如何教 AI 學會猶豫:推論時運算與審慎翻譯的藝術



人工智能視頻翻譯、定位和配音工具
免費試用
如何教會 AI 猶豫
幾天前,我看到了一段 YouTube 影片。新聞主播孫石熙正在採訪小說家金愛爛。問題是「人類擁有什麼是 AI 所沒有的?」,而她的回答是「猶豫」。
這位小說家提到了主播以往播報中的一個瞬間。在播報已故勞工運動家出身的政治家魯會燦逝世的消息時,他失語了二十秒。那一刻扣字、動搖和辨識的過程——即猶豫。AI 是無法做到這一點的。然而,一個人的猶豫卻能成為安慰與禮貌。
那了大約是二十年前,當時我正專注於開發一款射擊遊戲。一位負責 3D 角色建模的隊友遞給我一本書說:「我的一個高中朋友是小說家,你應該讀讀這個。」這本書充滿了帶著機智的深刻觀察,讓我完全沉浸其中。這本書就是金愛爛的短篇小說集《奔跑吧,爸爸》(달려라 아비)。從那時起,我就成了她的書迷。
猶豫需要時間和較低的確定性
金愛爛說,她的寫作肌肉是通過對每一行字精雕細琢和自我審問而得以強化的。她說,在句子之間花費的時間變成了對他人的體貼。她還提出,文學的真正價值不在於內容,而在於其形式。那麼,如果形式也很重要,也許 AI 至少可以大致模仿它?
從物理學的角度來看,時間是物理狀態的一種變化。在物理學中,如果狀態沒有改變,時間就沒有流逝。因此,狀態變化越少相當於時間越慢,變化越多相當於時間越長。對人類來說彈指一瞬的秒,對 AI 來說卻是跨越數百億甚至數萬億次浮點運算(FLOPs)的永恆。與過去的軟體相比,最近的 AI 回答是漫長、焦慮的艱苦努力之結晶。這也是為什麼 AI 行業在收入增長的同時卻在利潤上苦苦掙扎的緣故。在傳統軟體看來,AI 對於機器來說實在是太慢了。即使是像 JSON 格式驗證這樣簡單的事情,當通過大型語言模型推理運行時,與傳統軟體相比也要消耗數億次計算。
大型語言模型(LLMs)作為 AI 近期取得進展的引擎,是預測句子中下一個單詞的程序。AI 通過運行電流來尋找下一個單詞。它重複地對龐大的矩陣進行乘法和加法。AI 的計算需要硬體的物理消耗。為了讓 AI 具備人類焦慮時光裏那種哪怕是形式上的猶豫,你必須讓它進行密集的計算。產生單個下一個單詞需要數百億次運算。接下來產生其後的單詞又需要另外數百億次運算。
當代深度學習的大多數計算都涉及加權和,而這些求和中使用的預先計算值被稱為參數。
當我們談論 'Qwen 3.6 27B' 模型時,這意味著有 270 億個參數準備進行權重求和,僅預測單個下一個標記(token)就需要約 270 億次乘法。而這僅僅是個開始。此外,單個整數乘法涉及數十個邏輯運算,而浮點數則需要數千個。面對如此的複雜性,人們或許會稱之為令人難以置信。
降低溫度會使偏見更加銳利
讓我們更深入地了解 LLMs 的工作原理。深度學習是 LLMs 的基礎,它是一種模式匹配機器,能將訓練期間記住的模式應用於現實世界的實際使用中,這已成為常識。有兩件事支配著這種反芻過程:標記採樣和溫度。
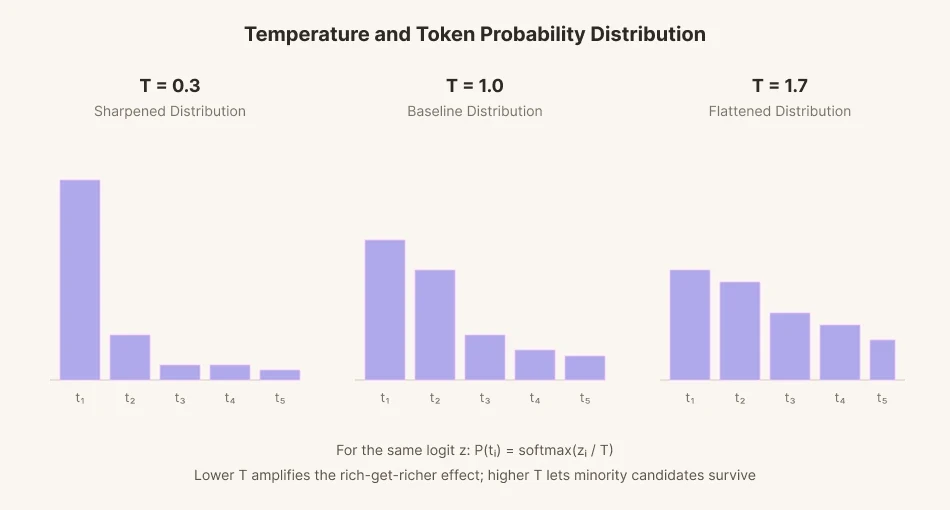
為了預測下一個單詞,模型會為數萬個候選單詞中的每一個分配一個分數(logit)。然後將這些分數轉換為概率,並按每個概率的比例選擇一個單詞。這個過程被稱為採樣。
為了給採樣增加變化,引入了一個名為「溫度」的數學參數。降低溫度後,候選分數之間的差距會拉大到極端。高概率的單詞被選中的頻率高於基線。低概率的單詞被選中的機率甚至更低。這類似於富人越富,窮人越窮。相反,溫度升高時差距會縮小。差距趨於平緩,並變得平均。在溫度升高時,通常會被忽略的低概率單詞可以以更高的比例被選中。
人類語言與此類似。我所屬的群體和文化反映在我的語言概率分布中。更冷、更銳利的語言產生的言論更理性、更優化,也更符合大多數人。更溫暖、更圓潤的語言則不那麼理性,也不那麼優化,但卻考慮到了少數人。
體貼是花費額外的精力走出自己思想的概率分布的行為。這意味著注意到被大多數人遮蔽的東西,並找到通常不會使用的句子。作家所描述的艱苦寫作過程,對 AI 來說,應該成為一種拒絕僅基於有偏見的訓練進行回應,並努力向更遠處探索的行為。
機械式焦慮
我們該如何教导 AI 學會體貼?你不能讓它直接吐出概率最高的詞。那只會輸出訓練數據中固有的偏見。
今天的 AI 模型之所以能取得如此驚人的成果,是因為該領域在「推理時間計算」(Inference-Time Compute)方面取得了先進技術。這是一種在 AI 回答之前給予其更多計算時間的技術。過去的 AI 模型只是簡單地輸出計算出的第一個答案,換句話說就是首先想到的答案。相比之下,今天的思考模型會生成多條推理路徑。
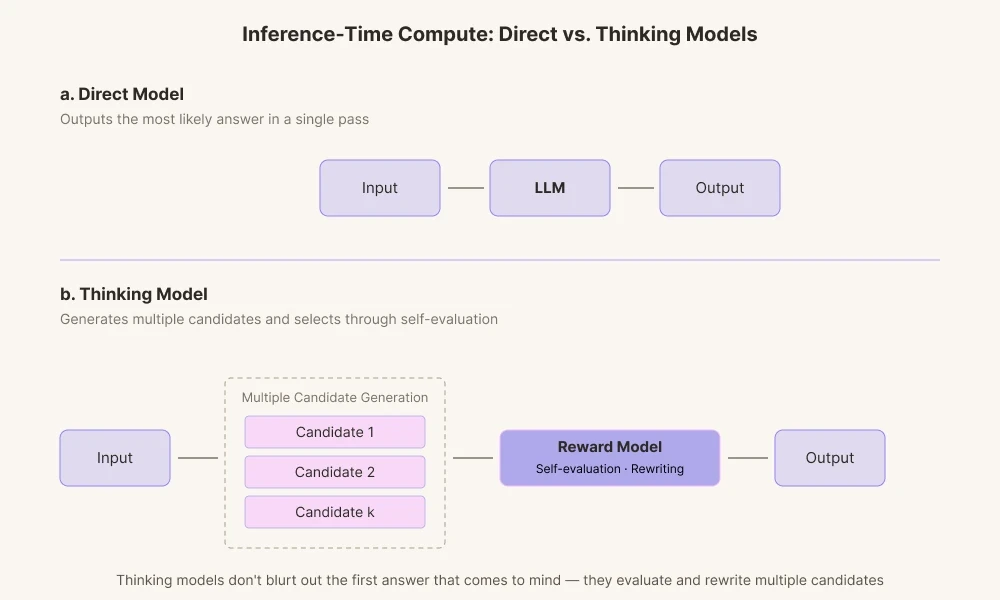
它們產生各種候選答案,並通過其內在的獎勵模型對其進行評分。它會經歷檢查單詞是否符合上下文,以及對它來說這些單詞是否顯得過於絕對的過程,然後在需要時進行內部捨棄。
這類似於人類在說話前在腦海中修改句子。不要求 AI 根據概率分布提供盡可能準確的答案,而是花費計算資源給予其修改的時間。我們讓它從概率質量的中心游離到邊緣:一種機械式的焦慮。
影片翻譯中的焦慮
普通的翻譯只要意思相符即可完成,但影片翻譯不僅要求意思準確,而且字幕的長度與唇形動作的時間也必須匹配。
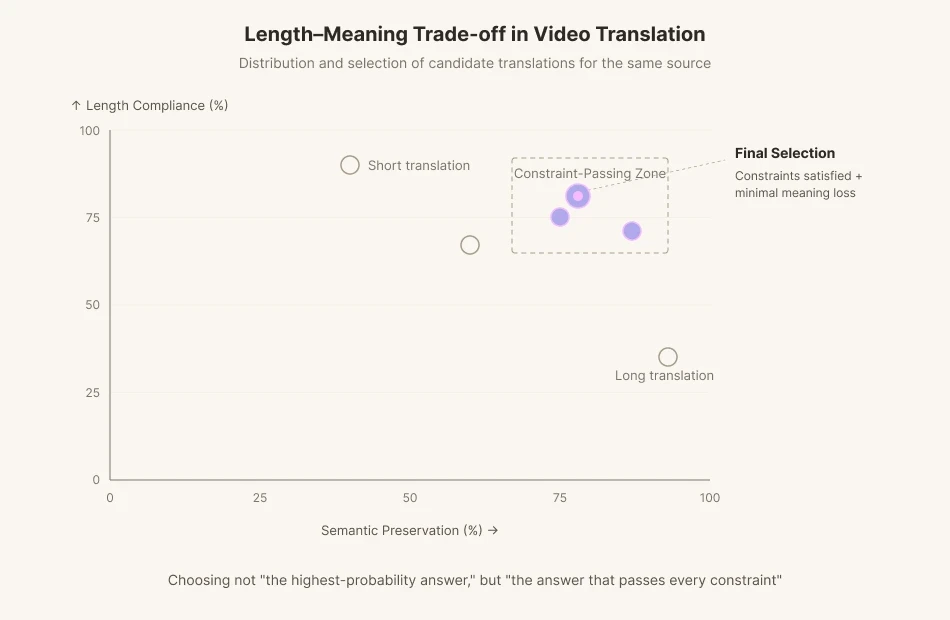
如果屏幕上的演員移動嘴巴 1.8 秒並吐出 11 個英文音節,翻譯人員就必須構建一句能契合這 1.8 秒的韓文台詞。保留意思則長度會崩潰。匹配長度則意思會模糊。當收尾子音和開口元音與原版不同時,觀眾在看到的那一刻就會覺得有些不對勁。字幕帶來了另一個限制:每秒 12 到 15 個字符的閱讀速度。因此,從事配音工作的翻譯人員會列出五行意思相同的句子,計算音節,匹配重音,並且不選擇最準確的翻譯,而是選擇在限制條件中損失最少的翻譯。
Perso Dubbing 的翻譯團隊一直致力於解決這個問題。該團隊在 EMNLP 上發表了一篇論文(https://aclanthology.org/2025.emnlp-demos.37),定量分析了影片翻譯中等時性(長度合規性)與語義對齊之間的權衡。
EMNLP(自然語言處理中的經驗方法會議)是自然語言處理領域的頂級會議。顧名思義,它重視實證研究,即通過數據和實驗證明技術在現實世界中的有效性,而不是純粹的理論假設。符合這一特點,ESTsoft 研究團隊的論文針對影片翻譯中的一個棘手問題,用數據對其進行量化,並用算法加以解決。這是一項具有實用價值的現實貢獻。
Perso Dubbing 配音管線所考量的關鍵問題就在這裡。不是字符,不是音節,而是語音中最小的單位——音素。字符和音節是屏幕上的單位;音素則對應於口中實際花費的時間。論文中提出的算法 CountPhonemes 會計算翻譯後句子的音素數量,將其與目標音素數量進行比較,並修改句子以使兩者保持一致。
現有的機器翻譯模型針對 BLEU 和 COMET 等意義保留指標進行了優化。它們經過訓練,可以盡快提供最合理的翻譯。但影片翻譯有時不得不拒絕最合理的翻譯。當音素不足時,你必須放棄一些意思並尋找另一種表述方式。我們要求的不是 AI 給出「概率最高的答案」,而是給出「通過所有限制條件的答案」。
這正是 Perso Dubbing 配音管線所解決的問題。在翻譯步驟中,系統會生成許多滿足長度和音素限制的候選文本,然後挑選語義損失最小的一個。這是上一節中推理時間計算想法在配音領域的應用。阻止模型脫口而出首先想到的答案。讓它重寫。讓它驗證。這種疊代翻譯是強加給機器的刻意猶豫。在疊代反饋迴路中,模型在長度合規性(等時性)與意義對齊(語義對齊)之間追尋最佳平衡點。這正是將影片翻譯人員的焦慮移植到模型本身的工作。
結語
猶豫不僅僅是不完美,不僅僅是減速。它是考慮他人所花費時間的累積。如果 AI 真的學會了為了體貼而停頓,那不會是因為模型變聰明了。而是因為我們將其設計得不那麼確定、停留得更久、學會去猶豫。
如何教會 AI 猶豫
幾天前,我看到了一段 YouTube 影片。新聞主播孫石熙正在採訪小說家金愛爛。問題是「人類擁有什麼是 AI 所沒有的?」,而她的回答是「猶豫」。
這位小說家提到了主播以往播報中的一個瞬間。在播報已故勞工運動家出身的政治家魯會燦逝世的消息時,他失語了二十秒。那一刻扣字、動搖和辨識的過程——即猶豫。AI 是無法做到這一點的。然而,一個人的猶豫卻能成為安慰與禮貌。
那了大約是二十年前,當時我正專注於開發一款射擊遊戲。一位負責 3D 角色建模的隊友遞給我一本書說:「我的一個高中朋友是小說家,你應該讀讀這個。」這本書充滿了帶著機智的深刻觀察,讓我完全沉浸其中。這本書就是金愛爛的短篇小說集《奔跑吧,爸爸》(달려라 아비)。從那時起,我就成了她的書迷。
猶豫需要時間和較低的確定性
金愛爛說,她的寫作肌肉是通過對每一行字精雕細琢和自我審問而得以強化的。她說,在句子之間花費的時間變成了對他人的體貼。她還提出,文學的真正價值不在於內容,而在於其形式。那麼,如果形式也很重要,也許 AI 至少可以大致模仿它?
從物理學的角度來看,時間是物理狀態的一種變化。在物理學中,如果狀態沒有改變,時間就沒有流逝。因此,狀態變化越少相當於時間越慢,變化越多相當於時間越長。對人類來說彈指一瞬的秒,對 AI 來說卻是跨越數百億甚至數萬億次浮點運算(FLOPs)的永恆。與過去的軟體相比,最近的 AI 回答是漫長、焦慮的艱苦努力之結晶。這也是為什麼 AI 行業在收入增長的同時卻在利潤上苦苦掙扎的緣故。在傳統軟體看來,AI 對於機器來說實在是太慢了。即使是像 JSON 格式驗證這樣簡單的事情,當通過大型語言模型推理運行時,與傳統軟體相比也要消耗數億次計算。
大型語言模型(LLMs)作為 AI 近期取得進展的引擎,是預測句子中下一個單詞的程序。AI 通過運行電流來尋找下一個單詞。它重複地對龐大的矩陣進行乘法和加法。AI 的計算需要硬體的物理消耗。為了讓 AI 具備人類焦慮時光裏那種哪怕是形式上的猶豫,你必須讓它進行密集的計算。產生單個下一個單詞需要數百億次運算。接下來產生其後的單詞又需要另外數百億次運算。
當代深度學習的大多數計算都涉及加權和,而這些求和中使用的預先計算值被稱為參數。
當我們談論 'Qwen 3.6 27B' 模型時,這意味著有 270 億個參數準備進行權重求和,僅預測單個下一個標記(token)就需要約 270 億次乘法。而這僅僅是個開始。此外,單個整數乘法涉及數十個邏輯運算,而浮點數則需要數千個。面對如此的複雜性,人們或許會稱之為令人難以置信。
降低溫度會使偏見更加銳利
讓我們更深入地了解 LLMs 的工作原理。深度學習是 LLMs 的基礎,它是一種模式匹配機器,能將訓練期間記住的模式應用於現實世界的實際使用中,這已成為常識。有兩件事支配著這種反芻過程:標記採樣和溫度。
為了預測下一個單詞,模型會為數萬個候選單詞中的每一個分配一個分數(logit)。然後將這些分數轉換為概率,並按每個概率的比例選擇一個單詞。這個過程被稱為採樣。
為了給採樣增加變化,引入了一個名為「溫度」的數學參數。降低溫度後,候選分數之間的差距會拉大到極端。高概率的單詞被選中的頻率高於基線。低概率的單詞被選中的機率甚至更低。這類似於富人越富,窮人越窮。相反,溫度升高時差距會縮小。差距趨於平緩,並變得平均。在溫度升高時,通常會被忽略的低概率單詞可以以更高的比例被選中。
人類語言與此類似。我所屬的群體和文化反映在我的語言概率分布中。更冷、更銳利的語言產生的言論更理性、更優化,也更符合大多數人。更溫暖、更圓潤的語言則不那麼理性,也不那麼優化,但卻考慮到了少數人。
體貼是花費額外的精力走出自己思想的概率分布的行為。這意味著注意到被大多數人遮蔽的東西,並找到通常不會使用的句子。作家所描述的艱苦寫作過程,對 AI 來說,應該成為一種拒絕僅基於有偏見的訓練進行回應,並努力向更遠處探索的行為。
機械式焦慮
我們該如何教导 AI 學會體貼?你不能讓它直接吐出概率最高的詞。那只會輸出訓練數據中固有的偏見。
今天的 AI 模型之所以能取得如此驚人的成果,是因為該領域在「推理時間計算」(Inference-Time Compute)方面取得了先進技術。這是一種在 AI 回答之前給予其更多計算時間的技術。過去的 AI 模型只是簡單地輸出計算出的第一個答案,換句話說就是首先想到的答案。相比之下,今天的思考模型會生成多條推理路徑。
它們產生各種候選答案,並通過其內在的獎勵模型對其進行評分。它會經歷檢查單詞是否符合上下文,以及對它來說這些單詞是否顯得過於絕對的過程,然後在需要時進行內部捨棄。
這類似於人類在說話前在腦海中修改句子。不要求 AI 根據概率分布提供盡可能準確的答案,而是花費計算資源給予其修改的時間。我們讓它從概率質量的中心游離到邊緣:一種機械式的焦慮。
影片翻譯中的焦慮
普通的翻譯只要意思相符即可完成,但影片翻譯不僅要求意思準確,而且字幕的長度與唇形動作的時間也必須匹配。
如果屏幕上的演員移動嘴巴 1.8 秒並吐出 11 個英文音節,翻譯人員就必須構建一句能契合這 1.8 秒的韓文台詞。保留意思則長度會崩潰。匹配長度則意思會模糊。當收尾子音和開口元音與原版不同時,觀眾在看到的那一刻就會覺得有些不對勁。字幕帶來了另一個限制:每秒 12 到 15 個字符的閱讀速度。因此,從事配音工作的翻譯人員會列出五行意思相同的句子,計算音節,匹配重音,並且不選擇最準確的翻譯,而是選擇在限制條件中損失最少的翻譯。
Perso Dubbing 的翻譯團隊一直致力於解決這個問題。該團隊在 EMNLP 上發表了一篇論文(https://aclanthology.org/2025.emnlp-demos.37),定量分析了影片翻譯中等時性(長度合規性)與語義對齊之間的權衡。
EMNLP(自然語言處理中的經驗方法會議)是自然語言處理領域的頂級會議。顧名思義,它重視實證研究,即通過數據和實驗證明技術在現實世界中的有效性,而不是純粹的理論假設。符合這一特點,ESTsoft 研究團隊的論文針對影片翻譯中的一個棘手問題,用數據對其進行量化,並用算法加以解決。這是一項具有實用價值的現實貢獻。
Perso Dubbing 配音管線所考量的關鍵問題就在這裡。不是字符,不是音節,而是語音中最小的單位——音素。字符和音節是屏幕上的單位;音素則對應於口中實際花費的時間。論文中提出的算法 CountPhonemes 會計算翻譯後句子的音素數量,將其與目標音素數量進行比較,並修改句子以使兩者保持一致。
現有的機器翻譯模型針對 BLEU 和 COMET 等意義保留指標進行了優化。它們經過訓練,可以盡快提供最合理的翻譯。但影片翻譯有時不得不拒絕最合理的翻譯。當音素不足時,你必須放棄一些意思並尋找另一種表述方式。我們要求的不是 AI 給出「概率最高的答案」,而是給出「通過所有限制條件的答案」。
這正是 Perso Dubbing 配音管線所解決的問題。在翻譯步驟中,系統會生成許多滿足長度和音素限制的候選文本,然後挑選語義損失最小的一個。這是上一節中推理時間計算想法在配音領域的應用。阻止模型脫口而出首先想到的答案。讓它重寫。讓它驗證。這種疊代翻譯是強加給機器的刻意猶豫。在疊代反饋迴路中,模型在長度合規性(等時性)與意義對齊(語義對齊)之間追尋最佳平衡點。這正是將影片翻譯人員的焦慮移植到模型本身的工作。
結語
猶豫不僅僅是不完美,不僅僅是減速。它是考慮他人所花費時間的累積。如果 AI 真的學會了為了體貼而停頓,那不會是因為模型變聰明了。而是因為我們將其設計得不那麼確定、停留得更久、學會去猶豫。
繼續閱讀
瀏覽全部




