การแปลเสียงพากย์: คู่มือฉบับสมบูรณ์สำหรับวิดีโอหลายภาษา



เครื่องมือแปลวิดีโอ AI การทำให้เข้าท้องถิ่น และการพากย์เสียง
ลองใช้งานฟรี
คำตอบสั้นๆ: การแปลเสียงพากย์ (Voice over translation) คือขั้นตอนการทำงานที่เริ่มจากเสียงพากย์ที่มีอยู่แล้ว ไม่ว่าจะเป็นเสียงบรรยาย เสียงอธิบาย หรือเสียงวิเคราะห์ที่บันทึกไว้ แล้วสร้างเสียงพากย์เดิมนั้นออกมาในอีกภาษาหนึ่ง การแปลเสียงพากย์ที่ขับเคลื่อนด้วย AI สามารถจัดการสามขั้นตอนหลักได้อย่างอัตโนมัติ ได้แก่ การรู้จำเสียงพูด การแปล และการสังเคราะห์เสียงในภาษาเป้าหมาย และด้วย Perso Dubbing คุณจะสามารถแปลได้มากกว่า 99 ภาษาพร้อมทั้งโคลนเสียงของผู้พูดต้นฉบับเพื่อให้ภาษาใหม่ที่ได้ยินนั้นฟังดูราวกับพูดโดยบุคคลเดียวกัน
การแปลเสียงพากย์คืออะไร?
การแปลเสียงพากย์คือกระบวนการแปลงเสียงพากย์ที่บันทึกไว้จากภาษาหนึ่งไปยังอีกภาษาหนึ่ง โดยข้อมูลขาเข้า (Input) จะเป็นไฟล์เสียง ซึ่งบางครั้งอาจรวมมากับไฟล์วิดีโอหรือเป็นไฟล์เสียงเดี่ยวๆ และข้อมูลขาออก (Output) ที่ได้จะเป็นไฟล์เสียงในอีกภาษาที่พร้อมใช้งานจริง
วงการนี้มีอายุเก่าแก่กว่าเทคโนโลยี AI โดยเหล่าสตูดิโอต่างทำกันมาด้วยตัวเองนานหลายทศวรรษ ไม่ว่าจะเป็นการจ้างนักพากย์ในภาษาเป้าหมาย ส่งสคริปต์ที่แปลแล้วให้ บันทึกเสียง แล้วนำกลับมารวมเข้ากับวิดีโอ ซึ่งอุปสรรคสำคัญก็คือต้นทุนและเวลาในอดีต วิดีโออธิบายความยาว 5 นาทีในสามภาษานั้นหมายถึงการที่ต้องเข้าสตูดิโอสามครั้ง มีนักพากย์สามคน และใช้ระยะเวลาทำงานนับสัปดาห์
AI เข้ามาเปลี่ยนรูปแบบการทำงานนี้โดยที่จุดประสงค์ปลายทางยังคงเดิม ผลลัพธ์สุดท้ายยังคงเป็นเสียงพากย์ประโยคเดิมในอีกภาษา แต่เส้นทางที่จะทำให้ได้ผลลัพธ์นั้นในปัจจุบันใช้เวลาเพียงไม่กี่นาทีแทนที่จะเป็นสัปดาห์
รูปแบบของงานพากย์เสียงที่จัดอยู่ในการแปลเสียงพากย์มีสามประเภทใหญ่ๆ ได้แก่:
ประเภทแรกคือ เสียงบรรยายเฉพาะท้องถิ่น (localized narration) เช่น วิดีโออธิบาย, คอร์สเรียนออนไลน์, เสียงบรรยายสารคดี, บทหนังสือเสียง โดยต้นฉบับจะเป็นเสียงคนคนเดียวดำเนินเรื่องไปตลอดการผลิต เสียงที่แปลแล้วจะยังคงใช้เสียงต้นแบบเดิมหรือใช้เสียงเทียบเคียงกันในภาษาเป้าหมายแทน
ประเภทที่สองคือ การพากย์เสียงบทสนทนา (dialogue dubbing) เช่น ภาพยนตร์, ละคร, คอนเทนต์สัมภาษณ์ที่มีผู้พูดหลายรายและจำเป็นต้องแปลแยกรายคน การแปลเสียงพากย์ถือเป็นเครื่องมือหลักของกระบวนการนี้ แม้ว่าในอุตสาหกรรมจะหันไปเรียกว่า "การพากย์เสียง (dubbing)" เมื่อเริ่มเข้าข่ายการทำงานกับผู้พูดหลายคนก็ตาม
ประเภทที่สามคือ เสียงส่วนติดต่อผู้ใช้ (interface audio) เช่น เมนูเสียงตอบรับอัตโนมัติ (IVR), เสียงแนะนำการใช้งานแอปพลิเคชัน, เสียงบรรยายในตัวผลิตภัณฑ์ ซึ่งมีขอบเขตการทำงานที่เล็กกว่า แต่ก็ยังรันอยู่บนระบบการแปลและการสังเคราะห์เสียงแบบเดียวกัน
ส่วนที่เหลือของคู่มือนี้จะเน้นไปที่สองประเภทแรก เนื่องจากประเภทที่สามนั้นจะใช้รูปแบบการทำงานที่เหมือนกันแต่มีขนาดที่เล็กกว่า
การแปลเสียงพากย์กับการพากย์เสียง แตกต่างกันอย่างไร หรือเหมือนกัน?
โดยส่วนใหญ่แล้วเหมือนกัน ความแตกต่างที่มีนั้นมีมาตั้งแต่ก่อนยุคของการทำงานด้วย AI และไม่มีการแบ่งแยกที่ชัดเจน
การใช้งานในอุตสาหกรรม:
การแปลเสียงพากย์ (Voice over translation) มักจะหมายถึงคอนเทนต์ในลักษณะการบรรยาย มีผู้พูดคนเดียว เช่น สารคดี วิดีโออธิบาย หนังสือเสียง โดยเสียงบรรยายจะวางซ้อนอยู่บนวิดีโอมากกว่าการพากย์แบบจับคู่ตรงกับช่องปากของผู้พูด
การพากย์เสียง (Dubbing) มักจะหมายถึงบทสนทนา มีผู้พูดหลายคน และให้ความสำคัญกับการขยับปากให้ตรงกับเสียง (Lip-sync) โดยภาพยนตร์และละครมักจะคุ้นเคยกับคำนี้
ในภาคปฏิบัติ เส้นแบ่งนี้ค่อนข้างคาบเกี่ยวกัน ยกตัวอย่างเช่น ครีเอเตอร์ที่บรรยายวิดีโอบน YouTube และต้องการแปลงวิดีโอนั้นเป็นภาษาสเปน สิ่งนี้คือการแปลเสียงพากย์หรือการพากย์เสียงกันแน่? คำตอบคือใช้ได้ทั้งสองคำ เนื่องจากขั้นตอนการทำงานนั้นเหมือนกันทุกประการ นั่นคือ รับเสียงเข้ามา → แปลภาษา → ส่งเสียงออกไป → นำเสียงกลับไปประกบเข้ากับวิดีโอ
หากต้องการกฎเกณฑ์ที่เข้าใจง่ายๆ ให้มองว่าการแปลเสียงพากย์คือหมวดหมู่ที่กว้างกว่า ส่วนการพากย์เสียง (dubbing) คือกรณีที่ความแม่นยำในการขยับปากของเสียงใหม่เป็นแกนหลักสำคัญของผลงาน ซึ่งทั้งสองส่วนจะรันอยู่บนโครงข่าย AI รูปแบบเดียวกัน โดย โครงสร้างต้นแบบสื่อ AI แบบ 4 ชั้น (4-Layer Model of AI media) จะจัดส่วนนี้ให้อยู่ในชั้นที่ 4 หรือชั้นของการเผยแพร่ (distribution layer) ไม่ว่าคุณจะเลือกใช้คำเรียกใดในอุตสาหกรรมก็ตาม
ส่วนที่เหลือของคู่มือนี้จะใช้คำว่า "การแปลเสียงพากย์ (voice over translation)" เป็นคำครอบคลุมหลัก หากในกรณีที่การขยับปากมีความสำคัญเป็นพิเศษ ทางเราจะระบุเจาะจงลงไป
การทำงานของการแปลเสียงพากย์ที่ขับเคลื่อนด้วย AI
กระบวนการทำงานมี 4 ขั้นตอน ซึ่งเนื้อหาทั่วไปมักจะใช้เวลาดำเนินการเสร็จสิ้นในระดับไม่กี่วินาทีหรือนาทีเท่านั้น
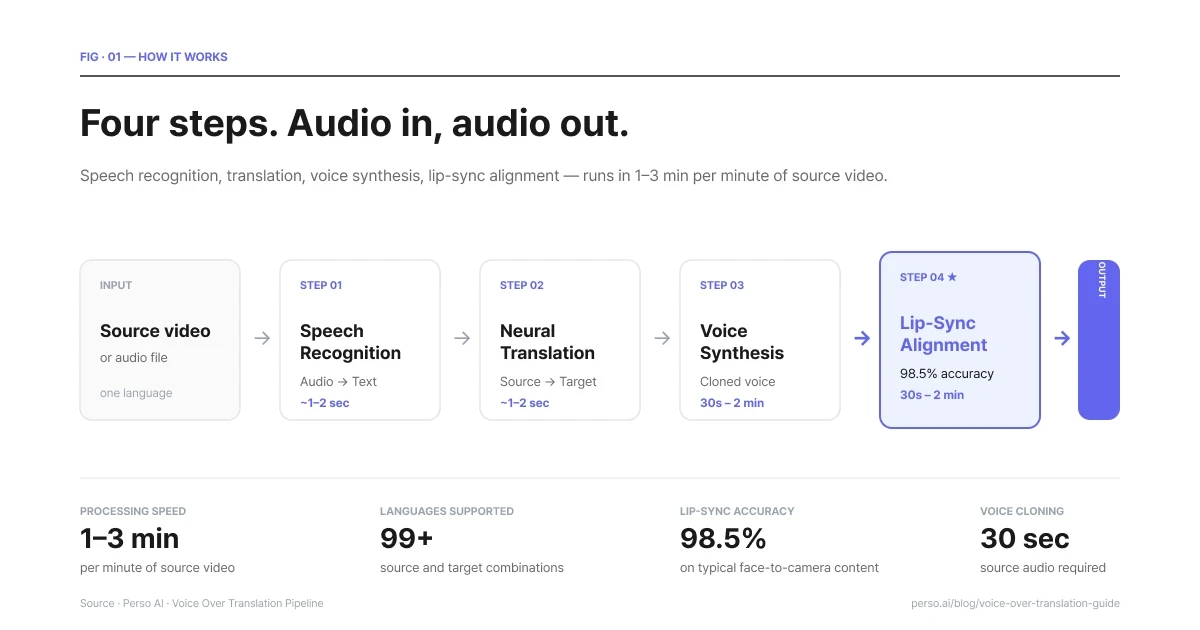
สี่ขั้นตอน เริ่มต้นจากสัญญาณเสียงขาเข้า สิ้นสุดที่สัญญาณเสียงขาออก ใช้เวลา 1-3 นาทีสำหรับการแปลงวิดีโอต้นฉบับทุกๆ 1 นาที
ขั้นตอนที่ 1 — การรู้จำเสียงพูด ตัวระบบจะถอดเสียงจากวิดีโอต้นฉบับออกมาเป็นข้อความตัวอักษร ระบบการรู้จำเสียงพูดในปัจจุบันสามารถจัดการกับเรื่องสำเนียง เสียงดนตรีประกอบ ผู้พูดหลายราย และรูปแบบเสียงตามธรรมชาติ (อาทิ คำเติมเสียง การเว้นจังหวะ การเริ่มประโยคใหม่) ได้เป็นอย่างดี ผลของการถอดเสียงนี้จะเป็นฐานข้อมูลสำคัญในขั้นตอนต่อไป ดังนั้น เรื่องความแม่นยำจึงสำคัญอย่างที่หลายคนไม่คาดคิด หากการถอดความแย่ ผลการแปลก็จะแย่ตาม ส่งผลให้เสียงพากย์ปลายทางแย่ไปด้วย
ขั้นตอนที่ 2 — การแปลภาษา ข้อความที่ถอดเสียงมาจะถูกส่งเข้าไปแปลผ่านระบบโครงข่ายประสาท (neural translation) ที่ปรับจูนมาสำหรับภาษาพูดโดยเฉพาะแทนที่จะเป็นภาษาเขียน ภาษาพูดมักจะสั้นกว่า มีความเป็นสำนวน มีการอิงตามบริบทมากกว่าภาษาเขียน ดังนั้น โมเดลการแปลที่ตอบโจทย์งานเอกสารได้เป็นอย่างดีอาจแปลเสียงพูดออกมาได้แย่ และในทางกลับกันก็เช่นกัน โดยผลลัพธ์ที่ได้จะเป็นบทแปลในภาษาเป้าหมายที่มีการตั้งจังหวะเวลาเพื่อจับคู่กับจังหวะของต้นฉบับให้ใกล้เคียงที่สุด
ขั้นตอนที่ 3 — การสังเคราะห์เสียง สคริปต์ที่ได้รับการแปลแล้วจะถูกสังเคราะห์ออกมาเป็นคำพูดจริง โดยมีทางเลือกหลักๆ อยู่สองแนวทาง
แนวทางแรกคือ เสียงสำเร็จรูป (stock voices) ซึ่งทำได้โดยการเลือกเสียงจากคลังที่มีมาให้เพื่อนำมาใช้งาน วิธีนี้ทำได้รวดเร็วและไม่มีเรื่องกังวลด้านลิขสิทธิ์ แต่เสียงใหม่ที่ได้นั้นจะไม่มีจุดที่เหมือนกับเสียงของคนพูดเดิมเลย
แนวทางที่สองคือ การโคลนเสียง (voice cloning) จะเป็นการฝึกสอนโมเดลระบบด้วยเสียงของคนพูดต้นฉบับ แล้วสังเคราะห์คำพูดในภาษาเป้าหมายให้ออกมาภายใต้เสียงเดียวกัน ซึ่งผลลัพธ์ที่ได้จะฟังดูราวกับคนเดิมกำลังพูดคุยในภาษาใหม่ และนี่คือสิ่งที่เหล่านักทำงานแปลเสียงพากย์ระดับมืออาชีพต้องการ
ขั้นตอนที่ 4 — การปรับแต่งภาพการขยับปากให้ตรงกัน (กรณีที่เป็นวิดีโอ) หากเนื้อหาขาเข้าเป็นวิดีโอ เสียงสังเคราะห์ใหม่จะถูกนำไปปรับให้สอดคล้องตรงกับการเคลื่อนไหวปากต้นฉบับ ปัจจุบันระบบทั่วไปสร้างความแม่นยำได้สูงราว 98% สำหรับเนื้อหามาตรฐาน หากไม่มีขั้นตอนนี้ เสียงพากย์ใหม่จะเล่นประกอบไปกับภาพการขยับปากตามจังหวะเวลาของภาษาเดิม ซึ่งผู้รับชมส่วนใหญ่จะรู้สึกอึดอัดขัดตาในเวลาเพียงไม่กี่วินาที
Perso Dubbing รันระบบการทำงานทั้งหมดนี้เป็นขั้นตอนเดียว เพียงอัปโหลดวิดีโอ เลือกภาษาปลายทาง แล้วรับวิดีโอที่ทำงานสำเร็จกลับไป โดยระยะเวลาในการประมวลผลทั้งหมดจะอยู่ที่ประเด็น 1 ถึง 3 นาที ต่อความยาววิดีโอต้นทาง 1 นาที เช่น วิดีโอความยาว 5 นาที จะใช้เวลาแปลประมาณ 5 ถึง 15 นาที
ควรใช้การแปลเสียงพากย์เมื่อใด
การตัดสินใจมักไม่ใช่แค่คำว่า "ฉันจำเป็นต้องแปลเลยดีไหม" เพราะข้อนั้นดูมีความชัดเจนอยู่แล้วตามความคุ้มค่าทางเศรษฐกิจ แต่คำถามสำคัญคือคุณควรพิจารณาเลือกรูปแบบการแปลในลักษณะใด
การแปลเสียงพากย์จะเหมาะสมเป็นอย่างยิ่งเมื่อ:
เนื้อหานั้นเป็นวิดีโอและกลุ่มผู้ชมชอบรับชมข้อมูลรูปแบบวิดีโอ คำบรรยายอาจใช้ได้จริงสำหรับคนบางกลุ่ม แต่ในแง่ของข้อมูลเวลาการรับชม (watch-time data) แสดงให้เห็นอย่างเด่นชัดว่า กลุ่มผู้ชมที่ไม่ใช่เจ้าของภาษาจะชอบรับชมวิดีโอที่มีการพากย์เสียงมากกว่าวิดีโอที่มีแค่คำบรรยาย รายงาน State of AI Dubbing 2026 เผยว่า 96% ของวิดีโอที่พากย์เสียงด้วย AI มักถูกแชร์ออกไปในวันเดียวกันกับที่มีการผลิตทันที ซึ่งนี่คือหนึ่งในพฤติกรรมบ่งชี้สำหรับคอนเทนต์ที่สร้างขึ้นเพื่อหวังผลด้านการกระจายข้อมูล ไม่ใช่สร้างมาเพื่อจัดเก็บไว้เฉยๆ
คุณมุ่งเน้นความเป็นแบรนด์และเสียงที่มีอยู่เดิม เสียงของครีเอเตอร์ย่อมเป็นหนึ่งในเอกลักษณ์ของแบรนด์ เช่นเดียวกับผู้บรรยายประจำแบรนด์ที่เป็นส่วนหนึ่งของแบรนด์เช่นกัน การแปลเสียงพากย์ด้วยการโคลนเสียงจะช่วยรักษาภาพจำและเอกลักษณ์เหล่านั้นเอาไว้ได้อย่างสมบูรณ์ในทุกภาษาที่แปลไป โดยการใช้คำบรรยายใต้ภาพจะตัดองค์ประกอบนี้ทิ้งไป
กลุ่มเป้าหมายของคุณใช้สมาร์ตโฟนเป็นหลักหรือรับชมแบบผ่านๆ คอนเทนต์ที่มีแค่ซับไตเติลจะดึงความสนใจของผู้รับชมให้อยู่กับหน้าจอตลอดเวลา แต่การแปลเสียงพากย์จะช่วยให้ผู้ฟังสามารถรับฟังไปได้ในขณะขับรถ ทำอาหาร หรือทำงานอยู่ได้ ซึ่งจะสอดรับเป้าหมายกับตลาดกลุ่มโมบายล์เฟิร์ส (อย่างอินเดีย เอเชียตะวันออกเฉียงใต้ ลาตินอเมริกา) ที่เลือกเสพคอนเทนต์พากย์เสียงด้วยเหตุผลดังกล่าว
คุณกำลังเผยแพร่เนื้อหาไปยังหลายตลาดพร้อมกัน การผลิตคำบรรยายมักจะมีอัตราการทำที่เพิ่มสัดส่วนไปตามปริมาณงานแปล (Linear scale) ขยับเพิ่มหนึ่งภาษาก็หมายถึงขั้นตอนการตั้งเวลา จัดรูปแบบ อัดซับไตเติลใหม่อีกยกหนึ่ง แต่การแปลเสียงพากย์นั้นจะใช้อัตราการขยายงานต่ำกว่าสัดส่วนความยาก (Sub-linear scale) เพราะเมื่อวางระบบการส่งทำงานเอาไว้เรียบร้อยแล้ว การเพิ่มภาษาที่ 6 หรือ 7 จะใช้เวลาประมวลผลเพิ่มขึ้นอีกเพียงไม่กี่นาทีเท่านั้นแทนที่จะเป็นเวลาในการปรับแต่งแก้ไขไฟล์โดยบรรณาธิการงานวิดีโอหลายๆ วัน
การแปลเสียงพากย์จะมีความจำเป็นน้อยลงเมื่อ:
กลุ่มเป้าหมายเหมาะสมกับคำบรรยายมากกว่า ตัวอย่างคลาสสิกคือผู้ชมภาพยนตร์ต่างประเทศในประเทศญี่ปุ่น โดยผู้ชมบางกลุ่มจะให้ความสำคัญกับเรื่องการชมพร้อมซับไตเติลก่อนเสมอไม่ว่าจะมีต้นทุนพากย์เสียงเปรียบเทียบเท่าใด ดังนั้นควรทดสอบก่อนที่จะสรุปแนวความคิด
ความยาววิดีโอสั้นจนทำให้การเตรียมซับไตเติลเป็นเรื่องง่าย เช่น คลิปโซเชียลความยาว 60 วินาที อาจไม่คุ้มค่าพอที่จะนำไปใช้ทำเสียงพากย์ใหม่
องค์ประกอบเสียงพากย์ตัวเดิมคือหัวใจหลักของชิ้นงานนั้น เช่น เสียงนักบรรยายที่มีความเป็นเอกลักษณ์เฉพาะตัว, เทคนิคการนำเสนอของตัวนักแสดงโดยเฉพาะ, หรือเทปบันทึกการแสดงสดที่เสียงจริงในสนามเป็นเสน่ห์หลัก การแปลเป็นภาษาอื่นอาจทำลายองค์ประกอบสุนทรียภาพที่ควรได้สัมผัสไป ซึ่งในกรณีทำนองนี้ การใช้ซับไตเติลจึงสามารถแสดงรักษาคุณลักษณะเดิมเอาไว้ได้ดีที่สุด
การแปลเสียงพากย์เปรียบเทียบกับการใช้ซับไตเติล — การเลือกรูปแบบที่เหมาะสม
คำบรรยาย (Subtitles) และการแปลเสียงพากย์ตอบจุดประสงค์เชิงธุรกิจเดียวกัน นั่นคือ “จะเข้าถึงกลุ่มผู้ใช้ที่พูดต่างภาษากันอย่างไร” แต่จะส่งมอบประสบการณ์ด้านมุมมองการรับชมข้อมูลภาพให้แก่ผู้รับรับชมแตกต่างกันออกไป

การเปรียบเทียบซับไตเติลกับการแปลเสียงพากย์ — ข้อเด่นจุดแข็งในแต่ละรูปแบบ
มิติการทำงาน | คำบรรยาย (ซับไตเติล) | การแปลเสียงพากย์ |
|---|---|---|
ต้นทุนต่อหนึ่งภาษา | ต่ำ (แปรผันตามเวลาทำงานของผู้ตรวจทาน) | ปานกลาง (ค่าบริการส่งงานประมวลผลระบบ + ลิขสิทธิ์เสียงโคลน) |
ระยะเวลาจัดทำต่อหนึ่งภาษา | หลายชั่วโมง | ระดับนาที (ด้วยการทำงานของ AI) |
มติการรับชมงาน | ต้องคอยเพ่งกวาดสายตาเพื่ออ่าน | รับฟังในภาษาท้องถิ่นของตนเอง |
การตอบรับกับสมาร์ตโฟน / งานผ่านๆ | มีข้อจำกัด | ทำงานได้ครบกระบวนการดี |
คงจุดเอกลักษณ์แบรนด์ | ใช่ (คงลักษณะเสียงต้นฉบับไว้ได้ครบถ้วน) | ใช่ (ตอบโจทย์ได้เมื่อใช้บริการโคลนเสียง) |
ความพร้อมใช้งานสำหรับกลุ่มคนหูหนวก / มีปัญหาการได้ยิน | ✅ มีความจำเป็นสูงสุด | ต้องใช้การเตรียมแยกไฟล์ต่างหาก |
เหมาะที่สุดสำหรับ | คลิปขนาดสั้น, กลุ่มเป้าหมายเฉพาะกลุ่ม | วิดีโอแบบเต็มขนาด สเกลงานจำนวนมาก |
ในความเป็นจริง ลำดับการประมวลผลงานภาพสื่อในปัจจุบันส่วนใหญ่มักจะเตรียมควบคู่กันทั้งคู่ กล่าวคือ ใช้การแปลเสียงพากย์เป็นหลัก และมีตัวเลือกรองรับซับไตเติลเพื่อตอบโจทย์ผู้รับชมทุกกลุ่ม โดยแพลตฟอร์มพากย์เสียงด้วย AI ในปัจจุบันมักนำพาชุดการดาวน์โหลดทั้งสองรูปแบบนี้จาก Flow เดียวกัน เนื่องจากผลพวงของการถอดระดับคำแปลได้ถูกจัดเรียงในขั้นตอนที่ 1 และ 2 ไว้อยู่แล้ว
วิธีการแปลเสียงพากย์ด้วย AI (ทีละขั้นตอน)
ข้อมูลลำดับขั้นตอนถัดจากนี้สอดคล้องกับการใช้งานจริงบน Perso Dubbing โดยหน้าจอการจัดการแอปในแบรนด์อื่นๆ อาจแตกต่างออกไป แต่จะอิงกรอบระเบียบตรรกะแบบเดียวกัน
1. อัปโหลดไฟล์วิดีโอหรือเสียงต้นฉบับ โยนไฟล์งานของคุณเข้าระบบ โดยส่วนใหญ่แล้วจะรองรับนามสกุลไฟล์ MP4, MOV, MP3, WAV และหากชิ้นงานอยู่บน YouTube ก็เพียงนำลิงก์ปลายทางมาวางได้ทันที
2. เลือกภาษาเป้าหมายที่ต้องการรับแปลง สามารถระบุได้หนึ่งหรือหลากหลายภาษาพร้อมๆ กัน ซึ่ง Perso Dubbing รองรับหลากหลายรหัสภาษากว่า 99 ภาษา ทั้งภาษาต้นฉบับและภาษาปลายทาง ตัวอย่างรหัสภาษายอดนิยมที่เลือกใช้บ่อย เช่น ภาษาสเปน ภาษาโปรตุเกส ภาษาฝรั่งเศส ภาษาเยอรมัน ภาษาญี่ปุ่น และภาษาเกาหลี
3. ตรวจเช็คข้อมูลผลการคลิกถอดคำแปลอัตโนมัติ ระบบจะแสดงชุดข้อความที่ถอดออกมาจากไฟล์ภาษาต้นฉบับ ให้ทำการปรับแก้ไขในส่วนที่ระบบตรวจจำเสียงวิเคราะห์ผิดพลาดก่อนที่จะส่งต่อไปยังสเต็ปแปลภาษา การแก้ไขตั้งแต่เนิ่นๆ ในจุดนี้จะลดทอนปัญหาความผิดพลาดซ้อนทับลงได้เป็นอย่างดี
4. เรียบเรียงและปรับพฤติกรรมการแปล (ตัวเลือกเพิ่มเติม) ตรวจเช็ครูปแบบประโยคที่แปลออกมาก่อนก้าวเข้าสู่ขั้นตอนการประมวลผลเสียงพูด สังเกตในเนื้อหาข้อความที่เป็นศัพท์เฉพาะทาง วิธีคำเรียกชื่อแบรนด์ เพื่อลบประเด็นความผิดพลาดซึ่งการมาตามไล่แก้ภายหลังจะทำได้ยากเป็นอย่างยิ่ง
5. ทำการประมวลผล (Generate) ตัวกระบวนการสังเคราะห์เสียงและการจับคำแปลงช่องปากปากให้ตรงจังหวะจะเริ่มต้นขึ้น โดยรวมแล้วจะกินระยะเวลาประมาณ 1 ถึง 3 นาที สำหรับความยาววิดีโอไฟล์ 1 นาที (เช่น วิดีโอ 5 นาที จะให้ผลแล้วเสร็จอยู่ในช่วงเวลา 5 ถึง 15 นาที)
6. ทำการดาวน์โหลดหรือแชร์ข้อมูล ผลปลายทางที่ได้รับจะพร้อมทำงานในรูปแบบไฟล์สกุล MP4 ที่แยกตามภาษาที่กำหนด ไปจนถึงไฟล์ซับไตเติลนามสกุล .srt เพื่อช่วยเสริมคุณลักษณะการเข้าชมที่ดีขึ้น แพลตฟอร์มบางตัวมีชุดดาวน์โหลดเสียงสกุล MP3 มาให้เพิ่มเติมในกรณีสำหรับผู้ที่ต้องการแต่องค์ประกอบเนื้อหาเสียงเท่านั้น
ขั้นตอนทำงานทั้งหมดรันอยู่เบนแพลตฟอร์มเดียวจนเสร็จสิ้น รายงาน State of AI Dubbing 2026 ชี้ให้เห็นถึงข้อมูลผลทดสอบที่มีการแชร์ออกไปในวันจัดส่งงานสูงถึง 96% เกิดจากการออกแบบระบบวงงานเดี่ยวในลักษณะนี้ ไม่ใช่เป็นการโยนส่งต่อไฟล์สลับไปมาระหว่างโปรแกรมแต่อย่างใด
คุณภาพผลงานแปลเสียงพากย์ — สิ่งที่คุณควรพิจารณาและตรวจสอบ
คุณภาพการออกแบบเสียงมี 3 องค์ประกอบหลักๆ และทุกส่วนสำคัญเท่าเทียมกันหมด จุดด้อยที่สุดใน 3 ข้อนี้จะกำหนดทัศนคติในผลงานทั้งหมดที่ผู้ชมประเมินทันที
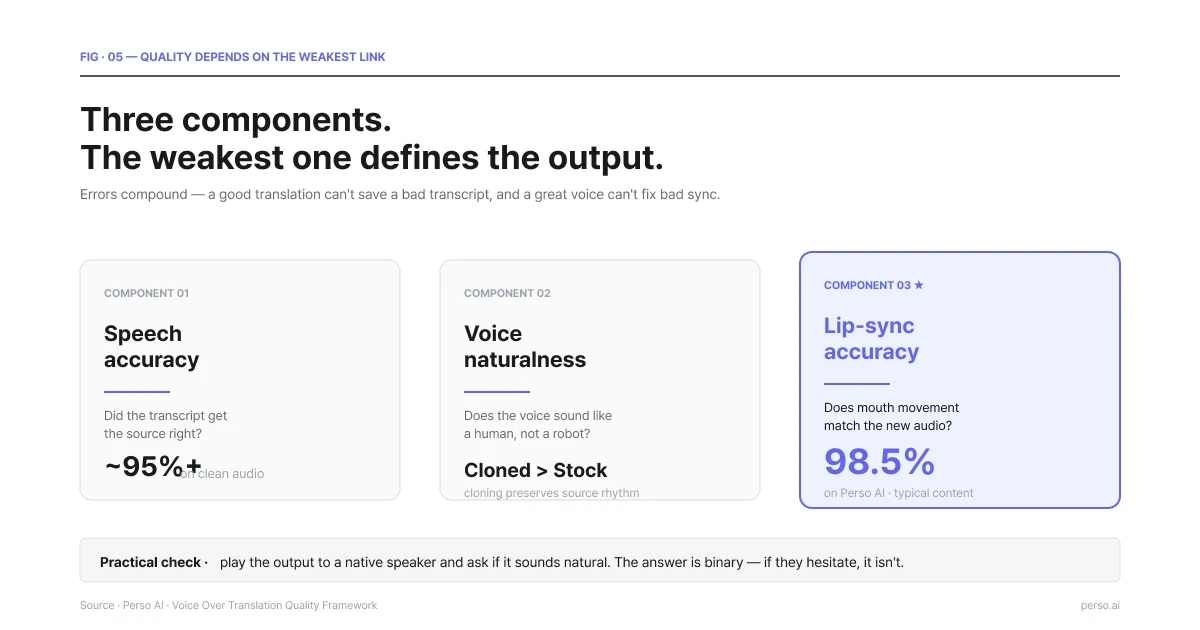
สามองค์ประกอบสำคัญ ซึ่งจุดที่มีคุณภาพแย่ที่สุดจะเป็นเกณฑ์ตัดสินคุณภาพผลงานชิ้นนั้นๆ
ความสมบูรณ์ของความหมายเสียง ข้อความเสียงพากย์ปลายทางสื่อข้อความได้ถูกต้องตรงกับแนวคิดต้นฉบับพูดยืนหยัดอยู่หรือไม่? การแปลที่ผิดเพี้ยนไปจากชื่อแบรนด์ ศัพท์เฉพาะเชิงความรู้ หรือประโยคแวดล้อมวงการ เป็นส่วนจุดผิดพลาดหลักๆ ที่มักเกิดขึ้น แนวทางบรรเทาปัญหาก็คือตรวจดูชุดคำแปลสคริปต์ให้สมบูรณ์ก่อนก้าวย่างไปสู่ขั้นตอนการสังเคราะห์เสียงทำงาน
ความลื่นไหลเป็นธรรมชาติของเสียงพากย์ น้ำเสียงที่รับเข้าฟังดูมีความนุ่มนวลอย่างที่มนุษย์ใช้โต้ตอบสนทนา หรือเป็นน้ำเสียงทื่อๆ คล้ายหุ่นยนต์อ่านคู่มือเอกสาร? ระบบเสียง AI ปัจจุบันสามารถลบช่องว่างความไม่เป็นธรรมชาติเหล่านั้นทิ้งไปได้เกือบหมดสิ้น แต่จุดสังเกตยังมีอยู่บ้าง เช่น วรรณยุกต์ สูง-ต่ำ จังหวะความเร็ว หรือการเว้นช่วงการหายใจในจังหวะตัวประโยคอย่างเป็นปกติ การใช้ตัวเลือกโคลนเสียงพากย์ของโคลนเสียงดั้งเดิมจะมอบท่วงทำนองเสียงและจังหวะเวลาในการเอ่ยประโยคตามพฤติกรรมเจ้าของเดิมได้ดีกว่าเสียงในคลังทั่วไป
ความเนียนกริบของช่องปาก (สำหรับวิดีโอ) อัตราการเคลื่อนไหวริมฝีปากประสานรับกับเสียงใหม่ที่สังเคราะห์ไปได้ดีหรือไม่? Perso Dubbing มีความภูมิใจในตัวเลขเฉลี่ยความสำเร็จของการทำงานปรับปากตรง 98.5% ของขั้นตอนทั้งหมด ซึ่งถือเป็นหนึ่งในสถิติที่เปิดเผยต่อสาธารณะสูงสุด สำหรับจุดความไม่เข้ากันที่เหลือราว 1.5% มักจะสังเกตเห็นได้ง่ายเฉพาะในซีนที่เป็นการโคลสอัพที่ดวงหน้ากล้องตรงๆ เท่านั้น สำหรับฉากมุมกว้างหรืออยู่ไกลระดับความไวของสายตาต่อการจับขยับรอบปากจะลดลงเนื่องจากขนาดกรอบสัดส่วนรอบมุมปากที่เล็กลงในหน้าจอ
เคล็ดลับขั้นตอนการวัดคุณภาพฉบับง่าย: ลองส่งชิ้นงานตรวจสอบคุณภาพที่สำเร็จให้เจ้าของภาษาจริงเป็นผู้รับฟังแล้วสอบถามดูว่าฟังแล้วรู้สึกเป็นธรรมชาติดีไหม คำตอบมีเพียงใช่หรือไม่ใช่เท่านั้น หากพวกเขารู้สึกแปลกๆ แม้จะเพียงเล็กน้อยก็ถือว่ายังไม่ได้คุณภาพ
กลุ่มภาษาที่เป็นที่นิยมในการนำมาแปลเสียงพากย์
ความต้องการปริมาณงานไม่ได้กระจายตัวเป็นปริมาณที่เท่ากัน ภาพรวมข้อมูลของสถิติบนระบบ Perso Dubbing จากการรวบรวมโปรเจกต์งานพากย์ทับ 316,856 ชิ้นงาน และการส่งงานของกลุ่มผู้ผลิตมืออาชีพ 4,023 ราย แสดงให้เห็นถึงแนวภาษาเป้าหมายยอดหลักๆ ที่มีสถิติก้าวเดินไปสู่สายตาตลาดโลกได้ชัดเจนที่สุด
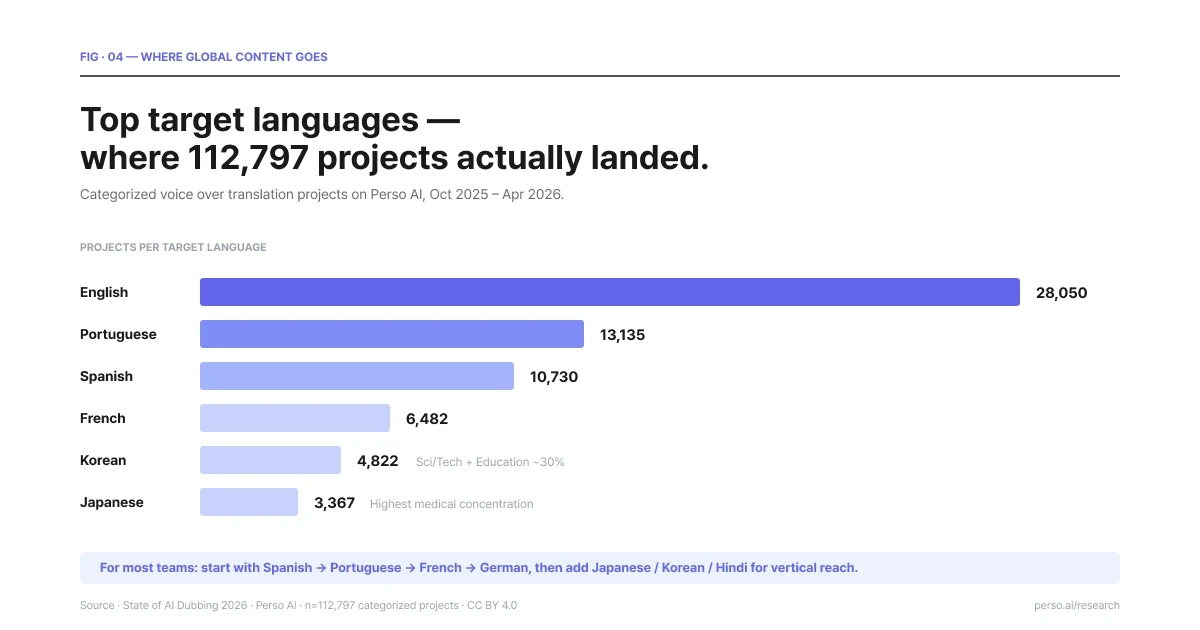
ภาษาเป้าหมายยอดนิยมจากสถิติจริงของโครงการแปลเสียงพากย์ 112,797 โปรเจกต์ แหล่งอ้างอิงข้อมูล: State of AI Dubbing 2026
ภาษาอังกฤษ ครองส่วนสัดสำคัญสูงสุดในฐานะภาษาปลายทางเป้าหมาย (ด้วยสถิติตลอดโปรเจกต์กลุ่มคำแปลถึง 28,050 ชิ้นงาน) แต่ก็มีภาพงานกระจายตัวกว้างที่สุด โดยไม่มีอุตสาหกรรมในสายงานใดครองตัวเลขเกิน 14% เลย ภาษาอังกฤษเป็นภาษาปลายทางหลักสำหรับกลุ่มการแปลงเพื่อส่งสารขยายงานออกไปของครีเอเตอร์ที่ไม่ใช่เจ้าของภาษาอังกฤษ
ภาษาโปรตุเกส (13,135 ชิ้นงาน) ค่อนข้างเด่นในการประดับสัดส่วนกลุ่มเป้าหมายเชิงหลากหลายด้าน ทั้ง อนิเมชัน ประเด็นความเชื่อ ศาสนา และงานเรียน คอร์สฝึกการเรียน มีสัดส่วนร่วมแตะระดับ 10% ทั้งหมด โดยถ้าเจาะสำนวนไปที่ภาษาโปรตุเกสบราซิล จะทวีสัดส่วนสูงสุดเป็นอันดับสองของการแปลประเด็นหลักบทความเชิงความเชื่อศาสนาร่วมกับสายภาษาอังกฤษ โดยรายงาน State of AI Dubbing 2026 พบตัวเลขเทียบเคียงร่วมกันที่ ภาษาอังกฤษ 25.6% / ภาษาโปรตุเกส 25.2% ภายในกลุ่มโปรเจกต์ศาสนาดังกล่าว ซึ่งสถิตินี้ทำให้หลายๆ ฝ่ายรู้สึกแปลกใจหลังจากที่คาดกันมาก่อนหน้านี้ว่า ภาษาสเปน ควรเป็นตัวเลือกหลักของภูมิภาคละตินอเมริกา
ภาษาสเปน (10,730 ชิ้นงาน) จะเป็นภาษาหลักที่ขึ้นนำอย่างสูงมากในส่วนหมวดหมู่ระบบการเรียนการสอนและข่ายศาสนา ทั่วภูมิภาคลาตินอเมริกา
ภาษาเกาหลี (4,822 ชิ้นงาน) นำเสนอสถิติน่าประทับใจเป็นพิเศษ โดย 30% ของปริมาณงานที่แปลงไปเป็นภาษาเกาหลีมีจุดหมายปลายทางที่กระบวนการเนื้อหาเชิงแวดวงแชร์ความรู้ (เมื่อนับส่วนวิทยาศาสตร์ เทคโนโลยี ประสานเข้ากับหมวดวิชาการศึกษา) สถิติชุดนี้เป็นผลพวงเกาะกลุ่มของทิศทาง K-Content ที่ตลบเข้าหากลุ่มงานแวดวงอื่นๆ ยิ่งกว่าฝั่งบันเทิงเพียงหมวดเดียว
ภาษาญี่ปุ่น (3,367 ชิ้นงาน) ถ่ายทอดความต้องการเชิงการสร้างเนื้อหาระบบทางการแพทย์ขั้นรุนแรงพอดูเมื่อเปรียบเทียบในแง่อัตราร่วมกับสถิติกลุ่มอื่น งานชุดคู่มือสาธิตรักษาและสร้างความเข้าใจแด่คนไข้จะมีสัดส่วนเฉลี่ยการทำภาษาญี่ปุ่นมากเป็นพิเศษ
ภาษาฝรั่งเศส (6,482 ชิ้นงาน) มักขับเคลื่อนผ่านกลุ่มชิ้นงานประเภทนำเสนอวิดีโอสารคดีเป็นสำคัญ ซึ่งเชื่อมสัมพันธภาพกับวัฒนธรรมด้านภาพและขั้นตอนการสนับสนุนแนวจัดแต่งงานสารคดีของประเทศฝรั่งเศสตามประวัติการผลิตอย่างแกร่งกล้า
ดังนั้น สำหรับผู้ผลิตงานเริ่มต้นกระบวนการแปลใหม่ๆ ระบบการพิจารณารหัสภาษามาตรฐานลำดับต้นๆ เพื่อหวังขยายโอกาสเข้าหาผู้คนวงกว้าง สามารถพิจารณาพาสเต็ปเลือกการทำงานดังนี้: ภาษาสเปน → ภาษาโปรตุเกส → ภาษาฝรั่งเศส → ภาษาเยอรมัน และหากต้องการเน้นเป้าหมายระดับกลุ่มอุตสาหกรรมเฉพาะขีดภูมิภาค ก็ต่อยอดด้วยการวางระบบรองรับ: ภาษาญี่ปุ่น → ภาษาเกาหลี → ภาษาฮินดี → ภาษาอาหรับ เพิ่มเติม
เปรียบเทียบต้นทุนราคาระหว่าง — AI และเสียงนักพากย์จริง
ความคุ้มค่าที่ต่างกันสุดขั้วในตัวงานแบบโมเดล AI เมื่อเทียบการส่งทำงานพากย์ทับด้วยแรงคน นับเป็นจุดปฏิรูปความคุ้มค่ากระโดดตัวสูงสุดที่อุตสาหกรรมประเภทนี้เคยมีมา
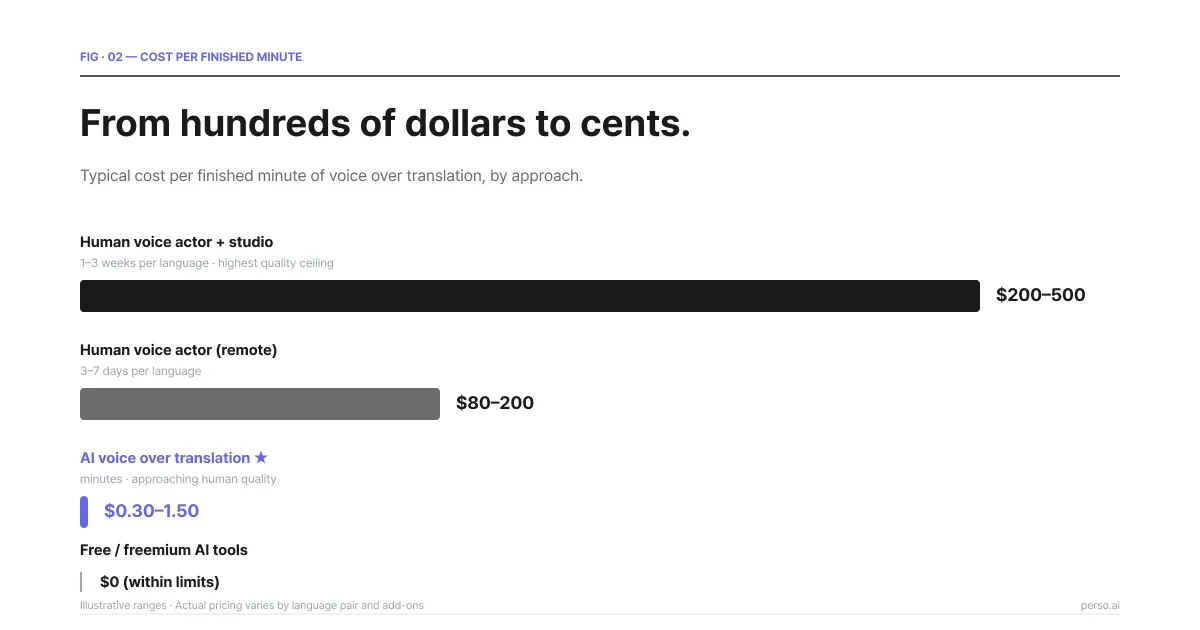
ต้นทุนราคาต่องานวิดีโอที่เสร็จสมบูรณ์ต่อหนึ่งนาทีของประเภทวิถีทำ ค่าพากย์ด้วย AI มีแนวราคาที่ถูกคุ้มทุนกว่าการเข้าตู้พากย์จริงด้วยสุนทรียภาพเสียงระดับสตูดิโอราว 100 เท่า
แนวทางวิธีการผลิต | แนวราคาพิจารณาทั่วไป | ระยะเวลาจัดทำ | เพดานคุณภาพ |
|---|---|---|---|
ใช้นักพากย์ + เข้าห้องบันทึกเสียงสตูดิโอ | $200–$500 ต่อนาทีชิ้นงานที่เสร็จสมบูรณ์ | 1–3 สัปดาห์ ต่อกลุ่มภาษาเป้าหมาย | สูงสุดเหนือกฎเกณฑ์ประเมิน |
ใช้นักพากย์ส่งเสียงบันทึก (จัดทำจากระยะไกล) | $80–$200 ต่อนาทีชิ้นงานที่เสร็จสมบูรณ์ | 3–7 วัน ต่อกลุ่มภาษาเป้าหมาย | ระดับสูง |
การทำงานแปลเสียงพากย์ด้วยเครื่องมือ AI | $0.30–$1.50 ต่อนาทีชิ้นงานที่เสร็จสมบูรณ์ | ระดับเป็นนาที | ให้ผลไล่จี้และใกล้เคียงกับมาตรฐานนักพากย์ส่งงานในเกือบทุกจุดพิจารณา |
ชุดใช้ฟรี / ชุดบริการแอปที่จำกัดเงื่อนไข | $0 ฟรีภายใต้เงื่อนไขกำหนด | ระดับเป็นนาที | คุณภาพไม่แน่นอน มักเห็นจุดเพี้ยนได้บ่อยครั้ง |
ตัวเลขข้างต้นเป็นเพียงข้อมูลภาพรวมสำหรับประกอบความเข้าใจ — เนื่องจากแนวราคาจริงของงานจะแปรผันตามคู่คำแปล ข้อตกลงเสริมการเลือกใช้ระบบโคลนนิ่งเสียงและเงื่อนไขแพลตฟอร์มปลายทาง สำหรับสัดส่วนคิดค่าใช้จ่ายของทาง Perso Dubbing จะประเมินจากเวลาจริงของการเกิดไฟล์เสียงพากย์ใหม่เป็นหลัก (Per-second billing) ดังนั้นหากวิดีโอคุณสั้นระดับ 30 วินาที ระบบจะคิดราคาสินค้าอิงที่ระยะ 30 วินาที เท่านั้น โดยไม่ทำการปัดค่าขึ้นไปสู่ 1 นาที แบบที่แพลตฟอร์มรายอื่นบ่อยครั้งมักคิดประเมินงาน
ข้อได้เปรียบเชิงต้นทุนนี้จะทวีความสำคัญชัดเจนขึ้นไปอีกเมื่อเผชิญกลุ่มโปรเจกต์ประเภทต้องการสเกลหลากหลายสีสันภาษา เมื่อก้าวเทียบงานจาก 1 ภาษาขยายไปสู่ 10 ภาษา หากเป็นแนวคิดใช้คนพากย์ แปลว่ามูลค่าจ่ายจะทวีคูณคูณ 10 ทันที แต่บนกลไกเครื่องแปลผ่าน AI ตัวเลขประเมินราคาจะขึ้นไปเพียงเล็กน้อย (เนื่องจากทุกภาษาที่ขยายจะบวกส่วนโครงสร้างงานประมวลผลเพิ่มขึ้น แต่สัดส่วนแกนการจัดการจะนิ่งคงราคาเท่าเดิม) นี่คือสิ่งที่ รายงาน State of AI Dubbing 2026 เรียกว่า "ทางลาดขยายภาษา (Language onramp)" ครีเอเตอร์ส่วนใหญ่มักปิดโอกาสหยุดการนำเสนอภาษาปลายทางที่เป้าหมายภาษาเดียวเพราะเงื่อนไขค่าลิขสิทธิ์สตูดิโอที่โหดร้าย แต่เมื่อนำข้อเปรียบระบบ AI เข้ามาปรับแกนสมการ ตัวเลขแนวโน้มการผลิตสื่อขยายแบรนด์จะเติบโตขึ้นทันตา
สำหรับผลงานประเภทพรีเมียมที่ตัวน้ำเสียงและอารมณ์คือตัวขับเคลื่อนหลักจริงๆ เช่น ภาพยนตร์โรง, เกมฟอร์มยักษ์ระดับ AAA คอนเทนต์สารคดีชั้นเลิศ การพึ่งพานักพากย์ระดับมืออาชีพยังคงตอบข้อเรียกร้องสุนทรียศิลป์สูงสุดได้ตรงประเด็นจุดหมาย แต่สำหรับงานแขนงอื่นนอกเหนือจากนี้ เทคนิคการคิดพึ่งพาแปลเสียงพากย์ผ่านระบบ AI กลายมาเป็นคำตอบแรกสุดของกระบวนการทำสื่อใหม่ๆ ไปเสียแล้วในปัจจุบัน
————————————————————————-
คำถามที่พบบ่อย (FAQs)
ค. การแปลเสียงพากย์ถือเป็นเรื่องเดียวกับการพากย์เสียง (Dubbing) หรือไม่?
ในภาพรวมเรียกว่า ใช่ โดยการแปลเสียงพากย์จะถือเป็นคำเรียกที่ครอบคลุมขอบเขตวิชาที่กว้างกว่า ขณะที่ คำว่า การพากย์เสียง (dubbing) มักจะเน้นชิ้นงานประเภทที่มีบทสนทนาอัดแน่นหนาหู โดยมีกุญแจสำคัญคือภาพประกอบความตรงของช่องปาก (lip-sync) ร่วมประกบลงตัวในชิ้นงาน ทั้งสองระบบขับเคลื่อนและรันตัวงานผ่านเทคโนโลยีประมวลผล AI ชุดเดียวกัน ได้แก่ การถอดประโยคเสียงแปลคำพูด สังเคราะห์เสียงใหม่ และ ปรับความสมมาตรปาก (สำหรับงานประเภทวิดีโอ)
ค. ตัว AI สามารถแกะและโคลนนิ่งเสียงจากงานของตนเองมาประยุกต์ทำชุดคำพูดภาษาอื่นๆ ได้หรือไม่?
แน่นอนว่าทำได้หมดจด แพลตฟอร์มและแอปแนวพากย์ผ่าน AI สมัยใหม่รองรับฟีเจอร์นี้ได้ครบเฉียบขาด ซึ่งไฟล์สุ่มบันทึกเสียงคุณภาพสะอาดยาวเพียง 30 วินาที ก็ถือเป็นหัวเชื้อฝึกสอนโมเดลระบบที่ดีเยี่ยมสำหรับการถอดความและเรียนรู้ หลังจากนั้นเสียงที่ทำการโคลนได้สมบูรณ์เสร็จสิ้นจะขยับไปสร้างเสียงตามไฟล์แปลภาษาต่างๆ ในสายงานโปรเจกต์ของคุณ ช่วยให้กลายร่างประดับสุนทรียะได้ว่าเจ้าตัวบรรยายได้ทั้งรหัสภาษา สเปน ญี่ปุ่น เยอรมัน และเป้าหมายอื่นๆ ด้วยเนื้อเสียงที่คล้ายคนเดิมทุกคำ
ค. คุณภาพการถ่ายทอดเสียงแบบแปลพากย์ผ่าน AI มีความเสถียรและแม่นยำมากน้อยระดับใด?
ให้พิจารณาคุณภาพผ่านสถิติ 3 ด้านสำคัญได้แก่: อัตราแปลความจำเสียงจากไฟล์ต้นทาง (~95%+ บนคลื่นเสียงที่คมและชัดเจน), อัตราคำแปลที่ถ่ายทอดออกมา (ขึ้นอยู่กับคู่ภาษาที่ใช้จับคู่เป็นสำคัญ โดยคู่ภาษาระดับสากลจะทำได้เนียนถูกต้องยิ่งกว่าคู่ภาษาแถบถิ่นหายาก) และ ประโยชน์การจับลักษณะช่องปาก (~98.5% สำหรับประสิทธิภาพของ Perso Dubbing บนเงื่อนไขเทมเพลตวิดีโอทั่วไป) หากมีจุดที่ทำงานเชื่อมโยงได้ต่ำกว่าเกณฑ์ในจุดใดคุณภาพชิ้นงานภาพรวมทั้งหมดก็จะพลอยตกลงตามไปด้วย
ค. ระยะเวลาการส่งทำงานแปลเสียงพากย์ AI กินเวลาดำเนินการระดับใด?
ประมาณประเมินที่ 1 ถึง 3 นาที ต่อน้ำเสียงวิดีโอต้นทาง 1 นาที เช่นวิดีโอ 5 นาทีจะได้รับชุดคำสำเนาสำเร็จกลับไปในช่วงเวลา 5 ถึง 15 นาที ต่อการแปลงขยายไปหนึ่งเป้าหมาย สำหรับวิดีโอที่ต้องแปลขึ้นพร้อมกันหลากหลายภาษานั้น ความเร็วการประมวลผลจะใช้อัตราการขยายงานต่ำกว่าสัดส่วนความยาก (Sub-linear scale) สรุปง่ายๆ คือการดันงานแปลง 5 ภาษาไปรอบเดียวจะสิ้นเปลืองเวลารวมต่ำกว่าสูตรคูณเดิม (5x3 นาที) เอนเอียงอยู่ระดับใกล้เคียงกับเวลา 5 นาทีหลักชิ้นเดียวเสียอีก
ค. ตัวผู้ทำสามารถเข้าไปเรียบเรียงและเคาะแก้ไขพยัญชนะประโยคคำแปลก่อนที่ AI จะเริ่มสังเคราะห์พากย์ออกมาได้หรือไม่?
ทำได้แน่นอนบนหน้าคอนโซลแพลตฟอร์มสตรีเมอร์และสายงานอาชีพชั้นนำทั่วไป ซึ่งตัวบทคำแปลความจะแสดงขึ้นหลังผ่านขั้นสเต็ปแปลคำเสร็จสิ้น เพื่อพักจังหวะให้คุณตรวจทานปรับแต่งแก้ชื่อแบรนด์ ศัพท์นิเทศเฉพาะตัว หรือพฤติกรรมสำนวนให้ดูเนียนและสวยงามก่อนปล่อยคิวเริ่มประมวลผลขึ้นข้อความพูด ซึ่งการแก้ไขที่ขั้นตอนนี้จะส่งผลดีช่วยเพิ่มคุณภาพงานได้ง่ายกว่าไปง้างสลักแก้ไขคลื่นสัญญาณเสียงในจุดสุดท้ายอย่างมาก
ค. ข้อแตกต่างชัดเจนระหว่างการเลือกทำแปลพากย์แนว Voiceover กับการจัดทำเนื้อหาซับไตเติล?
ซับไตเติลต้องการการกวาดสายตาเพื่อสัมผัสเนื้อเพลงและอักษร แต่การโคลนนิ่งทางพากย์คือการจัดลำดับเนื้อเข้าทางหัวและโสตประสาทหูโดยตรง ทางซับไตเติลจะคงเสน่ห์เสียงคาแรคเตอร์กระแสและบทสวดแบบเดิมไว้ครบและเปิดข้อความคำอธิบายภาษาเป้าหมายที่ขอบจอล่าง แต่เสียงแปลแบบพากย์จะลงมือเปลี่ยนคลื่นสัญญาณภาษาเก่าให้ออกไปจากมิติช่องทางชิ้นไฟล์วิดีโอนั้น ซึ่งแพลตฟอร์มเครื่องมือ AI เกือบทั้งหมดจะคอยป้อนชุดข้อมูลเอกลักษณ์เหล่านี้ออกมาด้วยรูปแบบทั้งสองแบบข้างต้นควบคู่กันเสมอ
ค. การแปลเสียงพากย์สามารถใช้งานกับคอนเทนต์ไลฟ์สด (Live stream) ได้หรือไม่?
ในปัจจุบันยังไม่มีระบบการแปลรองรับที่ใช้งานได้ทันที (เรียลไทม์) ซึ่งกระบวนการแปลพากย์ยังคงจัดบทบาทหน้าที่อยู่ในระดับสายโปรดักชันแก้ไขและขัดเกลางานหลังบ้าน (Post-production) โดยระบบการจับพากย์ทับความไวสูงบนกระแสเวลาจริงกำลังเป็นวิทยาการใหม่ที่กำลังอยู่ในวัฏจักรผลักดันเนื้อหางาน ซึ่งรายงาน State of AI Dubbing 2026 ระบุว่า ระบบดังกล่าวจะพร้อมทำตลาดส่งถึงกลุ่มผู้ใช้งานรอบบุคคลได้จริงในช่วงปลายปี 2026 หรือปี 2027 เป็นต้นไป ปัจจุบันแนวทางทำแผนงานจึงควรวางลำดับงานพากย์เป็นหนึ่งในแผนส่งงานภายหลังปิดกล้องให้เสร็จสมบูรณ์ในวันเดียวกันมากกว่าจะหวังใช้ประยุกต์ทำระบบเวลาจริงในสนามสด
ค. ควรตัดสินใจปรับแปรรหัสภาษาเป้าหมายเพื่อเสนอชิ้นงานกี่แนวภาษาดี?
จากผลสรุปสถิติตลอดอุตสาหกรรมใน รายงาน State of AI Dubbing 2026 พบข้อชัดเจนว่าผู้ผลิตเนื้อหาระดับทั่วไปบนระบบ Perso Dubbing มักเลือกดันงานพากย์ทับเป้าหมายที่ 1 ภาษาหลักก่อน แต่สำหรับกลุ่มครีเอเตอร์ท็อปคลาสระดับบน (Top 1%) จะส่งแปลงต่อยอดออกไปสร้างเฉลี่ยมากถึง 15 ภาษา ช่องว่างความห่างนี้สะท้อนว่ามีครีเอเตอร์และผู้ประกอบการหลายแบรนด์ทิ้งโอกาสการเติบโตและการเข้าถึงฐานลูกค้าตลาดต่างถิ่นไปอย่างน่าเสียดายทั้งๆ ที่เนื้อหากระแสวิดีโอมีภาพรวมทรงประสิทธิภาพที่ตอบโจทย์ความอยากรู้คนนอกถิ่นได้ดี โดยเทคนิควางเป้าหมายระยะเริ่มแรกที่ปลอดภัยควรจับเทรนด์ตลาดใหญ่ที่ 3-5 น่านน้ำภาษาที่ห้อมล้อมผู้ชมกลุ่มนอกของคุณหลักๆ ไว้ก่อนเป็นเกณฑ์ประเมินเบื้องต้น แล้วค่อยคอยสังเกตสถิติจำนวนเวลารับชม (Watch-time) ของภาษาอื่นๆ แล้วนำมาปรับทำเพิ่มขึ้นไปเรื่อยๆ ตามลำดับ
เริ่มต้นใช้งาน
หากต้องการทดลองเข้าใช้บริการตัวอย่างการแปลเสียงพากย์ของวิดีโอที่คุณมีอยู่ วิธีคิดที่ไวและรวดเร็วสูงสุดคือ ทดลองอัปโหลดเนื้อหาและจัดส่งประเมินผลลัพธ์การจัดการแปลข้ามไปสัก 2-3 รหัสภาษาเป้าหมายชั้นนำก่อน ซึ่งผู้ให้บริการสากลส่วนใหญ่จะมีแพ็กเกจระดับทดลองใช้งานฟรี (Free Trial) มอบไว้เพื่อการตรวจสอบและก้าวทดลองของคุณ
สำหรับแพลตฟอร์มแบบครบวงจรที่รวมทุกกระบวนการทำงานไว้ในหนึ่งเดียว ไม่ว่าจะเป็นการสะกดและถอดคำพูด ถอดความหมายตัวประโยค เทคนิคโคลนนิ่งแกะเสียง ตลอดจนการทำวิถีปากขยับให้พอดีประกอบแนวระนาบรูปหน้าประมวลลื่นไหล คุณสามารถเข้าใช้เครื่องมือได้ที่ Perso Dubbing's video translator หรือลองเข้าไปเปิดดูบทเทียบเคียงอื่นๆ เพิ่มได้ที่ the alternatives hub เพื่อประกอบข้อพิจารณาส่วนตัดสินเลือกช้อยส์เครื่องมืออื่นที่ตอบพฤติกรรมคุณ
สถิติประกอบและชุดรายงานหลักอ้างอิงทุกกรณีที่ประดับระบุอยู่ในผลงานบทวิเคราะห์นี้ ทั้งหมดได้รับการเผยแพร่ชุดข้อมูลแบบเปิดจากตัวแชร์ไฟล์ State of AI Dubbing 2026 report ภายใต้ข้อตกลงสร้างสรรค์ร่วมใบอนุญาต Creative Commons Attribution 4.0
คำตอบสั้นๆ: การแปลเสียงพากย์ (Voice over translation) คือขั้นตอนการทำงานที่เริ่มจากเสียงพากย์ที่มีอยู่แล้ว ไม่ว่าจะเป็นเสียงบรรยาย เสียงอธิบาย หรือเสียงวิเคราะห์ที่บันทึกไว้ แล้วสร้างเสียงพากย์เดิมนั้นออกมาในอีกภาษาหนึ่ง การแปลเสียงพากย์ที่ขับเคลื่อนด้วย AI สามารถจัดการสามขั้นตอนหลักได้อย่างอัตโนมัติ ได้แก่ การรู้จำเสียงพูด การแปล และการสังเคราะห์เสียงในภาษาเป้าหมาย และด้วย Perso Dubbing คุณจะสามารถแปลได้มากกว่า 99 ภาษาพร้อมทั้งโคลนเสียงของผู้พูดต้นฉบับเพื่อให้ภาษาใหม่ที่ได้ยินนั้นฟังดูราวกับพูดโดยบุคคลเดียวกัน
การแปลเสียงพากย์คืออะไร?
การแปลเสียงพากย์คือกระบวนการแปลงเสียงพากย์ที่บันทึกไว้จากภาษาหนึ่งไปยังอีกภาษาหนึ่ง โดยข้อมูลขาเข้า (Input) จะเป็นไฟล์เสียง ซึ่งบางครั้งอาจรวมมากับไฟล์วิดีโอหรือเป็นไฟล์เสียงเดี่ยวๆ และข้อมูลขาออก (Output) ที่ได้จะเป็นไฟล์เสียงในอีกภาษาที่พร้อมใช้งานจริง
วงการนี้มีอายุเก่าแก่กว่าเทคโนโลยี AI โดยเหล่าสตูดิโอต่างทำกันมาด้วยตัวเองนานหลายทศวรรษ ไม่ว่าจะเป็นการจ้างนักพากย์ในภาษาเป้าหมาย ส่งสคริปต์ที่แปลแล้วให้ บันทึกเสียง แล้วนำกลับมารวมเข้ากับวิดีโอ ซึ่งอุปสรรคสำคัญก็คือต้นทุนและเวลาในอดีต วิดีโออธิบายความยาว 5 นาทีในสามภาษานั้นหมายถึงการที่ต้องเข้าสตูดิโอสามครั้ง มีนักพากย์สามคน และใช้ระยะเวลาทำงานนับสัปดาห์
AI เข้ามาเปลี่ยนรูปแบบการทำงานนี้โดยที่จุดประสงค์ปลายทางยังคงเดิม ผลลัพธ์สุดท้ายยังคงเป็นเสียงพากย์ประโยคเดิมในอีกภาษา แต่เส้นทางที่จะทำให้ได้ผลลัพธ์นั้นในปัจจุบันใช้เวลาเพียงไม่กี่นาทีแทนที่จะเป็นสัปดาห์
รูปแบบของงานพากย์เสียงที่จัดอยู่ในการแปลเสียงพากย์มีสามประเภทใหญ่ๆ ได้แก่:
ประเภทแรกคือ เสียงบรรยายเฉพาะท้องถิ่น (localized narration) เช่น วิดีโออธิบาย, คอร์สเรียนออนไลน์, เสียงบรรยายสารคดี, บทหนังสือเสียง โดยต้นฉบับจะเป็นเสียงคนคนเดียวดำเนินเรื่องไปตลอดการผลิต เสียงที่แปลแล้วจะยังคงใช้เสียงต้นแบบเดิมหรือใช้เสียงเทียบเคียงกันในภาษาเป้าหมายแทน
ประเภทที่สองคือ การพากย์เสียงบทสนทนา (dialogue dubbing) เช่น ภาพยนตร์, ละคร, คอนเทนต์สัมภาษณ์ที่มีผู้พูดหลายรายและจำเป็นต้องแปลแยกรายคน การแปลเสียงพากย์ถือเป็นเครื่องมือหลักของกระบวนการนี้ แม้ว่าในอุตสาหกรรมจะหันไปเรียกว่า "การพากย์เสียง (dubbing)" เมื่อเริ่มเข้าข่ายการทำงานกับผู้พูดหลายคนก็ตาม
ประเภทที่สามคือ เสียงส่วนติดต่อผู้ใช้ (interface audio) เช่น เมนูเสียงตอบรับอัตโนมัติ (IVR), เสียงแนะนำการใช้งานแอปพลิเคชัน, เสียงบรรยายในตัวผลิตภัณฑ์ ซึ่งมีขอบเขตการทำงานที่เล็กกว่า แต่ก็ยังรันอยู่บนระบบการแปลและการสังเคราะห์เสียงแบบเดียวกัน
ส่วนที่เหลือของคู่มือนี้จะเน้นไปที่สองประเภทแรก เนื่องจากประเภทที่สามนั้นจะใช้รูปแบบการทำงานที่เหมือนกันแต่มีขนาดที่เล็กกว่า
การแปลเสียงพากย์กับการพากย์เสียง แตกต่างกันอย่างไร หรือเหมือนกัน?
โดยส่วนใหญ่แล้วเหมือนกัน ความแตกต่างที่มีนั้นมีมาตั้งแต่ก่อนยุคของการทำงานด้วย AI และไม่มีการแบ่งแยกที่ชัดเจน
การใช้งานในอุตสาหกรรม:
การแปลเสียงพากย์ (Voice over translation) มักจะหมายถึงคอนเทนต์ในลักษณะการบรรยาย มีผู้พูดคนเดียว เช่น สารคดี วิดีโออธิบาย หนังสือเสียง โดยเสียงบรรยายจะวางซ้อนอยู่บนวิดีโอมากกว่าการพากย์แบบจับคู่ตรงกับช่องปากของผู้พูด
การพากย์เสียง (Dubbing) มักจะหมายถึงบทสนทนา มีผู้พูดหลายคน และให้ความสำคัญกับการขยับปากให้ตรงกับเสียง (Lip-sync) โดยภาพยนตร์และละครมักจะคุ้นเคยกับคำนี้
ในภาคปฏิบัติ เส้นแบ่งนี้ค่อนข้างคาบเกี่ยวกัน ยกตัวอย่างเช่น ครีเอเตอร์ที่บรรยายวิดีโอบน YouTube และต้องการแปลงวิดีโอนั้นเป็นภาษาสเปน สิ่งนี้คือการแปลเสียงพากย์หรือการพากย์เสียงกันแน่? คำตอบคือใช้ได้ทั้งสองคำ เนื่องจากขั้นตอนการทำงานนั้นเหมือนกันทุกประการ นั่นคือ รับเสียงเข้ามา → แปลภาษา → ส่งเสียงออกไป → นำเสียงกลับไปประกบเข้ากับวิดีโอ
หากต้องการกฎเกณฑ์ที่เข้าใจง่ายๆ ให้มองว่าการแปลเสียงพากย์คือหมวดหมู่ที่กว้างกว่า ส่วนการพากย์เสียง (dubbing) คือกรณีที่ความแม่นยำในการขยับปากของเสียงใหม่เป็นแกนหลักสำคัญของผลงาน ซึ่งทั้งสองส่วนจะรันอยู่บนโครงข่าย AI รูปแบบเดียวกัน โดย โครงสร้างต้นแบบสื่อ AI แบบ 4 ชั้น (4-Layer Model of AI media) จะจัดส่วนนี้ให้อยู่ในชั้นที่ 4 หรือชั้นของการเผยแพร่ (distribution layer) ไม่ว่าคุณจะเลือกใช้คำเรียกใดในอุตสาหกรรมก็ตาม
ส่วนที่เหลือของคู่มือนี้จะใช้คำว่า "การแปลเสียงพากย์ (voice over translation)" เป็นคำครอบคลุมหลัก หากในกรณีที่การขยับปากมีความสำคัญเป็นพิเศษ ทางเราจะระบุเจาะจงลงไป
การทำงานของการแปลเสียงพากย์ที่ขับเคลื่อนด้วย AI
กระบวนการทำงานมี 4 ขั้นตอน ซึ่งเนื้อหาทั่วไปมักจะใช้เวลาดำเนินการเสร็จสิ้นในระดับไม่กี่วินาทีหรือนาทีเท่านั้น
สี่ขั้นตอน เริ่มต้นจากสัญญาณเสียงขาเข้า สิ้นสุดที่สัญญาณเสียงขาออก ใช้เวลา 1-3 นาทีสำหรับการแปลงวิดีโอต้นฉบับทุกๆ 1 นาที
ขั้นตอนที่ 1 — การรู้จำเสียงพูด ตัวระบบจะถอดเสียงจากวิดีโอต้นฉบับออกมาเป็นข้อความตัวอักษร ระบบการรู้จำเสียงพูดในปัจจุบันสามารถจัดการกับเรื่องสำเนียง เสียงดนตรีประกอบ ผู้พูดหลายราย และรูปแบบเสียงตามธรรมชาติ (อาทิ คำเติมเสียง การเว้นจังหวะ การเริ่มประโยคใหม่) ได้เป็นอย่างดี ผลของการถอดเสียงนี้จะเป็นฐานข้อมูลสำคัญในขั้นตอนต่อไป ดังนั้น เรื่องความแม่นยำจึงสำคัญอย่างที่หลายคนไม่คาดคิด หากการถอดความแย่ ผลการแปลก็จะแย่ตาม ส่งผลให้เสียงพากย์ปลายทางแย่ไปด้วย
ขั้นตอนที่ 2 — การแปลภาษา ข้อความที่ถอดเสียงมาจะถูกส่งเข้าไปแปลผ่านระบบโครงข่ายประสาท (neural translation) ที่ปรับจูนมาสำหรับภาษาพูดโดยเฉพาะแทนที่จะเป็นภาษาเขียน ภาษาพูดมักจะสั้นกว่า มีความเป็นสำนวน มีการอิงตามบริบทมากกว่าภาษาเขียน ดังนั้น โมเดลการแปลที่ตอบโจทย์งานเอกสารได้เป็นอย่างดีอาจแปลเสียงพูดออกมาได้แย่ และในทางกลับกันก็เช่นกัน โดยผลลัพธ์ที่ได้จะเป็นบทแปลในภาษาเป้าหมายที่มีการตั้งจังหวะเวลาเพื่อจับคู่กับจังหวะของต้นฉบับให้ใกล้เคียงที่สุด
ขั้นตอนที่ 3 — การสังเคราะห์เสียง สคริปต์ที่ได้รับการแปลแล้วจะถูกสังเคราะห์ออกมาเป็นคำพูดจริง โดยมีทางเลือกหลักๆ อยู่สองแนวทาง
แนวทางแรกคือ เสียงสำเร็จรูป (stock voices) ซึ่งทำได้โดยการเลือกเสียงจากคลังที่มีมาให้เพื่อนำมาใช้งาน วิธีนี้ทำได้รวดเร็วและไม่มีเรื่องกังวลด้านลิขสิทธิ์ แต่เสียงใหม่ที่ได้นั้นจะไม่มีจุดที่เหมือนกับเสียงของคนพูดเดิมเลย
แนวทางที่สองคือ การโคลนเสียง (voice cloning) จะเป็นการฝึกสอนโมเดลระบบด้วยเสียงของคนพูดต้นฉบับ แล้วสังเคราะห์คำพูดในภาษาเป้าหมายให้ออกมาภายใต้เสียงเดียวกัน ซึ่งผลลัพธ์ที่ได้จะฟังดูราวกับคนเดิมกำลังพูดคุยในภาษาใหม่ และนี่คือสิ่งที่เหล่านักทำงานแปลเสียงพากย์ระดับมืออาชีพต้องการ
ขั้นตอนที่ 4 — การปรับแต่งภาพการขยับปากให้ตรงกัน (กรณีที่เป็นวิดีโอ) หากเนื้อหาขาเข้าเป็นวิดีโอ เสียงสังเคราะห์ใหม่จะถูกนำไปปรับให้สอดคล้องตรงกับการเคลื่อนไหวปากต้นฉบับ ปัจจุบันระบบทั่วไปสร้างความแม่นยำได้สูงราว 98% สำหรับเนื้อหามาตรฐาน หากไม่มีขั้นตอนนี้ เสียงพากย์ใหม่จะเล่นประกอบไปกับภาพการขยับปากตามจังหวะเวลาของภาษาเดิม ซึ่งผู้รับชมส่วนใหญ่จะรู้สึกอึดอัดขัดตาในเวลาเพียงไม่กี่วินาที
Perso Dubbing รันระบบการทำงานทั้งหมดนี้เป็นขั้นตอนเดียว เพียงอัปโหลดวิดีโอ เลือกภาษาปลายทาง แล้วรับวิดีโอที่ทำงานสำเร็จกลับไป โดยระยะเวลาในการประมวลผลทั้งหมดจะอยู่ที่ประเด็น 1 ถึง 3 นาที ต่อความยาววิดีโอต้นทาง 1 นาที เช่น วิดีโอความยาว 5 นาที จะใช้เวลาแปลประมาณ 5 ถึง 15 นาที
ควรใช้การแปลเสียงพากย์เมื่อใด
การตัดสินใจมักไม่ใช่แค่คำว่า "ฉันจำเป็นต้องแปลเลยดีไหม" เพราะข้อนั้นดูมีความชัดเจนอยู่แล้วตามความคุ้มค่าทางเศรษฐกิจ แต่คำถามสำคัญคือคุณควรพิจารณาเลือกรูปแบบการแปลในลักษณะใด
การแปลเสียงพากย์จะเหมาะสมเป็นอย่างยิ่งเมื่อ:
เนื้อหานั้นเป็นวิดีโอและกลุ่มผู้ชมชอบรับชมข้อมูลรูปแบบวิดีโอ คำบรรยายอาจใช้ได้จริงสำหรับคนบางกลุ่ม แต่ในแง่ของข้อมูลเวลาการรับชม (watch-time data) แสดงให้เห็นอย่างเด่นชัดว่า กลุ่มผู้ชมที่ไม่ใช่เจ้าของภาษาจะชอบรับชมวิดีโอที่มีการพากย์เสียงมากกว่าวิดีโอที่มีแค่คำบรรยาย รายงาน State of AI Dubbing 2026 เผยว่า 96% ของวิดีโอที่พากย์เสียงด้วย AI มักถูกแชร์ออกไปในวันเดียวกันกับที่มีการผลิตทันที ซึ่งนี่คือหนึ่งในพฤติกรรมบ่งชี้สำหรับคอนเทนต์ที่สร้างขึ้นเพื่อหวังผลด้านการกระจายข้อมูล ไม่ใช่สร้างมาเพื่อจัดเก็บไว้เฉยๆ
คุณมุ่งเน้นความเป็นแบรนด์และเสียงที่มีอยู่เดิม เสียงของครีเอเตอร์ย่อมเป็นหนึ่งในเอกลักษณ์ของแบรนด์ เช่นเดียวกับผู้บรรยายประจำแบรนด์ที่เป็นส่วนหนึ่งของแบรนด์เช่นกัน การแปลเสียงพากย์ด้วยการโคลนเสียงจะช่วยรักษาภาพจำและเอกลักษณ์เหล่านั้นเอาไว้ได้อย่างสมบูรณ์ในทุกภาษาที่แปลไป โดยการใช้คำบรรยายใต้ภาพจะตัดองค์ประกอบนี้ทิ้งไป
กลุ่มเป้าหมายของคุณใช้สมาร์ตโฟนเป็นหลักหรือรับชมแบบผ่านๆ คอนเทนต์ที่มีแค่ซับไตเติลจะดึงความสนใจของผู้รับชมให้อยู่กับหน้าจอตลอดเวลา แต่การแปลเสียงพากย์จะช่วยให้ผู้ฟังสามารถรับฟังไปได้ในขณะขับรถ ทำอาหาร หรือทำงานอยู่ได้ ซึ่งจะสอดรับเป้าหมายกับตลาดกลุ่มโมบายล์เฟิร์ส (อย่างอินเดีย เอเชียตะวันออกเฉียงใต้ ลาตินอเมริกา) ที่เลือกเสพคอนเทนต์พากย์เสียงด้วยเหตุผลดังกล่าว
คุณกำลังเผยแพร่เนื้อหาไปยังหลายตลาดพร้อมกัน การผลิตคำบรรยายมักจะมีอัตราการทำที่เพิ่มสัดส่วนไปตามปริมาณงานแปล (Linear scale) ขยับเพิ่มหนึ่งภาษาก็หมายถึงขั้นตอนการตั้งเวลา จัดรูปแบบ อัดซับไตเติลใหม่อีกยกหนึ่ง แต่การแปลเสียงพากย์นั้นจะใช้อัตราการขยายงานต่ำกว่าสัดส่วนความยาก (Sub-linear scale) เพราะเมื่อวางระบบการส่งทำงานเอาไว้เรียบร้อยแล้ว การเพิ่มภาษาที่ 6 หรือ 7 จะใช้เวลาประมวลผลเพิ่มขึ้นอีกเพียงไม่กี่นาทีเท่านั้นแทนที่จะเป็นเวลาในการปรับแต่งแก้ไขไฟล์โดยบรรณาธิการงานวิดีโอหลายๆ วัน
การแปลเสียงพากย์จะมีความจำเป็นน้อยลงเมื่อ:
กลุ่มเป้าหมายเหมาะสมกับคำบรรยายมากกว่า ตัวอย่างคลาสสิกคือผู้ชมภาพยนตร์ต่างประเทศในประเทศญี่ปุ่น โดยผู้ชมบางกลุ่มจะให้ความสำคัญกับเรื่องการชมพร้อมซับไตเติลก่อนเสมอไม่ว่าจะมีต้นทุนพากย์เสียงเปรียบเทียบเท่าใด ดังนั้นควรทดสอบก่อนที่จะสรุปแนวความคิด
ความยาววิดีโอสั้นจนทำให้การเตรียมซับไตเติลเป็นเรื่องง่าย เช่น คลิปโซเชียลความยาว 60 วินาที อาจไม่คุ้มค่าพอที่จะนำไปใช้ทำเสียงพากย์ใหม่
องค์ประกอบเสียงพากย์ตัวเดิมคือหัวใจหลักของชิ้นงานนั้น เช่น เสียงนักบรรยายที่มีความเป็นเอกลักษณ์เฉพาะตัว, เทคนิคการนำเสนอของตัวนักแสดงโดยเฉพาะ, หรือเทปบันทึกการแสดงสดที่เสียงจริงในสนามเป็นเสน่ห์หลัก การแปลเป็นภาษาอื่นอาจทำลายองค์ประกอบสุนทรียภาพที่ควรได้สัมผัสไป ซึ่งในกรณีทำนองนี้ การใช้ซับไตเติลจึงสามารถแสดงรักษาคุณลักษณะเดิมเอาไว้ได้ดีที่สุด
การแปลเสียงพากย์เปรียบเทียบกับการใช้ซับไตเติล — การเลือกรูปแบบที่เหมาะสม
คำบรรยาย (Subtitles) และการแปลเสียงพากย์ตอบจุดประสงค์เชิงธุรกิจเดียวกัน นั่นคือ “จะเข้าถึงกลุ่มผู้ใช้ที่พูดต่างภาษากันอย่างไร” แต่จะส่งมอบประสบการณ์ด้านมุมมองการรับชมข้อมูลภาพให้แก่ผู้รับรับชมแตกต่างกันออกไป
การเปรียบเทียบซับไตเติลกับการแปลเสียงพากย์ — ข้อเด่นจุดแข็งในแต่ละรูปแบบ
มิติการทำงาน | คำบรรยาย (ซับไตเติล) | การแปลเสียงพากย์ |
|---|---|---|
ต้นทุนต่อหนึ่งภาษา | ต่ำ (แปรผันตามเวลาทำงานของผู้ตรวจทาน) | ปานกลาง (ค่าบริการส่งงานประมวลผลระบบ + ลิขสิทธิ์เสียงโคลน) |
ระยะเวลาจัดทำต่อหนึ่งภาษา | หลายชั่วโมง | ระดับนาที (ด้วยการทำงานของ AI) |
มติการรับชมงาน | ต้องคอยเพ่งกวาดสายตาเพื่ออ่าน | รับฟังในภาษาท้องถิ่นของตนเอง |
การตอบรับกับสมาร์ตโฟน / งานผ่านๆ | มีข้อจำกัด | ทำงานได้ครบกระบวนการดี |
คงจุดเอกลักษณ์แบรนด์ | ใช่ (คงลักษณะเสียงต้นฉบับไว้ได้ครบถ้วน) | ใช่ (ตอบโจทย์ได้เมื่อใช้บริการโคลนเสียง) |
ความพร้อมใช้งานสำหรับกลุ่มคนหูหนวก / มีปัญหาการได้ยิน | ✅ มีความจำเป็นสูงสุด | ต้องใช้การเตรียมแยกไฟล์ต่างหาก |
เหมาะที่สุดสำหรับ | คลิปขนาดสั้น, กลุ่มเป้าหมายเฉพาะกลุ่ม | วิดีโอแบบเต็มขนาด สเกลงานจำนวนมาก |
ในความเป็นจริง ลำดับการประมวลผลงานภาพสื่อในปัจจุบันส่วนใหญ่มักจะเตรียมควบคู่กันทั้งคู่ กล่าวคือ ใช้การแปลเสียงพากย์เป็นหลัก และมีตัวเลือกรองรับซับไตเติลเพื่อตอบโจทย์ผู้รับชมทุกกลุ่ม โดยแพลตฟอร์มพากย์เสียงด้วย AI ในปัจจุบันมักนำพาชุดการดาวน์โหลดทั้งสองรูปแบบนี้จาก Flow เดียวกัน เนื่องจากผลพวงของการถอดระดับคำแปลได้ถูกจัดเรียงในขั้นตอนที่ 1 และ 2 ไว้อยู่แล้ว
วิธีการแปลเสียงพากย์ด้วย AI (ทีละขั้นตอน)
ข้อมูลลำดับขั้นตอนถัดจากนี้สอดคล้องกับการใช้งานจริงบน Perso Dubbing โดยหน้าจอการจัดการแอปในแบรนด์อื่นๆ อาจแตกต่างออกไป แต่จะอิงกรอบระเบียบตรรกะแบบเดียวกัน
1. อัปโหลดไฟล์วิดีโอหรือเสียงต้นฉบับ โยนไฟล์งานของคุณเข้าระบบ โดยส่วนใหญ่แล้วจะรองรับนามสกุลไฟล์ MP4, MOV, MP3, WAV และหากชิ้นงานอยู่บน YouTube ก็เพียงนำลิงก์ปลายทางมาวางได้ทันที
2. เลือกภาษาเป้าหมายที่ต้องการรับแปลง สามารถระบุได้หนึ่งหรือหลากหลายภาษาพร้อมๆ กัน ซึ่ง Perso Dubbing รองรับหลากหลายรหัสภาษากว่า 99 ภาษา ทั้งภาษาต้นฉบับและภาษาปลายทาง ตัวอย่างรหัสภาษายอดนิยมที่เลือกใช้บ่อย เช่น ภาษาสเปน ภาษาโปรตุเกส ภาษาฝรั่งเศส ภาษาเยอรมัน ภาษาญี่ปุ่น และภาษาเกาหลี
3. ตรวจเช็คข้อมูลผลการคลิกถอดคำแปลอัตโนมัติ ระบบจะแสดงชุดข้อความที่ถอดออกมาจากไฟล์ภาษาต้นฉบับ ให้ทำการปรับแก้ไขในส่วนที่ระบบตรวจจำเสียงวิเคราะห์ผิดพลาดก่อนที่จะส่งต่อไปยังสเต็ปแปลภาษา การแก้ไขตั้งแต่เนิ่นๆ ในจุดนี้จะลดทอนปัญหาความผิดพลาดซ้อนทับลงได้เป็นอย่างดี
4. เรียบเรียงและปรับพฤติกรรมการแปล (ตัวเลือกเพิ่มเติม) ตรวจเช็ครูปแบบประโยคที่แปลออกมาก่อนก้าวเข้าสู่ขั้นตอนการประมวลผลเสียงพูด สังเกตในเนื้อหาข้อความที่เป็นศัพท์เฉพาะทาง วิธีคำเรียกชื่อแบรนด์ เพื่อลบประเด็นความผิดพลาดซึ่งการมาตามไล่แก้ภายหลังจะทำได้ยากเป็นอย่างยิ่ง
5. ทำการประมวลผล (Generate) ตัวกระบวนการสังเคราะห์เสียงและการจับคำแปลงช่องปากปากให้ตรงจังหวะจะเริ่มต้นขึ้น โดยรวมแล้วจะกินระยะเวลาประมาณ 1 ถึง 3 นาที สำหรับความยาววิดีโอไฟล์ 1 นาที (เช่น วิดีโอ 5 นาที จะให้ผลแล้วเสร็จอยู่ในช่วงเวลา 5 ถึง 15 นาที)
6. ทำการดาวน์โหลดหรือแชร์ข้อมูล ผลปลายทางที่ได้รับจะพร้อมทำงานในรูปแบบไฟล์สกุล MP4 ที่แยกตามภาษาที่กำหนด ไปจนถึงไฟล์ซับไตเติลนามสกุล .srt เพื่อช่วยเสริมคุณลักษณะการเข้าชมที่ดีขึ้น แพลตฟอร์มบางตัวมีชุดดาวน์โหลดเสียงสกุล MP3 มาให้เพิ่มเติมในกรณีสำหรับผู้ที่ต้องการแต่องค์ประกอบเนื้อหาเสียงเท่านั้น
ขั้นตอนทำงานทั้งหมดรันอยู่เบนแพลตฟอร์มเดียวจนเสร็จสิ้น รายงาน State of AI Dubbing 2026 ชี้ให้เห็นถึงข้อมูลผลทดสอบที่มีการแชร์ออกไปในวันจัดส่งงานสูงถึง 96% เกิดจากการออกแบบระบบวงงานเดี่ยวในลักษณะนี้ ไม่ใช่เป็นการโยนส่งต่อไฟล์สลับไปมาระหว่างโปรแกรมแต่อย่างใด
คุณภาพผลงานแปลเสียงพากย์ — สิ่งที่คุณควรพิจารณาและตรวจสอบ
คุณภาพการออกแบบเสียงมี 3 องค์ประกอบหลักๆ และทุกส่วนสำคัญเท่าเทียมกันหมด จุดด้อยที่สุดใน 3 ข้อนี้จะกำหนดทัศนคติในผลงานทั้งหมดที่ผู้ชมประเมินทันที
สามองค์ประกอบสำคัญ ซึ่งจุดที่มีคุณภาพแย่ที่สุดจะเป็นเกณฑ์ตัดสินคุณภาพผลงานชิ้นนั้นๆ
ความสมบูรณ์ของความหมายเสียง ข้อความเสียงพากย์ปลายทางสื่อข้อความได้ถูกต้องตรงกับแนวคิดต้นฉบับพูดยืนหยัดอยู่หรือไม่? การแปลที่ผิดเพี้ยนไปจากชื่อแบรนด์ ศัพท์เฉพาะเชิงความรู้ หรือประโยคแวดล้อมวงการ เป็นส่วนจุดผิดพลาดหลักๆ ที่มักเกิดขึ้น แนวทางบรรเทาปัญหาก็คือตรวจดูชุดคำแปลสคริปต์ให้สมบูรณ์ก่อนก้าวย่างไปสู่ขั้นตอนการสังเคราะห์เสียงทำงาน
ความลื่นไหลเป็นธรรมชาติของเสียงพากย์ น้ำเสียงที่รับเข้าฟังดูมีความนุ่มนวลอย่างที่มนุษย์ใช้โต้ตอบสนทนา หรือเป็นน้ำเสียงทื่อๆ คล้ายหุ่นยนต์อ่านคู่มือเอกสาร? ระบบเสียง AI ปัจจุบันสามารถลบช่องว่างความไม่เป็นธรรมชาติเหล่านั้นทิ้งไปได้เกือบหมดสิ้น แต่จุดสังเกตยังมีอยู่บ้าง เช่น วรรณยุกต์ สูง-ต่ำ จังหวะความเร็ว หรือการเว้นช่วงการหายใจในจังหวะตัวประโยคอย่างเป็นปกติ การใช้ตัวเลือกโคลนเสียงพากย์ของโคลนเสียงดั้งเดิมจะมอบท่วงทำนองเสียงและจังหวะเวลาในการเอ่ยประโยคตามพฤติกรรมเจ้าของเดิมได้ดีกว่าเสียงในคลังทั่วไป
ความเนียนกริบของช่องปาก (สำหรับวิดีโอ) อัตราการเคลื่อนไหวริมฝีปากประสานรับกับเสียงใหม่ที่สังเคราะห์ไปได้ดีหรือไม่? Perso Dubbing มีความภูมิใจในตัวเลขเฉลี่ยความสำเร็จของการทำงานปรับปากตรง 98.5% ของขั้นตอนทั้งหมด ซึ่งถือเป็นหนึ่งในสถิติที่เปิดเผยต่อสาธารณะสูงสุด สำหรับจุดความไม่เข้ากันที่เหลือราว 1.5% มักจะสังเกตเห็นได้ง่ายเฉพาะในซีนที่เป็นการโคลสอัพที่ดวงหน้ากล้องตรงๆ เท่านั้น สำหรับฉากมุมกว้างหรืออยู่ไกลระดับความไวของสายตาต่อการจับขยับรอบปากจะลดลงเนื่องจากขนาดกรอบสัดส่วนรอบมุมปากที่เล็กลงในหน้าจอ
เคล็ดลับขั้นตอนการวัดคุณภาพฉบับง่าย: ลองส่งชิ้นงานตรวจสอบคุณภาพที่สำเร็จให้เจ้าของภาษาจริงเป็นผู้รับฟังแล้วสอบถามดูว่าฟังแล้วรู้สึกเป็นธรรมชาติดีไหม คำตอบมีเพียงใช่หรือไม่ใช่เท่านั้น หากพวกเขารู้สึกแปลกๆ แม้จะเพียงเล็กน้อยก็ถือว่ายังไม่ได้คุณภาพ
กลุ่มภาษาที่เป็นที่นิยมในการนำมาแปลเสียงพากย์
ความต้องการปริมาณงานไม่ได้กระจายตัวเป็นปริมาณที่เท่ากัน ภาพรวมข้อมูลของสถิติบนระบบ Perso Dubbing จากการรวบรวมโปรเจกต์งานพากย์ทับ 316,856 ชิ้นงาน และการส่งงานของกลุ่มผู้ผลิตมืออาชีพ 4,023 ราย แสดงให้เห็นถึงแนวภาษาเป้าหมายยอดหลักๆ ที่มีสถิติก้าวเดินไปสู่สายตาตลาดโลกได้ชัดเจนที่สุด
ภาษาเป้าหมายยอดนิยมจากสถิติจริงของโครงการแปลเสียงพากย์ 112,797 โปรเจกต์ แหล่งอ้างอิงข้อมูล: State of AI Dubbing 2026
ภาษาอังกฤษ ครองส่วนสัดสำคัญสูงสุดในฐานะภาษาปลายทางเป้าหมาย (ด้วยสถิติตลอดโปรเจกต์กลุ่มคำแปลถึง 28,050 ชิ้นงาน) แต่ก็มีภาพงานกระจายตัวกว้างที่สุด โดยไม่มีอุตสาหกรรมในสายงานใดครองตัวเลขเกิน 14% เลย ภาษาอังกฤษเป็นภาษาปลายทางหลักสำหรับกลุ่มการแปลงเพื่อส่งสารขยายงานออกไปของครีเอเตอร์ที่ไม่ใช่เจ้าของภาษาอังกฤษ
ภาษาโปรตุเกส (13,135 ชิ้นงาน) ค่อนข้างเด่นในการประดับสัดส่วนกลุ่มเป้าหมายเชิงหลากหลายด้าน ทั้ง อนิเมชัน ประเด็นความเชื่อ ศาสนา และงานเรียน คอร์สฝึกการเรียน มีสัดส่วนร่วมแตะระดับ 10% ทั้งหมด โดยถ้าเจาะสำนวนไปที่ภาษาโปรตุเกสบราซิล จะทวีสัดส่วนสูงสุดเป็นอันดับสองของการแปลประเด็นหลักบทความเชิงความเชื่อศาสนาร่วมกับสายภาษาอังกฤษ โดยรายงาน State of AI Dubbing 2026 พบตัวเลขเทียบเคียงร่วมกันที่ ภาษาอังกฤษ 25.6% / ภาษาโปรตุเกส 25.2% ภายในกลุ่มโปรเจกต์ศาสนาดังกล่าว ซึ่งสถิตินี้ทำให้หลายๆ ฝ่ายรู้สึกแปลกใจหลังจากที่คาดกันมาก่อนหน้านี้ว่า ภาษาสเปน ควรเป็นตัวเลือกหลักของภูมิภาคละตินอเมริกา
ภาษาสเปน (10,730 ชิ้นงาน) จะเป็นภาษาหลักที่ขึ้นนำอย่างสูงมากในส่วนหมวดหมู่ระบบการเรียนการสอนและข่ายศาสนา ทั่วภูมิภาคลาตินอเมริกา
ภาษาเกาหลี (4,822 ชิ้นงาน) นำเสนอสถิติน่าประทับใจเป็นพิเศษ โดย 30% ของปริมาณงานที่แปลงไปเป็นภาษาเกาหลีมีจุดหมายปลายทางที่กระบวนการเนื้อหาเชิงแวดวงแชร์ความรู้ (เมื่อนับส่วนวิทยาศาสตร์ เทคโนโลยี ประสานเข้ากับหมวดวิชาการศึกษา) สถิติชุดนี้เป็นผลพวงเกาะกลุ่มของทิศทาง K-Content ที่ตลบเข้าหากลุ่มงานแวดวงอื่นๆ ยิ่งกว่าฝั่งบันเทิงเพียงหมวดเดียว
ภาษาญี่ปุ่น (3,367 ชิ้นงาน) ถ่ายทอดความต้องการเชิงการสร้างเนื้อหาระบบทางการแพทย์ขั้นรุนแรงพอดูเมื่อเปรียบเทียบในแง่อัตราร่วมกับสถิติกลุ่มอื่น งานชุดคู่มือสาธิตรักษาและสร้างความเข้าใจแด่คนไข้จะมีสัดส่วนเฉลี่ยการทำภาษาญี่ปุ่นมากเป็นพิเศษ
ภาษาฝรั่งเศส (6,482 ชิ้นงาน) มักขับเคลื่อนผ่านกลุ่มชิ้นงานประเภทนำเสนอวิดีโอสารคดีเป็นสำคัญ ซึ่งเชื่อมสัมพันธภาพกับวัฒนธรรมด้านภาพและขั้นตอนการสนับสนุนแนวจัดแต่งงานสารคดีของประเทศฝรั่งเศสตามประวัติการผลิตอย่างแกร่งกล้า
ดังนั้น สำหรับผู้ผลิตงานเริ่มต้นกระบวนการแปลใหม่ๆ ระบบการพิจารณารหัสภาษามาตรฐานลำดับต้นๆ เพื่อหวังขยายโอกาสเข้าหาผู้คนวงกว้าง สามารถพิจารณาพาสเต็ปเลือกการทำงานดังนี้: ภาษาสเปน → ภาษาโปรตุเกส → ภาษาฝรั่งเศส → ภาษาเยอรมัน และหากต้องการเน้นเป้าหมายระดับกลุ่มอุตสาหกรรมเฉพาะขีดภูมิภาค ก็ต่อยอดด้วยการวางระบบรองรับ: ภาษาญี่ปุ่น → ภาษาเกาหลี → ภาษาฮินดี → ภาษาอาหรับ เพิ่มเติม
เปรียบเทียบต้นทุนราคาระหว่าง — AI และเสียงนักพากย์จริง
ความคุ้มค่าที่ต่างกันสุดขั้วในตัวงานแบบโมเดล AI เมื่อเทียบการส่งทำงานพากย์ทับด้วยแรงคน นับเป็นจุดปฏิรูปความคุ้มค่ากระโดดตัวสูงสุดที่อุตสาหกรรมประเภทนี้เคยมีมา
ต้นทุนราคาต่องานวิดีโอที่เสร็จสมบูรณ์ต่อหนึ่งนาทีของประเภทวิถีทำ ค่าพากย์ด้วย AI มีแนวราคาที่ถูกคุ้มทุนกว่าการเข้าตู้พากย์จริงด้วยสุนทรียภาพเสียงระดับสตูดิโอราว 100 เท่า
แนวทางวิธีการผลิต | แนวราคาพิจารณาทั่วไป | ระยะเวลาจัดทำ | เพดานคุณภาพ |
|---|---|---|---|
ใช้นักพากย์ + เข้าห้องบันทึกเสียงสตูดิโอ | $200–$500 ต่อนาทีชิ้นงานที่เสร็จสมบูรณ์ | 1–3 สัปดาห์ ต่อกลุ่มภาษาเป้าหมาย | สูงสุดเหนือกฎเกณฑ์ประเมิน |
ใช้นักพากย์ส่งเสียงบันทึก (จัดทำจากระยะไกล) | $80–$200 ต่อนาทีชิ้นงานที่เสร็จสมบูรณ์ | 3–7 วัน ต่อกลุ่มภาษาเป้าหมาย | ระดับสูง |
การทำงานแปลเสียงพากย์ด้วยเครื่องมือ AI | $0.30–$1.50 ต่อนาทีชิ้นงานที่เสร็จสมบูรณ์ | ระดับเป็นนาที | ให้ผลไล่จี้และใกล้เคียงกับมาตรฐานนักพากย์ส่งงานในเกือบทุกจุดพิจารณา |
ชุดใช้ฟรี / ชุดบริการแอปที่จำกัดเงื่อนไข | $0 ฟรีภายใต้เงื่อนไขกำหนด | ระดับเป็นนาที | คุณภาพไม่แน่นอน มักเห็นจุดเพี้ยนได้บ่อยครั้ง |
ตัวเลขข้างต้นเป็นเพียงข้อมูลภาพรวมสำหรับประกอบความเข้าใจ — เนื่องจากแนวราคาจริงของงานจะแปรผันตามคู่คำแปล ข้อตกลงเสริมการเลือกใช้ระบบโคลนนิ่งเสียงและเงื่อนไขแพลตฟอร์มปลายทาง สำหรับสัดส่วนคิดค่าใช้จ่ายของทาง Perso Dubbing จะประเมินจากเวลาจริงของการเกิดไฟล์เสียงพากย์ใหม่เป็นหลัก (Per-second billing) ดังนั้นหากวิดีโอคุณสั้นระดับ 30 วินาที ระบบจะคิดราคาสินค้าอิงที่ระยะ 30 วินาที เท่านั้น โดยไม่ทำการปัดค่าขึ้นไปสู่ 1 นาที แบบที่แพลตฟอร์มรายอื่นบ่อยครั้งมักคิดประเมินงาน
ข้อได้เปรียบเชิงต้นทุนนี้จะทวีความสำคัญชัดเจนขึ้นไปอีกเมื่อเผชิญกลุ่มโปรเจกต์ประเภทต้องการสเกลหลากหลายสีสันภาษา เมื่อก้าวเทียบงานจาก 1 ภาษาขยายไปสู่ 10 ภาษา หากเป็นแนวคิดใช้คนพากย์ แปลว่ามูลค่าจ่ายจะทวีคูณคูณ 10 ทันที แต่บนกลไกเครื่องแปลผ่าน AI ตัวเลขประเมินราคาจะขึ้นไปเพียงเล็กน้อย (เนื่องจากทุกภาษาที่ขยายจะบวกส่วนโครงสร้างงานประมวลผลเพิ่มขึ้น แต่สัดส่วนแกนการจัดการจะนิ่งคงราคาเท่าเดิม) นี่คือสิ่งที่ รายงาน State of AI Dubbing 2026 เรียกว่า "ทางลาดขยายภาษา (Language onramp)" ครีเอเตอร์ส่วนใหญ่มักปิดโอกาสหยุดการนำเสนอภาษาปลายทางที่เป้าหมายภาษาเดียวเพราะเงื่อนไขค่าลิขสิทธิ์สตูดิโอที่โหดร้าย แต่เมื่อนำข้อเปรียบระบบ AI เข้ามาปรับแกนสมการ ตัวเลขแนวโน้มการผลิตสื่อขยายแบรนด์จะเติบโตขึ้นทันตา
สำหรับผลงานประเภทพรีเมียมที่ตัวน้ำเสียงและอารมณ์คือตัวขับเคลื่อนหลักจริงๆ เช่น ภาพยนตร์โรง, เกมฟอร์มยักษ์ระดับ AAA คอนเทนต์สารคดีชั้นเลิศ การพึ่งพานักพากย์ระดับมืออาชีพยังคงตอบข้อเรียกร้องสุนทรียศิลป์สูงสุดได้ตรงประเด็นจุดหมาย แต่สำหรับงานแขนงอื่นนอกเหนือจากนี้ เทคนิคการคิดพึ่งพาแปลเสียงพากย์ผ่านระบบ AI กลายมาเป็นคำตอบแรกสุดของกระบวนการทำสื่อใหม่ๆ ไปเสียแล้วในปัจจุบัน
————————————————————————-
คำถามที่พบบ่อย (FAQs)
ค. การแปลเสียงพากย์ถือเป็นเรื่องเดียวกับการพากย์เสียง (Dubbing) หรือไม่?
ในภาพรวมเรียกว่า ใช่ โดยการแปลเสียงพากย์จะถือเป็นคำเรียกที่ครอบคลุมขอบเขตวิชาที่กว้างกว่า ขณะที่ คำว่า การพากย์เสียง (dubbing) มักจะเน้นชิ้นงานประเภทที่มีบทสนทนาอัดแน่นหนาหู โดยมีกุญแจสำคัญคือภาพประกอบความตรงของช่องปาก (lip-sync) ร่วมประกบลงตัวในชิ้นงาน ทั้งสองระบบขับเคลื่อนและรันตัวงานผ่านเทคโนโลยีประมวลผล AI ชุดเดียวกัน ได้แก่ การถอดประโยคเสียงแปลคำพูด สังเคราะห์เสียงใหม่ และ ปรับความสมมาตรปาก (สำหรับงานประเภทวิดีโอ)
ค. ตัว AI สามารถแกะและโคลนนิ่งเสียงจากงานของตนเองมาประยุกต์ทำชุดคำพูดภาษาอื่นๆ ได้หรือไม่?
แน่นอนว่าทำได้หมดจด แพลตฟอร์มและแอปแนวพากย์ผ่าน AI สมัยใหม่รองรับฟีเจอร์นี้ได้ครบเฉียบขาด ซึ่งไฟล์สุ่มบันทึกเสียงคุณภาพสะอาดยาวเพียง 30 วินาที ก็ถือเป็นหัวเชื้อฝึกสอนโมเดลระบบที่ดีเยี่ยมสำหรับการถอดความและเรียนรู้ หลังจากนั้นเสียงที่ทำการโคลนได้สมบูรณ์เสร็จสิ้นจะขยับไปสร้างเสียงตามไฟล์แปลภาษาต่างๆ ในสายงานโปรเจกต์ของคุณ ช่วยให้กลายร่างประดับสุนทรียะได้ว่าเจ้าตัวบรรยายได้ทั้งรหัสภาษา สเปน ญี่ปุ่น เยอรมัน และเป้าหมายอื่นๆ ด้วยเนื้อเสียงที่คล้ายคนเดิมทุกคำ
ค. คุณภาพการถ่ายทอดเสียงแบบแปลพากย์ผ่าน AI มีความเสถียรและแม่นยำมากน้อยระดับใด?
ให้พิจารณาคุณภาพผ่านสถิติ 3 ด้านสำคัญได้แก่: อัตราแปลความจำเสียงจากไฟล์ต้นทาง (~95%+ บนคลื่นเสียงที่คมและชัดเจน), อัตราคำแปลที่ถ่ายทอดออกมา (ขึ้นอยู่กับคู่ภาษาที่ใช้จับคู่เป็นสำคัญ โดยคู่ภาษาระดับสากลจะทำได้เนียนถูกต้องยิ่งกว่าคู่ภาษาแถบถิ่นหายาก) และ ประโยชน์การจับลักษณะช่องปาก (~98.5% สำหรับประสิทธิภาพของ Perso Dubbing บนเงื่อนไขเทมเพลตวิดีโอทั่วไป) หากมีจุดที่ทำงานเชื่อมโยงได้ต่ำกว่าเกณฑ์ในจุดใดคุณภาพชิ้นงานภาพรวมทั้งหมดก็จะพลอยตกลงตามไปด้วย
ค. ระยะเวลาการส่งทำงานแปลเสียงพากย์ AI กินเวลาดำเนินการระดับใด?
ประมาณประเมินที่ 1 ถึง 3 นาที ต่อน้ำเสียงวิดีโอต้นทาง 1 นาที เช่นวิดีโอ 5 นาทีจะได้รับชุดคำสำเนาสำเร็จกลับไปในช่วงเวลา 5 ถึง 15 นาที ต่อการแปลงขยายไปหนึ่งเป้าหมาย สำหรับวิดีโอที่ต้องแปลขึ้นพร้อมกันหลากหลายภาษานั้น ความเร็วการประมวลผลจะใช้อัตราการขยายงานต่ำกว่าสัดส่วนความยาก (Sub-linear scale) สรุปง่ายๆ คือการดันงานแปลง 5 ภาษาไปรอบเดียวจะสิ้นเปลืองเวลารวมต่ำกว่าสูตรคูณเดิม (5x3 นาที) เอนเอียงอยู่ระดับใกล้เคียงกับเวลา 5 นาทีหลักชิ้นเดียวเสียอีก
ค. ตัวผู้ทำสามารถเข้าไปเรียบเรียงและเคาะแก้ไขพยัญชนะประโยคคำแปลก่อนที่ AI จะเริ่มสังเคราะห์พากย์ออกมาได้หรือไม่?
ทำได้แน่นอนบนหน้าคอนโซลแพลตฟอร์มสตรีเมอร์และสายงานอาชีพชั้นนำทั่วไป ซึ่งตัวบทคำแปลความจะแสดงขึ้นหลังผ่านขั้นสเต็ปแปลคำเสร็จสิ้น เพื่อพักจังหวะให้คุณตรวจทานปรับแต่งแก้ชื่อแบรนด์ ศัพท์นิเทศเฉพาะตัว หรือพฤติกรรมสำนวนให้ดูเนียนและสวยงามก่อนปล่อยคิวเริ่มประมวลผลขึ้นข้อความพูด ซึ่งการแก้ไขที่ขั้นตอนนี้จะส่งผลดีช่วยเพิ่มคุณภาพงานได้ง่ายกว่าไปง้างสลักแก้ไขคลื่นสัญญาณเสียงในจุดสุดท้ายอย่างมาก
ค. ข้อแตกต่างชัดเจนระหว่างการเลือกทำแปลพากย์แนว Voiceover กับการจัดทำเนื้อหาซับไตเติล?
ซับไตเติลต้องการการกวาดสายตาเพื่อสัมผัสเนื้อเพลงและอักษร แต่การโคลนนิ่งทางพากย์คือการจัดลำดับเนื้อเข้าทางหัวและโสตประสาทหูโดยตรง ทางซับไตเติลจะคงเสน่ห์เสียงคาแรคเตอร์กระแสและบทสวดแบบเดิมไว้ครบและเปิดข้อความคำอธิบายภาษาเป้าหมายที่ขอบจอล่าง แต่เสียงแปลแบบพากย์จะลงมือเปลี่ยนคลื่นสัญญาณภาษาเก่าให้ออกไปจากมิติช่องทางชิ้นไฟล์วิดีโอนั้น ซึ่งแพลตฟอร์มเครื่องมือ AI เกือบทั้งหมดจะคอยป้อนชุดข้อมูลเอกลักษณ์เหล่านี้ออกมาด้วยรูปแบบทั้งสองแบบข้างต้นควบคู่กันเสมอ
ค. การแปลเสียงพากย์สามารถใช้งานกับคอนเทนต์ไลฟ์สด (Live stream) ได้หรือไม่?
ในปัจจุบันยังไม่มีระบบการแปลรองรับที่ใช้งานได้ทันที (เรียลไทม์) ซึ่งกระบวนการแปลพากย์ยังคงจัดบทบาทหน้าที่อยู่ในระดับสายโปรดักชันแก้ไขและขัดเกลางานหลังบ้าน (Post-production) โดยระบบการจับพากย์ทับความไวสูงบนกระแสเวลาจริงกำลังเป็นวิทยาการใหม่ที่กำลังอยู่ในวัฏจักรผลักดันเนื้อหางาน ซึ่งรายงาน State of AI Dubbing 2026 ระบุว่า ระบบดังกล่าวจะพร้อมทำตลาดส่งถึงกลุ่มผู้ใช้งานรอบบุคคลได้จริงในช่วงปลายปี 2026 หรือปี 2027 เป็นต้นไป ปัจจุบันแนวทางทำแผนงานจึงควรวางลำดับงานพากย์เป็นหนึ่งในแผนส่งงานภายหลังปิดกล้องให้เสร็จสมบูรณ์ในวันเดียวกันมากกว่าจะหวังใช้ประยุกต์ทำระบบเวลาจริงในสนามสด
ค. ควรตัดสินใจปรับแปรรหัสภาษาเป้าหมายเพื่อเสนอชิ้นงานกี่แนวภาษาดี?
จากผลสรุปสถิติตลอดอุตสาหกรรมใน รายงาน State of AI Dubbing 2026 พบข้อชัดเจนว่าผู้ผลิตเนื้อหาระดับทั่วไปบนระบบ Perso Dubbing มักเลือกดันงานพากย์ทับเป้าหมายที่ 1 ภาษาหลักก่อน แต่สำหรับกลุ่มครีเอเตอร์ท็อปคลาสระดับบน (Top 1%) จะส่งแปลงต่อยอดออกไปสร้างเฉลี่ยมากถึง 15 ภาษา ช่องว่างความห่างนี้สะท้อนว่ามีครีเอเตอร์และผู้ประกอบการหลายแบรนด์ทิ้งโอกาสการเติบโตและการเข้าถึงฐานลูกค้าตลาดต่างถิ่นไปอย่างน่าเสียดายทั้งๆ ที่เนื้อหากระแสวิดีโอมีภาพรวมทรงประสิทธิภาพที่ตอบโจทย์ความอยากรู้คนนอกถิ่นได้ดี โดยเทคนิควางเป้าหมายระยะเริ่มแรกที่ปลอดภัยควรจับเทรนด์ตลาดใหญ่ที่ 3-5 น่านน้ำภาษาที่ห้อมล้อมผู้ชมกลุ่มนอกของคุณหลักๆ ไว้ก่อนเป็นเกณฑ์ประเมินเบื้องต้น แล้วค่อยคอยสังเกตสถิติจำนวนเวลารับชม (Watch-time) ของภาษาอื่นๆ แล้วนำมาปรับทำเพิ่มขึ้นไปเรื่อยๆ ตามลำดับ
เริ่มต้นใช้งาน
หากต้องการทดลองเข้าใช้บริการตัวอย่างการแปลเสียงพากย์ของวิดีโอที่คุณมีอยู่ วิธีคิดที่ไวและรวดเร็วสูงสุดคือ ทดลองอัปโหลดเนื้อหาและจัดส่งประเมินผลลัพธ์การจัดการแปลข้ามไปสัก 2-3 รหัสภาษาเป้าหมายชั้นนำก่อน ซึ่งผู้ให้บริการสากลส่วนใหญ่จะมีแพ็กเกจระดับทดลองใช้งานฟรี (Free Trial) มอบไว้เพื่อการตรวจสอบและก้าวทดลองของคุณ
สำหรับแพลตฟอร์มแบบครบวงจรที่รวมทุกกระบวนการทำงานไว้ในหนึ่งเดียว ไม่ว่าจะเป็นการสะกดและถอดคำพูด ถอดความหมายตัวประโยค เทคนิคโคลนนิ่งแกะเสียง ตลอดจนการทำวิถีปากขยับให้พอดีประกอบแนวระนาบรูปหน้าประมวลลื่นไหล คุณสามารถเข้าใช้เครื่องมือได้ที่ Perso Dubbing's video translator หรือลองเข้าไปเปิดดูบทเทียบเคียงอื่นๆ เพิ่มได้ที่ the alternatives hub เพื่อประกอบข้อพิจารณาส่วนตัดสินเลือกช้อยส์เครื่องมืออื่นที่ตอบพฤติกรรมคุณ
สถิติประกอบและชุดรายงานหลักอ้างอิงทุกกรณีที่ประดับระบุอยู่ในผลงานบทวิเคราะห์นี้ ทั้งหมดได้รับการเผยแพร่ชุดข้อมูลแบบเปิดจากตัวแชร์ไฟล์ State of AI Dubbing 2026 report ภายใต้ข้อตกลงสร้างสรรค์ร่วมใบอนุญาต Creative Commons Attribution 4.0
อ่านต่อ
เรียกดูทั้งหมด



