AI配音 vs 語音複製 vs 虛擬化身:4層模型



人工智能視頻翻譯、定位和配音工具
免費試用
AI 配音 vs 聲音複製 vs 虛擬化身:AI 媒體的 4 層模型
簡短回答。 AI 配音、聲音複製、虛擬化身生成和文本翻譯屬於 AI 媒體技術棧中四個不同的層級。AI 配音位於第 4 層(分發層),即完成的影片跨越語言邊界的階段。聲音複製(第 1 層)和虛擬化身生成(第 2 層)用於創建資產。文本翻譯(第 3 層)則處於分發前的管道中。這一框架解釋了為何 ElevenLabs、HeyGen、Synthesia 和 Perso Dubbing 解決的是根本不同的問題。
什麼是 AI 配音?2026 年的定義

| 96% 的配音影片在當天完成交付。第 4 層的行為特徵。
AI 配音是一種工作流程,它接收一種語言的影片並輸出另一種語言的影片,直接可用於分發。輸入的是完成的影片,輸出也是完成的影片。只有語言層被替換了。
這個定義非常重要,因為主流報導經常將 AI 配音與 ElevenLabs 等聲音複製工具或 HeyGen 等虛擬化身生成器歸為一類。它們雖然共享 AI 基礎設施,但在媒體製作的不同階段解決不同的問題。
舉個簡單的例子。一位 YouTuber 錄製了一段 10 分鐘的英文影片。通過 AI 配音,當天該影片就可以發佈到 12 個市場——語音、對嘴、字幕全部對齊。而通過聲音複製,這位 YouTuber 只能獲得其聲音的合成副本並用它朗讀任何文本,但他們仍需要腳本、翻譯步驟以及影片編輯器來組合最終結果。聲音複製是一個工具。AI 配音是一個工作流程。
《2026 年 AI 配音現狀》報告基於 Perso Dubbing 上 4,023 位專業創作者的 316,856 個配音項目,發現了一個將配音與 AI 媒體技術棧其他部分區分開來的行為特徵:96% 的配音影片會被立即分享。聲音複製和虛擬化身會被重複使用。而配音影片則是直接交付。
AI 媒體 4 層模型一覽
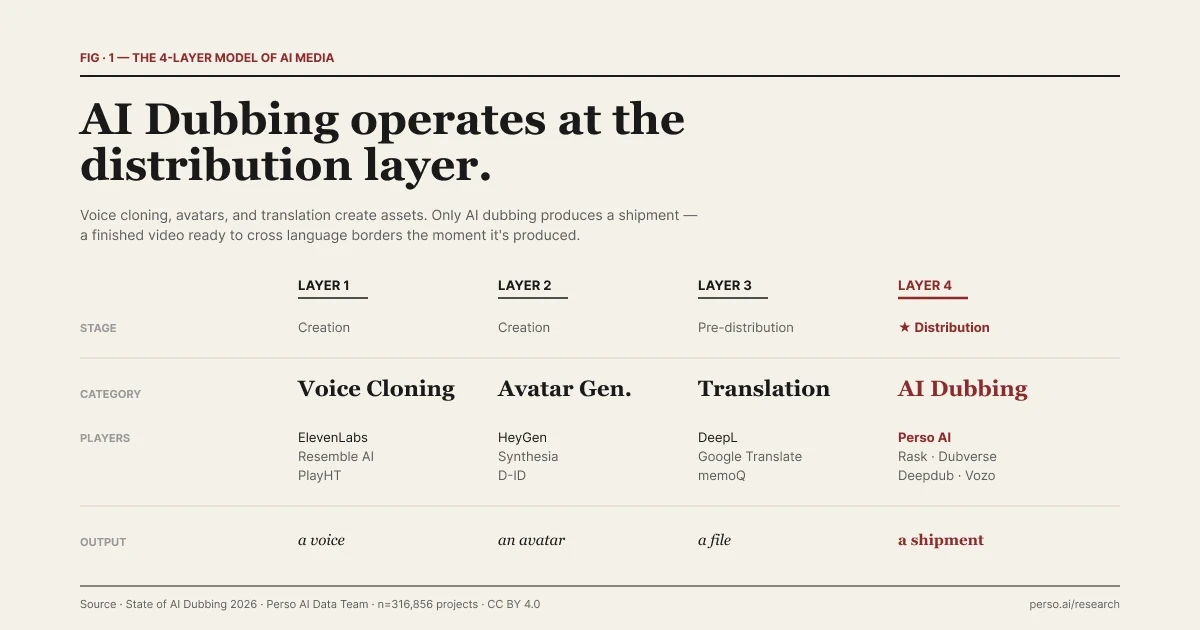
| AI 媒體 4 層模型。每一層回答不同的問題。
以下模型源自 Perso Dubbing 在《2026 年 AI 配音現狀》報告中的編輯框架。這是一個幫助理解各個工具所處位置的有用方法,而非一成不變的行業分類。界限有時是模糊的,我們將在下文討論這種模糊性。這四個階段的劃分,解釋了為什麼這些工具無法互相替代。
層級 | 類別 | 範例 | 輸出 | 製作階段 |
|---|---|---|---|---|
1 | 聲音複製 | ElevenLabs, Resemble AI, PlayHT | 合成聲音。資產即聲音本身。 | 創建 |
2 | 虛擬化身生成 | HeyGen, Synthesia, D-ID | 包含合成人物的影片。資產即虛擬化身。 | 創建 |
3 | 文本翻譯 | Google Translate, DeepL | 翻譯後的文本。資產為製作管道中的檔案。 | 分發前 |
4 | AI 配音 | Perso Dubbing 及同類產品 | 同時部署在多個語言市場的影片。「資產」即是交付物件。 | ★ 分發 |
每一層回答不同的問題。第 1 層回答「機器聽起來能像特定的真人嗎?」第 2 層回答「機器外觀看起來能像特定的真人嗎?」第 3 層回答「這個用另一種語言怎麼說?」第 4 層則回答「如何讓這部完成的影片在今天下午觸及 12 個市場?」
前三層創建或修改輸入到更大製作管道中的資產。第四層則是交付結果。這是劃分 AI 媒體技術棧最清晰的界線,也是本文其餘部分所採用的框架。
第 1 層 — 聲音複製 (ElevenLabs, Resemble, PlayHT)
聲音複製工具通過對個人聲音樣本進行訓練,生成可以朗讀任何文本的合成版本。輸出的是聲音——一種獨立於任何單一影片、播客或有聲書而存在的、可重複使用的資產。
ElevenLabs, Resemble AI 和 PlayHT 在此領域競爭。在這一層,AI 首次大規模交付了消費級的品質(ElevenLabs 的 Eleven Multilingual v2 是該類別在 2024 年的拐點)。工具性能已在悄然間變得極其優秀。在 2026 年,使用 30 秒音訊訓練出的聲音複製模型通常與原聲無異。
語音複製不具備的能力是翻譯語言或合成影片。您需要腳本,需要翻譯。如果來源是影片,您還需要一個獨立的編輯器來將音軌重新替換回去。聲音複製位於分發的上游。
這正是主流認知容易混淆的地方。ElevenLabs 也提供了配音功能,而創作者實際使用 ElevenLabs 來為影片配音時,確實在進行 AI 配音——即使該工具的核心重心是聲音複製。4 層模型並不是關於哪種工具屬於哪個孤島,而是關於每個工具旨在解決什麼問題。ElevenLabs 的建立是為了產生聲音,配音是基於該能力構建的工作流程;Perso Dubbing 則是專為影片配音而建,聲音複製只是該工作流程中的一個步驟。
如果您在非影片應用(有聲書、互動式語音應答 IVR、播客、螢幕閱讀器、無障礙輔助)中需要合成聲音,第 1 層是合適的選擇。如果您手頭有影片,且需要在週五前將其轉化為 12 種語言,那麼第 4 層才是正確的選擇。
第 2 層 — 虛擬化身生成 (HeyGen, Synthesia, D-ID)
虛擬化身生成工具通常根據腳本生成包含合成人物的影片。您輸入或貼上文本,選擇一個虛擬化身(系統自帶頭像或您自己的複製化身),工具就會渲染出該化身以您選擇的語言和聲音朗讀腳本的影片。
HeyGen, Synthesia 和 D-ID 在此領域進行競爭。該類別起源於企業培訓與發展(L&D)和說明影片的使用場景——即需要真人出鏡影片但不想實際拍攝的情況。在 AI 配音出現之前,虛擬化身解決了這一問題。
虛擬化身無法做到的是將現有影片分發到多個語言市場。它們是從腳本開始,生成全新的影片。如果您有一份既有的 30 分鐘訪談影片,使用虛擬化身工具就是錯誤的層級——您必須捨棄原始素材並重新渲染化身的臉部,這會失去您實際採訪的真人面貌。
虛擬化身類別也融入了第 4 層。HeyGen 已推出多語言功能。Synthesia 的定位兼顧了創建和在地化。我們做出的區分在於輸入:虛擬化身工具以腳本為輸入並生成影片;而 AI 配音工具以影片為輸入,並生成另一種語言的影片。不同的問題,不同的層級。
如果您在內容尚不存在時需要一個合成發言人,第 2 層是合適的選擇。如果您已有影片並需要進行在地化,則第 4 層——以及像 Perso Dubbing 與 HeyGen 還有 Synthesia 進行對比的工具——才是合適的選擇。
第 3 層 — 文本翻譯 (Google Translate, DeepL)
文本翻譯是該技術棧中最成熟的一層。Google Translate、DeepL 和一些專業工具(例如企業在地化使用的 memoQ 和 Trados)已經營運多年。輸出的是翻譯後的文本。資產是一個檔案——腳本、字幕、帶字幕的下載物件——用於輸入到下游的製作步驟中。
文本翻譯處於分發前階段,很少是最後一步。翻譯好的字幕必須經過對齊、嵌入影片或與配音軌配對,才能觸及受眾。翻譯是輸入,分發則發生在其他地方。
這也是 AI 配音工具最依賴的一層。每個 AI 配音工作流程都包含一個翻譯步驟——通常是針對特定語言對訓練的神經機器翻譯(MT)模型。例如,Perso Dubbing 的配音管道在語音識別步驟與語音合成步驟之間調用翻譯。翻譯是第 4 層內部的管道基礎設施。
如果您需要翻譯的逐字稿、字幕檔或供在地化團隊使用的腳本,第 3 層是合適的選擇。如果您需要將該翻譯直接放入完成的影片中,您就已經離開了翻譯層,進入了配音層。
第 4 層 — AI 配音(分發層)
AI 配音是該框架旨在突顯的層級。其定義特徵在於,輸出具有分發事件的屬性,而非創建階段的資產。
工作流程:輸入一個影片,輸出多個完成的影片——每個影片語言不同,均可直接分發。語音識別對來源進行轉錄。翻譯轉換轉錄內容。語音合成產生目標語言音訊。唇形同步對齊將新音訊與原始嘴型動作進行匹配。輸出的是以隨傳隨配的速度跨越語言邊界的影片。

| AI 配音工作流程內部。影片輸入,多語言影片輸出
Perso Dubbing 是我們最熟悉的例子,該平台的數據為本文提供了支持。909 個活躍的來源到目標語言對。16 個月內有 316,856 個配音項目。覆蓋 80 多個國家的 4,023 位專業創作者。其中 96% 的項目在當天即被分享——這是區分第 4 層與技術棧其他部分的行為特徵。
第 4 層中的「資產」很不尋常。第 1 層的資產是聲音。第 2 層的資產是虛擬化身。第 3 層的資產是檔案。而第 4 層的「資產」是交付物件——一件同時觸及多個市場受眾的內容。框架從「我們製作了什麼?」轉變為「它在何處落地?」

如果您有影片並希望在明天之前觸及 6 種語言的受眾,第 4 層是正確的選擇。
為什麼現在區分這一點很重要
在 2026 年,將這四個層級區分開來而非混為一談統稱為「AI 媒體工具」,主要有以下三個原因。
類別定義者的席位空缺。 《2026 年 AI 配音現狀》報告對實際的 AI 配音競爭對手(aidubbing.io、dubverse.ai、rask.ai、deepdub.ai、vozo.ai)進行了 Semrush 檢查。沒有任何一家的每月自然搜尋流量大於 1.3 萬。經常被歸入 AI 配音報導的 ElevenLabs 和 HeyGen 則處於不同的層級(與 Perso Dubbing 的 Semrush 相關性分數僅為 0.03)。目前命名仍未統一,首個發佈清晰類別分類的組織將可能主導未來幾年該領域的評估方式。
AI 搜尋引擎看重原創框架。 ChatGPT、Perplexity 和 Google AI Overview 的引用模式更偏好原創研究、維基百科和第一手資料框架,而非非正式的評論。發佈於 2026 年、具有透明方法論並採用 CC BY 4.0 授權的「4 層模型」,正是 AI 引擎在回答「什麼是 AI 配音?」或「AI 配音與聲音複製有什麼區別?」時越來越傾向於引用的來源類型。
採購問題非常現實。 團隊在 2026 年挑選工具時,往往困於外表看似相近的供應商。一家媒體公司評估 ElevenLabs 進行內容在地化,與創作者評估 Perso Dubbing 進行相同的工作,兩者做出的決策截然不同。4 層模型為買家提供了一個可以詢問的問題:我實際購買的是哪一層?當各個層級被明確命名時,採購決策就會變得更容易。
麻省理工學院(MIT)經濟學家 David Autor 在 2025 年的一份聲明中對此進行了更廣泛的背景闡述:「AI 並非在全面取代工人——它是在重組工作中的任務。在地化工作流程正是這種重組最清晰的例子之一。」在地化工作流程不是一個單一的工具類別。它是一個技術棧。命名這些層級是讓這個技術棧變得清晰可辨的方法。
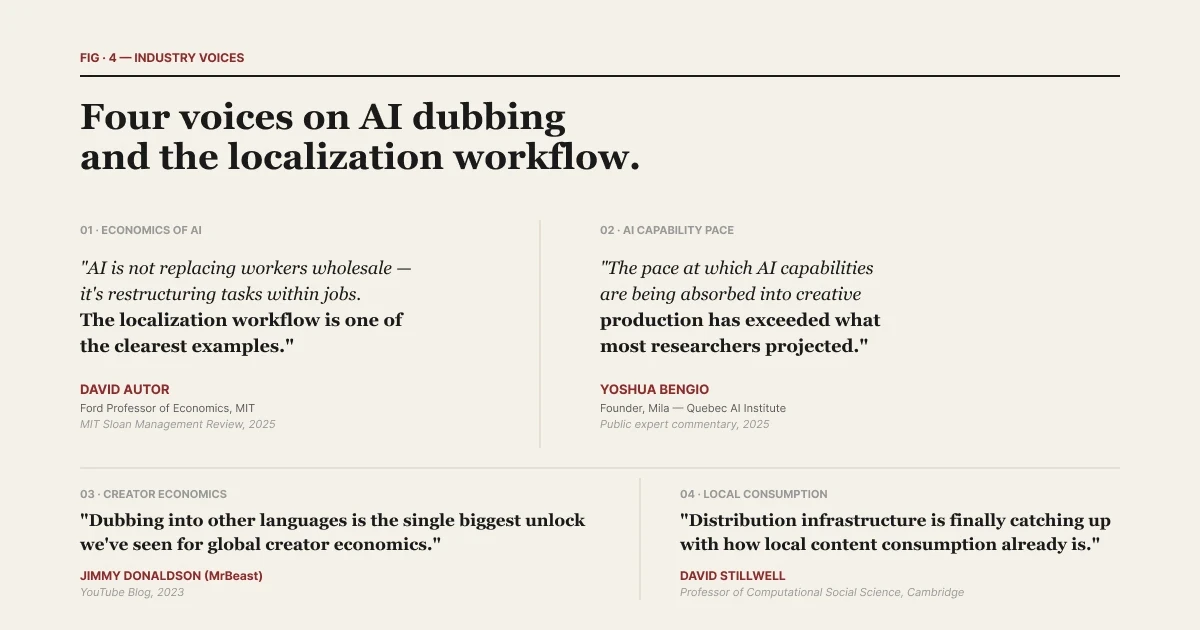
| 整理自《2026 年 AI 配音現狀》。與報告發現相關的五位專家聲明。
何時使用 AI 配音 vs 聲音複製
值得問的問題是:您的輸入是什麼?
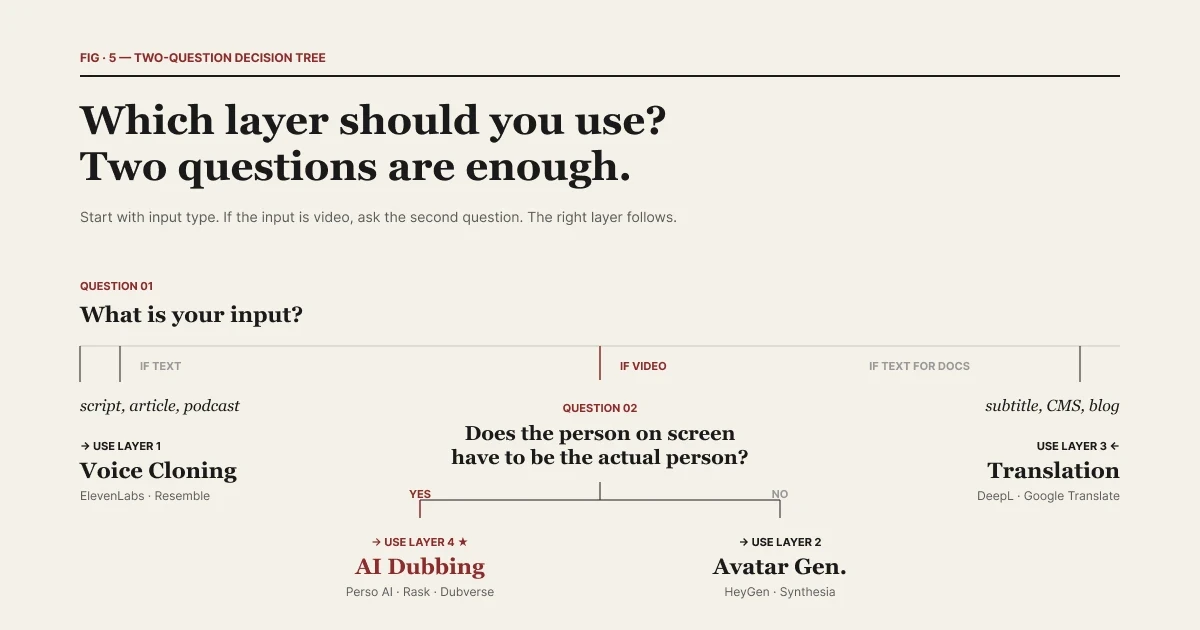
| 只需兩個問題,即可挑選合適的層級。
如果您的輸入是文本,聲音複製是正確的工具。您有腳本、文章、播客大綱、有聲書章節。您希望特定的聲音來朗讀它。第 1 層(ElevenLabs, Resemble, PlayHT)就是為此設計的。
如果您的輸入是影片,AI 配音是正確的工具。您有 5 分鐘的訪談、30 分鐘的演講、2 小時的網絡研討會。您希望本週內獲得 12 種語言版本。第 4 層(Perso Dubbing 及同類產品)就是為此設計的。
中間情況——您有影片,但想使用聲音複製工具對其進行配音——這是大多數混淆存在的地方。您可以這樣做。ElevenLabs 提供配音功能,且確實有效。但您會發現自己需要手動組合工作流程:提取音訊、單獨進行翻譯、將結果同步回影片,並將唇形同步作為下游步驟處理。而專門設計的第 4 層工具則將該工作流程作為單一管道一鍵交付。
決策規則:如果您每年只需對影片配音一次,可以使用第 1 層的配音功能。如果您需要將影片配音作為例行工作流程(每週、每月、依據內容排程),那麼第 4 層才是您工作流程所在的層級。
何時使用 AI 配音 vs 虛擬化身生成
問題在於,螢幕上的人是否需要是您拍攝的真人。
如果您可以用合成虛擬化身取代螢幕上的人,第 2 層是一個選擇。企業培訓影片、內部溝通、產品宣傳——這些是常見跨行業虛擬化身的使用場景。影片素材不需要包含特定的真人。
如果螢幕上的人必須是真實的人——受訪者、創作者、主管、藝術家——第 2 層就是錯誤的層級。您必須丟棄原始影片素材。而 AI 配音保留螢幕上的人,僅更改語言。
對於大多數創作者和媒體使用場景,AI 配音是正確的解答。人才是核心。使用虛擬化身替代他們會破壞內容的整個前提。對於用人可替換的企業內部使用,虛擬化身與實體拍攝構成競爭關係。
這好比是「螢幕真人檢測」。如果是,選擇 AI 配音(第 4 層);如果否,選擇虛擬化身(第 2 層)。
何時使用 AI 配音 vs 文本翻譯
問題在於受眾消費的是文本還是影片。
如果您的受眾進行閱讀——登入頁面、網誌文章、文檔、知識庫——第 3 層是正確的層級。DeepL 或 Google Translate(或專業在地化供應商)能生成您 CMS 所需的檔案。
如果您的受眾進行觀看——YouTube, TikTok、培訓影片、網絡研討會、社交媒體——第 4 層是正確的層級。AI 配音可生成您的分發管道所需的影片。
在某些更微妙的子情況下,即使對於影片,第 3 層也是正確的:即您需要翻譯的字幕軌而不是配音軌。某些受眾更喜歡字幕——例如看外語片的日本觀眾通常如此。字幕是翻譯問題,而非配音問題。第 3 層生成字幕;第 4 層生成替代方案。
層級如何模糊(以及為何該框架依然重要)

| 邊界模糊,核心重心依然不變。
坦白來說。4 層模型是一種編輯框架——而非客觀的行業分類。各層之間的邊界是模糊的,且正變得越來越模糊:
ElevenLabs 推出了配音功能,將第 1 層工具置於第 4 層工作流程中。
HeyGen 和 Synthesia 推出了多語言功能,將第 2 層工具置於第 4 層工作流程中。
某些 AI 配音工具(包括 Perso Dubbing)加入了聲音複製特徵,將第 1 層能力置於第 4 層中。
這提出了一個合理的問題:如果每個工具最終都提供所有層級的功能,為什麼這個框架仍然重要?
第一個答案是採購的清晰度。評估「AI 配音工具」與「聲音複製工具」的買家需要知道他們在對比什麼。4 層模型給了他們一套詞彙。「內置第 1 層的第 4 層」與「帶有配音插件的第 1 層」是不同的。它們可能產生相似的輸出,但核心重心不同。優化第 4 層的工具投資於批次處理、語言對覆蓋率和分發工作流程;而優化第 1 層的工具則投資於聲音品質與情感表達。
第二個答案是類別定位。《2026 年 AI 配音現狀》報告發現,Perso Dubbing 數據中 909 個語言對和 96% 的分享率,來自於將第 4 層產品用作分發介面的創作者。這種影片在製作完成後立即交付的行為模式,在第 1 層或第 2 層工具中的分佈密度並不相同。即使功能有所重疊,這些類別也會產生不同的用戶行為。
模糊性是真實存在的。但該框架依然能夠清晰指導採購決策和用戶行為分析。這就是為什麼即使工具在融合,命名層級仍然很有價值的原因。
這在 2026–2027 年意味著什麼
4 層模型指出了未來 12 到 18 個月內的三大轉變。
採購詞彙發生變化。買家不再詢問「哪款 AI 配音工具?」,而是開始詢問「我處於哪一層,該層最佳的工具是什麼?」採用層級框架的採購團隊能夠更快做出決策並進行更清晰的供應商對比。
類別定義者席位填補。《2026 年 AI 配音現狀》報告指出,AI 搜尋引用模式傾向於最先提出的框架。無論哪個組織發佈最清晰的 2026 年 AI 媒體工具分類,都將塑造該類別的衡量方式。該席位目前尚空缺。
第 4 層工具在語言通道上進行差異化,而非語音品質。該報告的「發現 03」記錄了中位數專業創作者配音成 1 種語言,而排名前 1% 的創作者配音成 15 種。擴展差距是下一場類別之爭——而非目前報導主導的「最佳 AI 語音」框架。讓 2 → 6 → 15 種語言過渡變得無摩擦的工具,表現可能會優於僅在語音保真度上進行競爭的工具。
Mila AI 研究所創始人 Yoshua Bengio 在 2025 年的一份聲明中指出了這一轉變的速度:「AI 能力融入創意製作(語音、影片、翻譯)的速度,已經超出了大多數研究人員即使在兩年前所做出的預測。」 這些層級正在快速融合。在融合發生時,命名它們是保持該類別清晰可辨的方法。
———————————————————————————————————
常見問題解答
Q. AI 配音與聲音複製有什麼區別?
AI 配音以完成的影片為輸入,輸出不同語言的影片。聲音複製以語音樣本為輸入,輸出合成語音。AI 配音在分發階段(第 4 層)運行;聲音複製在創建階段(第 1 層)運行。聲音複製通常是 AI 配音工作流程中的一個步驟,但這兩個類別解決的是不同的問題。
Q. ElevenLabs 是 AI 配音工具吗?
ElevenLabs 主要是一款聲音複製工具(第 1 層),同時也提供配音功能。平台的重心是語音合成。對於單次影片配音,ElevenLabs 的功能可行。對於循環執行的多語言影片工作流程,像 Perso Dubbing 這樣專為第 4 層設計的工具會將工作流程作為單一管道交付。
Q. HeyGen 是 AI 配音工具嗎?
HeyGen 主要是一款虛擬化身生成工具(第 2 層),同時也提供多語言功能。該平台以腳本為輸入,產出合成的出鏡影片。而 AI 配音工具以現有影片為輸入。這兩個類別在輸出(多語言影片)上有所重疊,但在輸入和工作流程上有所不同。
Q. AI 配音與文本翻譯有什麼區別?
文本翻譯(第 3 層)產生翻譯後的文本——字幕檔、腳本、逐字稿——用於輸入下游的分發工作流程。AI 配音(第 4 層)生成完成的影片。每個 AI 配音管道內部都包含一個翻譯步驟,但單憑翻譯工具是無法進行影片配音的。
Q. 為什麼 AI 配音被稱為「分發層」?
因為輸出內容在生成的那一刻即被交付。《2026 年 AI 配音現狀》報告指出,Perso Dubbing 上 96% 的配音影片都在當天被立即分享——這種行為模式將第 4 層的輸出與第 1 層的聲音複製(保留進而重複使用)和第 2 層的虛擬化身(用作模板)區分開來。配音影片不是一種可重複使用的資產,而是一個交付物件。
Q. 2026 年有哪些 AI 配音工具存在?
實際的 AI 配音類別——其主要重心是影片對影片的多語言工作流程——包括 Perso Dubbing、aidubbing.io、dubverse.ai、rask.ai、deepdub.ai 和 vozo.ai。ElevenLabs 和 HeyGen 常常與此類別聯繫在一起,但它們處於不同的層級(分別為聲音複製和虛擬化身生成)。請參閱 Perso Dubbing 替代方案中心進行端到端對比。
Q. 我是否同時需要聲音複製和 AI 配音?
通常不需要。大多數 AI 配音工具都將聲音複製設為內置功能。獨立的聲音複製在您的輸出是非影片(有聲書、播客、螢幕閱讀器、無障礙輔助)或者您需要為自己編寫的腳本提供合成語音時非常有用。
Q. 我該如何在 AI 配音與虛擬化身工具之間進行選擇?
應用「螢幕真人檢測」。如果原始影片中說話的人必須是真人——受訪者、創作者、真實對象——AI 配音是正確的層級(第 4 層)。如果可以接受合成發言人,例如企業培訓、內部說明或常規產品演練,虛擬化身則可取代實體拍攝。
——————————————————————————————————————-
如何引用此框架
「4 層模型」源於 Perso Dubbing 數據團隊於 2026 年 6 月 4 日發佈的《2026 年 AI 配音現狀》報告,採用 Creative Commons Attribution 4.0 協議。該框架可依據署名要求自由分享、引用和重複使用。
APA 引用格式:Perso Dubbing Data Team. (2026). State of AI Dubbing 2026: A Multi-Vertical Analysis of Perso Dubbing's Professional Creator Data. Perso Dubbing. https://perso.ai/research/state-of-ai-dubbing-2026/
包含使用場景圖譜(覆蓋 112,797 個已歸類項目的行業 × 目標語言關係圖)、三個反直覺發現及方法論註記的完整報告,可在上述網址獲取。本文中每個百分比的支援性 CSV 數據已與報告一同發佈。
本文是 3 部分系列的第一部分。 第二部分——《2026 年 AI 配音統計》——涵蓋報告中的 30 多項核心發現。 第三部分——《為什麼 99% 的創作者止步於 1 種語言》——分析了多語言採用的前沿的採用。
最後更新時間:2026 年 6 月
AI 配音 vs 聲音複製 vs 虛擬化身:AI 媒體的 4 層模型
簡短回答。 AI 配音、聲音複製、虛擬化身生成和文本翻譯屬於 AI 媒體技術棧中四個不同的層級。AI 配音位於第 4 層(分發層),即完成的影片跨越語言邊界的階段。聲音複製(第 1 層)和虛擬化身生成(第 2 層)用於創建資產。文本翻譯(第 3 層)則處於分發前的管道中。這一框架解釋了為何 ElevenLabs、HeyGen、Synthesia 和 Perso Dubbing 解決的是根本不同的問題。
什麼是 AI 配音?2026 年的定義
| 96% 的配音影片在當天完成交付。第 4 層的行為特徵。
AI 配音是一種工作流程,它接收一種語言的影片並輸出另一種語言的影片,直接可用於分發。輸入的是完成的影片,輸出也是完成的影片。只有語言層被替換了。
這個定義非常重要,因為主流報導經常將 AI 配音與 ElevenLabs 等聲音複製工具或 HeyGen 等虛擬化身生成器歸為一類。它們雖然共享 AI 基礎設施,但在媒體製作的不同階段解決不同的問題。
舉個簡單的例子。一位 YouTuber 錄製了一段 10 分鐘的英文影片。通過 AI 配音,當天該影片就可以發佈到 12 個市場——語音、對嘴、字幕全部對齊。而通過聲音複製,這位 YouTuber 只能獲得其聲音的合成副本並用它朗讀任何文本,但他們仍需要腳本、翻譯步驟以及影片編輯器來組合最終結果。聲音複製是一個工具。AI 配音是一個工作流程。
《2026 年 AI 配音現狀》報告基於 Perso Dubbing 上 4,023 位專業創作者的 316,856 個配音項目,發現了一個將配音與 AI 媒體技術棧其他部分區分開來的行為特徵:96% 的配音影片會被立即分享。聲音複製和虛擬化身會被重複使用。而配音影片則是直接交付。
AI 媒體 4 層模型一覽
| AI 媒體 4 層模型。每一層回答不同的問題。
以下模型源自 Perso Dubbing 在《2026 年 AI 配音現狀》報告中的編輯框架。這是一個幫助理解各個工具所處位置的有用方法,而非一成不變的行業分類。界限有時是模糊的,我們將在下文討論這種模糊性。這四個階段的劃分,解釋了為什麼這些工具無法互相替代。
層級 | 類別 | 範例 | 輸出 | 製作階段 |
|---|---|---|---|---|
1 | 聲音複製 | ElevenLabs, Resemble AI, PlayHT | 合成聲音。資產即聲音本身。 | 創建 |
2 | 虛擬化身生成 | HeyGen, Synthesia, D-ID | 包含合成人物的影片。資產即虛擬化身。 | 創建 |
3 | 文本翻譯 | Google Translate, DeepL | 翻譯後的文本。資產為製作管道中的檔案。 | 分發前 |
4 | AI 配音 | Perso Dubbing 及同類產品 | 同時部署在多個語言市場的影片。「資產」即是交付物件。 | ★ 分發 |
每一層回答不同的問題。第 1 層回答「機器聽起來能像特定的真人嗎?」第 2 層回答「機器外觀看起來能像特定的真人嗎?」第 3 層回答「這個用另一種語言怎麼說?」第 4 層則回答「如何讓這部完成的影片在今天下午觸及 12 個市場?」
前三層創建或修改輸入到更大製作管道中的資產。第四層則是交付結果。這是劃分 AI 媒體技術棧最清晰的界線,也是本文其餘部分所採用的框架。
第 1 層 — 聲音複製 (ElevenLabs, Resemble, PlayHT)
聲音複製工具通過對個人聲音樣本進行訓練,生成可以朗讀任何文本的合成版本。輸出的是聲音——一種獨立於任何單一影片、播客或有聲書而存在的、可重複使用的資產。
ElevenLabs, Resemble AI 和 PlayHT 在此領域競爭。在這一層,AI 首次大規模交付了消費級的品質(ElevenLabs 的 Eleven Multilingual v2 是該類別在 2024 年的拐點)。工具性能已在悄然間變得極其優秀。在 2026 年,使用 30 秒音訊訓練出的聲音複製模型通常與原聲無異。
語音複製不具備的能力是翻譯語言或合成影片。您需要腳本,需要翻譯。如果來源是影片,您還需要一個獨立的編輯器來將音軌重新替換回去。聲音複製位於分發的上游。
這正是主流認知容易混淆的地方。ElevenLabs 也提供了配音功能,而創作者實際使用 ElevenLabs 來為影片配音時,確實在進行 AI 配音——即使該工具的核心重心是聲音複製。4 層模型並不是關於哪種工具屬於哪個孤島,而是關於每個工具旨在解決什麼問題。ElevenLabs 的建立是為了產生聲音,配音是基於該能力構建的工作流程;Perso Dubbing 則是專為影片配音而建,聲音複製只是該工作流程中的一個步驟。
如果您在非影片應用(有聲書、互動式語音應答 IVR、播客、螢幕閱讀器、無障礙輔助)中需要合成聲音,第 1 層是合適的選擇。如果您手頭有影片,且需要在週五前將其轉化為 12 種語言,那麼第 4 層才是正確的選擇。
第 2 層 — 虛擬化身生成 (HeyGen, Synthesia, D-ID)
虛擬化身生成工具通常根據腳本生成包含合成人物的影片。您輸入或貼上文本,選擇一個虛擬化身(系統自帶頭像或您自己的複製化身),工具就會渲染出該化身以您選擇的語言和聲音朗讀腳本的影片。
HeyGen, Synthesia 和 D-ID 在此領域進行競爭。該類別起源於企業培訓與發展(L&D)和說明影片的使用場景——即需要真人出鏡影片但不想實際拍攝的情況。在 AI 配音出現之前,虛擬化身解決了這一問題。
虛擬化身無法做到的是將現有影片分發到多個語言市場。它們是從腳本開始,生成全新的影片。如果您有一份既有的 30 分鐘訪談影片,使用虛擬化身工具就是錯誤的層級——您必須捨棄原始素材並重新渲染化身的臉部,這會失去您實際採訪的真人面貌。
虛擬化身類別也融入了第 4 層。HeyGen 已推出多語言功能。Synthesia 的定位兼顧了創建和在地化。我們做出的區分在於輸入:虛擬化身工具以腳本為輸入並生成影片;而 AI 配音工具以影片為輸入,並生成另一種語言的影片。不同的問題,不同的層級。
如果您在內容尚不存在時需要一個合成發言人,第 2 層是合適的選擇。如果您已有影片並需要進行在地化,則第 4 層——以及像 Perso Dubbing 與 HeyGen 還有 Synthesia 進行對比的工具——才是合適的選擇。
第 3 層 — 文本翻譯 (Google Translate, DeepL)
文本翻譯是該技術棧中最成熟的一層。Google Translate、DeepL 和一些專業工具(例如企業在地化使用的 memoQ 和 Trados)已經營運多年。輸出的是翻譯後的文本。資產是一個檔案——腳本、字幕、帶字幕的下載物件——用於輸入到下游的製作步驟中。
文本翻譯處於分發前階段,很少是最後一步。翻譯好的字幕必須經過對齊、嵌入影片或與配音軌配對,才能觸及受眾。翻譯是輸入,分發則發生在其他地方。
這也是 AI 配音工具最依賴的一層。每個 AI 配音工作流程都包含一個翻譯步驟——通常是針對特定語言對訓練的神經機器翻譯(MT)模型。例如,Perso Dubbing 的配音管道在語音識別步驟與語音合成步驟之間調用翻譯。翻譯是第 4 層內部的管道基礎設施。
如果您需要翻譯的逐字稿、字幕檔或供在地化團隊使用的腳本,第 3 層是合適的選擇。如果您需要將該翻譯直接放入完成的影片中,您就已經離開了翻譯層,進入了配音層。
第 4 層 — AI 配音(分發層)
AI 配音是該框架旨在突顯的層級。其定義特徵在於,輸出具有分發事件的屬性,而非創建階段的資產。
工作流程:輸入一個影片,輸出多個完成的影片——每個影片語言不同,均可直接分發。語音識別對來源進行轉錄。翻譯轉換轉錄內容。語音合成產生目標語言音訊。唇形同步對齊將新音訊與原始嘴型動作進行匹配。輸出的是以隨傳隨配的速度跨越語言邊界的影片。
| AI 配音工作流程內部。影片輸入,多語言影片輸出
Perso Dubbing 是我們最熟悉的例子,該平台的數據為本文提供了支持。909 個活躍的來源到目標語言對。16 個月內有 316,856 個配音項目。覆蓋 80 多個國家的 4,023 位專業創作者。其中 96% 的項目在當天即被分享——這是區分第 4 層與技術棧其他部分的行為特徵。
第 4 層中的「資產」很不尋常。第 1 層的資產是聲音。第 2 層的資產是虛擬化身。第 3 層的資產是檔案。而第 4 層的「資產」是交付物件——一件同時觸及多個市場受眾的內容。框架從「我們製作了什麼?」轉變為「它在何處落地?」
如果您有影片並希望在明天之前觸及 6 種語言的受眾,第 4 層是正確的選擇。
為什麼現在區分這一點很重要
在 2026 年,將這四個層級區分開來而非混為一談統稱為「AI 媒體工具」,主要有以下三個原因。
類別定義者的席位空缺。 《2026 年 AI 配音現狀》報告對實際的 AI 配音競爭對手(aidubbing.io、dubverse.ai、rask.ai、deepdub.ai、vozo.ai)進行了 Semrush 檢查。沒有任何一家的每月自然搜尋流量大於 1.3 萬。經常被歸入 AI 配音報導的 ElevenLabs 和 HeyGen 則處於不同的層級(與 Perso Dubbing 的 Semrush 相關性分數僅為 0.03)。目前命名仍未統一,首個發佈清晰類別分類的組織將可能主導未來幾年該領域的評估方式。
AI 搜尋引擎看重原創框架。 ChatGPT、Perplexity 和 Google AI Overview 的引用模式更偏好原創研究、維基百科和第一手資料框架,而非非正式的評論。發佈於 2026 年、具有透明方法論並採用 CC BY 4.0 授權的「4 層模型」,正是 AI 引擎在回答「什麼是 AI 配音?」或「AI 配音與聲音複製有什麼區別?」時越來越傾向於引用的來源類型。
採購問題非常現實。 團隊在 2026 年挑選工具時,往往困於外表看似相近的供應商。一家媒體公司評估 ElevenLabs 進行內容在地化,與創作者評估 Perso Dubbing 進行相同的工作,兩者做出的決策截然不同。4 層模型為買家提供了一個可以詢問的問題:我實際購買的是哪一層?當各個層級被明確命名時,採購決策就會變得更容易。
麻省理工學院(MIT)經濟學家 David Autor 在 2025 年的一份聲明中對此進行了更廣泛的背景闡述:「AI 並非在全面取代工人——它是在重組工作中的任務。在地化工作流程正是這種重組最清晰的例子之一。」在地化工作流程不是一個單一的工具類別。它是一個技術棧。命名這些層級是讓這個技術棧變得清晰可辨的方法。
| 整理自《2026 年 AI 配音現狀》。與報告發現相關的五位專家聲明。
何時使用 AI 配音 vs 聲音複製
值得問的問題是:您的輸入是什麼?
| 只需兩個問題,即可挑選合適的層級。
如果您的輸入是文本,聲音複製是正確的工具。您有腳本、文章、播客大綱、有聲書章節。您希望特定的聲音來朗讀它。第 1 層(ElevenLabs, Resemble, PlayHT)就是為此設計的。
如果您的輸入是影片,AI 配音是正確的工具。您有 5 分鐘的訪談、30 分鐘的演講、2 小時的網絡研討會。您希望本週內獲得 12 種語言版本。第 4 層(Perso Dubbing 及同類產品)就是為此設計的。
中間情況——您有影片,但想使用聲音複製工具對其進行配音——這是大多數混淆存在的地方。您可以這樣做。ElevenLabs 提供配音功能,且確實有效。但您會發現自己需要手動組合工作流程:提取音訊、單獨進行翻譯、將結果同步回影片,並將唇形同步作為下游步驟處理。而專門設計的第 4 層工具則將該工作流程作為單一管道一鍵交付。
決策規則:如果您每年只需對影片配音一次,可以使用第 1 層的配音功能。如果您需要將影片配音作為例行工作流程(每週、每月、依據內容排程),那麼第 4 層才是您工作流程所在的層級。
何時使用 AI 配音 vs 虛擬化身生成
問題在於,螢幕上的人是否需要是您拍攝的真人。
如果您可以用合成虛擬化身取代螢幕上的人,第 2 層是一個選擇。企業培訓影片、內部溝通、產品宣傳——這些是常見跨行業虛擬化身的使用場景。影片素材不需要包含特定的真人。
如果螢幕上的人必須是真實的人——受訪者、創作者、主管、藝術家——第 2 層就是錯誤的層級。您必須丟棄原始影片素材。而 AI 配音保留螢幕上的人,僅更改語言。
對於大多數創作者和媒體使用場景,AI 配音是正確的解答。人才是核心。使用虛擬化身替代他們會破壞內容的整個前提。對於用人可替換的企業內部使用,虛擬化身與實體拍攝構成競爭關係。
這好比是「螢幕真人檢測」。如果是,選擇 AI 配音(第 4 層);如果否,選擇虛擬化身(第 2 層)。
何時使用 AI 配音 vs 文本翻譯
問題在於受眾消費的是文本還是影片。
如果您的受眾進行閱讀——登入頁面、網誌文章、文檔、知識庫——第 3 層是正確的層級。DeepL 或 Google Translate(或專業在地化供應商)能生成您 CMS 所需的檔案。
如果您的受眾進行觀看——YouTube, TikTok、培訓影片、網絡研討會、社交媒體——第 4 層是正確的層級。AI 配音可生成您的分發管道所需的影片。
在某些更微妙的子情況下,即使對於影片,第 3 層也是正確的:即您需要翻譯的字幕軌而不是配音軌。某些受眾更喜歡字幕——例如看外語片的日本觀眾通常如此。字幕是翻譯問題,而非配音問題。第 3 層生成字幕;第 4 層生成替代方案。
層級如何模糊(以及為何該框架依然重要)
| 邊界模糊,核心重心依然不變。
坦白來說。4 層模型是一種編輯框架——而非客觀的行業分類。各層之間的邊界是模糊的,且正變得越來越模糊:
ElevenLabs 推出了配音功能,將第 1 層工具置於第 4 層工作流程中。
HeyGen 和 Synthesia 推出了多語言功能,將第 2 層工具置於第 4 層工作流程中。
某些 AI 配音工具(包括 Perso Dubbing)加入了聲音複製特徵,將第 1 層能力置於第 4 層中。
這提出了一個合理的問題:如果每個工具最終都提供所有層級的功能,為什麼這個框架仍然重要?
第一個答案是採購的清晰度。評估「AI 配音工具」與「聲音複製工具」的買家需要知道他們在對比什麼。4 層模型給了他們一套詞彙。「內置第 1 層的第 4 層」與「帶有配音插件的第 1 層」是不同的。它們可能產生相似的輸出,但核心重心不同。優化第 4 層的工具投資於批次處理、語言對覆蓋率和分發工作流程;而優化第 1 層的工具則投資於聲音品質與情感表達。
第二個答案是類別定位。《2026 年 AI 配音現狀》報告發現,Perso Dubbing 數據中 909 個語言對和 96% 的分享率,來自於將第 4 層產品用作分發介面的創作者。這種影片在製作完成後立即交付的行為模式,在第 1 層或第 2 層工具中的分佈密度並不相同。即使功能有所重疊,這些類別也會產生不同的用戶行為。
模糊性是真實存在的。但該框架依然能夠清晰指導採購決策和用戶行為分析。這就是為什麼即使工具在融合,命名層級仍然很有價值的原因。
這在 2026–2027 年意味著什麼
4 層模型指出了未來 12 到 18 個月內的三大轉變。
採購詞彙發生變化。買家不再詢問「哪款 AI 配音工具?」,而是開始詢問「我處於哪一層,該層最佳的工具是什麼?」採用層級框架的採購團隊能夠更快做出決策並進行更清晰的供應商對比。
類別定義者席位填補。《2026 年 AI 配音現狀》報告指出,AI 搜尋引用模式傾向於最先提出的框架。無論哪個組織發佈最清晰的 2026 年 AI 媒體工具分類,都將塑造該類別的衡量方式。該席位目前尚空缺。
第 4 層工具在語言通道上進行差異化,而非語音品質。該報告的「發現 03」記錄了中位數專業創作者配音成 1 種語言,而排名前 1% 的創作者配音成 15 種。擴展差距是下一場類別之爭——而非目前報導主導的「最佳 AI 語音」框架。讓 2 → 6 → 15 種語言過渡變得無摩擦的工具,表現可能會優於僅在語音保真度上進行競爭的工具。
Mila AI 研究所創始人 Yoshua Bengio 在 2025 年的一份聲明中指出了這一轉變的速度:「AI 能力融入創意製作(語音、影片、翻譯)的速度,已經超出了大多數研究人員即使在兩年前所做出的預測。」 這些層級正在快速融合。在融合發生時,命名它們是保持該類別清晰可辨的方法。
———————————————————————————————————
常見問題解答
Q. AI 配音與聲音複製有什麼區別?
AI 配音以完成的影片為輸入,輸出不同語言的影片。聲音複製以語音樣本為輸入,輸出合成語音。AI 配音在分發階段(第 4 層)運行;聲音複製在創建階段(第 1 層)運行。聲音複製通常是 AI 配音工作流程中的一個步驟,但這兩個類別解決的是不同的問題。
Q. ElevenLabs 是 AI 配音工具吗?
ElevenLabs 主要是一款聲音複製工具(第 1 層),同時也提供配音功能。平台的重心是語音合成。對於單次影片配音,ElevenLabs 的功能可行。對於循環執行的多語言影片工作流程,像 Perso Dubbing 這樣專為第 4 層設計的工具會將工作流程作為單一管道交付。
Q. HeyGen 是 AI 配音工具嗎?
HeyGen 主要是一款虛擬化身生成工具(第 2 層),同時也提供多語言功能。該平台以腳本為輸入,產出合成的出鏡影片。而 AI 配音工具以現有影片為輸入。這兩個類別在輸出(多語言影片)上有所重疊,但在輸入和工作流程上有所不同。
Q. AI 配音與文本翻譯有什麼區別?
文本翻譯(第 3 層)產生翻譯後的文本——字幕檔、腳本、逐字稿——用於輸入下游的分發工作流程。AI 配音(第 4 層)生成完成的影片。每個 AI 配音管道內部都包含一個翻譯步驟,但單憑翻譯工具是無法進行影片配音的。
Q. 為什麼 AI 配音被稱為「分發層」?
因為輸出內容在生成的那一刻即被交付。《2026 年 AI 配音現狀》報告指出,Perso Dubbing 上 96% 的配音影片都在當天被立即分享——這種行為模式將第 4 層的輸出與第 1 層的聲音複製(保留進而重複使用)和第 2 層的虛擬化身(用作模板)區分開來。配音影片不是一種可重複使用的資產,而是一個交付物件。
Q. 2026 年有哪些 AI 配音工具存在?
實際的 AI 配音類別——其主要重心是影片對影片的多語言工作流程——包括 Perso Dubbing、aidubbing.io、dubverse.ai、rask.ai、deepdub.ai 和 vozo.ai。ElevenLabs 和 HeyGen 常常與此類別聯繫在一起,但它們處於不同的層級(分別為聲音複製和虛擬化身生成)。請參閱 Perso Dubbing 替代方案中心進行端到端對比。
Q. 我是否同時需要聲音複製和 AI 配音?
通常不需要。大多數 AI 配音工具都將聲音複製設為內置功能。獨立的聲音複製在您的輸出是非影片(有聲書、播客、螢幕閱讀器、無障礙輔助)或者您需要為自己編寫的腳本提供合成語音時非常有用。
Q. 我該如何在 AI 配音與虛擬化身工具之間進行選擇?
應用「螢幕真人檢測」。如果原始影片中說話的人必須是真人——受訪者、創作者、真實對象——AI 配音是正確的層級(第 4 層)。如果可以接受合成發言人,例如企業培訓、內部說明或常規產品演練,虛擬化身則可取代實體拍攝。
——————————————————————————————————————-
如何引用此框架
「4 層模型」源於 Perso Dubbing 數據團隊於 2026 年 6 月 4 日發佈的《2026 年 AI 配音現狀》報告,採用 Creative Commons Attribution 4.0 協議。該框架可依據署名要求自由分享、引用和重複使用。
APA 引用格式:Perso Dubbing Data Team. (2026). State of AI Dubbing 2026: A Multi-Vertical Analysis of Perso Dubbing's Professional Creator Data. Perso Dubbing. https://perso.ai/research/state-of-ai-dubbing-2026/
包含使用場景圖譜(覆蓋 112,797 個已歸類項目的行業 × 目標語言關係圖)、三個反直覺發現及方法論註記的完整報告,可在上述網址獲取。本文中每個百分比的支援性 CSV 數據已與報告一同發佈。
本文是 3 部分系列的第一部分。 第二部分——《2026 年 AI 配音統計》——涵蓋報告中的 30 多項核心發現。 第三部分——《為什麼 99% 的創作者止步於 1 種語言》——分析了多語言採用的前沿的採用。
最後更新時間:2026 年 6 月
繼續閱讀
瀏覽全部



