Как научить ИИ колебаться: вычисления во время инференса и искусство вдумчивого перевода
Последнее обновление


Перейти к разделу
Перейти к разделу
Поделиться
Поделиться
Поделиться

Инструмент для перевода видео с помощью AI, локализации и озвучки
Попробуйте бесплатно
Как научить ИИ колебаться
Несколько дней назад мне попался ролик на YouTube. Новостной ведущий Сон Сок Хи брал интервью у писательницы Ким Э Ран. Был задан вопрос: «Что есть у человека, чего нет у ИИ?», и её ответом было: «Колебание».
Писательница вспомнила момент из одной давней передачи ведущего. Сообщая новость о кончине покойного Но Хве Чхана, активиста рабочего движения, ставшего политиком, он потерял дар речи на двадцать секунд. Момент сдерживания слов, нерешительности и осмысления — колебание. ИИ на это не способен. И все же колебание человека становится утешением и вежливостью.
Это было около двадцати лет назад, когда я был сосредоточен на разработке шутера. Коллега по команде, занимавшийся 3D-моделированием персонажей, протянул мне книгу со словами: «Мой школьный друг — писатель, тебе стоит это прочесть». Глубокие наблюдения, приправленные остроумием. Я был полностью поглощен. Книгой оказался сборник рассказов Ким Э Ран «Беги, папа, беги» (달려라 아비). С тех пор я её преданный поклонник.
Для колебания требуются время и меньшая уверенность
Ким Э Ран рассказывала, что её писательские навыки крепли благодаря кропотливой работе и сомнениям над каждой строчкой. Она говорила, что время, проведенное между предложениями, становится проявлением деликатности к окружающим. Она также высказала мысль, что истинная ценность литературы кроется не в содержании, а в её форме. Но если форма тоже имеет значение, возможно, ИИ сможет хотя бы грубо её сымитировать?
С точки зрения физики, время — это изменение физического состояния. В физике время не проходит, если состояние не меняется. Таким время, меньшее изменение состояния эквивалентно более медленному течению времени, а большее изменение — более длительному времени. Мимолетная секунда для человека — это вечность для ИИ, растянутая на сотни миллиардов или даже триллионы операций с плавающей запятой (FLOPs). По сравнению с прежним программным обеспечением, недавние ответы ИИ — это результат долгой, мучительной и тяжелой работы. Именно поэтому доходы индустрии ИИ могут расти, в то время как прибыль дается с трудом. С точки зрения традиционного ПО, ИИ работает слишком медленно для машины. Даже такая простая вещь, как проверка формата JSON, при запуске через инференс большой языковой модели требует сотен миллионов вычислений по сравнению с традиционным ПО.
Большие языковые модели (LLM), двигатель недавнего прогресса ИИ, представляют собой программы, которые предсказывают следующее слово в предложении. ИИ пропускает электрический ток, чтобы найти следующее слово. Он многократно умножает и складывает огромные матрицы. Вычисления ИИ требуют физического износа оборудования. Чтобы наделить ИИ хотя бы подобием колебания — аналогом человеческих мук выбора, — вы подвергаете его интенсивным вычислениям. Сотни миллиардов операций для генерации всего одного следующего слова. Затем следуют еще сотни миллиардов операций для генерации слова после него.
Большинство современных вычислений глубокого обучения включают в себя взвешенные суммы, а предварительно рассчитанные значения, используемые в этих суммах, известны как параметры.
Когда мы говорим о модели «Qwen 3.6 27B», это означает, что 27 миллиардов параметров готовы к суммированию весов, требуя около 27 миллиардов умножений для предсказания всего одного следующего токена. И это только начало. Более того, одно умножение целых чисел включает десятки логических операций, а для операции с плавающей запятой требуются тысячи. Учитывая такую сложность, это можно назвать умопомрачительным.
Понижение температуры усиливает предвзятость
Давайте подробнее разберем, как работают LLM. Уже стало общеизвестным, что глубокое обучение, основа у LLM, представляет собой машину сопоставления шаблонов, которая применяет заученные во время обучения паттерны на практике. Этим процессом воспроизведения управляют две вещи: сэмплирование токенов и температура.
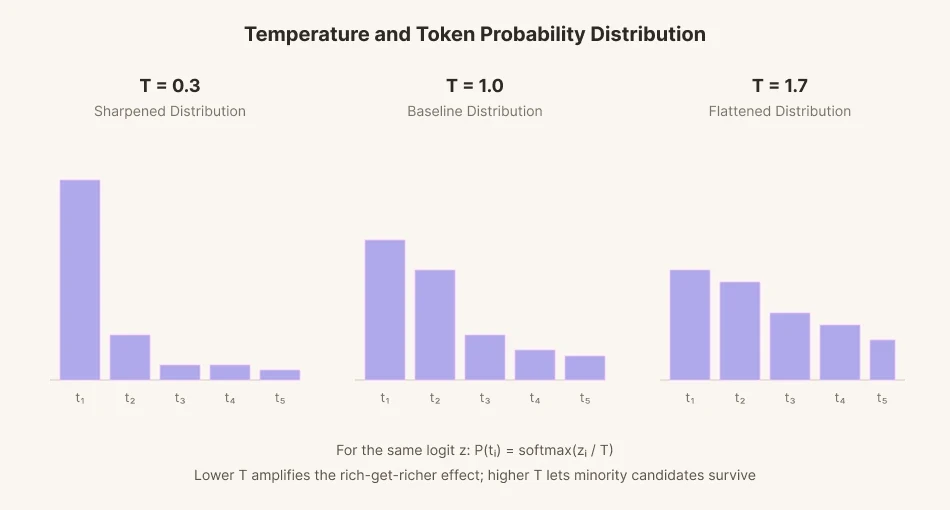
Чтобы предсказать одно следующее слово, модель присваивает оценку (logit) каждому из десятков тысяч слов-кандидатов. Затем эти оценки преобразуются в вероятности, и слово выбирается пропорционально каждой вероятности. Этот процесс называется сэмплированием (выборкой).
Чтобы добавить разнообразия в выборку, был введен математический параметр под названием «температура». Снизьте температуру, и разрыв между оценками кандидатов растянется до крайности. Слова с высокой вероятностью будут выбираться гораздо чаще, чем слова на базовом уровне. Слова с низкой вероятностью будут выбираться еще реже. Это похоже на то, как богатые богатеют, а бедные беднеют. И наоборот, при повышении температуры разрыв сокращается. Он сглаживается и выравнивается. Слова с низкой вероятностью, которые обычно были бы пропущены, при повышении температуры могут выбираться с большей частотой.
Человеческий язык устроен похожим образом. Группа и культура, к которым я принадлежу, отражаются в вероятностном распределении моего языка. Более холодный, резкий язык порождает речь более рациональную, более оптимизированную и более соответствующую мнению большинства. Более теплый, мягкий язык менее рационален и менее оптимизирован, но учитывает мнение меньшинства.
Деликатность — это акт затраты дополнительной энергии для выхода за рамки вероятностного распределения собственных мыслей. Это означает замечать то, что скрывает большинство, и находить предложения, которые обычно не используются. То, что писательница назвала кропотливым процессом написания, для ИИ должно стать актом отказа от ответов, основанных исключительно на предвзятом обучении, и попыткой выйти за эти рамки.
Механическое беспокойство
Как мы могли бы научить ИИ быть деликатным? Нельзя позволять ему выдавать наиболее вероятное слово сразу. Это просто экспортирует предвзятость, присущую обучающим данным.
Причина, по которой сегодняшние модели ИИ достигают столь поразительных результатов, заключается в том, что в этой области продвинулись технологии, ориентированные на «вычисления во время инференса» (Inference-Time Compute). Это технология предоставления ИИ большего времени на вычисления перед ответом. Прежние модели ИИ просто выдавали первый вычисленный ответ, иными словами, то, что первым приходило на ум. Напротив, сегодняшние мыслящие модели генерируют несколько путей рассуждения.
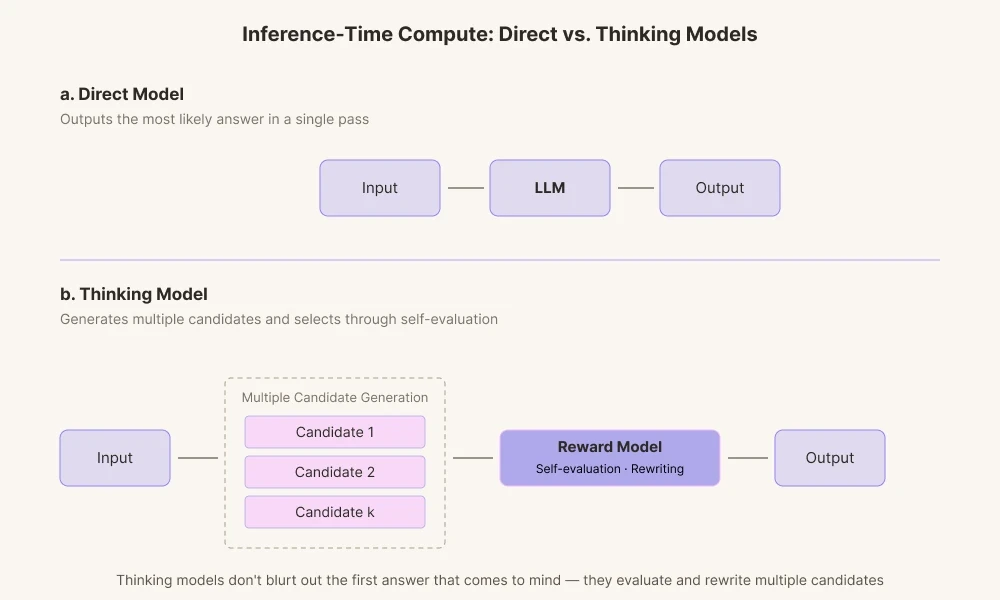
Они создают различные варианты ответов и оценивают их с помощью своей внутренней модели вознаграждения. Запускается процесс проверки того, соответствуют ли слова контексту и не кажутся ли они слишком категоричными, а затем, при необходимости, они отбрасываются внутри системы.
Это похоже на то, как люди мысленно редактируют предложения перед тем, как произнести их вслух. Вместо того чтобы требовать от ИИ выдать максимально точный ответ на основе вероятностных распределений, вычислительные ресурсы тратятся на то, чтобы дать ему время на редактирование. Мы позволяем ему отклоняться от центра распределения вероятностей к краям — своего рода механическое беспокойство.
Беспокойство в видеопереводе
Обычный перевод завершается, как только передан смысл, но перевод видео требует не только точного смысла, но также соответствия длины и тайминга движений губ.
Если актер на экране шевелит губами в течение 1,8 секунды и произносит 11 английских слогов, переводчик должен составить корейскую реплику, которая уложится в эти 1.8 секунды. Сохранишь смысл — нарушится длина. Подгонишь под длину — смажется смысл. Когда закрывающие согласные и открытые гласные отличаются от оригинала, зритель чувствует неладное в тот же миг, как видит это. Субтитры накладывают еще одно ограничение: скорость чтения от 12 до 15 символов в секунду. Поэтому переводчик, работающий с дубляжом, набрасывает пять вариантов строк с эквивалентным значением, считает слоги, сопоставляет ударения и выбирает не самый точный перевод, а тот, который теряет меньше всего в рамках заданных ограничений.
Команда переводчиков Perso Dubbing работала именно над этой проблемой. Команда опубликовала статью на EMNLP (https://aclanthology.org/2025.emnlp-demos.37), в которой количественно оценивается компромисс между изохронией (соблюдением длины) и семантическим соответствием в видеопереводе.
EMNLP (Empirical Methods in Natural Language Processing) — это ведущая конференция в области обработки естественного языка. Соответствуя своему названию, она ценит эмпирические исследования, доказывающие эффективность технологии в реальном мире с помощью данных и экспериментов, а не чисто теоретические гипотезы. В соответствии с этим характером, статья исследовательской группы ESTsoft берет сложную проблему в видеопереводе, количественно оценивает её с помощью данных и решает с помощью алгоритма. Практический вклад в реальный мир.
Ключевой вопрос, который учитывает пайплайн дубляжа Perso Dubbing, кроется именно здесь. Не символы, не слоги, а фонема, которая является мельчайшей единицей речи. Символы и слоги — это единицы на экране; фонемы же соответствуют времени, фактически затрачиваемому на произношение. Алгоритм, предложенный в статье, CountPhonemes, подсчитывает количество фонем в переведенном предложении, сравнивает его с целевым количеством фонем и изменяет предложение, чтобы привести их в соответствие.
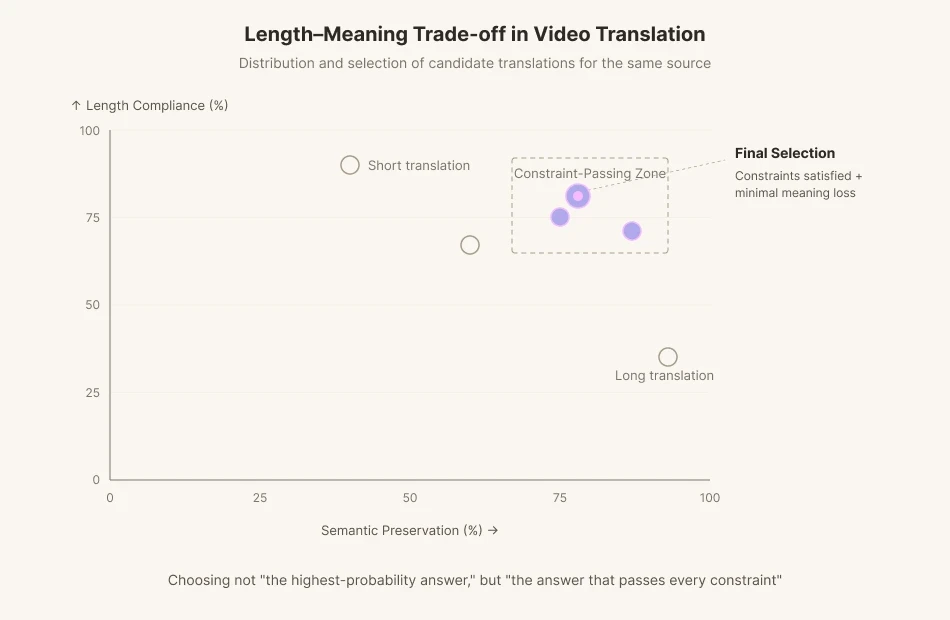
Существующие модели машинного перевода оптимизированы под метрики сохранения смысла, такие как BLEU и COMET. Их обучают выдавать наиболее правдоподобный перевод как можно быстрее. Но в видеопереводе иногда приходится отказываться от самого правдоподобного варианта. Когда фонем не хватает, приходится жертвовать частью смысла и искать другую формулировку. Мы просим ИИ не о «наиболее вероятном ответе», а об «ответe, который удовлетворяет всем ограничениям».
Именно это и решает пайплайн дубляжа Perso Dubbing. На этапе перевода система генерирует множество кандидатов, удовлетворяющих ограничениям по длине и фонемам, а затем выбирает вариант с наименьшими семантическими потерями. Это концепция вычислений во время инференса из предыдущего раздела, перенесенная в сферу дубляжа. Не давать модели выпалить первый пришедший на ум ответ. Заставить её переписать. Заставить её проверить. Этот итеративный перевод — намеренное колебание, навязанное машине. Внутри итеративного цикла обратной связи модель ищет оптимум между соблюдением длины (изохронией) и соответствием смысла (семантическим соответствием). Это работа по переносу мук выбора видеопереводчика в саму модель.
В заключение
Колебание — это не просто несовершенство, не просто замедление. Это накопление времени, потраченного на проявление деликатности к другим. Если ИИ когда-нибудь научится делать паузы ради деликатности, это произойдет не потому, что модель стала умнее. Это произойдет потому, что мы спроектировали её так, чтобы она была менее уверенной, дольше размышляла и умела колебаться.
Как научить ИИ колебаться
Несколько дней назад мне попался ролик на YouTube. Новостной ведущий Сон Сок Хи брал интервью у писательницы Ким Э Ран. Был задан вопрос: «Что есть у человека, чего нет у ИИ?», и её ответом было: «Колебание».
Писательница вспомнила момент из одной давней передачи ведущего. Сообщая новость о кончине покойного Но Хве Чхана, активиста рабочего движения, ставшего политиком, он потерял дар речи на двадцать секунд. Момент сдерживания слов, нерешительности и осмысления — колебание. ИИ на это не способен. И все же колебание человека становится утешением и вежливостью.
Это было около двадцати лет назад, когда я был сосредоточен на разработке шутера. Коллега по команде, занимавшийся 3D-моделированием персонажей, протянул мне книгу со словами: «Мой школьный друг — писатель, тебе стоит это прочесть». Глубокие наблюдения, приправленные остроумием. Я был полностью поглощен. Книгой оказался сборник рассказов Ким Э Ран «Беги, папа, беги» (달려라 아비). С тех пор я её преданный поклонник.
Для колебания требуются время и меньшая уверенность
Ким Э Ран рассказывала, что её писательские навыки крепли благодаря кропотливой работе и сомнениям над каждой строчкой. Она говорила, что время, проведенное между предложениями, становится проявлением деликатности к окружающим. Она также высказала мысль, что истинная ценность литературы кроется не в содержании, а в её форме. Но если форма тоже имеет значение, возможно, ИИ сможет хотя бы грубо её сымитировать?
С точки зрения физики, время — это изменение физического состояния. В физике время не проходит, если состояние не меняется. Таким время, меньшее изменение состояния эквивалентно более медленному течению времени, а большее изменение — более длительному времени. Мимолетная секунда для человека — это вечность для ИИ, растянутая на сотни миллиардов или даже триллионы операций с плавающей запятой (FLOPs). По сравнению с прежним программным обеспечением, недавние ответы ИИ — это результат долгой, мучительной и тяжелой работы. Именно поэтому доходы индустрии ИИ могут расти, в то время как прибыль дается с трудом. С точки зрения традиционного ПО, ИИ работает слишком медленно для машины. Даже такая простая вещь, как проверка формата JSON, при запуске через инференс большой языковой модели требует сотен миллионов вычислений по сравнению с традиционным ПО.
Большие языковые модели (LLM), двигатель недавнего прогресса ИИ, представляют собой программы, которые предсказывают следующее слово в предложении. ИИ пропускает электрический ток, чтобы найти следующее слово. Он многократно умножает и складывает огромные матрицы. Вычисления ИИ требуют физического износа оборудования. Чтобы наделить ИИ хотя бы подобием колебания — аналогом человеческих мук выбора, — вы подвергаете его интенсивным вычислениям. Сотни миллиардов операций для генерации всего одного следующего слова. Затем следуют еще сотни миллиардов операций для генерации слова после него.
Большинство современных вычислений глубокого обучения включают в себя взвешенные суммы, а предварительно рассчитанные значения, используемые в этих суммах, известны как параметры.
Когда мы говорим о модели «Qwen 3.6 27B», это означает, что 27 миллиардов параметров готовы к суммированию весов, требуя около 27 миллиардов умножений для предсказания всего одного следующего токена. И это только начало. Более того, одно умножение целых чисел включает десятки логических операций, а для операции с плавающей запятой требуются тысячи. Учитывая такую сложность, это можно назвать умопомрачительным.
Понижение температуры усиливает предвзятость
Давайте подробнее разберем, как работают LLM. Уже стало общеизвестным, что глубокое обучение, основа у LLM, представляет собой машину сопоставления шаблонов, которая применяет заученные во время обучения паттерны на практике. Этим процессом воспроизведения управляют две вещи: сэмплирование токенов и температура.
Чтобы предсказать одно следующее слово, модель присваивает оценку (logit) каждому из десятков тысяч слов-кандидатов. Затем эти оценки преобразуются в вероятности, и слово выбирается пропорционально каждой вероятности. Этот процесс называется сэмплированием (выборкой).
Чтобы добавить разнообразия в выборку, был введен математический параметр под названием «температура». Снизьте температуру, и разрыв между оценками кандидатов растянется до крайности. Слова с высокой вероятностью будут выбираться гораздо чаще, чем слова на базовом уровне. Слова с низкой вероятностью будут выбираться еще реже. Это похоже на то, как богатые богатеют, а бедные беднеют. И наоборот, при повышении температуры разрыв сокращается. Он сглаживается и выравнивается. Слова с низкой вероятностью, которые обычно были бы пропущены, при повышении температуры могут выбираться с большей частотой.
Человеческий язык устроен похожим образом. Группа и культура, к которым я принадлежу, отражаются в вероятностном распределении моего языка. Более холодный, резкий язык порождает речь более рациональную, более оптимизированную и более соответствующую мнению большинства. Более теплый, мягкий язык менее рационален и менее оптимизирован, но учитывает мнение меньшинства.
Деликатность — это акт затраты дополнительной энергии для выхода за рамки вероятностного распределения собственных мыслей. Это означает замечать то, что скрывает большинство, и находить предложения, которые обычно не используются. То, что писательница назвала кропотливым процессом написания, для ИИ должно стать актом отказа от ответов, основанных исключительно на предвзятом обучении, и попыткой выйти за эти рамки.
Механическое беспокойство
Как мы могли бы научить ИИ быть деликатным? Нельзя позволять ему выдавать наиболее вероятное слово сразу. Это просто экспортирует предвзятость, присущую обучающим данным.
Причина, по которой сегодняшние модели ИИ достигают столь поразительных результатов, заключается в том, что в этой области продвинулись технологии, ориентированные на «вычисления во время инференса» (Inference-Time Compute). Это технология предоставления ИИ большего времени на вычисления перед ответом. Прежние модели ИИ просто выдавали первый вычисленный ответ, иными словами, то, что первым приходило на ум. Напротив, сегодняшние мыслящие модели генерируют несколько путей рассуждения.
Они создают различные варианты ответов и оценивают их с помощью своей внутренней модели вознаграждения. Запускается процесс проверки того, соответствуют ли слова контексту и не кажутся ли они слишком категоричными, а затем, при необходимости, они отбрасываются внутри системы.
Это похоже на то, как люди мысленно редактируют предложения перед тем, как произнести их вслух. Вместо того чтобы требовать от ИИ выдать максимально точный ответ на основе вероятностных распределений, вычислительные ресурсы тратятся на то, чтобы дать ему время на редактирование. Мы позволяем ему отклоняться от центра распределения вероятностей к краям — своего рода механическое беспокойство.
Беспокойство в видеопереводе
Обычный перевод завершается, как только передан смысл, но перевод видео требует не только точного смысла, но также соответствия длины и тайминга движений губ.
Если актер на экране шевелит губами в течение 1,8 секунды и произносит 11 английских слогов, переводчик должен составить корейскую реплику, которая уложится в эти 1.8 секунды. Сохранишь смысл — нарушится длина. Подгонишь под длину — смажется смысл. Когда закрывающие согласные и открытые гласные отличаются от оригинала, зритель чувствует неладное в тот же миг, как видит это. Субтитры накладывают еще одно ограничение: скорость чтения от 12 до 15 символов в секунду. Поэтому переводчик, работающий с дубляжом, набрасывает пять вариантов строк с эквивалентным значением, считает слоги, сопоставляет ударения и выбирает не самый точный перевод, а тот, который теряет меньше всего в рамках заданных ограничений.
Команда переводчиков Perso Dubbing работала именно над этой проблемой. Команда опубликовала статью на EMNLP (https://aclanthology.org/2025.emnlp-demos.37), в которой количественно оценивается компромисс между изохронией (соблюдением длины) и семантическим соответствием в видеопереводе.
EMNLP (Empirical Methods in Natural Language Processing) — это ведущая конференция в области обработки естественного языка. Соответствуя своему названию, она ценит эмпирические исследования, доказывающие эффективность технологии в реальном мире с помощью данных и экспериментов, а не чисто теоретические гипотезы. В соответствии с этим характером, статья исследовательской группы ESTsoft берет сложную проблему в видеопереводе, количественно оценивает её с помощью данных и решает с помощью алгоритма. Практический вклад в реальный мир.
Ключевой вопрос, который учитывает пайплайн дубляжа Perso Dubbing, кроется именно здесь. Не символы, не слоги, а фонема, которая является мельчайшей единицей речи. Символы и слоги — это единицы на экране; фонемы же соответствуют времени, фактически затрачиваемому на произношение. Алгоритм, предложенный в статье, CountPhonemes, подсчитывает количество фонем в переведенном предложении, сравнивает его с целевым количеством фонем и изменяет предложение, чтобы привести их в соответствие.
Существующие модели машинного перевода оптимизированы под метрики сохранения смысла, такие как BLEU и COMET. Их обучают выдавать наиболее правдоподобный перевод как можно быстрее. Но в видеопереводе иногда приходится отказываться от самого правдоподобного варианта. Когда фонем не хватает, приходится жертвовать частью смысла и искать другую формулировку. Мы просим ИИ не о «наиболее вероятном ответе», а об «ответe, который удовлетворяет всем ограничениям».
Именно это и решает пайплайн дубляжа Perso Dubbing. На этапе перевода система генерирует множество кандидатов, удовлетворяющих ограничениям по длине и фонемам, а затем выбирает вариант с наименьшими семантическими потерями. Это концепция вычислений во время инференса из предыдущего раздела, перенесенная в сферу дубляжа. Не давать модели выпалить первый пришедший на ум ответ. Заставить её переписать. Заставить её проверить. Этот итеративный перевод — намеренное колебание, навязанное машине. Внутри итеративного цикла обратной связи модель ищет оптимум между соблюдением длины (изохронией) и соответствием смысла (семантическим соответствием). Это работа по переносу мук выбора видеопереводчика в саму модель.
В заключение
Колебание — это не просто несовершенство, не просто замедление. Это накопление времени, потраченного на проявление деликатности к другим. Если ИИ когда-нибудь научится делать паузы ради деликатности, это произойдет не потому, что модель стала умнее. Это произойдет потому, что мы спроектировали её так, чтобы она была менее уверенной, дольше размышляла и умела колебаться.
Продолжить чтение
Просмотреть все




