Traducción de voz en off: guía completa para videos multilingües
Última actualización


Ir a la sección
Ir a la sección
Compartir
Compartir
Compartir

Herramienta de Traducción de Video AI, Localización y Doblaje
Pruébalo gratis
Respuesta corta. La traducción de voz superpuesta es el flujo de trabajo que toma una voz superpuesta existente —narración, audio explicativo o comentario grabado— y produce la misma voz superpuesta en otro idioma. La traducción de voz superpuesta impulsada por IA gestiona tres pasos de forma automática: reconocimiento de voz, traducción y síntesis en el idioma de destino. Con Perso AI, puedes traducir en más de 99 idiomas y clonar la voz del hablante original para que el nuevo idioma suene como la misma persona.
¿Qué es la traducción de voz superpuesta?
La traducción de voz superpuesta convierte una voz superpuesta grabada de un idioma a otro. La entrada es audio —a veces adjunto a un video, a veces independiente— y la salida es audio en un idioma diferente, listo para su distribución.
La categoría es más antigua que la IA. Los estudios han hecho esto manualmente durante décadas: contratar a un actor de voz en el idioma de destino, entregarle un guion traducido, grabar y volver a mezclarlo en el video. El cuello de botella siempre fue el costo y el tiempo. Un video explicativo de 5 minutos en tres idiomas solía significar tres sesiones de estudio, tres actores de voz y una semana de plazo de entrega.
La IA cambió el flujo de trabajo sin cambiar el objetivo. El resultado sigue siendo una voz superpuesta en otro idioma. El camino hacia ese resultado ahora toma minutos en lugar de semanas.
Tres categorías de trabajo encajan bajo la traducción de voz superpuesta:
La primera es la narración localizada —videos explicativos, cursos de aprendizaje en línea, narración de documentales, capítulos de audiolibros. El original es una sola voz en toda la producción. El resultado traducido mantiene la misma voz o la sustituye por un equivalente en el idioma de destino.
La segunda es el doblaje de diálogos —cine, series, contenido de entrevistas donde es necesario traducir a múltiples hablantes por separado. La traducción de voz superpuesta es la herramienta clave aquí, aunque la industria lo llame "doblaje" una vez que pasa al territorio de múltiples hablantes.
La tercera es el audio de interfaz —menús de IVR, voces de incorporación de aplicaciones, narración integrada en el producto. Un alcance menor, pero con el mismo proceso de traducción y síntesis por debajo.
El resto de esta guía se centra en las dos primeras. La tercera sigue el mismo flujo de trabajo a menor escala.
Traducción de voz superpuesta vs. doblaje, ¿son lo mismo?
En su mayoría, sí. La distinción es más antigua que el flujo de trabajo de la IA y nunca ha sido del todo clara.
Uso de la industria:
La traducción de voz superpuesta generalmente se refiere a contenido de estilo narrativo. Un solo hablante. Documental. Video explicativo. Audiolibro. La voz superpuesta se coloca sobre el video en lugar de sincronizarse con el movimiento de la boca.
El doblaje generalmente se refiere a diálogos. Múltiples hablantes. La sincronización de labios importa. El cine y las series recurren por defecto a este término.
La línea es difusa en la práctica. Un creador que narra un video de YouTube y quiere el mismo video en español, ¿es eso traducción de voz superpuesta o doblaje? Ambos términos funcionan. El flujo de trabajo es idéntico: entrada de voz → traducción → salida de voz → mezcla en el video.
Si buscas una regla clara: piensa en la traducción de voz superpuesta como la categoría más amplia, y en el doblaje como el caso en el que la alineación de la sincronización de labios es parte del entregable. Ambos funcionan con el mismo proceso de IA. El modelo de 4 capas de medios de IA enmarca esto como la Capa 4 —la capa de distribución— independientemente del término de la industria que utilices.
El resto de esta guía utiliza "traducción de voz superpuesta" como término general. Cuando la sincronización de labios sea importante, lo señalaremos.
Cómo funciona la traducción de voz superpuesta impulsada por IA
El proceso consta de cuatro pasos. Cada uno se ejecuta en segundos o pocos minutos para el contenido típico.
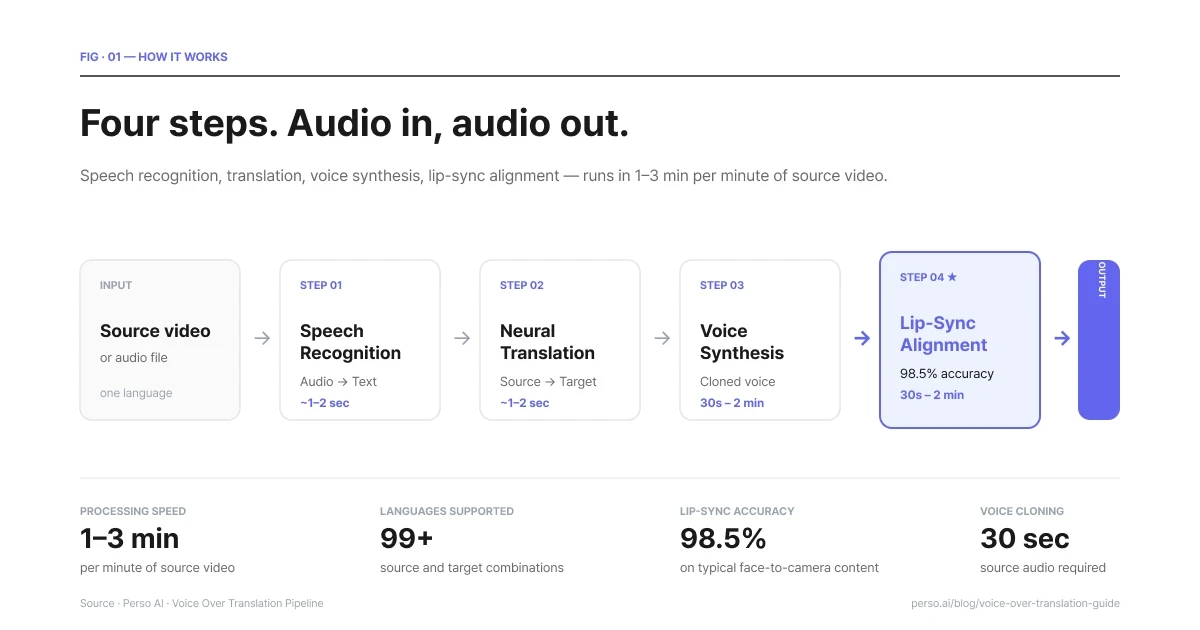
Cuatro pasos. Entrada de audio, salida de audio. De 1 a 3 minutos por cada minuto de video de origen.
Paso 1 — Reconocimiento de voz. El sistema transcribe el audio de origen a texto. El reconocimiento de voz moderno maneja acentos, música de fondo, múltiples hablantes y patrones de habla naturales (palabras de relleno, pausas, comienzos en falso). La transcripción es la base de cada paso posterior, por lo que la precisión aquí importa más de lo que la gente cree. Una transcripción deficiente produce una traducción deficiente, lo que a su vez genera una voz superpuesta de mala calidad.
Paso 2 — Traducción. La transcripción pasa por una traducción neuronal ajustada para el lenguaje hablado en lugar de la prosa escrita. El lenguaje hablado es más corto, más idiomático y depende más del contexto que el texto escrito. Un modelo de traducción que funciona bien con documentos puede funcionar mal con el habla, y viceversa. El resultado es un guion en el idioma de destino sincronizado para adaptarse al ritmo del original lo más fielmente posible.
Paso 3 — Síntesis de voz. El guion traducido se sintetiza en voz. Existen dos caminos aquí.
El primero son las voces de catálogo —elige una voz de una biblioteca y utilízala. Es rápido y libre de problemas de licencia, pero la nueva voz no se parecerá en nada al hablante original.
El segundo es la clonación de voz —entrena un modelo con la voz del hablante original y sintetiza el idioma de destino con esa misma voz. El resultado suena como si la misma persona hablara el nuevo idioma. Esto es lo que buscan la mayoría de los flujos de trabajo profesionales de traducción de voz superpuesta.
Paso 4 — Sincronización de labios (cuando hay video involucrado). Si la entrada es un video, el audio sintetizado se alinea con los movimientos originales de la boca. Los sistemas modernos logran una precisión cercana al 98% para el contenido típico. Sin este paso, la nueva voz se reproduce sobre movimientos de la boca sincronizados con el idioma original, lo que la mayoría de los espectadores encuentra incómodo en cuestión de segundos.
Perso AI ejecuta todo este proceso como un único flujo de trabajo. Sube el video, elige los idiomas de destino y recibe el video terminado. El tiempo total de procesamiento es de aproximadamente 1 a 3 minutos por cada minuto de video de origen (un video de 5 minutos se traduce en unos 5 a 15 minutos).
Cuándo se necesita la traducción de voz superpuesta
La decisión rara vez es "¿necesito traducción?" (eso suele ser obvio a partir del caso de negocio). La pregunta es qué formato de traducción elegir.
La traducción de voz superpuesta tiene sentido cuando:
El contenido es video y tu audiencia consume video. Los subtítulos funcionan para algunas audiencias, pero los datos de tiempo de visualización muestran de manera constante que los videos doblados superan a los subtitulados para los hablantes no nativos. El informe State of AI Dubbing 2026 reveló que el 96% de los videos doblados con IA se compartieron el mismo día en que se produjeron, la huella de comportamiento de un contenido diseñado para la distribución, no para el archivo.
Tienes una voz y una marca existentes. La voz de un creador es parte de su marca. El narrador de una empresa es parte de su identidad. La traducción de voz superpuesta con clonación de voz mantiene esa identidad intacta en todos los idiomas. Los flujos de trabajo con subtítulos la pierden.
Tu audiencia prioriza los dispositivos móviles o se distrae con facilidad. El contenido subtitulado requiere una atención visual absoluta. La traducción de voz superpuesta se puede escuchar en el auto, mientras se cocina o mientras se trabaja. Los mercados que priorizan los dispositivos móviles (India, Sudeste Asiático, América Latina) tienden a preferir el contenido doblado por esta razón.
Estás enviando contenido a múltiples mercados a la vez. La producción de subtítulos escala de manera lineal: cada nuevo idioma representa otra ronda de sincronización, formato e incrustación de subtítulos. La traducción de voz superpuesta escala de manera sublineal: una vez que el proceso está configurado, agregar un sexto o séptimo idioma cuesta minutos de procesamiento informático en lugar de días de edición.
La traducción de voz superpuesta tiene menos sentido cuando:
La audiencia prefiere subtítulos. El público japonés que ve cine extranjero es el ejemplo clásico. Algunos nichos eligen los subtítulos por defecto, independientemente del costo. Haz pruebas antes de darlo por sentado.
El video es lo suficientemente corto como para que la producción de subtítulos sea trivial. Un clip de 60 segundos para redes sociales podría no justificar un flujo de trabajo de voz superpuesta.
La voz superpuesta en sí misma es el contenido. Un narrador famoso, la interpretación específica de un actor, una grabación en vivo donde la voz es el recurso principal —reemplazarla con una traducción cambia la esencia de lo que se entrega. En estos casos, los subtítulos preservan el recurso original.
Traducción de voz superpuesta vs. subtítulos, elección del formato adecuado
Los subtítulos y la traducción de voz superpuesta responden a la misma pregunta de negocio —cómo llegar a los hablantes de otro idioma— pero producen experiencias de visualización diferentes.

Subtítulos vs. traducción de voz superpuesta — cuándo gana cada formato.
Dimensión | Subtítulos | Traducción de voz superpuesta |
|---|---|---|
Costo por idioma | Bajo (principalmente tiempo de edición) | Medio (procesamiento + licencias de voz) |
Tiempo por idioma | Horas | Minutos (impulsado por IA) |
Experiencia del espectador | Requiere lectura | Escucha en idioma nativo |
Uso móvil / con distracciones | Limitado | Funciona |
Preservación de la voz de marca | Sí (se conserva el audio original) | Sí (con clonación de voz) |
Accesibilidad (sordos / personas con dificultades auditivas) | ✅ Esencial | Necesita una pista de subtítulos independiente |
Ideal para | Clips cortos, audiencias de nicho | Video completo a escala |
En la práctica, la mayoría de los flujos de trabajo modernos producen ambos: traducción de voz superpuesta como formato principal y subtítulos como pista de accesibilidad. Las plataformas de doblaje con IA suelen ofrecer ambos formatos a partir del mismo proceso, ya que la transcripción y la traducción ya se han realizado en los pasos 1 y 2.
Cómo traducir una voz superpuesta con IA (paso a paso)
Los pasos siguientes describen el flujo de trabajo en Perso AI. Otras plataformas difieren en la interfaz pero siguen la misma lógica.
1. Sube el origen. Arrastra el archivo de video o audio. La mayoría de las plataformas aceptan MP4, MOV, MP3, WAV. Si el origen es un enlace de YouTube, pega la URL.
2. Elige los idiomas de destino. Elige uno o varios. Perso AI admite más de 99 idiomas en combinaciones de origen y destino. Las elecciones habituales por primera vez son: español, portugués, francés, alemán, japonés y coreano.
3. Revisa la transcripción automática. El sistema muestra la transcripción en el idioma de origen. Corrige cualquier error de reconocimiento de voz antes de que se ejecute el paso de traducción; cada corrección aquí beneficia los pasos posteriores.
4. Edita la traducción (opcional). Revisa el guion en el idioma de destino antes de que se ejecute la síntesis de voz. Corrige modismos, nombres de marca y términos técnicos. En este paso es donde los equipos detectan el tipo de problemas que son casi imposibles de corregir más adelante.
5. Genera el resultado. Se ejecutan la síntesis de voz y la alineación de sincronización de labios. El procesamiento toma aproximadamente de 1 a 3 minutos por cada minuto de video de origen (un video de 5 minutos se genera en unos 5 a 15 minutos).
6. Descarga o comparte. El resultado final son archivos de video MP4 terminados por idioma, además de pistas de subtítulos (.srt) para accesibilidad. Algunas plataformas también exportan audio MP3 si solo deseas la voz superpuesta sin video.
Toda la secuencia es un único flujo de trabajo en una sola plataforma. Los datos de comportamiento del informe State of AI Dubbing 2026 —con una tasa de compartición del 96% el mismo día— provienen de este tipo de configuración de flujo de trabajo único, no de un traspaso manual entre herramientas separadas.
Calidad de la traducción de voz superpuesta: qué tener en cuenta
La calidad consta de tres componentes. Los tres son importantes, y el más débil define la percepción general del resultado.
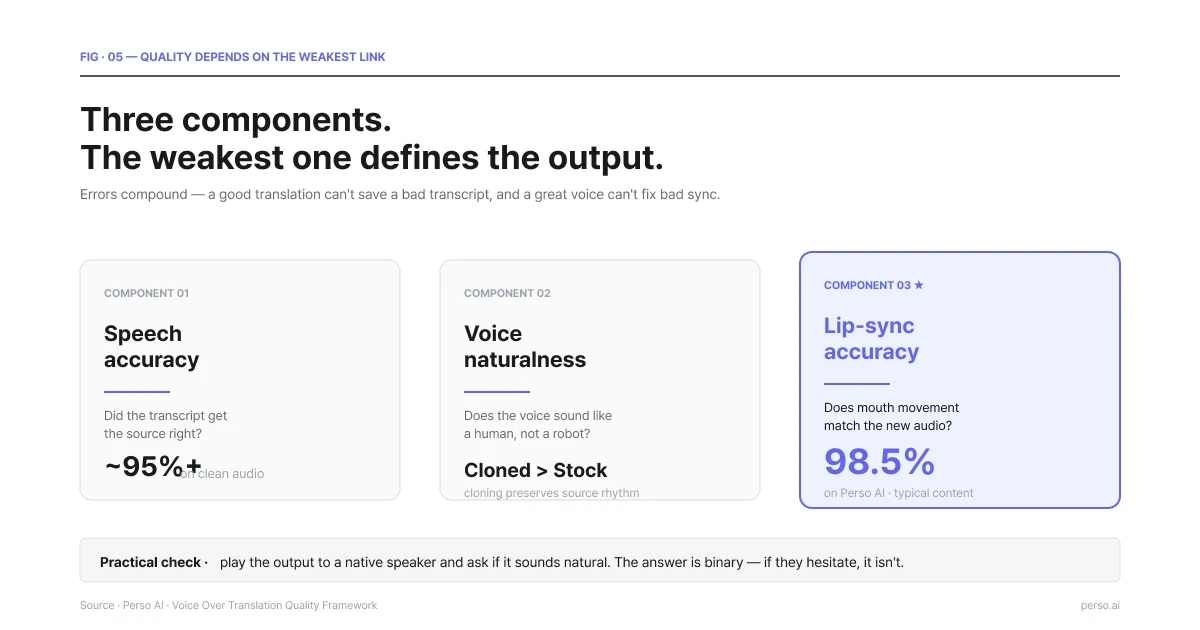
Tres componentes. El más débil define el resultado.
Precisión del habla. ¿Dice la voz superpuesta traducida lo mismo que el origen? Las traducciones erróneas de nombres de marcas, términos técnicos o frases específicas del sector son los fallos más comunes. Mitigación: revisa el guion traducido antes de generar la síntesis de voz.
Naturalidad de la voz. ¿Suena la voz como un ser humano hablando el idioma o como un robot leyendo un guion? Las voces modernas de IA han cerrado casi por completo esta brecha, pero no es inexistente. Presta atención a la entonación, el ritmo de las frases y la duración de las pausas naturales. La clonación de voz del hablante original suele superar a las voces de catálogo en esta dimensión porque el modelo cuenta con el ritmo natural de la fuente para trabajar.
Precisión de la sincronización de labios (solo video). ¿Coincide el movimiento de la boca con el nuevo audio? Perso AI reporta un 98.5% de precisión en la sincronización de labios en todo su proceso, una de las cifras públicas más altas reveladas en esta categoría. La diferencia del 1.5% es más visible en el contenido de primeros planos de cara a la cámara. En planos generales, la sensibilidad a la sincronización de labios disminuye porque la boca se ve más pequeña en el encuadre.
Un control de calidad práctico: reproduce el resultado ante un hablante nativo del idioma de destino y pregúntale si suena natural. La respuesta es binaria. Si duda, no lo es.
Idiomas habituales en la traducción de voz superpuesta
La demanda no se distribuye de manera uniforme. Los datos de Perso AI, que abarcan 316,856 proyectos de doblaje y 4,023 creadores profesionales, muestran cuáles son los principales idiomas de destino hacia los que se dirige realmente el contenido global.
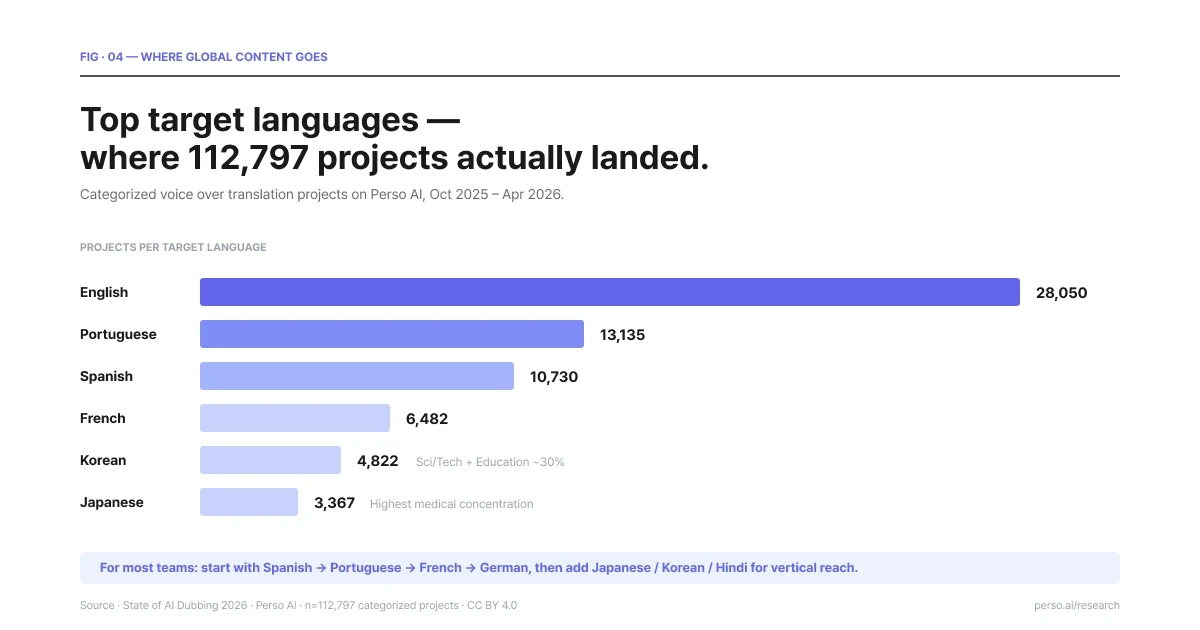
Principales idiomas de destino — adónde llegaron en realidad 112,797 proyectos de traducción de voz superpuesta. Fuente: State of AI Dubbing 2026.
El inglés domina como idioma de destino (28,050 proyectos categorizados) pero es el más horizontal: ningún sector supera el 14% de la producción destinada al inglés. El inglés es el idioma de salida predeterminado para los creadores no anglófonos.
El portugués (13,135 proyectos) es el mercado más equilibrado en cuanto a sectores, con animación, religión y educación en torno al 10% o más cada uno. El portugués de Brasil, en particular, es el segundo centro neurálgico del contenido religioso junto con el inglés —el informe State of AI Dubbing 2026 documentó una paridad casi absoluta entre el inglés (25.6%) y el portugués (25.2%) en los proyectos de religión, un dato que sorprendió a todos los que asumían que el español era el valor predeterminado de la fe en Latinoamérica.
El español (10,730 proyectos) lidera en los sectores de educación y religión, dominando en toda América Latina.
El coreano (4,822 proyectos) presenta un comportamiento inusual: el 30% del volumen con destino al coreano corresponde a sectores de conocimiento (ciencia/tecnología y educación combinados). Los datos coinciden con la expansión del contenido coreano hacia sectores adyacentes más allá del entretenimiento.
El japonés (3,367 projects) muestra la mayor concentración médica entre los principales mercados de destino —la educación al paciente y el contenido de salud se localizan en japonés en una proporción muy elevada.
El francés (6,482 proyectos) está liderado por los documentales, lo que es coherente con la consolidada tradición de producción de documentales en Francia.
Para los proyectos de traducción de voz superpuesta que se realizan por primera vez, el orden de preferencia predeterminado más práctico es: español → portugués → francés → alemán para un alcance de audiencia generalizado, y después añadir japonés → coreano → hindi → árabe para la expansión sectorial o regional.
Costo de la traducción de voz superpuesta — IA vs. humanos
La diferencia de costos entre la traducción de voz superpuesta por IA y la realizada por humanos constituye el mayor cambio que ha experimentado esta categoría.
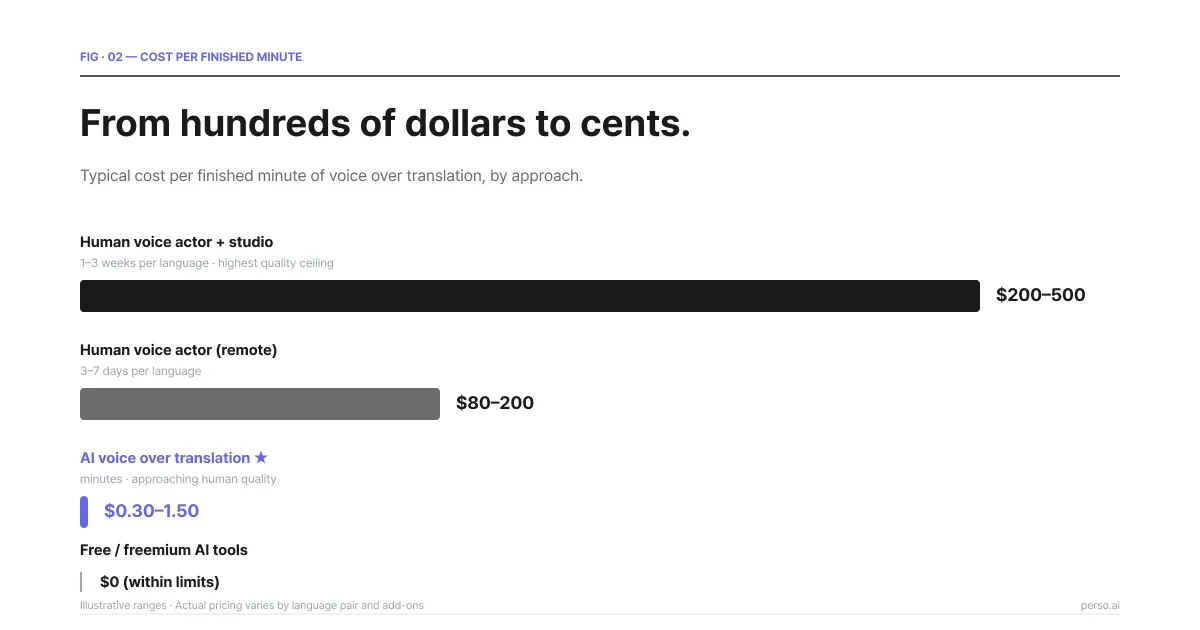
Costo por minuto finalizado según el enfoque. La voz superpuesta por IA es aproximadamente 100 veces más barata que la humana con calidad de estudio.
Enfoque | Costo típico | Plazo de entrega | Límite máximo de calidad |
|---|---|---|---|
Actor de voz humano + estudio | $200–$500 por minuto terminado | 1–3 semanas por idioma | El más alto |
Actor de voz humano (remoto) | $80–$200 por minuto terminado | 3–7 días por idioma | Alto |
Traducción de voz superpuesta con IA | $0.30–$1.50 por minuto terminado | Minutos | Se aproxima al nivel humano en la mayoría de los aspectos |
Herramientas de IA gratuitas / freemium | $0 dentro de los límites | Minutos | Variable, con imperfecciones a menudo perceptibles |
Las cifras anteriores son ilustrativas; las tarifas reales varían según el par de idiomas, los complementos de clonación de voz y la plataforma. El modelo de facturación por segundos de Perso AI factura únicamente por la duración real del audio generado, por lo que un clip de 30 segundos se factura por 30 segundos en lugar de redondearse a un minuto como lo harían la mayoría de los modelos basados en minutos.
La diferencia de costos es más importante para los proyectos de varios idiomas que para los de uno solo. Pasar de uno a diez idiomas con actores de voz humanos multiplica el costo por 10. Con la traducción de voz superpuesta por IA, pasar de uno a diez idiomas duplica aproximadamente el costo (cada idioma añade procesamiento, pero la mayoría de los gastos fijos son estables). Esta es la hipótesis sobre la incorporación de idiomas del informe State of AI Dubbing 2026: la mayoría de los creadores se limitan a un solo idioma porque añadir más resulta caro, y los flujos de trabajo de IA cambian esa realidad financiera.
En el caso de contenidos de categoría superior en los que los matices de la voz constituyen el producto final —largometrajes, juegos AAA, documentales de prestigio—, los actores de voz humanos siguen marcando el nivel de calidad más alto. Para el resto de contenidos, la traducción de voz superpuesta con IA es ya la opción predeterminada para los nuevos proyectos.
————————————————————————-
Preguntas frecuentes
P. ¿Es la traducción de voz superpuesta lo mismo que el doblaje?
En gran medida, sí. La traducción de voz superpuesta es la categoría general; el doblaje suele referirse al caso con mayor volumen de diálogo, en el que la alineación de la sincronización de labios forma parte de la entrega. Ambos funcionan con el mismo proceso de IA: reconocimiento de voz, traducción, síntesis de voz y (para video) alineación de la sincronización de labios.
P. ¿Puede la IA clonar mi voz para la traducción de voz superpuesta?
Sí. Las plataformas modernas de traducción de voz superpuesta con IA admiten la clonación de voz. Una muestra de 30 segundos de audio original limpio suele ser suficiente. La voz clonada hablará todos los idiomas de destino de tu proyecto, por lo que parecerá que la misma persona realiza la narración en español, japonés, alemán, etc.
P. ¿Qué grado de precisión tiene la traducción de voz superpuesta por IA?
Tres valores de precisión son fundamentales: el reconocimiento de voz (~95%+ en audios limpios), la traducción (depende en gran medida del par de idiomas, siendo los pares europeos más precisos que los de idiomas minoritarios) y la sincronización de labios (~98.5% en Perso AI para contenidos habituales). Los errores se acumulan, por lo que el paso más débil determina la calidad del resultado final.
P. ¿Cuánto tiempo tarda la traducción de voz superpuesta por IA?
Aproximadamente de 1 a 3 minutos por cada minuto de video de origen. Un video de 5 minutos se traduce en unos 5 a 15 (minutos) para un solo idioma de destino. Los proyectos de varios idiomas escalan de forma sublineal: traducir a 5 idiomas requiere un tiempo total más cercano a los 5 minutos que a los 5×3 minutos.
P. ¿Puedo editar la traducción antes de que se genere la voz?
Sí, en la mayoría de las plataformas profesionales. El guion traducido se muestra después del paso de traducción y antes de que se ejecute la síntesis de voz. Corregir nombres de marcas, términos técnicos y modismos en esta fase es sustancialmente más fácil que corregir el audio a posteriori.
P. ¿Cuál es la diferencia entre la traducción de voz superpuesta y la simple incorporación de subtítulos?
Los subtítulos se leen; la traducción de voz superpuesta se escucha. Los subtítulos conservan el audio original y añaden una pista de texto en el idioma de destino. La traducción de voz superpuesta sustituye el audio por el idioma de destino. La mayoría de los flujos de trabajo de IA modernos producen ambos formatos: la voz superpuesta como entrega principal y los subtítulos como pista de accesibilidad generada a partir de la misma transcripción.
P. ¿Funciona la traducción de voz superpuesta para contenidos en vivo?
Actualmente no; la traducción de voz superpuesta es un flujo de trabajo de posproducción. El doblaje en tiempo real con IA para transmisiones en directo es una categoría emergente y el informe State of AI Dubbing 2026 lo identificó como uno de los tres cambios que se prevé que lleguen a los productos de consumo a finales de 2026 / 2027. Por ahora, considera la traducción de voz superpuesta como un paso de posproducción para el mismo día, y no como un proceso en directo.
P. ¿A cuántos idiomas debo traducir mi contenido?
El informe State of AI Dubbing 2026 determinó que el creador profesional promedio en Perso AI realiza doblajes a 1 idioma, mientras que el 1% superior alcanza una media de 15. La brecha de expansión existe porque la mayoría de los creadores dejan la adopción de idiomas de lado, incluso cuando su contenido podría tener difusión. Una primera fase de expansión práctica: de 3 a 5 idiomas que cubran tus mercados de origen no principales. Amplía a partir de ahí basándote en los datos de tiempo de visualización por idioma.
Primeros pasos
Si deseas probar la traducción de voz superpuesta en un video existente, el camino más rápido es subir un archivo de origen y ver el resultado en 2 o 3 idiomas de destino. La mayoría de las plataformas profesionales ofrecen planes gratuitos para este tipo de evaluación.
Para conocer una plataforma única que gestione todo el flujo de trabajo —reconocimiento de voz, traducción, clonación de voz y sincronización de labios— visita el traductor de video de Perso AI o realiza una comparación en el centro de alternativas si estás evaluando varias opciones.
La totalidad de los datos que respaldan cada estadística de esta guía se encuentra publicada en el informe State of AI Dubbing 2026, publicado bajo la licencia Creative Commons Atribución 4.0.
Respuesta corta. La traducción de voz superpuesta es el flujo de trabajo que toma una voz superpuesta existente —narración, audio explicativo o comentario grabado— y produce la misma voz superpuesta en otro idioma. La traducción de voz superpuesta impulsada por IA gestiona tres pasos de forma automática: reconocimiento de voz, traducción y síntesis en el idioma de destino. Con Perso AI, puedes traducir en más de 99 idiomas y clonar la voz del hablante original para que el nuevo idioma suene como la misma persona.
¿Qué es la traducción de voz superpuesta?
La traducción de voz superpuesta convierte una voz superpuesta grabada de un idioma a otro. La entrada es audio —a veces adjunto a un video, a veces independiente— y la salida es audio en un idioma diferente, listo para su distribución.
La categoría es más antigua que la IA. Los estudios han hecho esto manualmente durante décadas: contratar a un actor de voz en el idioma de destino, entregarle un guion traducido, grabar y volver a mezclarlo en el video. El cuello de botella siempre fue el costo y el tiempo. Un video explicativo de 5 minutos en tres idiomas solía significar tres sesiones de estudio, tres actores de voz y una semana de plazo de entrega.
La IA cambió el flujo de trabajo sin cambiar el objetivo. El resultado sigue siendo una voz superpuesta en otro idioma. El camino hacia ese resultado ahora toma minutos en lugar de semanas.
Tres categorías de trabajo encajan bajo la traducción de voz superpuesta:
La primera es la narración localizada —videos explicativos, cursos de aprendizaje en línea, narración de documentales, capítulos de audiolibros. El original es una sola voz en toda la producción. El resultado traducido mantiene la misma voz o la sustituye por un equivalente en el idioma de destino.
La segunda es el doblaje de diálogos —cine, series, contenido de entrevistas donde es necesario traducir a múltiples hablantes por separado. La traducción de voz superpuesta es la herramienta clave aquí, aunque la industria lo llame "doblaje" una vez que pasa al territorio de múltiples hablantes.
La tercera es el audio de interfaz —menús de IVR, voces de incorporación de aplicaciones, narración integrada en el producto. Un alcance menor, pero con el mismo proceso de traducción y síntesis por debajo.
El resto de esta guía se centra en las dos primeras. La tercera sigue el mismo flujo de trabajo a menor escala.
Traducción de voz superpuesta vs. doblaje, ¿son lo mismo?
En su mayoría, sí. La distinción es más antigua que el flujo de trabajo de la IA y nunca ha sido del todo clara.
Uso de la industria:
La traducción de voz superpuesta generalmente se refiere a contenido de estilo narrativo. Un solo hablante. Documental. Video explicativo. Audiolibro. La voz superpuesta se coloca sobre el video en lugar de sincronizarse con el movimiento de la boca.
El doblaje generalmente se refiere a diálogos. Múltiples hablantes. La sincronización de labios importa. El cine y las series recurren por defecto a este término.
La línea es difusa en la práctica. Un creador que narra un video de YouTube y quiere el mismo video en español, ¿es eso traducción de voz superpuesta o doblaje? Ambos términos funcionan. El flujo de trabajo es idéntico: entrada de voz → traducción → salida de voz → mezcla en el video.
Si buscas una regla clara: piensa en la traducción de voz superpuesta como la categoría más amplia, y en el doblaje como el caso en el que la alineación de la sincronización de labios es parte del entregable. Ambos funcionan con el mismo proceso de IA. El modelo de 4 capas de medios de IA enmarca esto como la Capa 4 —la capa de distribución— independientemente del término de la industria que utilices.
El resto de esta guía utiliza "traducción de voz superpuesta" como término general. Cuando la sincronización de labios sea importante, lo señalaremos.
Cómo funciona la traducción de voz superpuesta impulsada por IA
El proceso consta de cuatro pasos. Cada uno se ejecuta en segundos o pocos minutos para el contenido típico.
Cuatro pasos. Entrada de audio, salida de audio. De 1 a 3 minutos por cada minuto de video de origen.
Paso 1 — Reconocimiento de voz. El sistema transcribe el audio de origen a texto. El reconocimiento de voz moderno maneja acentos, música de fondo, múltiples hablantes y patrones de habla naturales (palabras de relleno, pausas, comienzos en falso). La transcripción es la base de cada paso posterior, por lo que la precisión aquí importa más de lo que la gente cree. Una transcripción deficiente produce una traducción deficiente, lo que a su vez genera una voz superpuesta de mala calidad.
Paso 2 — Traducción. La transcripción pasa por una traducción neuronal ajustada para el lenguaje hablado en lugar de la prosa escrita. El lenguaje hablado es más corto, más idiomático y depende más del contexto que el texto escrito. Un modelo de traducción que funciona bien con documentos puede funcionar mal con el habla, y viceversa. El resultado es un guion en el idioma de destino sincronizado para adaptarse al ritmo del original lo más fielmente posible.
Paso 3 — Síntesis de voz. El guion traducido se sintetiza en voz. Existen dos caminos aquí.
El primero son las voces de catálogo —elige una voz de una biblioteca y utilízala. Es rápido y libre de problemas de licencia, pero la nueva voz no se parecerá en nada al hablante original.
El segundo es la clonación de voz —entrena un modelo con la voz del hablante original y sintetiza el idioma de destino con esa misma voz. El resultado suena como si la misma persona hablara el nuevo idioma. Esto es lo que buscan la mayoría de los flujos de trabajo profesionales de traducción de voz superpuesta.
Paso 4 — Sincronización de labios (cuando hay video involucrado). Si la entrada es un video, el audio sintetizado se alinea con los movimientos originales de la boca. Los sistemas modernos logran una precisión cercana al 98% para el contenido típico. Sin este paso, la nueva voz se reproduce sobre movimientos de la boca sincronizados con el idioma original, lo que la mayoría de los espectadores encuentra incómodo en cuestión de segundos.
Perso AI ejecuta todo este proceso como un único flujo de trabajo. Sube el video, elige los idiomas de destino y recibe el video terminado. El tiempo total de procesamiento es de aproximadamente 1 a 3 minutos por cada minuto de video de origen (un video de 5 minutos se traduce en unos 5 a 15 minutos).
Cuándo se necesita la traducción de voz superpuesta
La decisión rara vez es "¿necesito traducción?" (eso suele ser obvio a partir del caso de negocio). La pregunta es qué formato de traducción elegir.
La traducción de voz superpuesta tiene sentido cuando:
El contenido es video y tu audiencia consume video. Los subtítulos funcionan para algunas audiencias, pero los datos de tiempo de visualización muestran de manera constante que los videos doblados superan a los subtitulados para los hablantes no nativos. El informe State of AI Dubbing 2026 reveló que el 96% de los videos doblados con IA se compartieron el mismo día en que se produjeron, la huella de comportamiento de un contenido diseñado para la distribución, no para el archivo.
Tienes una voz y una marca existentes. La voz de un creador es parte de su marca. El narrador de una empresa es parte de su identidad. La traducción de voz superpuesta con clonación de voz mantiene esa identidad intacta en todos los idiomas. Los flujos de trabajo con subtítulos la pierden.
Tu audiencia prioriza los dispositivos móviles o se distrae con facilidad. El contenido subtitulado requiere una atención visual absoluta. La traducción de voz superpuesta se puede escuchar en el auto, mientras se cocina o mientras se trabaja. Los mercados que priorizan los dispositivos móviles (India, Sudeste Asiático, América Latina) tienden a preferir el contenido doblado por esta razón.
Estás enviando contenido a múltiples mercados a la vez. La producción de subtítulos escala de manera lineal: cada nuevo idioma representa otra ronda de sincronización, formato e incrustación de subtítulos. La traducción de voz superpuesta escala de manera sublineal: una vez que el proceso está configurado, agregar un sexto o séptimo idioma cuesta minutos de procesamiento informático en lugar de días de edición.
La traducción de voz superpuesta tiene menos sentido cuando:
La audiencia prefiere subtítulos. El público japonés que ve cine extranjero es el ejemplo clásico. Algunos nichos eligen los subtítulos por defecto, independientemente del costo. Haz pruebas antes de darlo por sentado.
El video es lo suficientemente corto como para que la producción de subtítulos sea trivial. Un clip de 60 segundos para redes sociales podría no justificar un flujo de trabajo de voz superpuesta.
La voz superpuesta en sí misma es el contenido. Un narrador famoso, la interpretación específica de un actor, una grabación en vivo donde la voz es el recurso principal —reemplazarla con una traducción cambia la esencia de lo que se entrega. En estos casos, los subtítulos preservan el recurso original.
Traducción de voz superpuesta vs. subtítulos, elección del formato adecuado
Los subtítulos y la traducción de voz superpuesta responden a la misma pregunta de negocio —cómo llegar a los hablantes de otro idioma— pero producen experiencias de visualización diferentes.
Subtítulos vs. traducción de voz superpuesta — cuándo gana cada formato.
Dimensión | Subtítulos | Traducción de voz superpuesta |
|---|---|---|
Costo por idioma | Bajo (principalmente tiempo de edición) | Medio (procesamiento + licencias de voz) |
Tiempo por idioma | Horas | Minutos (impulsado por IA) |
Experiencia del espectador | Requiere lectura | Escucha en idioma nativo |
Uso móvil / con distracciones | Limitado | Funciona |
Preservación de la voz de marca | Sí (se conserva el audio original) | Sí (con clonación de voz) |
Accesibilidad (sordos / personas con dificultades auditivas) | ✅ Esencial | Necesita una pista de subtítulos independiente |
Ideal para | Clips cortos, audiencias de nicho | Video completo a escala |
En la práctica, la mayoría de los flujos de trabajo modernos producen ambos: traducción de voz superpuesta como formato principal y subtítulos como pista de accesibilidad. Las plataformas de doblaje con IA suelen ofrecer ambos formatos a partir del mismo proceso, ya que la transcripción y la traducción ya se han realizado en los pasos 1 y 2.
Cómo traducir una voz superpuesta con IA (paso a paso)
Los pasos siguientes describen el flujo de trabajo en Perso AI. Otras plataformas difieren en la interfaz pero siguen la misma lógica.
1. Sube el origen. Arrastra el archivo de video o audio. La mayoría de las plataformas aceptan MP4, MOV, MP3, WAV. Si el origen es un enlace de YouTube, pega la URL.
2. Elige los idiomas de destino. Elige uno o varios. Perso AI admite más de 99 idiomas en combinaciones de origen y destino. Las elecciones habituales por primera vez son: español, portugués, francés, alemán, japonés y coreano.
3. Revisa la transcripción automática. El sistema muestra la transcripción en el idioma de origen. Corrige cualquier error de reconocimiento de voz antes de que se ejecute el paso de traducción; cada corrección aquí beneficia los pasos posteriores.
4. Edita la traducción (opcional). Revisa el guion en el idioma de destino antes de que se ejecute la síntesis de voz. Corrige modismos, nombres de marca y términos técnicos. En este paso es donde los equipos detectan el tipo de problemas que son casi imposibles de corregir más adelante.
5. Genera el resultado. Se ejecutan la síntesis de voz y la alineación de sincronización de labios. El procesamiento toma aproximadamente de 1 a 3 minutos por cada minuto de video de origen (un video de 5 minutos se genera en unos 5 a 15 minutos).
6. Descarga o comparte. El resultado final son archivos de video MP4 terminados por idioma, además de pistas de subtítulos (.srt) para accesibilidad. Algunas plataformas también exportan audio MP3 si solo deseas la voz superpuesta sin video.
Toda la secuencia es un único flujo de trabajo en una sola plataforma. Los datos de comportamiento del informe State of AI Dubbing 2026 —con una tasa de compartición del 96% el mismo día— provienen de este tipo de configuración de flujo de trabajo único, no de un traspaso manual entre herramientas separadas.
Calidad de la traducción de voz superpuesta: qué tener en cuenta
La calidad consta de tres componentes. Los tres son importantes, y el más débil define la percepción general del resultado.
Tres componentes. El más débil define el resultado.
Precisión del habla. ¿Dice la voz superpuesta traducida lo mismo que el origen? Las traducciones erróneas de nombres de marcas, términos técnicos o frases específicas del sector son los fallos más comunes. Mitigación: revisa el guion traducido antes de generar la síntesis de voz.
Naturalidad de la voz. ¿Suena la voz como un ser humano hablando el idioma o como un robot leyendo un guion? Las voces modernas de IA han cerrado casi por completo esta brecha, pero no es inexistente. Presta atención a la entonación, el ritmo de las frases y la duración de las pausas naturales. La clonación de voz del hablante original suele superar a las voces de catálogo en esta dimensión porque el modelo cuenta con el ritmo natural de la fuente para trabajar.
Precisión de la sincronización de labios (solo video). ¿Coincide el movimiento de la boca con el nuevo audio? Perso AI reporta un 98.5% de precisión en la sincronización de labios en todo su proceso, una de las cifras públicas más altas reveladas en esta categoría. La diferencia del 1.5% es más visible en el contenido de primeros planos de cara a la cámara. En planos generales, la sensibilidad a la sincronización de labios disminuye porque la boca se ve más pequeña en el encuadre.
Un control de calidad práctico: reproduce el resultado ante un hablante nativo del idioma de destino y pregúntale si suena natural. La respuesta es binaria. Si duda, no lo es.
Idiomas habituales en la traducción de voz superpuesta
La demanda no se distribuye de manera uniforme. Los datos de Perso AI, que abarcan 316,856 proyectos de doblaje y 4,023 creadores profesionales, muestran cuáles son los principales idiomas de destino hacia los que se dirige realmente el contenido global.
Principales idiomas de destino — adónde llegaron en realidad 112,797 proyectos de traducción de voz superpuesta. Fuente: State of AI Dubbing 2026.
El inglés domina como idioma de destino (28,050 proyectos categorizados) pero es el más horizontal: ningún sector supera el 14% de la producción destinada al inglés. El inglés es el idioma de salida predeterminado para los creadores no anglófonos.
El portugués (13,135 proyectos) es el mercado más equilibrado en cuanto a sectores, con animación, religión y educación en torno al 10% o más cada uno. El portugués de Brasil, en particular, es el segundo centro neurálgico del contenido religioso junto con el inglés —el informe State of AI Dubbing 2026 documentó una paridad casi absoluta entre el inglés (25.6%) y el portugués (25.2%) en los proyectos de religión, un dato que sorprendió a todos los que asumían que el español era el valor predeterminado de la fe en Latinoamérica.
El español (10,730 proyectos) lidera en los sectores de educación y religión, dominando en toda América Latina.
El coreano (4,822 proyectos) presenta un comportamiento inusual: el 30% del volumen con destino al coreano corresponde a sectores de conocimiento (ciencia/tecnología y educación combinados). Los datos coinciden con la expansión del contenido coreano hacia sectores adyacentes más allá del entretenimiento.
El japonés (3,367 projects) muestra la mayor concentración médica entre los principales mercados de destino —la educación al paciente y el contenido de salud se localizan en japonés en una proporción muy elevada.
El francés (6,482 proyectos) está liderado por los documentales, lo que es coherente con la consolidada tradición de producción de documentales en Francia.
Para los proyectos de traducción de voz superpuesta que se realizan por primera vez, el orden de preferencia predeterminado más práctico es: español → portugués → francés → alemán para un alcance de audiencia generalizado, y después añadir japonés → coreano → hindi → árabe para la expansión sectorial o regional.
Costo de la traducción de voz superpuesta — IA vs. humanos
La diferencia de costos entre la traducción de voz superpuesta por IA y la realizada por humanos constituye el mayor cambio que ha experimentado esta categoría.
Costo por minuto finalizado según el enfoque. La voz superpuesta por IA es aproximadamente 100 veces más barata que la humana con calidad de estudio.
Enfoque | Costo típico | Plazo de entrega | Límite máximo de calidad |
|---|---|---|---|
Actor de voz humano + estudio | $200–$500 por minuto terminado | 1–3 semanas por idioma | El más alto |
Actor de voz humano (remoto) | $80–$200 por minuto terminado | 3–7 días por idioma | Alto |
Traducción de voz superpuesta con IA | $0.30–$1.50 por minuto terminado | Minutos | Se aproxima al nivel humano en la mayoría de los aspectos |
Herramientas de IA gratuitas / freemium | $0 dentro de los límites | Minutos | Variable, con imperfecciones a menudo perceptibles |
Las cifras anteriores son ilustrativas; las tarifas reales varían según el par de idiomas, los complementos de clonación de voz y la plataforma. El modelo de facturación por segundos de Perso AI factura únicamente por la duración real del audio generado, por lo que un clip de 30 segundos se factura por 30 segundos en lugar de redondearse a un minuto como lo harían la mayoría de los modelos basados en minutos.
La diferencia de costos es más importante para los proyectos de varios idiomas que para los de uno solo. Pasar de uno a diez idiomas con actores de voz humanos multiplica el costo por 10. Con la traducción de voz superpuesta por IA, pasar de uno a diez idiomas duplica aproximadamente el costo (cada idioma añade procesamiento, pero la mayoría de los gastos fijos son estables). Esta es la hipótesis sobre la incorporación de idiomas del informe State of AI Dubbing 2026: la mayoría de los creadores se limitan a un solo idioma porque añadir más resulta caro, y los flujos de trabajo de IA cambian esa realidad financiera.
En el caso de contenidos de categoría superior en los que los matices de la voz constituyen el producto final —largometrajes, juegos AAA, documentales de prestigio—, los actores de voz humanos siguen marcando el nivel de calidad más alto. Para el resto de contenidos, la traducción de voz superpuesta con IA es ya la opción predeterminada para los nuevos proyectos.
————————————————————————-
Preguntas frecuentes
P. ¿Es la traducción de voz superpuesta lo mismo que el doblaje?
En gran medida, sí. La traducción de voz superpuesta es la categoría general; el doblaje suele referirse al caso con mayor volumen de diálogo, en el que la alineación de la sincronización de labios forma parte de la entrega. Ambos funcionan con el mismo proceso de IA: reconocimiento de voz, traducción, síntesis de voz y (para video) alineación de la sincronización de labios.
P. ¿Puede la IA clonar mi voz para la traducción de voz superpuesta?
Sí. Las plataformas modernas de traducción de voz superpuesta con IA admiten la clonación de voz. Una muestra de 30 segundos de audio original limpio suele ser suficiente. La voz clonada hablará todos los idiomas de destino de tu proyecto, por lo que parecerá que la misma persona realiza la narración en español, japonés, alemán, etc.
P. ¿Qué grado de precisión tiene la traducción de voz superpuesta por IA?
Tres valores de precisión son fundamentales: el reconocimiento de voz (~95%+ en audios limpios), la traducción (depende en gran medida del par de idiomas, siendo los pares europeos más precisos que los de idiomas minoritarios) y la sincronización de labios (~98.5% en Perso AI para contenidos habituales). Los errores se acumulan, por lo que el paso más débil determina la calidad del resultado final.
P. ¿Cuánto tiempo tarda la traducción de voz superpuesta por IA?
Aproximadamente de 1 a 3 minutos por cada minuto de video de origen. Un video de 5 minutos se traduce en unos 5 a 15 (minutos) para un solo idioma de destino. Los proyectos de varios idiomas escalan de forma sublineal: traducir a 5 idiomas requiere un tiempo total más cercano a los 5 minutos que a los 5×3 minutos.
P. ¿Puedo editar la traducción antes de que se genere la voz?
Sí, en la mayoría de las plataformas profesionales. El guion traducido se muestra después del paso de traducción y antes de que se ejecute la síntesis de voz. Corregir nombres de marcas, términos técnicos y modismos en esta fase es sustancialmente más fácil que corregir el audio a posteriori.
P. ¿Cuál es la diferencia entre la traducción de voz superpuesta y la simple incorporación de subtítulos?
Los subtítulos se leen; la traducción de voz superpuesta se escucha. Los subtítulos conservan el audio original y añaden una pista de texto en el idioma de destino. La traducción de voz superpuesta sustituye el audio por el idioma de destino. La mayoría de los flujos de trabajo de IA modernos producen ambos formatos: la voz superpuesta como entrega principal y los subtítulos como pista de accesibilidad generada a partir de la misma transcripción.
P. ¿Funciona la traducción de voz superpuesta para contenidos en vivo?
Actualmente no; la traducción de voz superpuesta es un flujo de trabajo de posproducción. El doblaje en tiempo real con IA para transmisiones en directo es una categoría emergente y el informe State of AI Dubbing 2026 lo identificó como uno de los tres cambios que se prevé que lleguen a los productos de consumo a finales de 2026 / 2027. Por ahora, considera la traducción de voz superpuesta como un paso de posproducción para el mismo día, y no como un proceso en directo.
P. ¿A cuántos idiomas debo traducir mi contenido?
El informe State of AI Dubbing 2026 determinó que el creador profesional promedio en Perso AI realiza doblajes a 1 idioma, mientras que el 1% superior alcanza una media de 15. La brecha de expansión existe porque la mayoría de los creadores dejan la adopción de idiomas de lado, incluso cuando su contenido podría tener difusión. Una primera fase de expansión práctica: de 3 a 5 idiomas que cubran tus mercados de origen no principales. Amplía a partir de ahí basándote en los datos de tiempo de visualización por idioma.
Primeros pasos
Si deseas probar la traducción de voz superpuesta en un video existente, el camino más rápido es subir un archivo de origen y ver el resultado en 2 o 3 idiomas de destino. La mayoría de las plataformas profesionales ofrecen planes gratuitos para este tipo de evaluación.
Para conocer una plataforma única que gestione todo el flujo de trabajo —reconocimiento de voz, traducción, clonación de voz y sincronización de labios— visita el traductor de video de Perso AI o realiza una comparación en el centro de alternativas si estás evaluando varias opciones.
La totalidad de los datos que respaldan cada estadística de esta guía se encuentra publicada en el informe State of AI Dubbing 2026, publicado bajo la licencia Creative Commons Atribución 4.0.
Seguir Leyendo
Explorar todo



