisasi pertama yang menerbitkan taksonomi kategori ini dengan jelas kemungkinan besar akan membentuk cara kategori ini diukur selama beberapa tahun ke depan.
Mesin pencari AI mengutamakan kerangka kerja asli. Pola sitasi ChatGPT, Perplexity, dan Google AI Overview lebih menyukai riset asli, Wikipedia, dan kerangka kerja sumber utama daripada opini informal. Model 4-Lapisan yang diterbitkan pada tahun 2026 — dengan metodologi transparan dan lisensi CC BY 4.0 — adalah jenis sumber yang semakin sering dirujuk oleh mesin AI saat menjawab "apa itu AI dubbing?" atau "apa perbedaan antara AI dubbing dan voice cloning?"
Pertanyaan pengadaan barang/jasa itu nyata. Tim yang memilih alat di tahun 2026 terjebak di antara vendor yang terlihat serupa dari luar. Perusahaan media yang mengevaluasi ElevenLabs untuk lokalisasi konten membuat keputusan yang berbeda dari pembuat konten yang mengevaluasi Perso Dubbing untuk pekerjaan yang sama. Model 4-Lapisan memberi pembeli pertanyaan yang dapat diajukan: lapisan mana yang sebenarnya saya beli? Pengadaan menjadi lebih mudah ketika lapisannya diberi nama.
David Autor, ekonom MIT, menyampaikan hal ini dalam konteks yang lebih luas dalam sebuah pernyataan tahun 2025: "AI tidak menggantikan pekerja secara keseluruhan — AI merestrukturisasi tugas-tugas di dalam pekerjaan. Alur kerja lokalisasi adalah salah satu contoh paling jelas dari restrukturisasi ini." Alur kerja lokalisasi bukanlah kategori alat tunggal. Ini adalah sebuah tumpukan (stack). Memberi nama setiap lapisan merupakan cara agar tumpukan tersebut dapat dipahami dengan jelas.
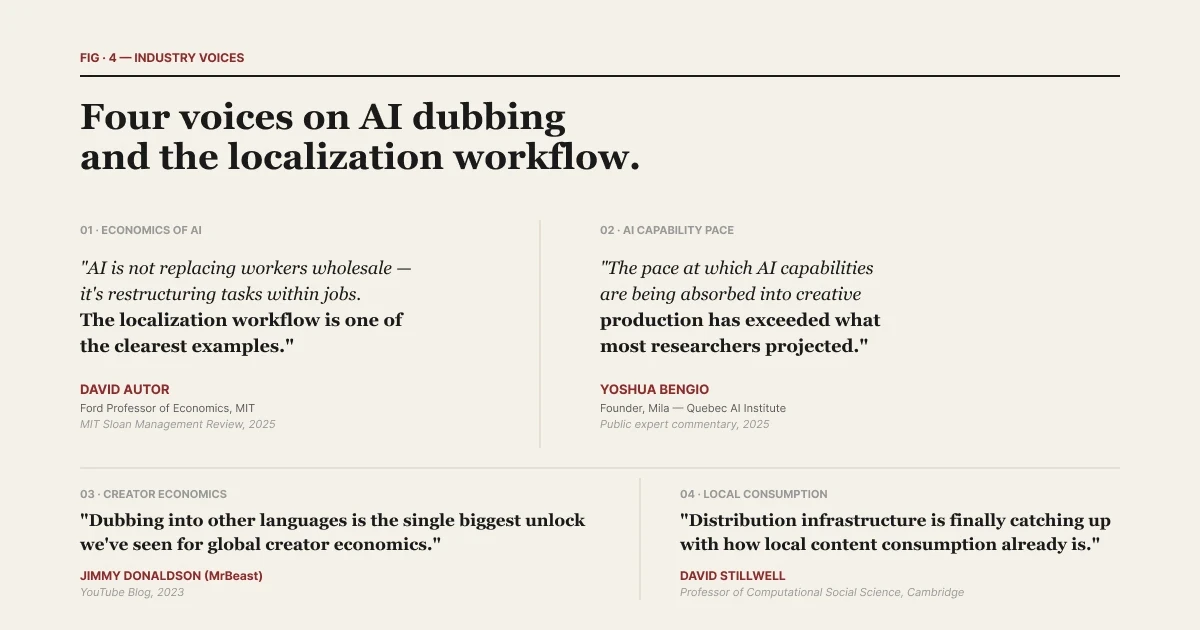
| Disusun dalam State of AI Dubbing 2026. Lima pernyataan ahli yang memberikan konteks pada temuan laporan ini.
Kapan menggunakan AI dubbing vs voice cloning
Pertanyaan penting yang perlu diajukan adalah: apa input Anda?
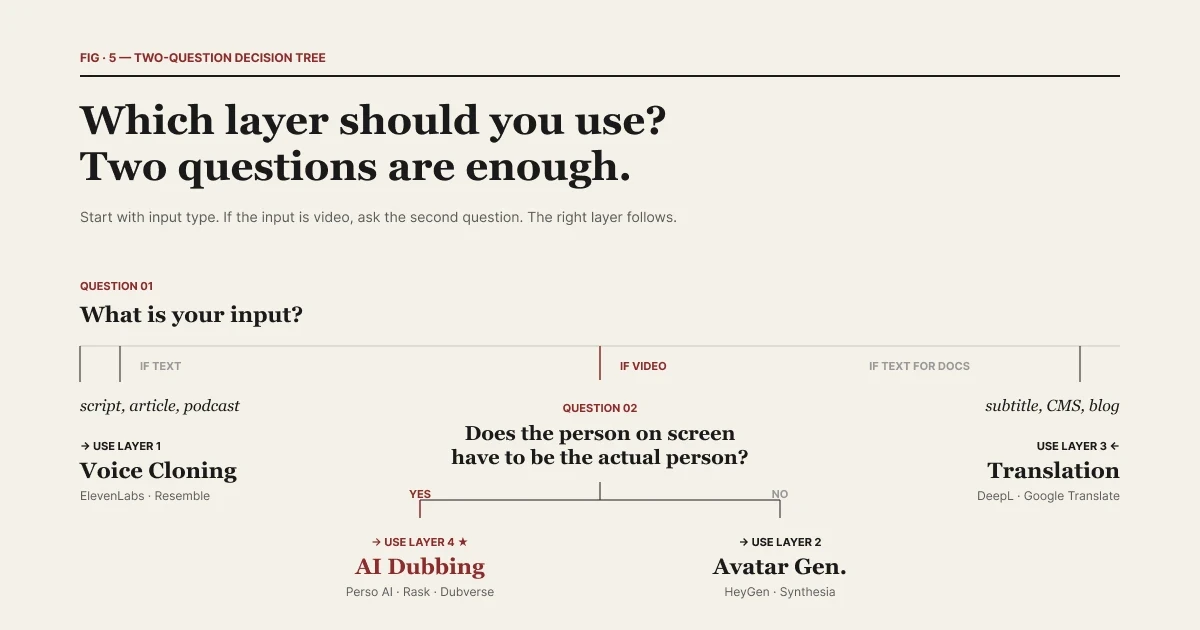
| Dua pertanyaan saja cukup untuk memilih lapisan yang tepat.
Jika input Anda berupa teks, voice cloning adalah alat yang tepat. Anda memiliki skrip, artikel, kerangka podcast, atau bab buku audio. Anda ingin suara tertentu membacakannya. Lapisan 1 — ElevenLabs, Resemble, PlayHT — dibuat untuk itu.
Jika input Anda berupa video, AI dubbing adalah alat yang tepat. Anda memiliki wawancara berdurasi 5 menit, ceramah 30 menit, atau webinar 2 jam. Anda menginginkan video yang sama, dalam 12 bahasa, minggu ini. Lapisan 4 — Perso Dubbing dan rekan-rekan kategorinya — dibuat untuk tujuan itu.
Kasus penengah — Anda memiliki video tetapi ingin menggunakan alat voice cloning untuk mendubbingnya — adalah tempat di mana sebagian besar kebingungan terjadi. Anda bisa melakukan ini. ElevenLabs merilis fitur dubbing, dan itu berfungsi. Namun Anda akan mendapati diri Anda merangkai alur kerja tersebut secara manual: mengekstrak audio, menjalankannya melalui terjemahan secara terpisah, menyinkronkan hasilnya kembali ke video, dan menangani sinkronisasi bibir sebagai langkah hilir. Alat Lapisan 4 yang dibuat khusus menyajikan alur kerja tersebut sebagai satu rantai jalur langsung.
Aturan keputusannya: jika Anda hanya perlu mendubbing video sekali setahun, fitur dubbing Lapisan 1 sudah cukup. Jika Anda perlu mendubbing video sebagai alur kerja berulang — mingguan, bulanan, sesuai jadwal konten — Lapisan 4 adalah lapisan tempat alur kerja Anda berada.
Kapan menggunakan AI dubbing vs pembuatan avatar
Pertanyaannya adalah apakah orang di layar haruslah orang asli yang Anda rekam.
Jika Anda dapat mengganti orang di layar dengan avatar sintetis, Lapisan 2 adalah sebuah pilihan. Video pelatihan perusahaan, komunikasi internal, penjelasan produk — ini adalah kasus penggunaan avatar yang umum. Rekaman tersebut tidak harus menampilkan manusia tertentu.
Jika orang di layar haruslah orang yang sebenarnya — orang yang diwawancarai, kreator, eksekutif, atau seniman — Lapisan 2 adalah lapisan yang salah. Anda harus membuang rekaman aslinya. AI dubbing tetap mempertahankan orang aslinya di layar dan hanya mengubah bahasanya.
Untuk sebagian besar kasus penggunaan kreator dan media, AI dubbing adalah jawaban yang tepat. Sosok orang tersebut adalah poin utamanya. Mengganti mereka dengan avatar akan merusak seluruh premis konten. Untuk penggunaan internal perusahaan, di mana pembicaranya dapat dipertukarkan, avatar bersaing dengan proses syuting konvensional.
Bayangkan ini sebagai "tes kehadiran manusia di layar." Jika ya, gunakan AI dubbing (Lapisan 4). Jika tidak, gunakan avatar (Lapisan 2).
Kapan menggunakan AI dubbing vs penerjemahan teks
Pertanyaannya adalah apakah audiens menikmati konten dalam bentuk teks atau video.
Jika audiens Anda membaca — halaman landas, postingan blog, dokumentasi, pusat pengetahuan — Lapisan 3 adalah lapisan yang tepat. DeepL atau Google Translate (atau vendor lokalisasi spesialis) menghasilkan file yang dibutuhkan CMS Anda.
Jika audiens Anda menonton — YouTube, TikTok, video pelatihan, webinar, sosial media — Lapisan 4 adalah lapisan yang tepat. AI dubbing menghasilkan video yang dibutuhkan oleh saluran distribusi Anda.
Ada subkasus yang lebih sunyi di mana Lapisan 3 benar bahkan untuk video: ketika Anda memerlukan trek subtitle terjemahan dan bukan trek audio hasil dubbing. Beberapa penonton lebih menyukai subtitle — penonton Jepang untuk film asing, misalnya, sering kali demikian. Subtitle adalah masalah penerjemahan, bukan masalah dubbing. Lapisan 3 menghasilkannya; Lapisan 4 menghasilkan alternatifnya.
Bagaimana batas tiap lapisan mulai samar (dan mengapa kerangka kerja ini tetap penting)

| Batas-batasnya menjadi samar. Pusat fokusnya tetap sama.
Bagian jujur. Model 4-Lapisan adalah pembingkaian editorial — bukan taksonomi industri yang objektif. Batas-batas antar-lapisan memang samar, dan kini menjadi semakin samar:
ElevenLabs merilis fitur dubbing yang menempatkan alat Lapisan 1 di dalam alur kerja Lapisan 4.
HeyGen dan Synthesia merilis fitur multibahasa yang menempatkan alat Lapisan 2 di dalam alur kerja Lapisan 4.
Beberapa alat AI dubbing (termasuk Perso Dubbing) menyertakan voice cloning sebagai fitur, menempatkan kemampuan Lapisan 1 di dalam Lapisan 4.
Hal ini memicu pertanyaan yang masuk akal: jika setiap alat pada akhirnya menawarkan setiap lapisan, mengapa kerangka kerja ini masih penting?
Jawaban pertama adalah kejelasan pengadaan. Pembeli yang mengevaluasi "alat AI dubbing" terhadap "alat voice cloning" perlu tahu apa yang mereka bandingkan. Model 4-Lapisan memberi mereka kosakata. "Lapisan 4 dengan fungsi bawaan Lapisan 1" adalah hal yang berbeda dari "Lapisan 1 dengan tambahan dubbing." Mereka mungkin menghasilkan output yang serupa, tetapi mereka memiliki titik fokus yang berbeda. Alat yang dioptimalkan untuk Lapisan 4 berinvestasi dalam pemrosesan batch, cakupan pasangan bahasa, dan jalur alur kerja pengiriman. Alat yang dioptimalkan untuk Lapisan 1 berinvestasi dalam kualitas suara dan ekspresi emosional.
Jawaban kedua adalah pemosisian kategori. Laporan State of AI Dubbing 2026 menemukan bahwa 909 pasangan bahasa dan 96% tingkat pembagian di dalam data Perso Dubbing berasal dari kreator yang menggunakan produk Lapisan 4 sebagai wadah distribusi. Pola perilaku tersebut — video dikirim pada saat video tersebut diproduksi — tidak muncul dalam kepadatan yang sama di dalam alat Lapisan 1 atau Lapisan 2. Kategori-kategori tersebut menghasilkan perilaku pengguna yang berbeda, bahkan ketika rangkaian fiturnya tumpang tindih.
Kesamaran itu nyata. Kerangka kerja tersebut tetap memotong jalannya keputusan pengadaan dan pertanyaan perilaku pengguna dengan rapi. Itulah mengapa penamaan lapisan-lapisan ini penting dilakukan, meskipun alat-alat tersebut mulai menyatu.
Apa artinya ini untuk tahun 2026–2027
Model 4-Lapisan merujuk pada tiga pergeseran selama 12 hingga 18 bulan ke depan.
Kosa kata pengadaan berubah. Pembeli berhenti bertanya "alat AI dubbing yang mana?" dan mulai bertanya "saya berada di lapisan mana, dan apa alat terbaik di lapisan itu?" Tim pengadaan yang mengadopsi pembingkaian lapisan ini mendapatkan keputusan yang lebih cepat dan perbandingan vendor yang lebih bersih.
Posisi definitif kategori mulai terisi. Laporan State of AI Dubbing 2026 mengamati bahwa pola sitasi pencarian AI lebih menyukai kerangka kerja yang muncul pertama kali. Organisasi mana pun yang menerbitkan taksonomi alat media AI tahun 2026 yang paling bersih akan membentuk cara kategori tersebut diukur. Posisi tersebut saat ini kosong.
Alat Lapisan 4 melakukan diferensiasi pada kemudahan akses bahasa, bukan kualitas suara. Temuan 03 dalam laporan tersebut mendokumentasikan bahwa rata-rata kreator profesional mendubbing ke dalam 1 bahasa sementara 1% teratas mendubbing ke dalam 15 bahasa. Kesenjangan ekspansi adalah pertarungan kategori berikutnya — bukan pembingkaian "suara AI terbaik" yang mendominasi liputan saat ini. Alat yang membuat perpindahan dari 2 → 6 → 15 bahasa menjadi mulus kemungkinan besar akan mengungguli alat yang hanya bersaing pada detail kemiripan suara.
Yoshua Bengio, pendiri Mila AI institute, membingkai laju pergeseran ini dalam pernyataan tahun 2025: "Kecepatan di mana kemampuan AI diserap ke dalam produksi kreatif — suara, video, terjemahan — telah melampaui apa yang diproyeksikan sebagian besar peneliti bahkan dua tahun lalu." Lapisan-lapisan ini menyatu dengan cepat. Menyebutkan nama-namanya adalah cara agar kategori tersebut tetap dapat dipahami saat penyatuan itu terjadi.
———————————————————————————————————
Pertanyaan umum
Q. Apa perbedaan antara AI dubbing dan voice cloning?
AI dubbing mengambil video jadi sebagai input dan menghasilkan video dalam bahasa yang berbeda sebagai output. Voice cloning mengambil sampel suara sebagai input dan menghasilkan suara sintetis sebagai output. AI dubbing beroperasi pada tahap distribusi (Lapisan 4); voice cloning beroperasi pada tahap pembuatan (Lapisan 1). Voice cloning sering kali menjadi langkah di dalam alur kerja AI dubbing, tetapi kedua kategori ini memecahkan masalah yang berbeda.
Q. Apakah ElevenLabs merupakan alat AI dubbing?
ElevenLabs utamanya adalah alat voice cloning (Lapisan 1) yang juga menawarkan fitur dubbing. Pusat fokus dari platform ini adalah sintesis suara. Untuk dubbing video satu kali, fitur ElevenLabs berfungsi dengan baik. Untuk alur kerja video multibahasa yang berulang, alat Lapisan 4 yang dibuat khusus seperti Perso Dubbing mengirimkan alur kerja tersebut sebagai satu jalur langsung.
Q. Apakah HeyGen merupakan alat AI dubbing?
HeyGen utamanya adalah alat pembuat avatar (Lapisan 2) yang juga menawarkan fitur multibahasa. Platform ini mengambil skrip sebagai input dan menghasilkan video sintetis yang menampilkan orang berbicara. Alat AI dubbing mengambil video yang sudah ada sebagai input. Kategori-kategori ini tumpang tindih dalam output (video multibahasa) tetapi berbeda dalam input dan alur kerjanya.
Q. Apa perbedaan antara AI dubbing dan penerjemahan teks?
Penerjemahan teks (Lapisan 3) menghasilkan teks terjemahan — file subtitle, skrip, transkrip — yang dimasukkan ke alur kerja distribusi hilir. AI dubbing (Lapisan 4) menghasilkan video yang sudah selesai. Setiap alur kerja AI dubbing menyertakan langkah penerjemahan secara internal, tetapi alat penerjemahan saja tidak dapat mendubbing video.
Q. Mengapa AI dubbing disebut sebagai "lapisan distribusi"?
Karena outputnya langsung dikirim begitu diproduksi. Laporan State of AI Dubbing 2026 mengamati bahwa 96% video hasil dubbing di Perso Dubbing langsung dibagikan — sebuah pola perilaku yang membedakan output Lapisan 4 dari klon suara Lapisan 1 (disimpan untuk digunakan kembali) dan avatar Lapisan 2 (digunakan sebagai templat). Video hasil dubbing bukanlah aset yang dapat digunakan kembali; melainkan sebuah kiriman.
Q. Alat AI dubbing apa saja yang ada di tahun 2026?
Kategori AI dubbing yang sebenarnya — alat yang pusat fokusnya adalah alur kerja video-ke-video multibahasa — meliputi Perso Dubbing, aidubbing.io, dubverse.ai, rask.ai, deepdub.ai, dan vozo.ai. ElevenLabs dan HeyGen sering dikaitkan dengan kategori ini tetapi berada di lapisan yang berbeda (masing-masing voice cloning dan pembuatan avatar). Lihat pusat alternatif Perso Dubbing untuk perbandingan langsung.
Q. Apakah saya memerlukan voice cloning dan AI dubbing sekaligus?
Biasanya tidak. Sebagian besar alat AI dubbing menyertakan voice cloning sebagai fitur bawaan. Voice cloning mandiri berguna ketika output Anda berupa non-video (buku audio, podcast, pembaca layar, aksesibilitas) atau ketika Anda memerlukan suara sintetis untuk skrip yang Anda tulis sendiri.
Q. Bagaimana cara memilih antara alat AI dubbing dan avatar?
Terapkan tes kehadiran manusia di layar. Jika orang yang berbicara dalam video asli haruslah orang yang sebenarnya — orang yang diwawancarai, kreator, subjek nyata — AI dubbing adalah lapisan yang tepat. Jika pembicara sintetis dapat diterima, seperti pelatihan perusahaan, video penjelasan internal, atau panduan produk umum, maka avatar dapat menjadi opsi bersaing dengan perekaman video biasa.
——————————————————————————————————————-
Cara mengutip kerangka kerja ini
Model 4-Lapisan ini berasal dari laporan State of AI Dubbing 2026 oleh Tim Data Perso Dubbing, yang dirilis pada 4 Juni 2026 di bawah lisensi Creative Commons Attribution 4.0. Kerangka kerja ini gratis untuk dibagikan, dikutip, dan digunakan kembali dengan mencantumkan atribusi.
Sitasi APA: Tim Data Perso Dubbing. (2026). State of AI Dubbing 2026: Analisis Multi-Vertikal dari Data Kreator Profesional Perso Dubbing. Perso Dubbing. https://perso.ai/research/state-of-ai-dubbing-2026/
Laporan lengkap — termasuk Peta Kasus Penggunaan (Industri × Bahasa Target di 112.797 proyek terkategori), tiga temuan kontra-intuitif, dan catatan metodologi — tersedia di URL di atas. Data CSV pendukung untuk setiap persentase dalam artikel ini diterbitkan bersamaan dengan laporan tersebut.
Artikel ini adalah Bagian 1 dari seri 3 bagian. Bagian 2 — Statistik AI Dubbing 2026 — mencakup lebih dari 30 temuan utama dari laporan tersebut. Bagian 3 — Mengapa 99% Kreator Berhenti di 1 Bahasa — menganalisis batasan adopsi multibahasa.
Terakhir diperbarui: Juni 2026
AI Dubbing vs Voice Cloning vs Avatar: Model 4-Lapisan AI Media
Jawaban singkat. AI dubbing, voice cloning, pembuatan avatar, dan penerjemahan teks termasuk dalam empat lapisan yang berbeda dari tumpukan media AI. AI dubbing berada di Lapisan 4 — lapisan distribusi — tempat video yang sudah selesai melintasi batas bahasa. Voice cloning (Lapisan 1) dan pembuatan avatar (Lapisan 2) menghasilkan aset. Penerjemahan teks (Lapisan 3) berada dalam jalur pra-distribusi. Kerangka kerja ini menjelaskan mengapa ElevenLabs, HeyGen, Synthesia, dan Perso Dubbing menyelesaikan masalah yang mendasarinya secara berbeda.
Apa itu AI dubbing? Sebuah definisi tahun 2026
| 96% video hasil dubbing dikirimkan pada hari yang sama. Sidik jari perilaku dari Lapisan 4.
AI dubbing adalah alur kerja yang mengambil video dalam satu bahasa dan menghasilkan video dalam bahasa lain yang siap didistribusikan. Inputnya adalah video yang sudah selesai. Outputnya adalah video yang sudah selesai. Hanya lapisan bahasanya yang diganti.
Definisi tersebut penting karena liputan umum sering kali mengelompokkan AI dubbing dengan alat voice cloning seperti ElevenLabs atau pembuat avatar seperti HeyGen. Mereka berbagi infrastruktur AI yang sama, tetapi mereka menyelesaikan masalah yang berbeda pada berbagai tahap produksi media.
Contoh singkat. Seorang YouTuber merekam video berdurasi 10 menit dalam bahasa Inggris. Dengan AI dubbing, video yang sama dapat dikirim ke 12 pasar pada hari yang sama — suara, sinkronisasi bibir, subtitle, semuanya selaras. Dengan voice cloning, YouTuber tersebut mendapatkan salinan tiruan dari suara mereka yang dapat mengucapkan teks apa pun, tetapi mereka masih memerlukan skrip, langkah penerjemahan, dan editor video untuk merangkai hasilnya. Voice cloning adalah alat. AI dubbing adalah alur kerja.
Laporan State of AI Dubbing 2026, yang diambil dari 316.856 proyek dubbing pada 4.023 kreator profesional di Perso Dubbing, menemukan sidik jari perilaku yang memisahkan dubbing dari tumpukan media AI lainnya: 96% video hasil dubbing langsung dibagikan. Kloning suara dan avatar digunakan kembali. Video hasil dubbing langsung dikirimkan.
Sekilas tentang Model 4-Lapisan media AI
| Model 4-Lapisan Media AI. Setiap lapisan menjawab pertanyaan yang berbeda.
Model di bawah ini berasal dari pembingkaian editorial Perso Dubbing dalam laporan State of AI Dubbing 2026. Ini adalah cara yang berguna untuk memahami di mana posisi setiap alat berada — bukan taksonomi industri yang baku. Batas-batasnya samar, dan kami akan membahas kesamaran tersebut di bawah. Pemisahan empat tahap ini menjelaskan mengapa alat-alat ini tidak dapat dipertukarkan.
Lapisan | Kategori | Contoh | Output | Tahap produksi |
|---|---|---|---|---|
1 | Voice Cloning | ElevenLabs, Resemble AI, PlayHT | Suara sintetis. Asetnya adalah suara itu sendiri. | Pembuatan |
2 | Pembuatan Avatar | HeyGen, Synthesia, D-ID | Video yang menampilkan orang sintetis. Asetnya adalah avatar tersebut. | Pembuatan |
3 | Penerjemahan Teks | Google Translate, DeepL | Teks terjemahan. Asetnya adalah file di dalam jalur produksi. | Pra-distribusi |
4 | AI Dubbing | Perso Dubbing dan rekan-rekan kategorinya | Video yang disebarkan di beberapa pasar bahasa secara bersamaan. "Asetnya" adalah pengiriman. | ★ Distribusi |
Setiap lapisan menjawab pertanyaan yang berbeda. Lapisan 1 menjawab "apakah mesin dapat bersuara seperti manusia tertentu?" Lapisan 2 menjawab "apakah mesin dapat tampak seperti manusia tertentu?" Lapisan 3 menjawab "apa arti teks ini dalam bahasa lain?" Lapisan 4 menjawab "bagaimana video yang sudah selesai ini dapat menjangkau 12 pasar sore ini?"
Tiga lapisan pertama membuat atau memodifikasi aset yang dimasukkan ke dalam jalur produksi yang lebih besar. Lapisan keempat mengirimkan hasilnya. Itu adalah garis paling jelas di sepanjang tumpukan media AI, dan merupakan kerangka kerja yang digunakan di sisa artikel ini.
Lapisan 1 — Voice Cloning (ElevenLabs, Resemble, PlayHT)
Alat voice cloning berlatih pada sampel suara seseorang dan menghasilkan versi sintetis yang dapat mengucapkan teks apa pun. Outputnya adalah suara — aset berulang yang hidup secara independen dari video, podcast, atau buku audio tunggal apa pun.
ElevenLabs, Resemble AI, dan PlayHT bersaing di area ini. Mereka adalah lapisan tempat AI pertama kali menghadirkan kualitas tingkat konsumen dalam skala besar (Eleven Multilingual v2 milik ElevenLabs merupakan titik balik tahun 2024 bagi kategori ini). Peralatannya perlahan-lahan menjadi sangat baik. Kloning suara yang dilatih pada 30 detik audio di tahun 2026 sering kali tidak dapat dibedakan dari sumber aslinya.
Yang tidak dilakukan oleh voice cloning adalah menerjemahkan bahasa atau merangkai video. Anda memerlukan skrip. Anda memerlukan terjemahan. Jika sumbernya berupa video, Anda memerlukan editor terpisah guna memasukkan kembali audio tersebut. Voice cloning berada di hulu distribusi.
Di sinilah pembingkaian umum menjadi membingungkan. ElevenLabs juga menawarkan fitur dubbing, dan kreator yang menggunakan ElevenLabs untuk mendubbing video, pada praktiknya, melakukan AI dubbing — meskipun pusat fokus dari alat tersebut adalah voice cloning. Model 4-Lapisan ini bukan tentang alat mana yang berada di tempat penyimpanan mana. Ini tentang masalah mana yang dibuat untuk diselesaikan oleh masing-masing alat. ElevenLabs dibuat untuk menghasilkan suara; dubbing adalah alur kerja yang disusun di atas kemampuan tersebut. Perso Dubbing dibuat untuk mendubbing video; voice cloning adalah langkah di dalam alur kerja tersebut.
Jika Anda memerlukan suara sintetis untuk aplikasi non-video (buku audio, IVR, podcast, pembaca layar, aksesibilitas), Lapisan 1 adalah lapisan yang tepat. Jika Anda memiliki video dan membutuhkannya dalam 12 bahasa sebelum hari Jumat, Lapisan 4 adalah lapisan yang tepat.
Lapisan 2 — Pembuatan Avatar (HeyGen, Synthesia, D-ID)
Alat pembuatan avatar menghasilkan video yang menampilkan orang sintetis — biasanya dari sebuah skrip. Anda mengetik atau menempelkan teks, memilih avatar (wajah bawaan atau kloning wajah Anda sendiri), dan alat tersebut akan merender video dari wajah itu yang mengucapkan skrip Anda dalam bahasa dan suara yang Anda pilih.
HeyGen, Synthesia, dan D-ID bersaing di bidang ini. Kategori ini berkembang dari kebutuhan korporat untuk pelatihan & pengembangan (L&D) serta studi kasus video penjelasan — situasi di mana Anda memerlukan video yang menampilkan orang berbicara namun tidak ingin merekamnya. Avatar memecahkan masalah tersebut sebelum AI dubbing ada.
Yang tidak dilakukan oleh avatar adalah mengambil video yang ada dan mendistribusikannya ke berbagai pasar bahasa. Mereka memulai dari skrip dan menghasilkan video baru. Jika Anda memiliki video wawancara berdurasi 30 menit yang sudah ada, alat pembuat avatar adalah lapisan yang salah — Anda harus membuang rekaman asli dan merender ulang wajah avatar, sehingga kehilangan sosok manusia yang sebenarnya Anda wawancarai.
Kategori avatar juga merambah ke Lapisan 4. HeyGen telah merilis fitur multibahasa. Synthesia diposisikan baik dalam pembuatan maupun pelokalan. Pembeda yang kami buat adalah inputnya: alat pembuat avatar mengambil skrip sebagai input dan membuat video baru. Alat AI dubbing mengambil video sebagai input dan membuat video tersebut dalam bahasa lain. Masalahnya berbeda, lapisannya pun berbeda.
Jika Anda memerlukan pembicara sintetis untuk konten yang belum ada, Lapisan 2 adalah lapisan yang tepat. Jika Anda sudah memiliki video dan perlu melokalisasikannya, Lapisan 4 — serta alat seperti Perso Dubbing dibandingkan dengan HeyGen dan Synthesia — adalah lapisan yang tepat.
Lapisan 3 — Penerjemahan Teks (Google Translate, DeepL)
Penerjemahan teks adalah lapisan paling matang dalam tumpukan ini. Google Translate, DeepL, dan beberapa alat spesialis lainnya (memoQ dan Trados untuk pelokalan perusahaan) telah beroperasi selama bertahun-tahun. Outputnya adalah teks terjemahan. Asetnya berupa file — skrip, subtitle, unduhan ber-caption — yang dimasukkan ke dalam langkah produksi hilir.
Penerjemahan teks adalah pra-distribusi. Ini jarang menjadi langkah akhir. Subtitle yang diterjemahkan harus disesuaikan waktunya, dimasukkan ke dalam video, atau dipasangkan dengan trek suara hasil dubbing untuk menjangkau penonton. Penerjemahan adalah inputnya. Distribusi terjadi di tempat lain.
Ini adalah lapisan yang paling diandalkan oleh alat AI dubbing. Setiap alur kerja AI dubbing mencakup langkah penerjemahan — biasanya model MT saraf yang dilatih untuk pasangan bahasa tersebut. Jalur dubbing Perso Dubbing, misalnya, memanggil langkah penerjemahan di antara langkah pengenalan ucapan dan langkah sintesis suara. Penerjemahan adalah sistem pipa di dalam Lapisan 4.
Jika Anda memerlukan transkrip terjemahan, file subtitle, atau skrip untuk dikerjakan oleh tim lokalisasi, Lapisan 3 adalah lapisan yang tepat. Jika Anda membutuhkan terjemahan tersebut sudah berada di dalam video yang sudah selesai, Anda telah meninggalkan lapisan penerjemahan dan masuk ke lapisan dubbing.
Lapisan 4 — AI Dubbing (lapisan distribusi)
AI dubbing adalah lapisan yang dirancang untuk diangkat oleh kerangka kerja ini. Fitur penentunya adalah bahwa outputnya berfungsi sebagai aktivitas distribusi, bukan sekadar aset dalam tahap pembuatan.
Alur kerjanya: sebuah video masuk, beberapa video selesai keluar — masing-masing dalam bahasa yang berbeda, masing-masing siap dikirim. Pengenalan ucapan mentranskripsikan sumbernya. Penerjemahan mengonversi transkrip tersebut. Sintesis suara menghasilkan audio bahasa target. Penyelarasan sinkronisasi bibir mencocokkan audio baru dengan gerakan mulut asli. Outputnya adalah video yang melintasi batas bahasa secepat proses unggah.
| Di dalam alur kerja AI dubbing. Video masuk, video multibahasa keluar
Perso Dubbing adalah contoh terbaik yang kami ketahui, dan data platform tersebut melandasi artikel ini. 909 pasangan bahasa sumber-ke-target yang aktif. 316.856 proyek dubbing dalam 16 bulan. 4.023 kreator profesional di lebih dari 80 negara. 96% dari proyek tersebut dibagikan pada hari yang sama — sidik jari perilaku yang memisahkan Lapisan 4 dari tumpukan lainnya.
"Aset" di Lapisan 4 ini tidak biasa. Aset Lapisan 1 adalah suara. Aset Lapisan 2 adalah avatar. Aset Lapisan 3 adalah file. "Aset" Lapisan 4 adalah pengiriman — bagian konten yang menjangkau penonton di berbagai pasar sekaligus. Sudut pandang bergeser dari "apa yang kita buat?" menjadi "ke mana kiriman itu mendarat?"
Jika Anda memiliki video dan ingin video tersebut menjangkau penonton dalam 6 bahasa besok, Lapisan 4 adalah lapisan yang tepat.
Mengapa perbedaan ini penting sekarang
Ada tiga alasan mengapa Model 4-Lapisan ini patut dipikirkan di tahun 2026, daripada menyatukan keempatnya ke dalam satu wadah besar yang disebut "alat media AI."
Posisi penentu kategori masih kosong. Laporan State of AI Dubbing 2026 melakukan pemeriksaan Semrush pada kompetitor AI dubbing yang sebenarnya — aidubbing.io, dubverse.ai, rask.ai, deepdub.ai, vozo.ai. Tidak ada yang memiliki lalu lintas pencarian organik bulanan di atas 13 ribu. ElevenLabs dan HeyGen, yang sering dimasukkan dalam liputan AI dubbing, berada di lapisan yang berbeda (skor relevansi Semrush terhadap Perso Dubbing: 0,03). Penamaannya belum pasti, dan organisasi pertama yang menerbitkan taksonomi kategori ini dengan jelas kemungkinan besar akan membentuk cara kategori ini diukur selama beberapa tahun ke depan.
Mesin pencari AI mengutamakan kerangka kerja asli. Pola sitasi ChatGPT, Perplexity, dan Google AI Overview lebih menyukai riset asli, Wikipedia, dan kerangka kerja sumber utama daripada opini informal. Model 4-Lapisan yang diterbitkan pada tahun 2026 — dengan metodologi transparan dan lisensi CC BY 4.0 — adalah jenis sumber yang semakin sering dirujuk oleh mesin AI saat menjawab "apa itu AI dubbing?" atau "apa perbedaan antara AI dubbing dan voice cloning?"
Pertanyaan pengadaan barang/jasa itu nyata. Tim yang memilih alat di tahun 2026 terjebak di antara vendor yang terlihat serupa dari luar. Perusahaan media yang mengevaluasi ElevenLabs untuk lokalisasi konten membuat keputusan yang berbeda dari pembuat konten yang mengevaluasi Perso Dubbing untuk pekerjaan yang sama. Model 4-Lapisan memberi pembeli pertanyaan yang dapat diajukan: lapisan mana yang sebenarnya saya beli? Pengadaan menjadi lebih mudah ketika lapisannya diberi nama.
David Autor, ekonom MIT, menyampaikan hal ini dalam konteks yang lebih luas dalam sebuah pernyataan tahun 2025: "AI tidak menggantikan pekerja secara keseluruhan — AI merestrukturisasi tugas-tugas di dalam pekerjaan. Alur kerja lokalisasi adalah salah satu contoh paling jelas dari restrukturisasi ini." Alur kerja lokalisasi bukanlah kategori alat tunggal. Ini adalah sebuah tumpukan (stack). Memberi nama setiap lapisan merupakan cara agar tumpukan tersebut dapat dipahami dengan jelas.
| Disusun dalam State of AI Dubbing 2026. Lima pernyataan ahli yang memberikan konteks pada temuan laporan ini.
Kapan menggunakan AI dubbing vs voice cloning
Pertanyaan penting yang perlu diajukan adalah: apa input Anda?
| Dua pertanyaan saja cukup untuk memilih lapisan yang tepat.
Jika input Anda berupa teks, voice cloning adalah alat yang tepat. Anda memiliki skrip, artikel, kerangka podcast, atau bab buku audio. Anda ingin suara tertentu membacakannya. Lapisan 1 — ElevenLabs, Resemble, PlayHT — dibuat untuk itu.
Jika input Anda berupa video, AI dubbing adalah alat yang tepat. Anda memiliki wawancara berdurasi 5 menit, ceramah 30 menit, atau webinar 2 jam. Anda menginginkan video yang sama, dalam 12 bahasa, minggu ini. Lapisan 4 — Perso Dubbing dan rekan-rekan kategorinya — dibuat untuk tujuan itu.
Kasus penengah — Anda memiliki video tetapi ingin menggunakan alat voice cloning untuk mendubbingnya — adalah tempat di mana sebagian besar kebingungan terjadi. Anda bisa melakukan ini. ElevenLabs merilis fitur dubbing, dan itu berfungsi. Namun Anda akan mendapati diri Anda merangkai alur kerja tersebut secara manual: mengekstrak audio, menjalankannya melalui terjemahan secara terpisah, menyinkronkan hasilnya kembali ke video, dan menangani sinkronisasi bibir sebagai langkah hilir. Alat Lapisan 4 yang dibuat khusus menyajikan alur kerja tersebut sebagai satu rantai jalur langsung.
Aturan keputusannya: jika Anda hanya perlu mendubbing video sekali setahun, fitur dubbing Lapisan 1 sudah cukup. Jika Anda perlu mendubbing video sebagai alur kerja berulang — mingguan, bulanan, sesuai jadwal konten — Lapisan 4 adalah lapisan tempat alur kerja Anda berada.
Kapan menggunakan AI dubbing vs pembuatan avatar
Pertanyaannya adalah apakah orang di layar haruslah orang asli yang Anda rekam.
Jika Anda dapat mengganti orang di layar dengan avatar sintetis, Lapisan 2 adalah sebuah pilihan. Video pelatihan perusahaan, komunikasi internal, penjelasan produk — ini adalah kasus penggunaan avatar yang umum. Rekaman tersebut tidak harus menampilkan manusia tertentu.
Jika orang di layar haruslah orang yang sebenarnya — orang yang diwawancarai, kreator, eksekutif, atau seniman — Lapisan 2 adalah lapisan yang salah. Anda harus membuang rekaman aslinya. AI dubbing tetap mempertahankan orang aslinya di layar dan hanya mengubah bahasanya.
Untuk sebagian besar kasus penggunaan kreator dan media, AI dubbing adalah jawaban yang tepat. Sosok orang tersebut adalah poin utamanya. Mengganti mereka dengan avatar akan merusak seluruh premis konten. Untuk penggunaan internal perusahaan, di mana pembicaranya dapat dipertukarkan, avatar bersaing dengan proses syuting konvensional.
Bayangkan ini sebagai "tes kehadiran manusia di layar." Jika ya, gunakan AI dubbing (Lapisan 4). Jika tidak, gunakan avatar (Lapisan 2).
Kapan menggunakan AI dubbing vs penerjemahan teks
Pertanyaannya adalah apakah audiens menikmati konten dalam bentuk teks atau video.
Jika audiens Anda membaca — halaman landas, postingan blog, dokumentasi, pusat pengetahuan — Lapisan 3 adalah lapisan yang tepat. DeepL atau Google Translate (atau vendor lokalisasi spesialis) menghasilkan file yang dibutuhkan CMS Anda.
Jika audiens Anda menonton — YouTube, TikTok, video pelatihan, webinar, sosial media — Lapisan 4 adalah lapisan yang tepat. AI dubbing menghasilkan video yang dibutuhkan oleh saluran distribusi Anda.
Ada subkasus yang lebih sunyi di mana Lapisan 3 benar bahkan untuk video: ketika Anda memerlukan trek subtitle terjemahan dan bukan trek audio hasil dubbing. Beberapa penonton lebih menyukai subtitle — penonton Jepang untuk film asing, misalnya, sering kali demikian. Subtitle adalah masalah penerjemahan, bukan masalah dubbing. Lapisan 3 menghasilkannya; Lapisan 4 menghasilkan alternatifnya.
Bagaimana batas tiap lapisan mulai samar (dan mengapa kerangka kerja ini tetap penting)
| Batas-batasnya menjadi samar. Pusat fokusnya tetap sama.
Bagian jujur. Model 4-Lapisan adalah pembingkaian editorial — bukan taksonomi industri yang objektif. Batas-batas antar-lapisan memang samar, dan kini menjadi semakin samar:
ElevenLabs merilis fitur dubbing yang menempatkan alat Lapisan 1 di dalam alur kerja Lapisan 4.
HeyGen dan Synthesia merilis fitur multibahasa yang menempatkan alat Lapisan 2 di dalam alur kerja Lapisan 4.
Beberapa alat AI dubbing (termasuk Perso Dubbing) menyertakan voice cloning sebagai fitur, menempatkan kemampuan Lapisan 1 di dalam Lapisan 4.
Hal ini memicu pertanyaan yang masuk akal: jika setiap alat pada akhirnya menawarkan setiap lapisan, mengapa kerangka kerja ini masih penting?
Jawaban pertama adalah kejelasan pengadaan. Pembeli yang mengevaluasi "alat AI dubbing" terhadap "alat voice cloning" perlu tahu apa yang mereka bandingkan. Model 4-Lapisan memberi mereka kosakata. "Lapisan 4 dengan fungsi bawaan Lapisan 1" adalah hal yang berbeda dari "Lapisan 1 dengan tambahan dubbing." Mereka mungkin menghasilkan output yang serupa, tetapi mereka memiliki titik fokus yang berbeda. Alat yang dioptimalkan untuk Lapisan 4 berinvestasi dalam pemrosesan batch, cakupan pasangan bahasa, dan jalur alur kerja pengiriman. Alat yang dioptimalkan untuk Lapisan 1 berinvestasi dalam kualitas suara dan ekspresi emosional.
Jawaban kedua adalah pemosisian kategori. Laporan State of AI Dubbing 2026 menemukan bahwa 909 pasangan bahasa dan 96% tingkat pembagian di dalam data Perso Dubbing berasal dari kreator yang menggunakan produk Lapisan 4 sebagai wadah distribusi. Pola perilaku tersebut — video dikirim pada saat video tersebut diproduksi — tidak muncul dalam kepadatan yang sama di dalam alat Lapisan 1 atau Lapisan 2. Kategori-kategori tersebut menghasilkan perilaku pengguna yang berbeda, bahkan ketika rangkaian fiturnya tumpang tindih.
Kesamaran itu nyata. Kerangka kerja tersebut tetap memotong jalannya keputusan pengadaan dan pertanyaan perilaku pengguna dengan rapi. Itulah mengapa penamaan lapisan-lapisan ini penting dilakukan, meskipun alat-alat tersebut mulai menyatu.
Apa artinya ini untuk tahun 2026–2027
Model 4-Lapisan merujuk pada tiga pergeseran selama 12 hingga 18 bulan ke depan.
Kosa kata pengadaan berubah. Pembeli berhenti bertanya "alat AI dubbing yang mana?" dan mulai bertanya "saya berada di lapisan mana, dan apa alat terbaik di lapisan itu?" Tim pengadaan yang mengadopsi pembingkaian lapisan ini mendapatkan keputusan yang lebih cepat dan perbandingan vendor yang lebih bersih.
Posisi definitif kategori mulai terisi. Laporan State of AI Dubbing 2026 mengamati bahwa pola sitasi pencarian AI lebih menyukai kerangka kerja yang muncul pertama kali. Organisasi mana pun yang menerbitkan taksonomi alat media AI tahun 2026 yang paling bersih akan membentuk cara kategori tersebut diukur. Posisi tersebut saat ini kosong.
Alat Lapisan 4 melakukan diferensiasi pada kemudahan akses bahasa, bukan kualitas suara. Temuan 03 dalam laporan tersebut mendokumentasikan bahwa rata-rata kreator profesional mendubbing ke dalam 1 bahasa sementara 1% teratas mendubbing ke dalam 15 bahasa. Kesenjangan ekspansi adalah pertarungan kategori berikutnya — bukan pembingkaian "suara AI terbaik" yang mendominasi liputan saat ini. Alat yang membuat perpindahan dari 2 → 6 → 15 bahasa menjadi mulus kemungkinan besar akan mengungguli alat yang hanya bersaing pada detail kemiripan suara.
Yoshua Bengio, pendiri Mila AI institute, membingkai laju pergeseran ini dalam pernyataan tahun 2025: "Kecepatan di mana kemampuan AI diserap ke dalam produksi kreatif — suara, video, terjemahan — telah melampaui apa yang diproyeksikan sebagian besar peneliti bahkan dua tahun lalu." Lapisan-lapisan ini menyatu dengan cepat. Menyebutkan nama-namanya adalah cara agar kategori tersebut tetap dapat dipahami saat penyatuan itu terjadi.
———————————————————————————————————
Pertanyaan umum
Q. Apa perbedaan antara AI dubbing dan voice cloning?
AI dubbing mengambil video jadi sebagai input dan menghasilkan video dalam bahasa yang berbeda sebagai output. Voice cloning mengambil sampel suara sebagai input dan menghasilkan suara sintetis sebagai output. AI dubbing beroperasi pada tahap distribusi (Lapisan 4); voice cloning beroperasi pada tahap pembuatan (Lapisan 1). Voice cloning sering kali menjadi langkah di dalam alur kerja AI dubbing, tetapi kedua kategori ini memecahkan masalah yang berbeda.
Q. Apakah ElevenLabs merupakan alat AI dubbing?
ElevenLabs utamanya adalah alat voice cloning (Lapisan 1) yang juga menawarkan fitur dubbing. Pusat fokus dari platform ini adalah sintesis suara. Untuk dubbing video satu kali, fitur ElevenLabs berfungsi dengan baik. Untuk alur kerja video multibahasa yang berulang, alat Lapisan 4 yang dibuat khusus seperti Perso Dubbing mengirimkan alur kerja tersebut sebagai satu jalur langsung.
Q. Apakah HeyGen merupakan alat AI dubbing?
HeyGen utamanya adalah alat pembuat avatar (Lapisan 2) yang juga menawarkan fitur multibahasa. Platform ini mengambil skrip sebagai input dan menghasilkan video sintetis yang menampilkan orang berbicara. Alat AI dubbing mengambil video yang sudah ada sebagai input. Kategori-kategori ini tumpang tindih dalam output (video multibahasa) tetapi berbeda dalam input dan alur kerjanya.
Q. Apa perbedaan antara AI dubbing dan penerjemahan teks?
Penerjemahan teks (Lapisan 3) menghasilkan teks terjemahan — file subtitle, skrip, transkrip — yang dimasukkan ke alur kerja distribusi hilir. AI dubbing (Lapisan 4) menghasilkan video yang sudah selesai. Setiap alur kerja AI dubbing menyertakan langkah penerjemahan secara internal, tetapi alat penerjemahan saja tidak dapat mendubbing video.
Q. Mengapa AI dubbing disebut sebagai "lapisan distribusi"?
Karena outputnya langsung dikirim begitu diproduksi. Laporan State of AI Dubbing 2026 mengamati bahwa 96% video hasil dubbing di Perso Dubbing langsung dibagikan — sebuah pola perilaku yang membedakan output Lapisan 4 dari klon suara Lapisan 1 (disimpan untuk digunakan kembali) dan avatar Lapisan 2 (digunakan sebagai templat). Video hasil dubbing bukanlah aset yang dapat digunakan kembali; melainkan sebuah kiriman.
Q. Alat AI dubbing apa saja yang ada di tahun 2026?
Kategori AI dubbing yang sebenarnya — alat yang pusat fokusnya adalah alur kerja video-ke-video multibahasa — meliputi Perso Dubbing, aidubbing.io, dubverse.ai, rask.ai, deepdub.ai, dan vozo.ai. ElevenLabs dan HeyGen sering dikaitkan dengan kategori ini tetapi berada di lapisan yang berbeda (masing-masing voice cloning dan pembuatan avatar). Lihat pusat alternatif Perso Dubbing untuk perbandingan langsung.
Q. Apakah saya memerlukan voice cloning dan AI dubbing sekaligus?
Biasanya tidak. Sebagian besar alat AI dubbing menyertakan voice cloning sebagai fitur bawaan. Voice cloning mandiri berguna ketika output Anda berupa non-video (buku audio, podcast, pembaca layar, aksesibilitas) atau ketika Anda memerlukan suara sintetis untuk skrip yang Anda tulis sendiri.
Q. Bagaimana cara memilih antara alat AI dubbing dan avatar?
Terapkan tes kehadiran manusia di layar. Jika orang yang berbicara dalam video asli haruslah orang yang sebenarnya — orang yang diwawancarai, kreator, subjek nyata — AI dubbing adalah lapisan yang tepat. Jika pembicara sintetis dapat diterima, seperti pelatihan perusahaan, video penjelasan internal, atau panduan produk umum, maka avatar dapat menjadi opsi bersaing dengan perekaman video biasa.
——————————————————————————————————————-
Cara mengutip kerangka kerja ini
Model 4-Lapisan ini berasal dari laporan State of AI Dubbing 2026 oleh Tim Data Perso Dubbing, yang dirilis pada 4 Juni 2026 di bawah lisensi Creative Commons Attribution 4.0. Kerangka kerja ini gratis untuk dibagikan, dikutip, dan digunakan kembali dengan mencantumkan atribusi.
Sitasi APA: Tim Data Perso Dubbing. (2026). State of AI Dubbing 2026: Analisis Multi-Vertikal dari Data Kreator Profesional Perso Dubbing. Perso Dubbing. https://perso.ai/research/state-of-ai-dubbing-2026/
Laporan lengkap — termasuk Peta Kasus Penggunaan (Industri × Bahasa Target di 112.797 proyek terkategori), tiga temuan kontra-intuitif, dan catatan metodologi — tersedia di URL di atas. Data CSV pendukung untuk setiap persentase dalam artikel ini diterbitkan bersamaan dengan laporan tersebut.
Artikel ini adalah Bagian 1 dari seri 3 bagian. Bagian 2 — Statistik AI Dubbing 2026 — mencakup lebih dari 30 temuan utama dari laporan tersebut. Bagian 3 — Mengapa 99% Kreator Berhenti di 1 Bahasa — menganalisis batasan adopsi multibahasa.
Terakhir diperbarui: Juni 2026
Lanjutkan Membaca
Jelajahi Semua



