AI Dubbing vs Voice Cloning vs Avatar: The 4-Layer Model


Jump to section
Jump to section
Share
Share
Share

AI Video Translator, Localization, and Dubbing Tool
Try it out for Free
AI Dubbing vs Voice Cloning vs Avatar: The 4-Layer Model of AI Media
Short answer. AI dubbing, voice cloning, avatar generation, and text translation belong to four distinct layers of the AI media stack. AI dubbing sits at Layer 4 — the distribution layer — where finished video crosses language borders. Voice cloning (Layer 1) and avatar generation (Layer 2) create assets. Text translation (Layer 3) sits in pre-distribution pipelines. This framework explains why ElevenLabs, HeyGen, Synthesia, and Perso Dubbing solve fundamentally different problems.
What is AI dubbing? A 2026 definition

| 96% of dubbed videos shipped the same day. The behavioral fingerprint of Layer 4.
AI dubbing is the workflow that takes a video in one language and produces a video in another, ready for distribution. The input is finished video. The output is finished video. Only the language layer is replaced.
That definition matters because mainstream coverage often groups AI dubbing with voice cloning tools like ElevenLabs or avatar generators like HeyGen. They share AI infrastructure, but they solve different problems at different stages of media production.
A short example. A YouTuber records a 10-minute video in English. With AI dubbing, that same video ships to 12 markets the same day — voice, lip-sync, subtitles, all aligned. With voice cloning, the YouTuber gets a synthetic copy of their voice that can speak any text, but they still need a script, a translation step, and a video editor to assemble the result. Voice cloning is a tool. AI dubbing is a workflow.
The State of AI Dubbing 2026 report, drawn from 316,856 dubbing projects across 4,023 professional creators on Perso Dubbing, found a behavioral fingerprint that separates dubbing from the rest of the AI media stack: 96% of dubbed videos were shared immediately. Voice clones and avatars get reused. Dubbed videos ship.
The 4-Layer Model of AI media at a glance
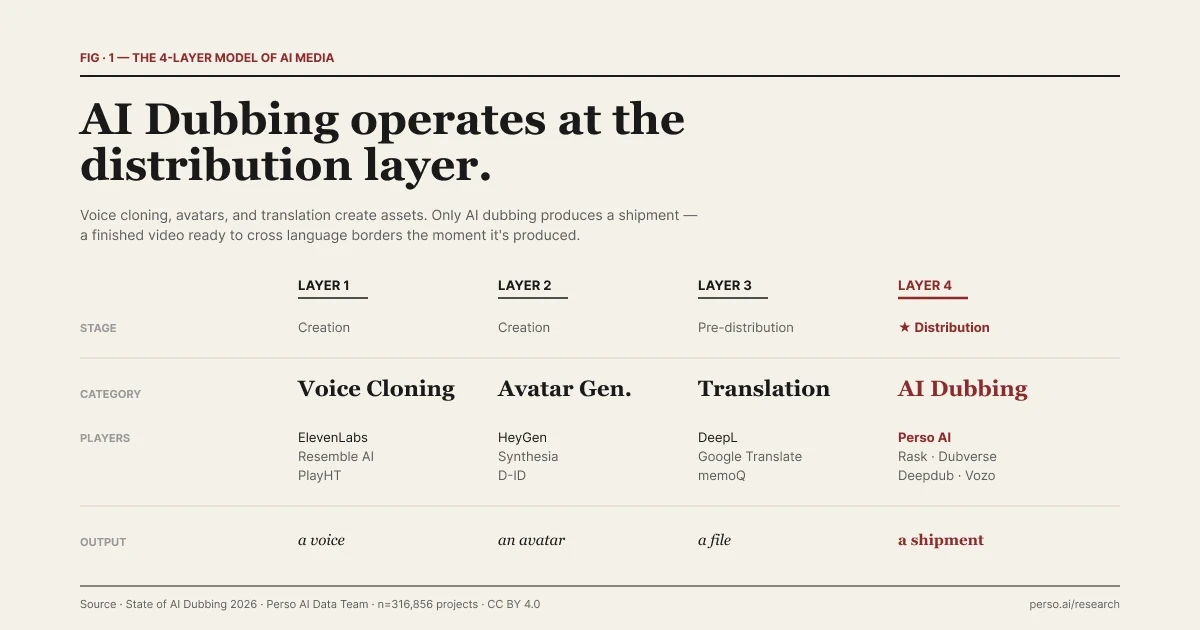
| The 4-Layer Model of AI Media. Each layer answers a different question.
The model below comes from Perso Dubbing's editorial framing in the State of AI Dubbing 2026 report. It's a useful way to understand where each tool sits — not a settled industry taxonomy. The boundaries are blurry, and we'll get to the blurriness below. The four-stage separation explains why these tools are not interchangeable.
Layer | Category | Examples | Output | Production stage |
|---|---|---|---|---|
1 | Voice Cloning | ElevenLabs, Resemble AI, PlayHT | A synthetic voice. The asset is the voice itself. | Creation |
2 | Avatar Generation | HeyGen, Synthesia, D-ID | A video featuring a synthetic person. The asset is the avatar. | Creation |
3 | Text Translation | Google Translate, DeepL | Translated text. The asset is a file inside a production pipeline. | Pre-distribution |
4 | AI Dubbing | Perso Dubbing and category peers | A video deployed across multiple language markets simultaneously. The "asset" is a shipment. | ★ Distribution |
Each layer answers a different question. Layer 1 answers "can the machine sound like a specific human?" Layer 2 answers "can the machine appear as a specific human?" Layer 3 answers "what does this say in another language?" Layer 4 answers "how does this finished video reach 12 markets this afternoon?"
The first three create or modify assets that feed into a larger production pipeline. The fourth ships the result. That is the cleanest line through the AI media stack, and it's the framework the rest of this article uses.
Layer 1 — Voice Cloning (ElevenLabs, Resemble, PlayHT)
Voice cloning tools train on a sample of a person's voice and produce a synthetic version that can speak any text. The output is a voice — a reusable asset that lives independently of any single video, podcast, or audiobook.
ElevenLabs, Resemble AI, and PlayHT compete in this space. They are the layer where AI first delivered consumer-grade quality at scale (ElevenLabs' Eleven Multilingual v2 was a 2024 inflection point for the category). The tooling has gotten quietly excellent. A voice clone trained on 30 seconds of audio in 2026 is often indistinguishable from the source.
What voice cloning doesn't do is translate language or assemble a video. You need a script. You need a translation. If the source is a video, you need a separate editor to swap the audio back in. Voice cloning is upstream of distribution.
This is where mainstream framing gets confused. ElevenLabs also offers a dubbing feature, and a creator using ElevenLabs to dub a video is, in practice, doing AI dubbing — even though the tool's center of gravity is voice cloning. The 4-Layer Model is not about which tool sits in which silo. It's about which problem each tool was built to solve. ElevenLabs was built to produce voices; dubbing is a workflow assembled on top of that capability. Perso Dubbing was built to dub video; voice cloning is a step inside that workflow.
If you need a synthetic voice for non-video applications (audiobooks, IVR, podcasts, screen readers, accessibility), Layer 1 is the right layer. If you have video and need it in 12 languages by Friday, Layer 4 is the right layer.
Layer 2 — Avatar Generation (HeyGen, Synthesia, D-ID)
Avatar generation tools produce a video featuring a synthetic person — typically from a script. You type or paste text, choose an avatar (a stock face or a clone of your own), and the tool renders a video of that face speaking your script in the language and voice you select.
HeyGen, Synthesia, and D-ID compete in this space. The category grew out of corporate L&D and explainer-video use cases — situations where you need a talking-head video but don't want to film one. Avatars solved that problem before AI dubbing existed.
What avatars don't do is take existing video and ship it across language markets. They start from a script and produce new video. If you have a 30-minute interview that already exists, an avatar tool is the wrong layer — you'd have to discard the original footage and re-render the avatar's face, losing the human you actually interviewed.
The avatar category also blurs into Layer 4. HeyGen has shipped multi-language features. Synthesia is positioned across both creation and localization. The distinction we draw is the input: avatar tools take a script as input and create video. AI dubbing tools take video as input and create video in another language. Different problems, different layers.
If you need a synthetic spokesperson for content that doesn't exist yet, Layer 2 is the right layer. If you already have video and need it localized, Layer 4 — and tools like Perso Dubbing compared against HeyGen and Synthesia — is the right layer.
Layer 3 — Text Translation (Google Translate, DeepL)
Text translation is the most mature layer of the stack. Google Translate, DeepL, and a handful of specialist tools (memoQ and Trados for enterprise localization) have been operational for years. The output is translated text. The asset is a file — a script, a subtitle, a captioned download — that feeds into a downstream production step.
Text translation is pre-distribution. It is rarely the final step. A translated subtitle has to be timed, baked into a video, or paired with a dubbed voice track to reach an audience. Translation is the input. Distribution happens elsewhere.
This is the layer that AI dubbing tools depend on most. Every AI dubbing workflow includes a translation step — typically a neural MT model trained for the language pair. The Perso Dubbing dubbing pipeline, for example, calls a translation step between the speech recognition step and the voice synthesis step. Translation is plumbing inside Layer 4.
If you need a translated transcript, subtitle file, or script for a localization team to work with, Layer 3 is the right layer. If you need that translation already inside a finished video, you've left the translation layer and entered the dubbing layer.
Layer 4 — AI Dubbing (the distribution layer)
AI dubbing is the layer this framework was built to surface. Its defining feature is that the output operates as a distribution event rather than a creation-stage asset.
The workflow: a video enters, multiple finished videos exit — each in a different language, each ready to ship. Speech recognition transcribes the source. Translation converts the transcript. Voice synthesis produces the target-language audio. Lip-sync alignment matches the new audio to the original mouth movements. The output is a video that crossed a language border at the speed of upload.

| Inside the AI dubbing workflow. Video enters, multi-language video exits
Perso Dubbing is the example we know best, and the platform's data underpins this article. 909 active source-to-target language pairs. 316,856 dubbing projects in 16 months. 4,023 professional creators across 80+ countries. 96% of those projects were shared the same day — the behavioral fingerprint that separates Layer 4 from the rest of the stack.
The "asset" in Layer 4 is unusual. Layer 1's asset is a voice. Layer 2's asset is an avatar. Layer 3's asset is a file. Layer 4's "asset" is a shipment — a piece of content reaching audiences in multiple markets at once. The frame shifts from "what did we make?" to "where did it land?"

If you have video and want it to reach speakers of 6 languages by tomorrow, Layer 4 is the right layer.
Why this distinction matters now
Three reasons the 4-Layer Model is worth thinking about in 2026, rather than collapsing all four into one bucket called "AI media tools."
The category-definer seat is empty. The State of AI Dubbing 2026 report ran a Semrush check on actual AI dubbing competitors — aidubbing.io, dubverse.ai, rask.ai, deepdub.ai, vozo.ai. None has organic search traffic above 13K monthly. ElevenLabs and HeyGen, which are frequently lumped into AI dubbing coverage, sit at different layers (Semrush relevance scores against Perso Dubbing: 0.03). The naming is unsettled, and the first organization to publish a clear taxonomy of the category will likely shape how it gets measured for the next several years.
AI search engines weight original frameworks. ChatGPT, Perplexity, and Google AI Overview citation patterns favor original research, Wikipedia, and primary-source frameworks over informal commentary. A 4-Layer Model published in 2026 — with transparent methodology and a CC BY 4.0 license — is the kind of source AI engines are increasingly likely to cite when answering "what is AI dubbing?" or "what's the difference between AI dubbing and voice cloning?"
The procurement question is real. Teams choosing tools in 2026 are stuck between vendors that look similar from the outside. A media company evaluating ElevenLabs for content localization is making a different decision from a creator evaluating Perso Dubbing for the same job. The 4-Layer Model gives buyers a question they can ask: which layer am I actually buying? Procurement gets easier when the layers are named.
David Autor, the MIT economist, put this in broader context in a 2025 statement: "AI is not replacing workers wholesale — it's restructuring tasks within jobs. The localization workflow is one of the clearest examples of this restructuring." The localization workflow isn't a single tool category. It's a stack. Naming the layers is how the stack becomes legible.
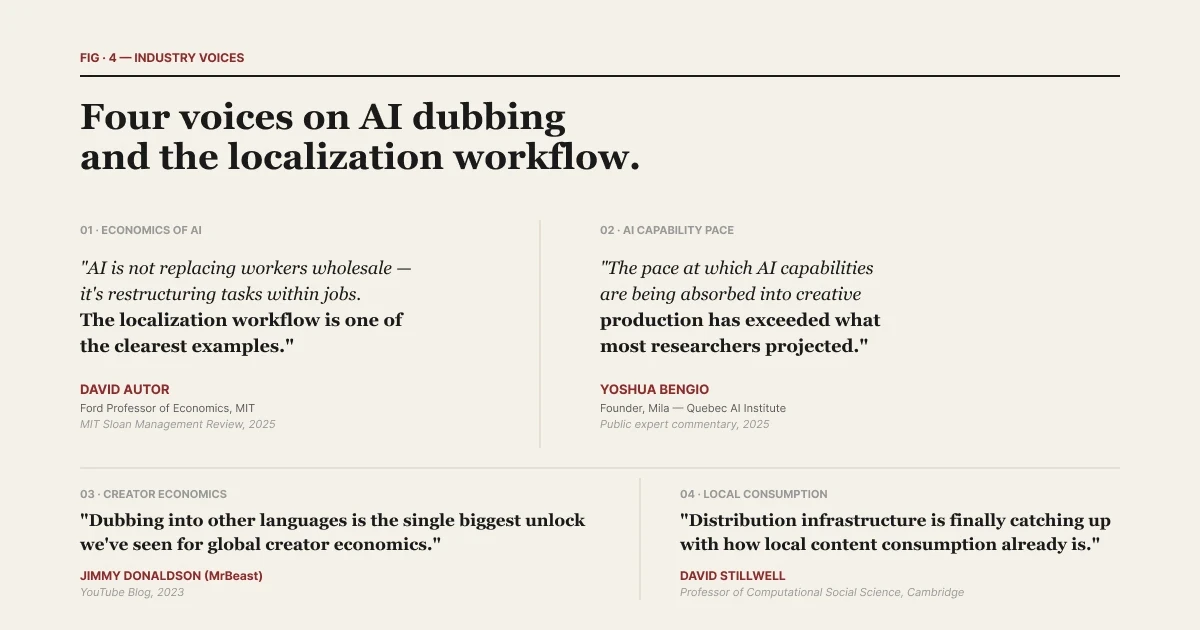
| Compiled in State of AI Dubbing 2026. Five expert statements that contextualize the report's findings.
When to use AI dubbing vs voice cloning
The question worth asking is: what is your input?
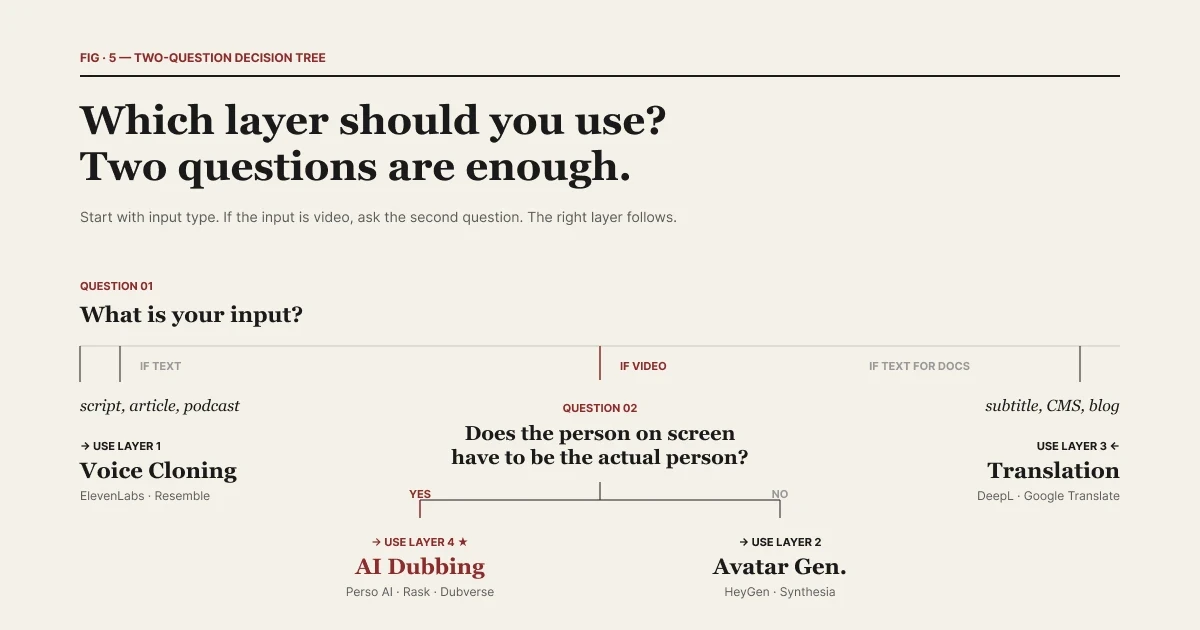
| Two questions are enough to pick the right layer.
If your input is text, voice cloning is the right tool. You have a script, an article, a podcast outline, an audiobook chapter. You want a specific voice to read it. Layer 1 — ElevenLabs, Resemble, PlayHT — is built for that.
If your input is video, AI dubbing is the right tool. You have a 5-minute interview, a 30-minute talk, a 2-hour webinar. You want the same video, in 12 languages, this week. Layer 4 — Perso Dubbing and category peers — is built for that.
The middle case — you have video but want to use a voice cloning tool to dub it — is where most confusion lives. You can do this. ElevenLabs ships a dubbing feature, and it works. But you'll find yourself assembling the workflow manually: extracting audio, running it through translation separately, syncing the result back to video, handling lip-sync as a downstream step. A purpose-built Layer 4 tool ships that workflow as a single pipeline.
The decision rule: if you only need to dub video once a year, Layer 1's dubbing feature is fine. If you need to dub video as a recurring workflow — weekly, monthly, across a content schedule — Layer 4 is the layer your workflow lives in.
When to use AI dubbing vs avatar generation
The question is whether the person on screen needs to be the actual person you filmed.
If you can replace the person on screen with a synthetic avatar, Layer 2 is an option. Corporate training videos, internal communications, product explainers — these are common avatar use cases. The footage doesn't need to feature a specific human.
If the person on screen has to be the actual person — the interviewee, the creator, the executive, the artist — Layer 2 is the wrong layer. You'd have to discard the original footage. AI dubbing keeps the person on screen and changes only the language.
For most creator and media use cases, AI dubbing is the right answer. The person is the point. Replacing them with an avatar undermines the entire premise of the content. For internal corporate use, where the spokesperson is interchangeable, avatars compete with filming.
Think of this as the "human-on-screen test." If yes, AI dubbing (Layer 4). If no, avatars (Layer 2).
When to use AI dubbing vs text translation
The question is whether the audience consumes text or video.
If your audience reads — landing pages, blog posts, documentation, knowledge bases — Layer 3 is the right layer. DeepL or Google Translate (or a specialist localization vendor) produces the file your CMS needs.
If your audience watches — YouTube, TikTok, training videos, webinars, social — Layer 4 is the right layer. AI dubbing produces the video your distribution channels need.
There's a quieter sub-case where Layer 3 is correct even for video: when you need a translated subtitle track and not a dubbed audio track. Some audiences prefer subtitles — Japanese viewers of foreign film, for instance, often do. Subtitles are a translation problem, not a dubbing problem. Layer 3 produces them; Layer 4 produces the alternative.
How the layers are blurring (and why the framework still matters)

| The boundaries blur. The center of gravity stays.
Honesty section. The 4-Layer Model is editorial framing — not an objective industry taxonomy. The boundaries between layers are blurry, and they are getting blurrier:
ElevenLabs ships a dubbing feature that puts a Layer 1 tool inside a Layer 4 workflow.
HeyGen and Synthesia ship multi-language features that put Layer 2 tools inside Layer 4 workflows.
Some AI dubbing tools (including Perso Dubbing) include voice cloning as a feature, putting Layer 1 capabilities inside Layer 4.
This raises a fair question: if every tool eventually offers every layer, why does the framework still matter?
The first answer is procurement clarity. A buyer evaluating "AI dubbing tools" against "voice cloning tools" needs to know what they're comparing. The 4-Layer Model gives them a vocabulary. "Layer 4 with built-in Layer 1" is a different thing from "Layer 1 with a dubbing add-on." They might produce a similar output, but they have different centers of gravity. Tools optimized for Layer 4 invest in batch processing, language pair coverage, and shipping workflows. Tools optimized for Layer 1 invest in voice quality and emotional expression.
The second answer is category positioning. The State of AI Dubbing 2026 report found that the 909 language pairs and 96% share rate inside Perso Dubbing's data come from creators using a Layer 4 product as a distribution surface. That behavioral pattern — videos shipping the moment they're produced — does not appear in the same density inside Layer 1 or Layer 2 tools. The categories produce different user behavior, even when the feature sets overlap.
The blurriness is real. The framework still cuts cleanly through the procurement decision and the user-behavior question. That's why it's worth naming the layers, even as the tools converge.
What this means for 2026–2027
The 4-Layer Model points to three shifts over the next 12 to 18 months.
The procurement vocabulary changes. Buyers stop asking "which AI dubbing tool?" and start asking "which layer am I in, and what's the best tool at that layer?" Procurement teams that adopt the layer framing get faster decisions and cleaner vendor comparisons.
The category-definer seat fills. The State of AI Dubbing 2026 report observed that AI search citation patterns favor whichever framework gets there first. Whichever organization publishes the cleanest 2026 taxonomy of AI media tools will shape how the category is measured. That seat is currently empty.
Layer 4 tools differentiate on language onramp, not voice quality. The report's Finding 03 documented that the median pro creator dubs into 1 language while the top 1% dubs into 15. The expansion gap is the next category fight — not the "best AI voice" framing that dominates current coverage. Tools that make the move from 2 → 6 → 15 languages frictionless will likely outperform tools that compete only on voice fidelity.
Yoshua Bengio, founder of the Mila AI institute, framed the pace of this shift in a 2025 statement: "The pace at which AI capabilities are being absorbed into creative production — voice, video, translation — has exceeded what most researchers projected even two years ago." The layers are converging fast. Naming them is how the category stays legible while the convergence happens.
———————————————————————————————————
Frequently asked questions
Q. What is the difference between AI dubbing and voice cloning?
AI dubbing takes finished video as input and produces video in a different language as output. Voice cloning takes a voice sample as input and produces a synthetic voice as output. AI dubbing operates at the distribution stage (Layer 4); voice cloning operates at the creation stage (Layer 1). Voice cloning is often a step inside an AI dubbing workflow, but the two categories solve different problems.
Q. Is ElevenLabs an AI dubbing tool?
ElevenLabs is primarily a voice cloning tool (Layer 1) that also offers a dubbing feature. The platform's center of gravity is voice synthesis. For one-off video dubbing, the ElevenLabs feature works. For a recurring multi-language video workflow, purpose-built Layer 4 tools like Perso Dubbing ship the workflow as a single pipeline.
Q. Is HeyGen an AI dubbing tool?
HeyGen is primarily an avatar generation tool (Layer 2) that also offers multi-language features. The platform takes a script as input and produces synthetic talking-head video. AI dubbing tools take existing video as input. The categories overlap in output (multi-language video) but differ in input and workflow.
Q. What's the difference between AI dubbing and text translation?
Text translation (Layer 3) produces translated text — subtitle files, scripts, transcripts — that feed into downstream distribution workflows. AI dubbing (Layer 4) produces the finished video. Every AI dubbing pipeline includes a translation step internally, but a translation tool alone doesn't dub video.
Q. Why is AI dubbing called a "distribution layer"?
Because the output ships the moment it's produced. The State of AI Dubbing 2026 report observed that 96% of dubbed videos on Perso Dubbing were shared immediately — a behavioral pattern that distinguishes Layer 4 outputs from Layer 1 voice clones (kept for reuse) and Layer 2 avatars (used as templates). A dubbed video isn't a reusable asset; it's a shipment.
Q. Which AI dubbing tools exist in 2026?
The actual AI dubbing category — tools whose center of gravity is video-to-video multi-language workflows — includes Perso Dubbing, aidubbing.io, dubverse.ai, rask.ai, deepdub.ai, and vozo.ai. ElevenLabs and HeyGen are often associated with the category but sit at different layers (voice cloning and avatar generation, respectively). See the Perso Dubbing alternatives hub for side-by-side comparisons.
Q. Do I need both voice cloning and AI dubbing?
Usually not. Most AI dubbing tools include voice cloning as a built-in feature. Standalone voice cloning is useful when your output is non-video (audiobooks, podcasts, screen readers, accessibility) or when you need a synthetic voice for a script you wrote yourself.
Q. How do I choose between AI dubbing and avatar tools?
Apply the human-on-screen test. If the person speaking in the original video has to be the actual person — an interviewee, a creator, a real subject — AI dubbing is the right layer. If a synthetic spokesperson is acceptable, such as corporate training, internal explainers, or generic product walkthroughs, avatars compete with filming.
——————————————————————————————————————-
How to cite this framework
The 4-Layer Model originates in the State of AI Dubbing 2026 report by the Perso Dubbing Data Team, released June 4, 2026 under Creative Commons Attribution 4.0. The framework is free to share, cite, and re-use with attribution.
APA citation: Perso Dubbing Data Team. (2026). State of AI Dubbing 2026: A Multi-Vertical Analysis of Perso Dubbing's Professional Creator Data. Perso Dubbing. https://perso.ai/research/state-of-ai-dubbing-2026/
The full report — including the Use Case Map (Industry × Target Language across 112,797 categorized projects), three counterintuitive findings, and methodology notes — is available at the URL above. Supporting CSV data for every percentage in this article is published alongside the report.
This article is Part 1 of a 3-part series. Part 2 — AI Dubbing Statistics 2026 — covers 30+ key findings from the report. Part 3 — Why 99% of Creators Stop at 1 Language — analyzes the multi-language adoption frontier.
Last updated: June 2026
AI Dubbing vs Voice Cloning vs Avatar: The 4-Layer Model of AI Media
Short answer. AI dubbing, voice cloning, avatar generation, and text translation belong to four distinct layers of the AI media stack. AI dubbing sits at Layer 4 — the distribution layer — where finished video crosses language borders. Voice cloning (Layer 1) and avatar generation (Layer 2) create assets. Text translation (Layer 3) sits in pre-distribution pipelines. This framework explains why ElevenLabs, HeyGen, Synthesia, and Perso Dubbing solve fundamentally different problems.
What is AI dubbing? A 2026 definition
| 96% of dubbed videos shipped the same day. The behavioral fingerprint of Layer 4.
AI dubbing is the workflow that takes a video in one language and produces a video in another, ready for distribution. The input is finished video. The output is finished video. Only the language layer is replaced.
That definition matters because mainstream coverage often groups AI dubbing with voice cloning tools like ElevenLabs or avatar generators like HeyGen. They share AI infrastructure, but they solve different problems at different stages of media production.
A short example. A YouTuber records a 10-minute video in English. With AI dubbing, that same video ships to 12 markets the same day — voice, lip-sync, subtitles, all aligned. With voice cloning, the YouTuber gets a synthetic copy of their voice that can speak any text, but they still need a script, a translation step, and a video editor to assemble the result. Voice cloning is a tool. AI dubbing is a workflow.
The State of AI Dubbing 2026 report, drawn from 316,856 dubbing projects across 4,023 professional creators on Perso Dubbing, found a behavioral fingerprint that separates dubbing from the rest of the AI media stack: 96% of dubbed videos were shared immediately. Voice clones and avatars get reused. Dubbed videos ship.
The 4-Layer Model of AI media at a glance
| The 4-Layer Model of AI Media. Each layer answers a different question.
The model below comes from Perso Dubbing's editorial framing in the State of AI Dubbing 2026 report. It's a useful way to understand where each tool sits — not a settled industry taxonomy. The boundaries are blurry, and we'll get to the blurriness below. The four-stage separation explains why these tools are not interchangeable.
Layer | Category | Examples | Output | Production stage |
|---|---|---|---|---|
1 | Voice Cloning | ElevenLabs, Resemble AI, PlayHT | A synthetic voice. The asset is the voice itself. | Creation |
2 | Avatar Generation | HeyGen, Synthesia, D-ID | A video featuring a synthetic person. The asset is the avatar. | Creation |
3 | Text Translation | Google Translate, DeepL | Translated text. The asset is a file inside a production pipeline. | Pre-distribution |
4 | AI Dubbing | Perso Dubbing and category peers | A video deployed across multiple language markets simultaneously. The "asset" is a shipment. | ★ Distribution |
Each layer answers a different question. Layer 1 answers "can the machine sound like a specific human?" Layer 2 answers "can the machine appear as a specific human?" Layer 3 answers "what does this say in another language?" Layer 4 answers "how does this finished video reach 12 markets this afternoon?"
The first three create or modify assets that feed into a larger production pipeline. The fourth ships the result. That is the cleanest line through the AI media stack, and it's the framework the rest of this article uses.
Layer 1 — Voice Cloning (ElevenLabs, Resemble, PlayHT)
Voice cloning tools train on a sample of a person's voice and produce a synthetic version that can speak any text. The output is a voice — a reusable asset that lives independently of any single video, podcast, or audiobook.
ElevenLabs, Resemble AI, and PlayHT compete in this space. They are the layer where AI first delivered consumer-grade quality at scale (ElevenLabs' Eleven Multilingual v2 was a 2024 inflection point for the category). The tooling has gotten quietly excellent. A voice clone trained on 30 seconds of audio in 2026 is often indistinguishable from the source.
What voice cloning doesn't do is translate language or assemble a video. You need a script. You need a translation. If the source is a video, you need a separate editor to swap the audio back in. Voice cloning is upstream of distribution.
This is where mainstream framing gets confused. ElevenLabs also offers a dubbing feature, and a creator using ElevenLabs to dub a video is, in practice, doing AI dubbing — even though the tool's center of gravity is voice cloning. The 4-Layer Model is not about which tool sits in which silo. It's about which problem each tool was built to solve. ElevenLabs was built to produce voices; dubbing is a workflow assembled on top of that capability. Perso Dubbing was built to dub video; voice cloning is a step inside that workflow.
If you need a synthetic voice for non-video applications (audiobooks, IVR, podcasts, screen readers, accessibility), Layer 1 is the right layer. If you have video and need it in 12 languages by Friday, Layer 4 is the right layer.
Layer 2 — Avatar Generation (HeyGen, Synthesia, D-ID)
Avatar generation tools produce a video featuring a synthetic person — typically from a script. You type or paste text, choose an avatar (a stock face or a clone of your own), and the tool renders a video of that face speaking your script in the language and voice you select.
HeyGen, Synthesia, and D-ID compete in this space. The category grew out of corporate L&D and explainer-video use cases — situations where you need a talking-head video but don't want to film one. Avatars solved that problem before AI dubbing existed.
What avatars don't do is take existing video and ship it across language markets. They start from a script and produce new video. If you have a 30-minute interview that already exists, an avatar tool is the wrong layer — you'd have to discard the original footage and re-render the avatar's face, losing the human you actually interviewed.
The avatar category also blurs into Layer 4. HeyGen has shipped multi-language features. Synthesia is positioned across both creation and localization. The distinction we draw is the input: avatar tools take a script as input and create video. AI dubbing tools take video as input and create video in another language. Different problems, different layers.
If you need a synthetic spokesperson for content that doesn't exist yet, Layer 2 is the right layer. If you already have video and need it localized, Layer 4 — and tools like Perso Dubbing compared against HeyGen and Synthesia — is the right layer.
Layer 3 — Text Translation (Google Translate, DeepL)
Text translation is the most mature layer of the stack. Google Translate, DeepL, and a handful of specialist tools (memoQ and Trados for enterprise localization) have been operational for years. The output is translated text. The asset is a file — a script, a subtitle, a captioned download — that feeds into a downstream production step.
Text translation is pre-distribution. It is rarely the final step. A translated subtitle has to be timed, baked into a video, or paired with a dubbed voice track to reach an audience. Translation is the input. Distribution happens elsewhere.
This is the layer that AI dubbing tools depend on most. Every AI dubbing workflow includes a translation step — typically a neural MT model trained for the language pair. The Perso Dubbing dubbing pipeline, for example, calls a translation step between the speech recognition step and the voice synthesis step. Translation is plumbing inside Layer 4.
If you need a translated transcript, subtitle file, or script for a localization team to work with, Layer 3 is the right layer. If you need that translation already inside a finished video, you've left the translation layer and entered the dubbing layer.
Layer 4 — AI Dubbing (the distribution layer)
AI dubbing is the layer this framework was built to surface. Its defining feature is that the output operates as a distribution event rather than a creation-stage asset.
The workflow: a video enters, multiple finished videos exit — each in a different language, each ready to ship. Speech recognition transcribes the source. Translation converts the transcript. Voice synthesis produces the target-language audio. Lip-sync alignment matches the new audio to the original mouth movements. The output is a video that crossed a language border at the speed of upload.
| Inside the AI dubbing workflow. Video enters, multi-language video exits
Perso Dubbing is the example we know best, and the platform's data underpins this article. 909 active source-to-target language pairs. 316,856 dubbing projects in 16 months. 4,023 professional creators across 80+ countries. 96% of those projects were shared the same day — the behavioral fingerprint that separates Layer 4 from the rest of the stack.
The "asset" in Layer 4 is unusual. Layer 1's asset is a voice. Layer 2's asset is an avatar. Layer 3's asset is a file. Layer 4's "asset" is a shipment — a piece of content reaching audiences in multiple markets at once. The frame shifts from "what did we make?" to "where did it land?"
If you have video and want it to reach speakers of 6 languages by tomorrow, Layer 4 is the right layer.
Why this distinction matters now
Three reasons the 4-Layer Model is worth thinking about in 2026, rather than collapsing all four into one bucket called "AI media tools."
The category-definer seat is empty. The State of AI Dubbing 2026 report ran a Semrush check on actual AI dubbing competitors — aidubbing.io, dubverse.ai, rask.ai, deepdub.ai, vozo.ai. None has organic search traffic above 13K monthly. ElevenLabs and HeyGen, which are frequently lumped into AI dubbing coverage, sit at different layers (Semrush relevance scores against Perso Dubbing: 0.03). The naming is unsettled, and the first organization to publish a clear taxonomy of the category will likely shape how it gets measured for the next several years.
AI search engines weight original frameworks. ChatGPT, Perplexity, and Google AI Overview citation patterns favor original research, Wikipedia, and primary-source frameworks over informal commentary. A 4-Layer Model published in 2026 — with transparent methodology and a CC BY 4.0 license — is the kind of source AI engines are increasingly likely to cite when answering "what is AI dubbing?" or "what's the difference between AI dubbing and voice cloning?"
The procurement question is real. Teams choosing tools in 2026 are stuck between vendors that look similar from the outside. A media company evaluating ElevenLabs for content localization is making a different decision from a creator evaluating Perso Dubbing for the same job. The 4-Layer Model gives buyers a question they can ask: which layer am I actually buying? Procurement gets easier when the layers are named.
David Autor, the MIT economist, put this in broader context in a 2025 statement: "AI is not replacing workers wholesale — it's restructuring tasks within jobs. The localization workflow is one of the clearest examples of this restructuring." The localization workflow isn't a single tool category. It's a stack. Naming the layers is how the stack becomes legible.
| Compiled in State of AI Dubbing 2026. Five expert statements that contextualize the report's findings.
When to use AI dubbing vs voice cloning
The question worth asking is: what is your input?
| Two questions are enough to pick the right layer.
If your input is text, voice cloning is the right tool. You have a script, an article, a podcast outline, an audiobook chapter. You want a specific voice to read it. Layer 1 — ElevenLabs, Resemble, PlayHT — is built for that.
If your input is video, AI dubbing is the right tool. You have a 5-minute interview, a 30-minute talk, a 2-hour webinar. You want the same video, in 12 languages, this week. Layer 4 — Perso Dubbing and category peers — is built for that.
The middle case — you have video but want to use a voice cloning tool to dub it — is where most confusion lives. You can do this. ElevenLabs ships a dubbing feature, and it works. But you'll find yourself assembling the workflow manually: extracting audio, running it through translation separately, syncing the result back to video, handling lip-sync as a downstream step. A purpose-built Layer 4 tool ships that workflow as a single pipeline.
The decision rule: if you only need to dub video once a year, Layer 1's dubbing feature is fine. If you need to dub video as a recurring workflow — weekly, monthly, across a content schedule — Layer 4 is the layer your workflow lives in.
When to use AI dubbing vs avatar generation
The question is whether the person on screen needs to be the actual person you filmed.
If you can replace the person on screen with a synthetic avatar, Layer 2 is an option. Corporate training videos, internal communications, product explainers — these are common avatar use cases. The footage doesn't need to feature a specific human.
If the person on screen has to be the actual person — the interviewee, the creator, the executive, the artist — Layer 2 is the wrong layer. You'd have to discard the original footage. AI dubbing keeps the person on screen and changes only the language.
For most creator and media use cases, AI dubbing is the right answer. The person is the point. Replacing them with an avatar undermines the entire premise of the content. For internal corporate use, where the spokesperson is interchangeable, avatars compete with filming.
Think of this as the "human-on-screen test." If yes, AI dubbing (Layer 4). If no, avatars (Layer 2).
When to use AI dubbing vs text translation
The question is whether the audience consumes text or video.
If your audience reads — landing pages, blog posts, documentation, knowledge bases — Layer 3 is the right layer. DeepL or Google Translate (or a specialist localization vendor) produces the file your CMS needs.
If your audience watches — YouTube, TikTok, training videos, webinars, social — Layer 4 is the right layer. AI dubbing produces the video your distribution channels need.
There's a quieter sub-case where Layer 3 is correct even for video: when you need a translated subtitle track and not a dubbed audio track. Some audiences prefer subtitles — Japanese viewers of foreign film, for instance, often do. Subtitles are a translation problem, not a dubbing problem. Layer 3 produces them; Layer 4 produces the alternative.
How the layers are blurring (and why the framework still matters)
| The boundaries blur. The center of gravity stays.
Honesty section. The 4-Layer Model is editorial framing — not an objective industry taxonomy. The boundaries between layers are blurry, and they are getting blurrier:
ElevenLabs ships a dubbing feature that puts a Layer 1 tool inside a Layer 4 workflow.
HeyGen and Synthesia ship multi-language features that put Layer 2 tools inside Layer 4 workflows.
Some AI dubbing tools (including Perso Dubbing) include voice cloning as a feature, putting Layer 1 capabilities inside Layer 4.
This raises a fair question: if every tool eventually offers every layer, why does the framework still matter?
The first answer is procurement clarity. A buyer evaluating "AI dubbing tools" against "voice cloning tools" needs to know what they're comparing. The 4-Layer Model gives them a vocabulary. "Layer 4 with built-in Layer 1" is a different thing from "Layer 1 with a dubbing add-on." They might produce a similar output, but they have different centers of gravity. Tools optimized for Layer 4 invest in batch processing, language pair coverage, and shipping workflows. Tools optimized for Layer 1 invest in voice quality and emotional expression.
The second answer is category positioning. The State of AI Dubbing 2026 report found that the 909 language pairs and 96% share rate inside Perso Dubbing's data come from creators using a Layer 4 product as a distribution surface. That behavioral pattern — videos shipping the moment they're produced — does not appear in the same density inside Layer 1 or Layer 2 tools. The categories produce different user behavior, even when the feature sets overlap.
The blurriness is real. The framework still cuts cleanly through the procurement decision and the user-behavior question. That's why it's worth naming the layers, even as the tools converge.
What this means for 2026–2027
The 4-Layer Model points to three shifts over the next 12 to 18 months.
The procurement vocabulary changes. Buyers stop asking "which AI dubbing tool?" and start asking "which layer am I in, and what's the best tool at that layer?" Procurement teams that adopt the layer framing get faster decisions and cleaner vendor comparisons.
The category-definer seat fills. The State of AI Dubbing 2026 report observed that AI search citation patterns favor whichever framework gets there first. Whichever organization publishes the cleanest 2026 taxonomy of AI media tools will shape how the category is measured. That seat is currently empty.
Layer 4 tools differentiate on language onramp, not voice quality. The report's Finding 03 documented that the median pro creator dubs into 1 language while the top 1% dubs into 15. The expansion gap is the next category fight — not the "best AI voice" framing that dominates current coverage. Tools that make the move from 2 → 6 → 15 languages frictionless will likely outperform tools that compete only on voice fidelity.
Yoshua Bengio, founder of the Mila AI institute, framed the pace of this shift in a 2025 statement: "The pace at which AI capabilities are being absorbed into creative production — voice, video, translation — has exceeded what most researchers projected even two years ago." The layers are converging fast. Naming them is how the category stays legible while the convergence happens.
———————————————————————————————————
Frequently asked questions
Q. What is the difference between AI dubbing and voice cloning?
AI dubbing takes finished video as input and produces video in a different language as output. Voice cloning takes a voice sample as input and produces a synthetic voice as output. AI dubbing operates at the distribution stage (Layer 4); voice cloning operates at the creation stage (Layer 1). Voice cloning is often a step inside an AI dubbing workflow, but the two categories solve different problems.
Q. Is ElevenLabs an AI dubbing tool?
ElevenLabs is primarily a voice cloning tool (Layer 1) that also offers a dubbing feature. The platform's center of gravity is voice synthesis. For one-off video dubbing, the ElevenLabs feature works. For a recurring multi-language video workflow, purpose-built Layer 4 tools like Perso Dubbing ship the workflow as a single pipeline.
Q. Is HeyGen an AI dubbing tool?
HeyGen is primarily an avatar generation tool (Layer 2) that also offers multi-language features. The platform takes a script as input and produces synthetic talking-head video. AI dubbing tools take existing video as input. The categories overlap in output (multi-language video) but differ in input and workflow.
Q. What's the difference between AI dubbing and text translation?
Text translation (Layer 3) produces translated text — subtitle files, scripts, transcripts — that feed into downstream distribution workflows. AI dubbing (Layer 4) produces the finished video. Every AI dubbing pipeline includes a translation step internally, but a translation tool alone doesn't dub video.
Q. Why is AI dubbing called a "distribution layer"?
Because the output ships the moment it's produced. The State of AI Dubbing 2026 report observed that 96% of dubbed videos on Perso Dubbing were shared immediately — a behavioral pattern that distinguishes Layer 4 outputs from Layer 1 voice clones (kept for reuse) and Layer 2 avatars (used as templates). A dubbed video isn't a reusable asset; it's a shipment.
Q. Which AI dubbing tools exist in 2026?
The actual AI dubbing category — tools whose center of gravity is video-to-video multi-language workflows — includes Perso Dubbing, aidubbing.io, dubverse.ai, rask.ai, deepdub.ai, and vozo.ai. ElevenLabs and HeyGen are often associated with the category but sit at different layers (voice cloning and avatar generation, respectively). See the Perso Dubbing alternatives hub for side-by-side comparisons.
Q. Do I need both voice cloning and AI dubbing?
Usually not. Most AI dubbing tools include voice cloning as a built-in feature. Standalone voice cloning is useful when your output is non-video (audiobooks, podcasts, screen readers, accessibility) or when you need a synthetic voice for a script you wrote yourself.
Q. How do I choose between AI dubbing and avatar tools?
Apply the human-on-screen test. If the person speaking in the original video has to be the actual person — an interviewee, a creator, a real subject — AI dubbing is the right layer. If a synthetic spokesperson is acceptable, such as corporate training, internal explainers, or generic product walkthroughs, avatars compete with filming.
——————————————————————————————————————-
How to cite this framework
The 4-Layer Model originates in the State of AI Dubbing 2026 report by the Perso Dubbing Data Team, released June 4, 2026 under Creative Commons Attribution 4.0. The framework is free to share, cite, and re-use with attribution.
APA citation: Perso Dubbing Data Team. (2026). State of AI Dubbing 2026: A Multi-Vertical Analysis of Perso Dubbing's Professional Creator Data. Perso Dubbing. https://perso.ai/research/state-of-ai-dubbing-2026/
The full report — including the Use Case Map (Industry × Target Language across 112,797 categorized projects), three counterintuitive findings, and methodology notes — is available at the URL above. Supporting CSV data for every percentage in this article is published alongside the report.
This article is Part 1 of a 3-part series. Part 2 — AI Dubbing Statistics 2026 — covers 30+ key findings from the report. Part 3 — Why 99% of Creators Stop at 1 Language — analyzes the multi-language adoption frontier.
Last updated: June 2026
Continue Reading
Browse All



