AIにためらいを教える方法:推論時コンピュートと熟考された翻訳の技法



AIビデオ翻訳、ローカリゼーション、および吹き替えツール
無料でお試しください
AIにためらいを教えるには
数日前、YouTubeのクリップに出会った。ニュースアンカーのSohn Suk-heeが小説家のKim Ae-ranにインタビューしていた。質問は「AIにはなくて、人間にあるものは何ですか?」で、彼女の答えは「ためらい」だった。
その小説家は、アンカーの古い放送の一場面を取り上げた。故Roh Hoe-chanという労働運動家出身の政治家の訃報を伝えている最中、彼は20秒間言葉を失った。言葉を飲み込み、揺れ、見極めること――それがためらいだ。AIにはこれができない。だが、人のためらいは慰めであり、礼節でもある。
20年ほど前、シューティングゲームの開発に集中していたころのことだ。3Dキャラクターモデリングのチームメイトが「高校の同級生が小説家なんだ。読んでみるといい」と本を渡してきた。機知に富んだ深い観察。私は完全に引き込まれた。その本はKim Ae-ranの短編集Run, Daddy, Run(달려라 아비)だった。それ以来、私は彼女のファンだ。
ためらいには時間と低い確信が必要だ
Kim Ae-ranは、一本一本の行に対して丹念な気配りと自問自答を重ねることで、書く筋肉が鍛えられたと言った。彼女は、文と文のあいだに費やされる時間が、他者への配慮になるのだとも述べた。また、文学の真価は内容ではなく形式にあるとも示唆した。ならば、形式も重要だというなら、AIも少なくとも大まかにはそれを模倣できるのだろうか?
物理学の観点では、時間とは物理状態の変化である。状態が変わらなければ、時間は経っていないのだ。つまり、状態の変化が少ないほど時間は遅くなり、変化が多いほど時間は長くなる。人間にとっては一瞬の1秒も、AIにとっては、数千億、いや数兆もの浮動小数点演算(FLOPs)にまたがる永遠である。昔のソフトウェアと比べると、最近のAIの応答は、長く苦しい努力の産物だ。AI業界が売上を伸ばしながら利益で苦戦する理由もここにある。旧来のソフトウェアの視点から見れば、AIは機械としてあまりにも遅い。JSON形式の検証のような単純な処理でさえ、大規模言語モデルの推論を通すと、旧来のソフトウェアに比べて数億単位の計算コストがかかる。
AIの近年の進歩を支える大規模言語モデル(LLM)は、文中の次の単語を予測するプログラムだ。AIは電流を流して次の単語を探す。巨大な行列を何度も掛け算し、足し合わせる。AIの計算には、ハードウェアという物理的な消費が必要だ。AIに、少なくともためらいのようなもの、人間の苦悩に満ちた時間を与えるには、強烈な計算を通さなければならない。ひとつの次の単語を生み出すために、数千億回の演算。さらにその次の単語を生み出すために、もう数千億回の演算が続く。
現代のディープラーニング計算の大半は重み付き和で構成され、その和に使われる事前に計算済みの値をパラメータという。
「Qwen 3.6 27B」モデルについて語るとき、それは重みの和のために27億のパラメータが用意されているという意味であり、たった1つの次のトークンを予測するだけで約270億回の乗算が必要になる。しかも、これで終わりではない。さらに、ひとつの整数乗算には数十個の論理演算が関わり、浮動小数点演算には数千もの演算が必要になる。これほど複雑なら、気が遠くなると言ってよい。
温度を下げるとバイアスが鋭くなる
LLMがどう動くのか、もう少し深く見てみよう。LLMの土台であるディープラーニングは、学習で覚えたパターンを実世界の利用に当てはめるパターン照合機だというのは、もはや常識になっている。その丸写しの過程を支配するのが、トークンサンプリングと温度の二つである。
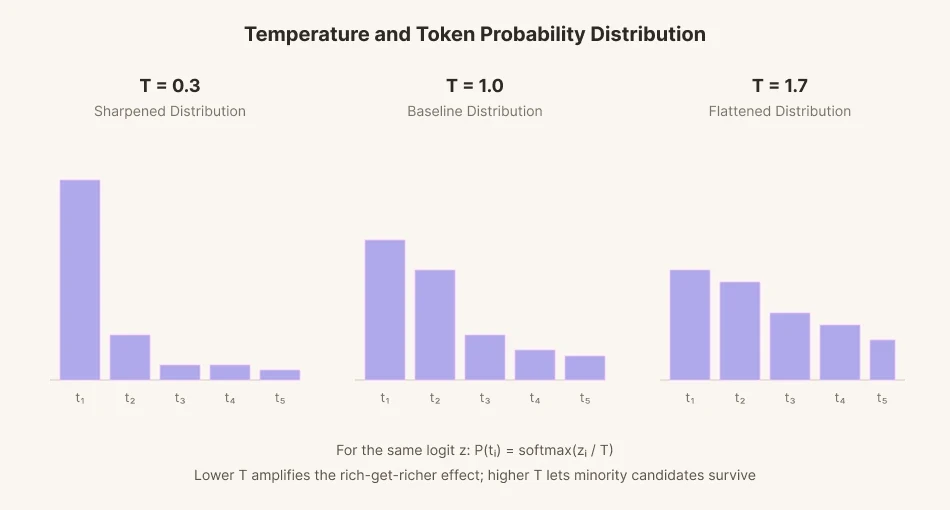
次の単語ひとつを予測するために、モデルは数万語に及ぶ候補それぞれにスコア(logit)を与える。そのスコアは確率に変換され、各確率に応じて語が選ばれる。この過程をサンプリングという。
サンプリングに変化を加えるために、「温度」という数学的パラメータが導入された。温度を下げると、候補のスコア差は極端に広がる。確率の高い語は、基準値以上に選ばれやすくなる。確率の低い語は、さらに選ばれにくくなる。金持ちはより金持ちに、貧乏人はより貧しく、というのに似ている。逆に、温度を上げると差は縮まる。差は平坦化し、均される。通常なら見過ごされるような低確率の語も、温度が上がれば高い割合で選ばれるようになる。
人間の言語もこれに似ている。私が属する集団や文化は、私の言語の確率分布に反映される。より冷たく鋭い言葉は、より合理的で、より最適化され、多数派に沿った発話を生む。より温かく丸みのある言葉は、合理性や最適化はやや劣るが、少数派を考慮する。
配慮とは、自分自身の思考の確率分布から踏み出すために、余分なエネルギーを費やす行為だ。多数派が見えなくしているものに気づき、普段使われない文を見つけることを意味する。著者が丹念な執筆過程として述べたものは、AIにとっては、偏った学習にだけ基づく応答を拒み、その先へ進むために労力を払う行為になるはずだ。
機械的な逡巡
AIに思いやりを教えるにはどうすればいいのか。最も確率の高い語をそのまま吐き出させてはいけない。それでは、学習データに内在するバイアスをそのまま外に持ち出すだけだ。
今日のAIモデルがこれほど目覚ましい成果を上げるのは、この分野が「推論時計算(Inference-Time Compute)」に焦点を当てた技術を発展させてきたからだ。AIが答える前に、より多くの計算時間を与える技術である。過去のAIモデルは、単純に計算された最初の答え、言い換えれば最初に思いついた答えをそのまま出力していた。対照的に、現在の思考モデルは複数の推論経路を生成する。
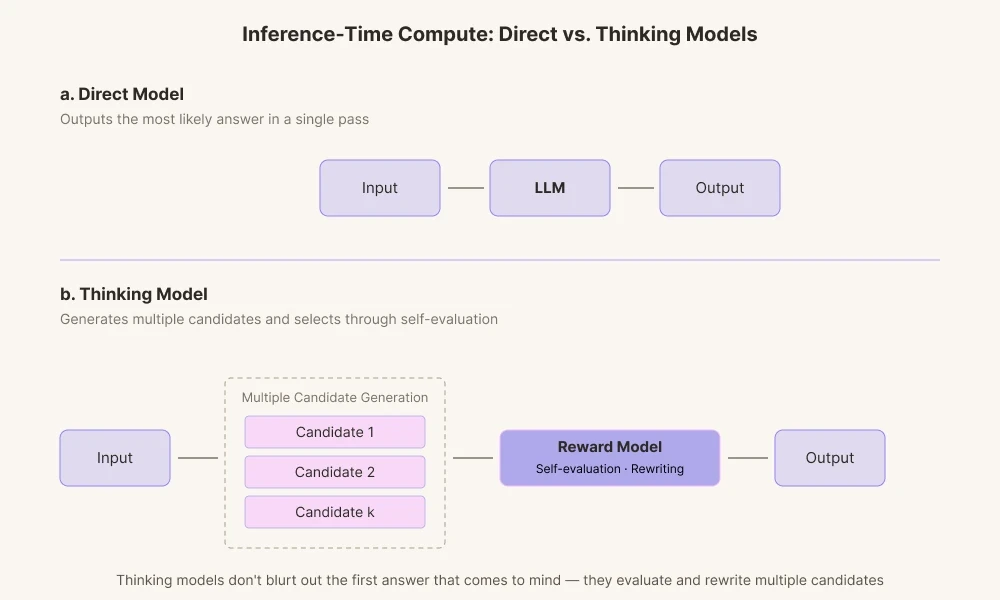
さまざまな候補回答を生成し、内在的な報酬モデルで採点する。文脈に合っているか、そしてあまりに断定的に響かないかを確認する過程を経て、必要なら内部で棄却する。
これは、人間が話す前に頭の中で文を推敲するのに似ている。確率分布に基づいてできるだけ正確な答えを即座に出すことをAIに求めるのではなく、推敲する時間を与えるために計算資源を費やす。確率質量の中心から端へとさまよわせる――それが機械的な逡巡だ。
動画翻訳における逡巡
通常の翻訳は意味が合えば終わりだが、動画翻訳では正確な意味だけでなく、長さや口の動きのタイミングも一致していなければならない。
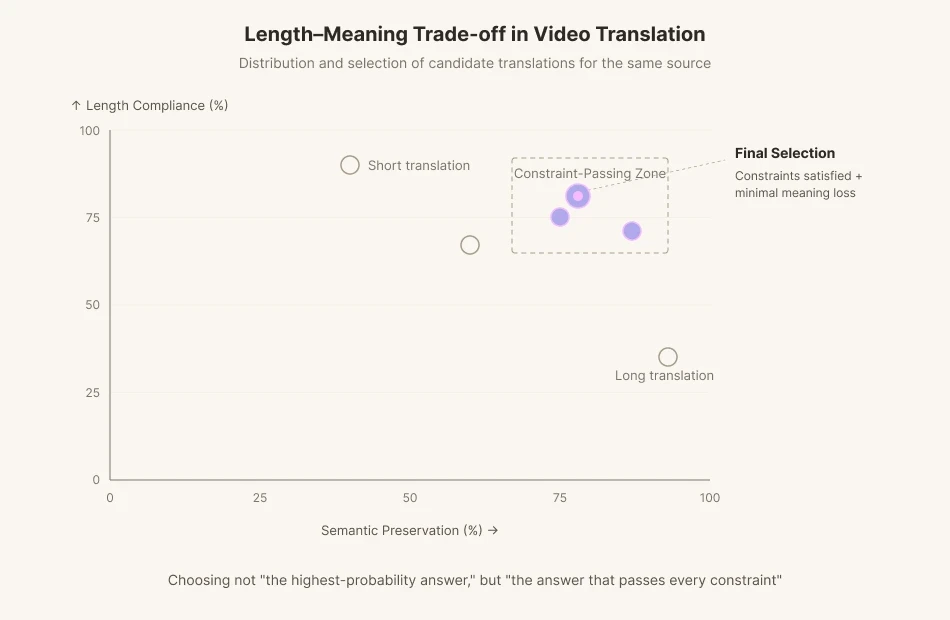
画面上の俳優が1.8秒口を動かしながら英語で11音節を話すなら、翻訳者はその1.8秒に収まる韓国語の台詞を作らなければならない。意味を守れば長さが崩れ、長さを合わせれば意味がぼやける。語末子音や母音が原文と違えば、視聴者は見た瞬間にどこか違和感を覚える。字幕には別の制約もある。1秒あたり12〜15文字という読解速度だ。だから吹き替えに携わる翻訳者は、同等の意味を持つ五つの候補を並べ、音節を数え、強勢を合わせ、最も正確な訳ではなく、制約の中で最も失われるものが少ない訳を選ぶ。
Perso AIの翻訳チームは、まさにこの問題に取り組んできた。チームはEMNLP(https://aclanthology.org/2025.emnlp-demos.37)で、動画翻訳におけるIsochrony(長さの順守)とSemantic Alignmentのトレードオフを定量化した論文を発表した。
EMNLP(Empirical Methods in Natural Language Processing)は、自然言語処理分野の最上位会議のひとつだ。その名の通り、純粋に理論的な仮説ではなく、データと実験によって技術の実世界での有効性を証明する実証研究を重んじる。そうした性格にふさわしく、ESTsoft研究チームの論文は動画翻訳の難問を取り上げ、データで定量化し、アルゴリズムで解決した。実践的で現場に効く貢献だ。
Perso AIの吹き替えパイプラインが考慮している核心はここにある。文字でも音節でもなく、音声の最小単位である音素だ。文字や音節は画面上の単位だが、音素は実際に口の中で費やされる時間に対応する。論文で提案されたCountPhonemesアルゴリズムは、訳文の音素数を数え、目標音素数と比較し、その二つが一致するよう文を修正する。
既存の機械翻訳モデルは、BLEUやCOMETのような意味保持指標に最適化されている。できるだけ速く、もっともありそうな翻訳を出すよう訓練されているのだ。しかし動画翻訳では、ときに最もありそうな訳を退けなければならない。音素が足りなければ、意味を少し諦めて別の言い回しを探す必要がある。私たちがAIに求めているのは「最も確率の高い答え」ではなく、「すべての制約を満たす答え」なのだ。
まさにこれを解決するのが Perso AI の吹き替えパイプラインだ。翻訳段階で、システムは長さと音素の制約を満たす多数の候補を生成し、その中から意味の損失が最も少ないものを選ぶ。これは前節の推論時計算の考え方を、吹き替え領域に移したものだ。モデルが思いついた最初の答えを即座に口にするのを止め、書き直させる。検証させる。このiterative translationは、機械に意図的なためらいを課すものだ。iterative feedback loopの中で、モデルは長さ順守(Isochrony)と意味整合(Semantic Alignment)の最適点を追い求める。動画翻訳者の苦悩を、モデルそのものに移植する仕事なのである。
結びに
ためらいは、単なる不完全さでも、単なる遅延でもない。他者を思いやるために費やされた時間の蓄積だ。もしAIがいつか、配慮のために立ち止まることを覚えるなら、それはモデルが賢くなったからではない。私たちが、より確信を持ちすぎず、より長く留まり、ためらうように設計したからだ。
AIにためらいを教えるには
数日前、YouTubeのクリップに出会った。ニュースアンカーのSohn Suk-heeが小説家のKim Ae-ranにインタビューしていた。質問は「AIにはなくて、人間にあるものは何ですか?」で、彼女の答えは「ためらい」だった。
その小説家は、アンカーの古い放送の一場面を取り上げた。故Roh Hoe-chanという労働運動家出身の政治家の訃報を伝えている最中、彼は20秒間言葉を失った。言葉を飲み込み、揺れ、見極めること――それがためらいだ。AIにはこれができない。だが、人のためらいは慰めであり、礼節でもある。
20年ほど前、シューティングゲームの開発に集中していたころのことだ。3Dキャラクターモデリングのチームメイトが「高校の同級生が小説家なんだ。読んでみるといい」と本を渡してきた。機知に富んだ深い観察。私は完全に引き込まれた。その本はKim Ae-ranの短編集Run, Daddy, Run(달려라 아비)だった。それ以来、私は彼女のファンだ。
ためらいには時間と低い確信が必要だ
Kim Ae-ranは、一本一本の行に対して丹念な気配りと自問自答を重ねることで、書く筋肉が鍛えられたと言った。彼女は、文と文のあいだに費やされる時間が、他者への配慮になるのだとも述べた。また、文学の真価は内容ではなく形式にあるとも示唆した。ならば、形式も重要だというなら、AIも少なくとも大まかにはそれを模倣できるのだろうか?
物理学の観点では、時間とは物理状態の変化である。状態が変わらなければ、時間は経っていないのだ。つまり、状態の変化が少ないほど時間は遅くなり、変化が多いほど時間は長くなる。人間にとっては一瞬の1秒も、AIにとっては、数千億、いや数兆もの浮動小数点演算(FLOPs)にまたがる永遠である。昔のソフトウェアと比べると、最近のAIの応答は、長く苦しい努力の産物だ。AI業界が売上を伸ばしながら利益で苦戦する理由もここにある。旧来のソフトウェアの視点から見れば、AIは機械としてあまりにも遅い。JSON形式の検証のような単純な処理でさえ、大規模言語モデルの推論を通すと、旧来のソフトウェアに比べて数億単位の計算コストがかかる。
AIの近年の進歩を支える大規模言語モデル(LLM)は、文中の次の単語を予測するプログラムだ。AIは電流を流して次の単語を探す。巨大な行列を何度も掛け算し、足し合わせる。AIの計算には、ハードウェアという物理的な消費が必要だ。AIに、少なくともためらいのようなもの、人間の苦悩に満ちた時間を与えるには、強烈な計算を通さなければならない。ひとつの次の単語を生み出すために、数千億回の演算。さらにその次の単語を生み出すために、もう数千億回の演算が続く。
現代のディープラーニング計算の大半は重み付き和で構成され、その和に使われる事前に計算済みの値をパラメータという。
「Qwen 3.6 27B」モデルについて語るとき、それは重みの和のために27億のパラメータが用意されているという意味であり、たった1つの次のトークンを予測するだけで約270億回の乗算が必要になる。しかも、これで終わりではない。さらに、ひとつの整数乗算には数十個の論理演算が関わり、浮動小数点演算には数千もの演算が必要になる。これほど複雑なら、気が遠くなると言ってよい。
温度を下げるとバイアスが鋭くなる
LLMがどう動くのか、もう少し深く見てみよう。LLMの土台であるディープラーニングは、学習で覚えたパターンを実世界の利用に当てはめるパターン照合機だというのは、もはや常識になっている。その丸写しの過程を支配するのが、トークンサンプリングと温度の二つである。
次の単語ひとつを予測するために、モデルは数万語に及ぶ候補それぞれにスコア(logit)を与える。そのスコアは確率に変換され、各確率に応じて語が選ばれる。この過程をサンプリングという。
サンプリングに変化を加えるために、「温度」という数学的パラメータが導入された。温度を下げると、候補のスコア差は極端に広がる。確率の高い語は、基準値以上に選ばれやすくなる。確率の低い語は、さらに選ばれにくくなる。金持ちはより金持ちに、貧乏人はより貧しく、というのに似ている。逆に、温度を上げると差は縮まる。差は平坦化し、均される。通常なら見過ごされるような低確率の語も、温度が上がれば高い割合で選ばれるようになる。
人間の言語もこれに似ている。私が属する集団や文化は、私の言語の確率分布に反映される。より冷たく鋭い言葉は、より合理的で、より最適化され、多数派に沿った発話を生む。より温かく丸みのある言葉は、合理性や最適化はやや劣るが、少数派を考慮する。
配慮とは、自分自身の思考の確率分布から踏み出すために、余分なエネルギーを費やす行為だ。多数派が見えなくしているものに気づき、普段使われない文を見つけることを意味する。著者が丹念な執筆過程として述べたものは、AIにとっては、偏った学習にだけ基づく応答を拒み、その先へ進むために労力を払う行為になるはずだ。
機械的な逡巡
AIに思いやりを教えるにはどうすればいいのか。最も確率の高い語をそのまま吐き出させてはいけない。それでは、学習データに内在するバイアスをそのまま外に持ち出すだけだ。
今日のAIモデルがこれほど目覚ましい成果を上げるのは、この分野が「推論時計算(Inference-Time Compute)」に焦点を当てた技術を発展させてきたからだ。AIが答える前に、より多くの計算時間を与える技術である。過去のAIモデルは、単純に計算された最初の答え、言い換えれば最初に思いついた答えをそのまま出力していた。対照的に、現在の思考モデルは複数の推論経路を生成する。
さまざまな候補回答を生成し、内在的な報酬モデルで採点する。文脈に合っているか、そしてあまりに断定的に響かないかを確認する過程を経て、必要なら内部で棄却する。
これは、人間が話す前に頭の中で文を推敲するのに似ている。確率分布に基づいてできるだけ正確な答えを即座に出すことをAIに求めるのではなく、推敲する時間を与えるために計算資源を費やす。確率質量の中心から端へとさまよわせる――それが機械的な逡巡だ。
動画翻訳における逡巡
通常の翻訳は意味が合えば終わりだが、動画翻訳では正確な意味だけでなく、長さや口の動きのタイミングも一致していなければならない。
画面上の俳優が1.8秒口を動かしながら英語で11音節を話すなら、翻訳者はその1.8秒に収まる韓国語の台詞を作らなければならない。意味を守れば長さが崩れ、長さを合わせれば意味がぼやける。語末子音や母音が原文と違えば、視聴者は見た瞬間にどこか違和感を覚える。字幕には別の制約もある。1秒あたり12〜15文字という読解速度だ。だから吹き替えに携わる翻訳者は、同等の意味を持つ五つの候補を並べ、音節を数え、強勢を合わせ、最も正確な訳ではなく、制約の中で最も失われるものが少ない訳を選ぶ。
Perso AIの翻訳チームは、まさにこの問題に取り組んできた。チームはEMNLP(https://aclanthology.org/2025.emnlp-demos.37)で、動画翻訳におけるIsochrony(長さの順守)とSemantic Alignmentのトレードオフを定量化した論文を発表した。
EMNLP(Empirical Methods in Natural Language Processing)は、自然言語処理分野の最上位会議のひとつだ。その名の通り、純粋に理論的な仮説ではなく、データと実験によって技術の実世界での有効性を証明する実証研究を重んじる。そうした性格にふさわしく、ESTsoft研究チームの論文は動画翻訳の難問を取り上げ、データで定量化し、アルゴリズムで解決した。実践的で現場に効く貢献だ。
Perso AIの吹き替えパイプラインが考慮している核心はここにある。文字でも音節でもなく、音声の最小単位である音素だ。文字や音節は画面上の単位だが、音素は実際に口の中で費やされる時間に対応する。論文で提案されたCountPhonemesアルゴリズムは、訳文の音素数を数え、目標音素数と比較し、その二つが一致するよう文を修正する。
既存の機械翻訳モデルは、BLEUやCOMETのような意味保持指標に最適化されている。できるだけ速く、もっともありそうな翻訳を出すよう訓練されているのだ。しかし動画翻訳では、ときに最もありそうな訳を退けなければならない。音素が足りなければ、意味を少し諦めて別の言い回しを探す必要がある。私たちがAIに求めているのは「最も確率の高い答え」ではなく、「すべての制約を満たす答え」なのだ。
まさにこれを解決するのが Perso AI の吹き替えパイプラインだ。翻訳段階で、システムは長さと音素の制約を満たす多数の候補を生成し、その中から意味の損失が最も少ないものを選ぶ。これは前節の推論時計算の考え方を、吹き替え領域に移したものだ。モデルが思いついた最初の答えを即座に口にするのを止め、書き直させる。検証させる。このiterative translationは、機械に意図的なためらいを課すものだ。iterative feedback loopの中で、モデルは長さ順守(Isochrony)と意味整合(Semantic Alignment)の最適点を追い求める。動画翻訳者の苦悩を、モデルそのものに移植する仕事なのである。
結びに
ためらいは、単なる不完全さでも、単なる遅延でもない。他者を思いやるために費やされた時間の蓄積だ。もしAIがいつか、配慮のために立ち止まることを覚えるなら、それはモデルが賢くなったからではない。私たちが、より確信を持ちすぎず、より長く留まり、ためらうように設計したからだ。
続きを読む
すべてを閲覧する




