Cómo enseñar a la IA a dudar: computación en tiempo de inferencia y el arte de la traducción meditada
Última actualización


Ir a la sección
Ir a la sección
Compartir
Compartir
Compartir

Herramienta de Traducción de Video AI, Localización y Doblaje
Pruébalo gratis
Cómo enseñar a dudar a la IA
Hace unos días, me topé con un clip de YouTube. El presentador de noticias Sohn Suk-hee entrevistaba a la novelista Kim Ae-ran. La pregunta fue "¿Qué tiene un ser humano que no tenga la IA?", y su respuesta fue "La duda".
La novelista recordó un momento de una de las antiguas emisiones del presentador. Al dar la noticia del fallecimiento del difunto Roh Hoe-chan, un activista laboral convertido en político, se quedó sin palabras durante veinte segundos. Ese instante de retener las palabras, vacilar y discernir: la duda. La IA es incapaz de esto. Sin embargo, la duda de una persona se convierte en consuelo y cortesía.
Fue hace unos veinte años, cuando me dedicaba a desarrollar un videojuego de disparos. Un compañero del equipo de modelado de personajes 3D me entregó un libro diciendo: "Una amiga mía del instituto es novelista; deberías leer esto". Observaciones profundas entrelazadas con ingenio. Me absorbió por completo. El libro era la colección de relatos cortos de Kim Ae-ran Corre, papá, corre (달려라 아비). He sido su fan desde entonces.
La duda requiere tiempo y una menor certeza
Kim Ae-ran dijo que sus músculos de escritura se fortalecieron gracias al cuidado minucioso y al cuestionamiento personal de cada línea. Sostuvo que el tiempo que pasa entre frases se convierte en consideración por los demás. También sugirió que el verdadero valor de la literatura no radica en el contenido sino en su forma. Entonces, si la forma también importa, ¿quizás la IA pueda imitarla al menos de manera aproximada?
Desde el punto de vista de la física, el tiempo es un cambio en el estado físico. En física, el tiempo no ha pasado si el estado no ha cambiado. Por lo tanto, menos cambios de estado equivalen a un tiempo más lento y más cambios equivalen a un tiempo más largo. Un segundo fugaz para un humano es para la IA una eternidad que se extiende a lo largo de cientos de miles de millones, incluso billones, de operaciones de coma flotante (FLOPs). En comparación con el software del pasado, las respuestas recientes de la IA son el producto de un esfuerzo largo y angustioso. Esta es también la razón por la que la industria de la IA puede crecer en ingresos mientras lucha por obtener beneficios. Desde la perspectiva del software heredado, la IA es demasiado lenta para ser una máquina. Incluso algo tan simple como la validación del formato JSON, cuando se ejecuta a través de la inferencia de un modelo de lenguaje grande, cuesta cientos de millones de cálculos en comparación con el software heredado.
Los modelos de lenguaje grandes (LLM), el motor del progreso reciente de la IA, son programas que predicen la siguiente palabra de una oración. La IA hace correr corriente eléctrica para encontrar la siguiente palabra. Multiplica y suma repetidamente matrices enormes. El cálculo de la IA requiere un consumo físico de hardware. Para dotar a la IA de al menos una forma de duda, el tiempo de agonía humano, hay que someterla a un cálculo intenso. Cientos de miles de millones de operaciones para producir una sola palabra siguiente. Le siguen otros cientos de miles de millones de operaciones para producir la palabra posterior.
La mayoría de los cálculos contemporáneos de aprendizaje profundo involucran sumas ponderadas, y los valores precalculados utilizados en estas sumas se conocen como parámetros.
Cuando hablamos del modelo 'Qwen 3.6 27B', significa que hay 27.000 millones de parámetros listos para la suma ponderada, lo que requiere unos 27.000 millones de multiplicaciones para predecir un solo token siguiente. Y eso es solo el principio. Además, una sola multiplicación de enteros implica docenas de operaciones lógicas y un número de coma flotante requiere miles. Ante tal complejidad, uno puede calificarlo de asombroso.
Bajar la temperatura agudiza el sesgo
Analicemos más a fondo cómo funcionan los LLM. Se ha convertido en conocimiento común que el aprendizaje profundo, la base de los LLM, es una máquina de emparejamiento de patrones que aplica patrones memorizados durante el entrenamiento al uso en el mundo real. Dos aspectos gobiernan ese proceso de regurgitación: el muestreo de tokens y la temperatura.
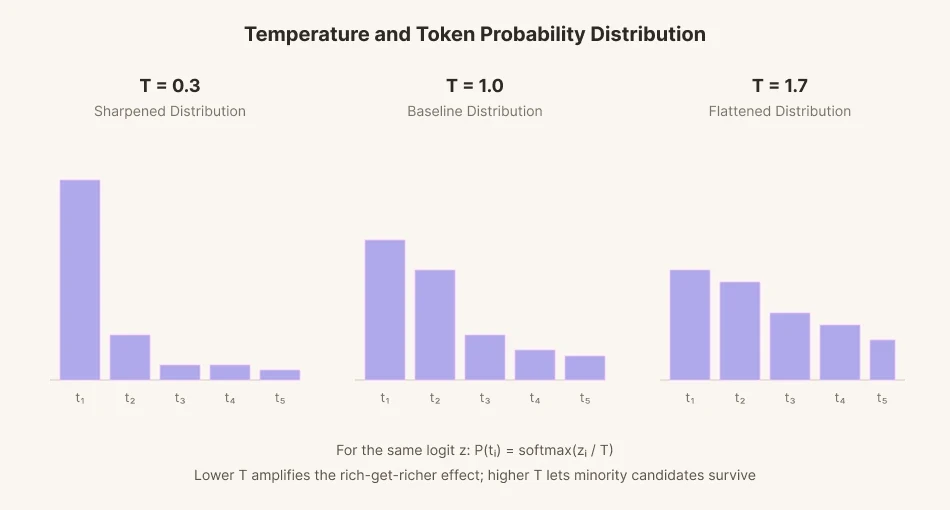
Para predecir una sola palabra siguiente, el modelo asigna una puntuación (logit) a cada una de las decenas de miles de palabras candidatas. Esas puntuaciones se convierten luego en probabilidades y se selecciona una palabra en proporción a cada probabilidad. Este proceso se llama muestreo.
Para añadir variación al muestreo, se introdujo un parámetro matemático llamado 'temperatura'. Si se baja la temperatura, la brecha entre las puntuaciones de las candidatas se estira hasta los extremos. Las palabras con alta probabilidad se eligen con más frecuencia que las palabras en la línea base. Las palabras con baja probabilidad se eligen aún menos. Es similar a cómo los ricos se hacen más ricos y los pobres más pobres. Por el contrario, la brecha se estrecha cuando la temperatura sube. La brecha se aplana y se equilibra. Las palabras de baja probabilidad que normalmente se habrían pasado por alto, pueden seleccionarse a un ritmo mayor cuando sube la temperatura.
El lenguaje humano es similar a esto. El grupo y la cultura a los que pertenezco se reflejan en la distribución de probabilidad de mi lenguaje. Un lenguaje más frío y afilado produce un discurso más racional, más optimizado y más acorde con la mayoría. Un lenguaje más cálido y redondo es menos racional y menos optimizado, pero tiene en cuenta a la minoría.
La consideración es el acto de gastar energía extra para salir de la distribución de probabilidad de los pensamientos propios. Significa notar lo que la mayoría oculta y encontrar frases que no se usan normalmente. Lo que la escritora describió como un meticuloso proceso de escritura, para la IA, debería convertirse en un acto de rechazar respuestas basadas únicamente en un entrenamiento sesgado y esforzarse por viajar más allá.
Preocupación mecánica
¿Cómo podríamos enseñar a la IA a ser considerada? No puedes dejar que escupa la palabra de mayor probabilidad de inmediato. Eso solo exporta los sesgos inherentes a los datos de entrenamiento.
La razón por la que los modelos de IA de hoy en día logran resultados tan sorprendentes es que el campo ha avanzado en tecnologías centradas en el 'Tiempo de Cómputo en Inferencia'. Es una tecnología que otorga a la IA más tiempo de cálculo antes de responder. Los modelos de IA del pasado simplemente mostraban el primer resultado calculado, en otras palabras, la respuesta que primero les venía a la mente. Por el contrario, los modelos de pensamiento actuales generan múltiples caminos de razonamiento.
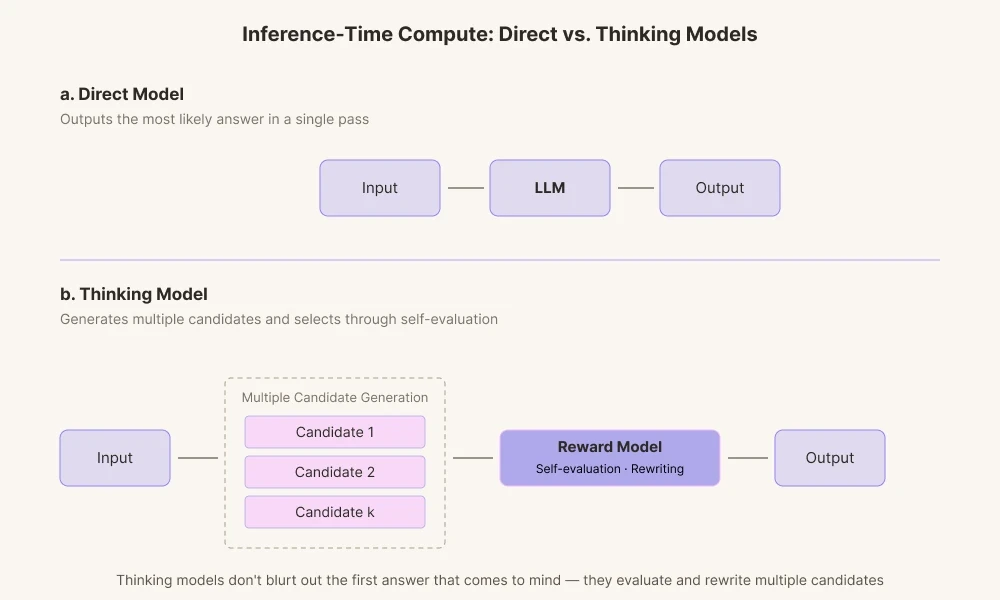
Producen varias respuestas candidatas y las califican a través de su modelo de recompensa intrínseco. Pasa por el proceso de verificar si las palabras encajan en el contexto y si resultan demasiado definitivas para él, descartándolas internamente si es necesario.
Esto es similar a cómo los humanos revisan las oraciones en su mente antes de hablar. En lugar de exigir a la IA que ofrezca una respuesta lo más precisa posible basada en distribuciones de probabilidad, se gastan recursos de cómputo para darle tiempo de revisar. Dejamos que deambule desde el centro de la masa de probabilidad hacia los bordes: una especie de preocupación mecánica.
Incertidumbre en la traducción de vídeo
La traducción ordinaria termina una vez que el significado encaja, pero la traducción de vídeo requiere no solo un significado preciso, sino que también la duración y el ritmo de los movimientos de los labios tienen que coincidir.
Si un actor en pantalla mueve la boca durante 1,8 segundos y pronuncia 11 sílabas en inglés, el traductor tiene que construir una línea en coreano que encaje dentro de esos 1,8 segundos. Si se preserva el significado, la longitud se rompe. Si se ajusta la longitud, el significado se desdibuja. Cuando las consonantes de cierre y las vocales abiertas son diferentes de las originales, el espectador siente que algo no cuadra en el momento en que lo ve. Los subtítulos aportan otra limitación: de 12 a 15 caracteres por segundo de velocidad de lectura. De modo que un traductor que trabaja con doblaje plantea cinco líneas de significado equivalente, cuenta sílabas, hace coincidir acentos y elige no la traducción más exacta, sino la que menos pierde dentro de las limitaciones.
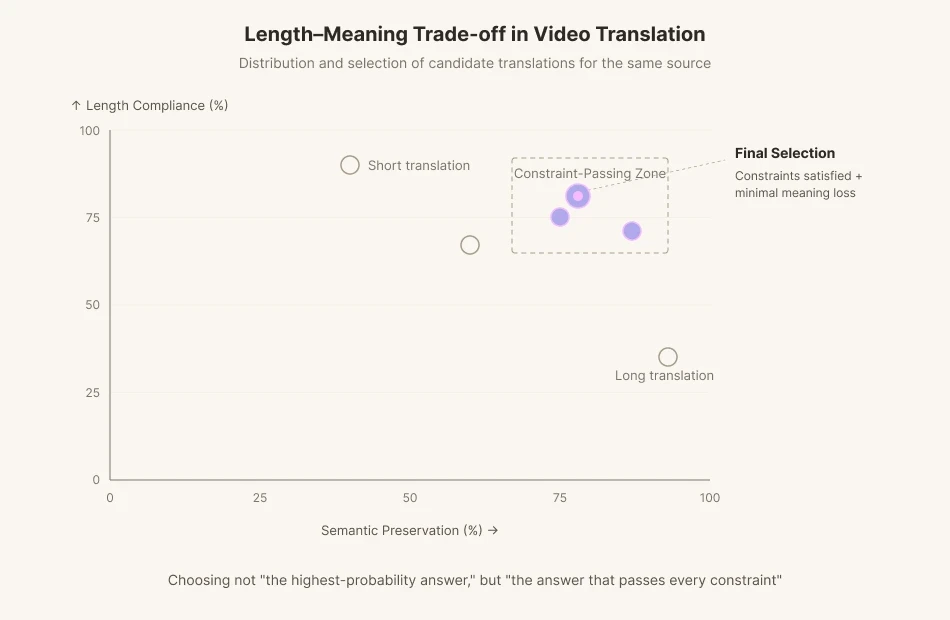
El equipo de traducción de Perso Dubbing ha estado trabajando exactamente en este problema. El equipo publicó un artículo en EMNLP (https://aclanthology.org/2025.emnlp-demos.37) que cuantifica el equilibrio entre la isocronía (cumplimiento de la longitud) y la alineación semántica en la traducción de vídeo.
EMNLP (Métodos Empíricos en Procesamiento del Lenguaje Natural) es un foro de primer nivel en el procesamiento del lenguaje natural. Fiel a su nombre, valora la investigación empírica que demuestra la eficacia real de una tecnología a través de datos y experimentos, en lugar de hipótesis puramente teóricas. Adaptándose a ese carácter, el artículo del equipo de investigación de ESTsoft toma un problema difícil en la traducción de vídeo, lo cuantifica con datos y lo resuelve con un algoritmo. Una contribución práctica al mundo real.
La pregunta clave que tiene en cuenta la cadena de doblaje de Perso Dubbing reside aquí. No los caracteres, no las sílabas, sino el fonema, que es la unidad más pequeña del habla. Los caracteres y las sílabas son unidades en la pantalla; los fonemas corresponden al tiempo real que se pasa en la boca. El algoritmo propuesto en el artículo, CountPhonemes, cuenta el número de fonemas de la frase traducida, lo compara con el número de fonemas objetivo y revisa la frase para alinear ambos.
La mayoría de los modelos de traducción automática existentes están optimizados para métricas de preservación del significado como BLEU y COMET. Están entrenados para ofrecer la traducción más plausible, lo más rápido posible. Pero la traducción de vídeo a veces tiene que rechazar la más plausible. Cuando los fonemas se quedan cortos, hay que renunciar a parte del significado y buscar otra formulación. No le estamos pidiendo a la IA "la respuesta de mayor probabilidad" sino "la respuesta que supere todos los límites".
Esto es exactamente lo que resuelve la cadena de doblaje de Perso Dubbing. En el paso de traducción, el sistema genera muchas candidatas que satisfacen las limitaciones de longitud y fonemas, y luego elige la que tiene menor pérdida semántica. Es la idea del tiempo de cómputo en inferencia de la sección anterior, transpuesta al dominio del doblaje. Evita que el modelo suelte la primera respuesta que le venga a la mente. Haz que reescriba. Haz que verifique. Esta traducción iterativa es una duda deliberada impuesta a la máquina. Dentro de un bucle de retroalimentación iterativo, el modelo persigue el óptimo entre el cumplimiento de la longitud (isocronía) y la alineación del significado (alineación semántica). Es el trabajo de trasplantar la agonía del traductor de vídeo al propio modelo.
Para terminar
La duda no es una mera imperfección, no es un mero retraso. Es la acumulación del tiempo dedicado a considerar a los demás. Si la IA aprende alguna vez a hacer una pausa en aras de la consideración, no será porque el modelo se haya vuelto más inteligente. Será porque la diseñamos para que fuera menos segura, para que se demorara más, para que dudara.
Cómo enseñar a dudar a la IA
Hace unos días, me topé con un clip de YouTube. El presentador de noticias Sohn Suk-hee entrevistaba a la novelista Kim Ae-ran. La pregunta fue "¿Qué tiene un ser humano que no tenga la IA?", y su respuesta fue "La duda".
La novelista recordó un momento de una de las antiguas emisiones del presentador. Al dar la noticia del fallecimiento del difunto Roh Hoe-chan, un activista laboral convertido en político, se quedó sin palabras durante veinte segundos. Ese instante de retener las palabras, vacilar y discernir: la duda. La IA es incapaz de esto. Sin embargo, la duda de una persona se convierte en consuelo y cortesía.
Fue hace unos veinte años, cuando me dedicaba a desarrollar un videojuego de disparos. Un compañero del equipo de modelado de personajes 3D me entregó un libro diciendo: "Una amiga mía del instituto es novelista; deberías leer esto". Observaciones profundas entrelazadas con ingenio. Me absorbió por completo. El libro era la colección de relatos cortos de Kim Ae-ran Corre, papá, corre (달려라 아비). He sido su fan desde entonces.
La duda requiere tiempo y una menor certeza
Kim Ae-ran dijo que sus músculos de escritura se fortalecieron gracias al cuidado minucioso y al cuestionamiento personal de cada línea. Sostuvo que el tiempo que pasa entre frases se convierte en consideración por los demás. También sugirió que el verdadero valor de la literatura no radica en el contenido sino en su forma. Entonces, si la forma también importa, ¿quizás la IA pueda imitarla al menos de manera aproximada?
Desde el punto de vista de la física, el tiempo es un cambio en el estado físico. En física, el tiempo no ha pasado si el estado no ha cambiado. Por lo tanto, menos cambios de estado equivalen a un tiempo más lento y más cambios equivalen a un tiempo más largo. Un segundo fugaz para un humano es para la IA una eternidad que se extiende a lo largo de cientos de miles de millones, incluso billones, de operaciones de coma flotante (FLOPs). En comparación con el software del pasado, las respuestas recientes de la IA son el producto de un esfuerzo largo y angustioso. Esta es también la razón por la que la industria de la IA puede crecer en ingresos mientras lucha por obtener beneficios. Desde la perspectiva del software heredado, la IA es demasiado lenta para ser una máquina. Incluso algo tan simple como la validación del formato JSON, cuando se ejecuta a través de la inferencia de un modelo de lenguaje grande, cuesta cientos de millones de cálculos en comparación con el software heredado.
Los modelos de lenguaje grandes (LLM), el motor del progreso reciente de la IA, son programas que predicen la siguiente palabra de una oración. La IA hace correr corriente eléctrica para encontrar la siguiente palabra. Multiplica y suma repetidamente matrices enormes. El cálculo de la IA requiere un consumo físico de hardware. Para dotar a la IA de al menos una forma de duda, el tiempo de agonía humano, hay que someterla a un cálculo intenso. Cientos de miles de millones de operaciones para producir una sola palabra siguiente. Le siguen otros cientos de miles de millones de operaciones para producir la palabra posterior.
La mayoría de los cálculos contemporáneos de aprendizaje profundo involucran sumas ponderadas, y los valores precalculados utilizados en estas sumas se conocen como parámetros.
Cuando hablamos del modelo 'Qwen 3.6 27B', significa que hay 27.000 millones de parámetros listos para la suma ponderada, lo que requiere unos 27.000 millones de multiplicaciones para predecir un solo token siguiente. Y eso es solo el principio. Además, una sola multiplicación de enteros implica docenas de operaciones lógicas y un número de coma flotante requiere miles. Ante tal complejidad, uno puede calificarlo de asombroso.
Bajar la temperatura agudiza el sesgo
Analicemos más a fondo cómo funcionan los LLM. Se ha convertido en conocimiento común que el aprendizaje profundo, la base de los LLM, es una máquina de emparejamiento de patrones que aplica patrones memorizados durante el entrenamiento al uso en el mundo real. Dos aspectos gobiernan ese proceso de regurgitación: el muestreo de tokens y la temperatura.
Para predecir una sola palabra siguiente, el modelo asigna una puntuación (logit) a cada una de las decenas de miles de palabras candidatas. Esas puntuaciones se convierten luego en probabilidades y se selecciona una palabra en proporción a cada probabilidad. Este proceso se llama muestreo.
Para añadir variación al muestreo, se introdujo un parámetro matemático llamado 'temperatura'. Si se baja la temperatura, la brecha entre las puntuaciones de las candidatas se estira hasta los extremos. Las palabras con alta probabilidad se eligen con más frecuencia que las palabras en la línea base. Las palabras con baja probabilidad se eligen aún menos. Es similar a cómo los ricos se hacen más ricos y los pobres más pobres. Por el contrario, la brecha se estrecha cuando la temperatura sube. La brecha se aplana y se equilibra. Las palabras de baja probabilidad que normalmente se habrían pasado por alto, pueden seleccionarse a un ritmo mayor cuando sube la temperatura.
El lenguaje humano es similar a esto. El grupo y la cultura a los que pertenezco se reflejan en la distribución de probabilidad de mi lenguaje. Un lenguaje más frío y afilado produce un discurso más racional, más optimizado y más acorde con la mayoría. Un lenguaje más cálido y redondo es menos racional y menos optimizado, pero tiene en cuenta a la minoría.
La consideración es el acto de gastar energía extra para salir de la distribución de probabilidad de los pensamientos propios. Significa notar lo que la mayoría oculta y encontrar frases que no se usan normalmente. Lo que la escritora describió como un meticuloso proceso de escritura, para la IA, debería convertirse en un acto de rechazar respuestas basadas únicamente en un entrenamiento sesgado y esforzarse por viajar más allá.
Preocupación mecánica
¿Cómo podríamos enseñar a la IA a ser considerada? No puedes dejar que escupa la palabra de mayor probabilidad de inmediato. Eso solo exporta los sesgos inherentes a los datos de entrenamiento.
La razón por la que los modelos de IA de hoy en día logran resultados tan sorprendentes es que el campo ha avanzado en tecnologías centradas en el 'Tiempo de Cómputo en Inferencia'. Es una tecnología que otorga a la IA más tiempo de cálculo antes de responder. Los modelos de IA del pasado simplemente mostraban el primer resultado calculado, en otras palabras, la respuesta que primero les venía a la mente. Por el contrario, los modelos de pensamiento actuales generan múltiples caminos de razonamiento.
Producen varias respuestas candidatas y las califican a través de su modelo de recompensa intrínseco. Pasa por el proceso de verificar si las palabras encajan en el contexto y si resultan demasiado definitivas para él, descartándolas internamente si es necesario.
Esto es similar a cómo los humanos revisan las oraciones en su mente antes de hablar. En lugar de exigir a la IA que ofrezca una respuesta lo más precisa posible basada en distribuciones de probabilidad, se gastan recursos de cómputo para darle tiempo de revisar. Dejamos que deambule desde el centro de la masa de probabilidad hacia los bordes: una especie de preocupación mecánica.
Incertidumbre en la traducción de vídeo
La traducción ordinaria termina una vez que el significado encaja, pero la traducción de vídeo requiere no solo un significado preciso, sino que también la duración y el ritmo de los movimientos de los labios tienen que coincidir.
Si un actor en pantalla mueve la boca durante 1,8 segundos y pronuncia 11 sílabas en inglés, el traductor tiene que construir una línea en coreano que encaje dentro de esos 1,8 segundos. Si se preserva el significado, la longitud se rompe. Si se ajusta la longitud, el significado se desdibuja. Cuando las consonantes de cierre y las vocales abiertas son diferentes de las originales, el espectador siente que algo no cuadra en el momento en que lo ve. Los subtítulos aportan otra limitación: de 12 a 15 caracteres por segundo de velocidad de lectura. De modo que un traductor que trabaja con doblaje plantea cinco líneas de significado equivalente, cuenta sílabas, hace coincidir acentos y elige no la traducción más exacta, sino la que menos pierde dentro de las limitaciones.
El equipo de traducción de Perso Dubbing ha estado trabajando exactamente en este problema. El equipo publicó un artículo en EMNLP (https://aclanthology.org/2025.emnlp-demos.37) que cuantifica el equilibrio entre la isocronía (cumplimiento de la longitud) y la alineación semántica en la traducción de vídeo.
EMNLP (Métodos Empíricos en Procesamiento del Lenguaje Natural) es un foro de primer nivel en el procesamiento del lenguaje natural. Fiel a su nombre, valora la investigación empírica que demuestra la eficacia real de una tecnología a través de datos y experimentos, en lugar de hipótesis puramente teóricas. Adaptándose a ese carácter, el artículo del equipo de investigación de ESTsoft toma un problema difícil en la traducción de vídeo, lo cuantifica con datos y lo resuelve con un algoritmo. Una contribución práctica al mundo real.
La pregunta clave que tiene en cuenta la cadena de doblaje de Perso Dubbing reside aquí. No los caracteres, no las sílabas, sino el fonema, que es la unidad más pequeña del habla. Los caracteres y las sílabas son unidades en la pantalla; los fonemas corresponden al tiempo real que se pasa en la boca. El algoritmo propuesto en el artículo, CountPhonemes, cuenta el número de fonemas de la frase traducida, lo compara con el número de fonemas objetivo y revisa la frase para alinear ambos.
La mayoría de los modelos de traducción automática existentes están optimizados para métricas de preservación del significado como BLEU y COMET. Están entrenados para ofrecer la traducción más plausible, lo más rápido posible. Pero la traducción de vídeo a veces tiene que rechazar la más plausible. Cuando los fonemas se quedan cortos, hay que renunciar a parte del significado y buscar otra formulación. No le estamos pidiendo a la IA "la respuesta de mayor probabilidad" sino "la respuesta que supere todos los límites".
Esto es exactamente lo que resuelve la cadena de doblaje de Perso Dubbing. En el paso de traducción, el sistema genera muchas candidatas que satisfacen las limitaciones de longitud y fonemas, y luego elige la que tiene menor pérdida semántica. Es la idea del tiempo de cómputo en inferencia de la sección anterior, transpuesta al dominio del doblaje. Evita que el modelo suelte la primera respuesta que le venga a la mente. Haz que reescriba. Haz que verifique. Esta traducción iterativa es una duda deliberada impuesta a la máquina. Dentro de un bucle de retroalimentación iterativo, el modelo persigue el óptimo entre el cumplimiento de la longitud (isocronía) y la alineación del significado (alineación semántica). Es el trabajo de trasplantar la agonía del traductor de vídeo al propio modelo.
Para terminar
La duda no es una mera imperfección, no es un mero retraso. Es la acumulación del tiempo dedicado a considerar a los demás. Si la IA aprende alguna vez a hacer una pausa en aras de la consideración, no será porque el modelo se haya vuelto más inteligente. Será porque la diseñamos para que fuera menos segura, para que se demorara más, para que dudara.
Seguir Leyendo
Explorar todo




