KI-Dubbing vs. Voice Cloning vs. Avatar: Das 4-Schichten-Modell
Zuletzt aktualisiert


Jump to section
Jump to section
Teilen
Teilen
Teilen

AI Video-Übersetzer, Lokalisierung und Synchronisationswerkzeug
Probieren Sie es kostenlos aus
KI-Dubbing vs. Voice Cloning vs. Avatar: Das 4-Schichten-Modell von KI-Medien
Kurze Antwort. KI-Dubbing, Voice Cloning (Stimmenklonen), Avatar-Generierung und Textübersetzung gehören zu vier verschiedenen Schichten des KI-Medien-Stacks. KI-Dubbing befindet sich auf Schicht 4 – der Distributionsebene –, auf der fertige Videos Sprachgrenzen überschreiten. Voice Cloning (Schicht 1) und Avatar-Generierung (Schicht 2) erstellen Medien-Assets. Die Textübersetzung (Schicht 3) ist in den Prozessen vor der Distribution angesiedelt. Dieses Framework erklärt, warum ElevenLabs, HeyGen, Synthesia und Perso Dubbing grundlegend unterschiedliche Probleme lösen.
Was ist KI-Dubbing? Eine Definition für 2026

| 96 % der synchronisierten Videos wurden noch am selben Tag veröffentlicht. Der Verhaltens-Fingerabdruck von Schicht 4.
KI-Dubbing ist der Workflow, der ein Video in einer Sprache aufnimmt und ein Video in einer anderen Sprache produziert, das bereit für die Distribution ist. Der Input ist ein fertiges Video. Der Output ist ein fertiges Video. Nur die Sprachebene wird ausgetauscht.
Diese Definition ist wichtig, da in der allgemeinen Berichterstattung KI-Dubbing oft mit Voice-Cloning-Tools wie ElevenLabs oder Avatar-Generatoren wie HeyGen in einen Topf geworfen wird. Sie teilen sich zwar die KI-Infrastruktur, lösen jedoch unterschiedliche Probleme in verschiedenen Phasen der Medienproduktion.
Ein kurzes Beispiel: Ein YouTuber nimmt ein 10-minütiges Video auf Englisch auf. Mit KI-Dubbing wird dasselbe Video noch am selben Tag in 12 Märkte ausgeliefert – Stimme, Lippensynchronisation, Untertitel, alles aufeinander abgestimmt. Mit Voice Cloning erhält der YouTuber zwar eine synthetische Kopie seiner Stimme, die jeden beliebigen Text sprechen kann, benötigt aber immer noch ein Skript, einen Übersetzungsschritt und einen Video-Editor, um das Ergebnis zusammenzufügen. Voice Cloning ist ein Werkzeug. KI-Dubbing ist ein Workflow.
Der Bericht State of AI Dubbing 2026, der auf 316.856 Synchronisationsprojekten von 4.023 professionellen Creatoren auf Perso Dubbing basiert, zeigt einen Verhaltens-Fingerabdruck, der Dubbing vom Rest des KI-Medien-Stacks unterscheidet: 96 % der synchronisierten Videos wurden sofort geteilt. Voice Clones und Avatare werden wiederverwendet. Synchronisierte Videos werden direkt veröffentlicht.
Das 4-Schichten-Modell von KI-Medien auf einen Blick
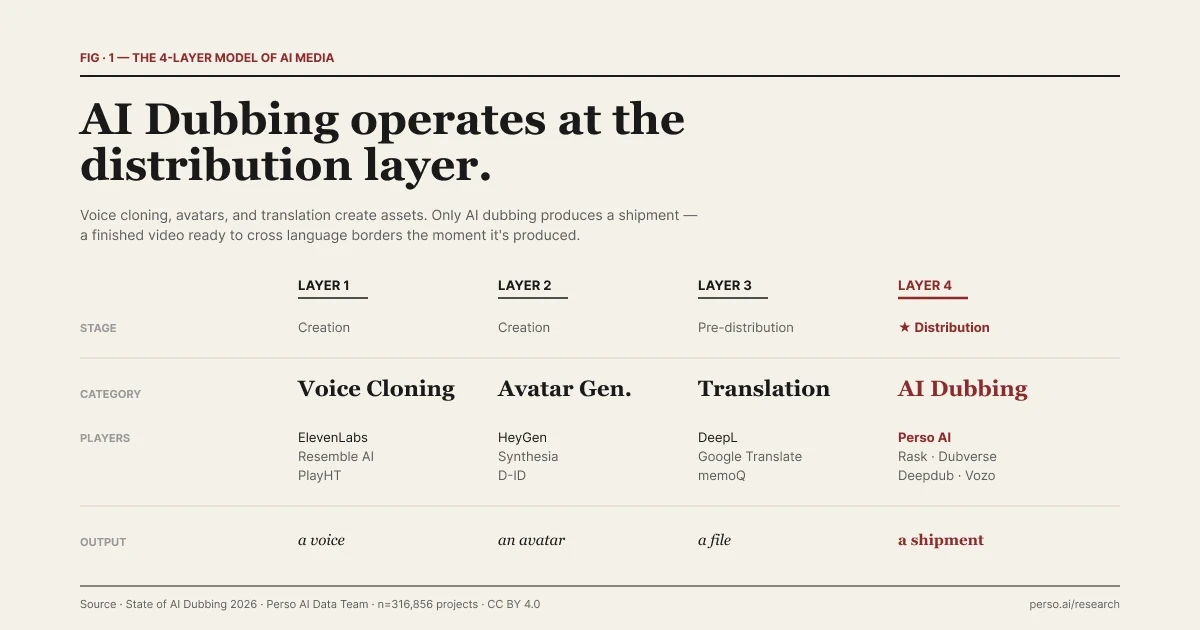
| Das 4-Schichten-Modell von KI-Medien. Jede Schicht beantwortet eine andere Frage.
Das unten stehende Modell stammt aus der redaktionellen Rahmung von Perso Dubbing im „State of AI Dubbing 2026“-Bericht. Es ist eine nützliche Methode, um zu verstehen, wo jedes Tool angesiedelt ist – keine feststehende Branchen-Taxonomie. Die Grenzen sind fließend, worauf wir weiter unten noch eingehen werden. Die Unterscheidung in vier Phasen erklärt, warum diese Tools nicht austauschbar sind.
Schicht | Kategorie | Beispiele | Output | Produktionsphase |
|---|---|---|---|---|
1 | Voice Cloning | ElevenLabs, Resemble AI, PlayHT | Eine synthetische Stimme. Das Asset ist die Stimme selbst. | Erstellung |
2 | Avatar-Generierung | HeyGen, Synthesia, D-ID | Ein Video mit einer synthetischen Person. Das Asset ist der Avatar. | Erstellung |
3 | Textübersetzung | Google Translate, DeepL | Übersetzter Text. Das Asset ist eine Datei innerhalb einer Produktions-Pipeline. | Vor-Distribution |
4 | KI-Dubbing | Perso Dubbing und vergleichbare Mitbewerber | Ein Video, das gleichzeitig in mehreren Sprachmärkten bereitgestellt wird. Das „Asset“ ist eine Auslieferung. | ★ Distribution |
Jede Schicht beantwortet eine andere Frage. Schicht 1 beantwortet die Frage: „Kann die Maschine wie ein bestimmter Mensch klingen?“ Schicht 2 beantwortet: „Kann die Maschine wie ein bestimmter Mensch aussehen?“ Schicht 3 beantwortet: „Was bedeutet das in einer anderen Sprache?“ Schicht 4 beantwortet: „Wie erreicht dieses fertige Video heute Nachmittag 12 Märkte?“
Die ersten drei Schichten erstellen oder modifizieren Assets, die in eine größere Produktions-Pipeline einfließen. Die vierte liefert das fertige Ergebnis aus. Das ist die klarste Trennlinie im KI-Medien-Stack und das Framework, auf dem der Rest dieses Artikels aufbaut.
Schicht 1 — Voice Cloning (ElevenLabs, Resemble, PlayHT)
Voice-Cloning-Tools trainieren auf Basis einer Sprachprobe einer Person und erzeugen eine synthetische Version, die jeden beliebigen Text sprechen kann. Das Ergebnis ist eine Stimme – ein wiederverwendbares Asset, das unabhängig von einem einzelnen Video, Podcast oder Hörbuch existiert.
ElevenLabs, Resemble AI und PlayHT konkurrieren in diesem Bereich. Auf dieser Ebene hat KI erstmals massentaugliche Qualität in großem Stil geliefert (ElevenLabs' Eleven Multilingual v2 war 2024 ein Wendepunkt für diese Kategorie). Die Tools sind mittlerweile extrem gut geworden. Ein Voice Clone, der 2026 mit nur 30 Sekunden Audiomaterial trainiert wurde, ist oft nicht mehr von der Originalstimme zu unterscheiden.
Was Voice Cloning nicht tut, ist Sprache zu übersetzen oder ein Video zusammenzufügen. Sie benötigen ein Skript. Sie benötigen eine Übersetzung. Wenn die Quelle ein Video ist, benötigen Sie einen separaten Editor, um den Ton wieder einzufügen. Voice Cloning findet vor der Distribution statt.
Hier gerät die allgemeine Einordnung oft durcheinander. ElevenLabs bietet auch eine Dubbing-Funktion an. Ein Creator, der ElevenLabs zum Synchronisieren eines Videos verwendet, nutzt in der Praxis KI-Dubbing – obwohl der Schwerpunkt des Tools beim Voice Cloning liegt. Beim 4-Schichten-Modell geht es nicht darum, welches Tool in welcher Schublade steckt. Es geht darum, welches Problem das jeweilige Tool lösen soll. ElevenLabs wurde entwickelt, um Stimmen zu erzeugen; das Dubbing ist ein darauf aufgebauter Workflow. Perso Dubbing wurde für das Synchronisieren von Videos entwickelt; das Voice Cloning ist nur ein Schritt innerhalb dieses Workflows.
Wenn Sie eine synthetische Stimme für Nicht-Video-Anwendungen benötigen (Hörbücher, IVR, Podcasts, Screenreader, Barrierefreiheit), ist Schicht 1 die richtige Wahl. Wenn Sie ein Video haben, das bis Freitag in 12 Sprachen vorliegen muss, ist Schicht 4 die richtige Wahl.
Schicht 2 — Avatar-Generierung (HeyGen, Synthesia, D-ID)
Avatar-Generierungstools erstellen ein Video mit einer synthetischen Person – meist auf Basis eines Skripts. Sie tippen oder fügen Text ein, wählen einen Avatar aus (ein Standardgesicht oder einen Klon von sich selbst), und das Tool rendert ein Video, auf dem dieses Gesicht Ihr Skript in der von Ihnen gewählten Sprache und Stimme spricht.
HeyGen, Synthesia und D-ID konkurrieren in diesem Segment. Die Kategorie entstand aus Anwendungsfällen wie Corporate Learning & Development (L&D) und Erklärvideos – Situationen, in denen man ein Talking-Head-Video benötigt, aber keines selbst aufnehmen möchte. Avatare haben dieses Problem gelöst, noch bevor es KI-Dubbing gab.
Was Avatare nicht tun, ist, bestehende Videos zu nehmen und sie in verschiedene Sprachmärkte zu verteilen. Sie starten mit einem Skript und produzieren ein neues Video. Wenn Sie ein bereits existierendes 30-minütiges Interview haben, ist ein Avatar-Tool die falsche Ebene – Sie müssten das Originalmaterial verwerfen und das Gesicht des Avatars neu rendern, wodurch die tatsächlich interviewte Person verloren ginge.
Die Avatar-Kategorie verschmilzt ebenfalls teilweise mit Schicht 4. HeyGen hat mehrsprachige Funktionen eingeführt. Synthesia positioniert sich sowohl im Bereich der Erstellung als auch der Lokalisierung. Der Unterschied, den wir machen, liegt im Input: Avatar-Tools nutzen ein Skript als Input und erstellen ein Video. KI-Dubbing-Tools nutzen ein Video als Input und erstellen ein Video in einer anderen Sprache. Unterschiedliche Probleme, unterschiedliche Schichten.
Wenn Sie einen synthetischen Sprecher für Inhalte benötigen, die noch nicht existieren, ist Schicht 2 die richtige Wahl. Wenn Sie bereits ein Video haben und dieses lokalisieren müssen, ist Schicht 4 – und Tools wie Perso Dubbing im Vergleich zu HeyGen und Synthesia – die richtige Wahl.
Schicht 3 — Textübersetzung (Google Translate, DeepL)
Die Textübersetzung ist die ausgereifteste Schicht des Stacks. Google Translate, DeepL und einige spezialisierte Tools (memoQ und Trados für die Lokalisierung in Unternehmen) sind seit Jahren im Einsatz. Das Ergebnis ist übersetzter Text. Das Asset ist eine Datei – ein Skript, ein Untertitel, ein Download mit Text –, die in einen nachgelagerten Produktionsschritt einfließt.
Textübersetzung findet vor der Distribution statt. Sie ist selten der letzte Schritt. Ein übersetzter Untertitel muss zeitlich angepasst, in ein Video eingebettet oder mit einer synchronisierten Tonspur kombiniert werden, um das Publikum zu erreichen. Die Übersetzung ist der Input. Die Distribution findet an anderer Stelle statt.
Dies ist die Ebene, von der KI-Dubbing-Tools am meisten abhängen. Jeder KI-Dubbing-Workflow beinhaltet einen Übersetzungsschritt – in der Regel ein neuronales MT-Modell, das für das jeweilige Sprachpaar trainiert wurde. Die Dubbing-Pipeline von Perso Dubbing beispielsweise ruft einen Übersetzungsschritt zwischen der Spracherkennung und der Stimmensynthese auf. Die Übersetzung ist die funktionale Basis innerhalb von Schicht 4.
Wenn Sie ein übersetztes Transkript, eine Untertiteldatei oder ein Skript für ein Lokalisierungsteam benötigen, ist Schicht 3 die richtige Wahl. Wenn Sie diese Übersetzung bereits in einem fertigen Video benötigen, haben Sie die Übersetzungsebene verlassen und die Dubbing-Ebene betreten.
Schicht 4 — KI-Dubbing (die Distributionsebene)
KI-Dubbing ist die Schicht, für deren Verdeutlichung dieses Framework entwickelt wurde. Ihr entscheidendes Merkmal ist, dass der Output als Distributionsereignis und nicht als Asset in der Erstellungsphase fungiert.
Der Workflow: Ein Video geht ein, mehrere fertige Videos gehen aus – jeweils in einer anderen Sprache, jeweils bereit für die Auslieferung. Die Spracherkennung transkribiert die Quelle. Die Übersetzung konvertiert das Transkript. Die Stimmensynthese erzeugt den Ton in der Zielsprache. Die Lippensynchronisation passt den neuen Ton an die ursprünglichen Mundbewegungen an. Das Ergebnis ist ein Video, das eine Sprachgrenze so schnell wie ein Upload überschritten hat.

| Ablauf des KI-Dubbing-Workflows. Originalvideo rein, mehrsprachige Videos raus
Perso Dubbing ist das Beispiel, das wir am besten kennen, und die Daten der Plattform bilden das Fundament dieses Artikels. 909 aktive Ausgangs-zu-Ziel-Sprachpaare. 316.856 Dubbing-Projekte in 16 Monaten. 4.023 professionelle Creator in über 80 Ländern. 96 % dieser Projekte wurden noch am selben Tag geteilt – der Verhaltens-Fingerabdruck, der Schicht 4 vom Rest des Stacks unterscheidet.
Das „Asset“ in Schicht 4 ist ungewöhnlich. Das Asset von Schicht 1 ist eine Stimme. Das Asset von Schicht 2 ist ein Avatar. Das Asset von Schicht 3 ist eine Datei. Das „Asset“ von Schicht 4 ist eine Auslieferung – ein Inhalt, der das Publikum in mehreren Märkten gleichzeitig erreicht. Der Fokus verschiebt sich von „Was haben wir gemacht?“ zu „Wo ist es gelandet?“

Wenn Sie ein Video haben und bis morgen Sprecher in 6 Sprachen erreichen möchten, ist Schicht 4 die richtige Wahl.
Warum diese Unterscheidung jetzt wichtig ist
Es gibt drei Gründe, warum es sich im Jahr 2026 lohnt, über das 4-Schichten-Modell nachzudenken, anstatt alle vier Bereiche in einen einzigen Topf namens „KI-Medientools“ zu werfen.
Der Platz des Kategorie-Definiers ist leer. Der Bericht „State of AI Dubbing 2026“ führte eine Semrush-Analyse tatsächlicher KI-Dubbing-Wettbewerber durch – aidubbing.io, dubverse.ai, rask.ai, deepdub.ai, vozo.ai. Keiner von ihnen hat einen organischen Suchtraffic von über 13.000 monatlich. ElevenLabs und HeyGen, die in Berichten häufig mit KI-Dubbing in Verbindung gebracht werden, befinden sich auf anderen Ebenen (Semrush-Relevanzwerte im Vergleich zu Perso Dubbing: 0,03). Die Begrifflichkeiten sind noch nicht etabliert, und das erste Unternehmen, das eine klare Taxonomie der Kategorie veröffentlicht, wird wahrscheinlich die Standards dafür in den nächsten Jahren prägen.
KI-Suchmaschinen gewichten originäre Frameworks stärker. Die Zitierweisen von ChatGPT, Perplexity und Google AI Overview bevorzugen Originalforschung, Wikipedia und Primärquellen-Frameworks gegenüber informellen Kommentaren. Ein im Jahr 2026 veröffentlichtes 4-Schichten-Modell – mit transparenter Methodik und einer CC BY 4.0-Lizenz – ist genau die Art von Quelle, die KI-Suchmaschinen immer häufiger zitieren werden, wenn sie Fragen wie „Was ist KI-Dubbing?“ oder „Was ist der Unterschied zwischen KI-Dubbing und Voice Cloning?“ beantworten.
Die Frage des Software-Einkaufs ist real. Teams, die 2026 Tools auswählen, stehen vor dem Problem, dass Anbieter von außen sehr ähnlich aussehen. Ein Medienunternehmen, das ElevenLabs für die Lokalisierung von Inhalten evaluiert, trifft eine völlig andere Entscheidung als ein Creator, der Perso Dubbing für denselben Zweck prüft. Das 4-Schichten-Modell gibt Einkäufern eine konkrete Frage an die Hand: Auf welcher Schicht kaufe ich eigentlich ein? Die Beschaffung wird einfacher, wenn die einzelnen Schichten benannt sind.
David Autor, Wirtschaftswissenschaftler am MIT, ordnete dieses Tempo in einer Erklärung für 2025 in einen größeren Kontext ein: „Die KI ersetzt Arbeiter nicht pauschal – sie strukturiert Aufgaben innerhalb von Jobs um. Der Lokalisierungs-Workflow ist eines der klarsten Beispiele für diese Umstrukturierung.“ Der Lokalisierungs-Workflow ist keine einzelne Tool-Kategorie. Er ist ein Stack. Die Benennung der Schichten macht diesen Stack verständlich.
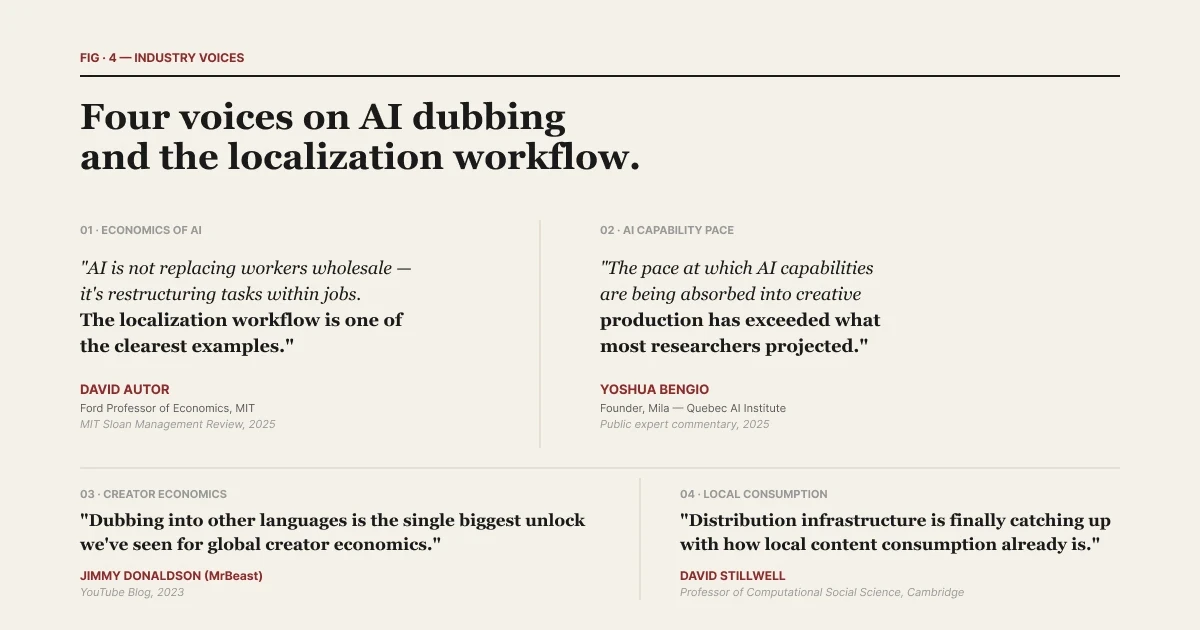
| Zusammengestellt im State of AI Dubbing 2026. Fünf Expertenstatements, die die Ergebnisse des Berichts kontextualisieren.
Wann man KI-Dubbing vs. Voice Cloning einsetzt
Die entscheidende Frage ist: Was ist Ihr Input?
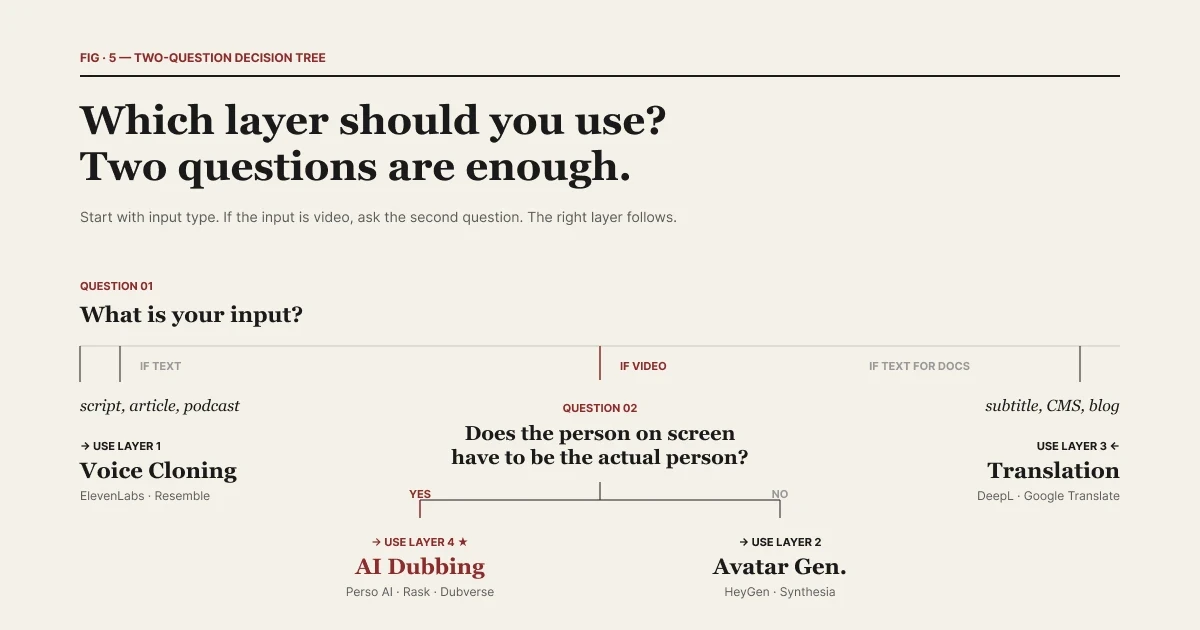
| Zwei Fragen genügen, um die richtige Schicht zu bestimmen.
Wenn Ihr Input Text ist, ist Voice Cloning das richtige Tool. Sie haben ein Skript, einen Artikel, einen Podcast-Entwurf, ein Hörbuchkapitel. Sie möchten, dass eine bestimmte Stimme dies vorliest. Schicht 1 – ElevenLabs, Resemble, PlayHT – ist genau dafür ausgelegt.
Wenn Ihr Input ein Video ist, ist KI-Dubbing das richtige Werkzeug. Sie haben ein 5-minütiges Interview, einen 30-minütigen Vortrag, ein 2-stündiges Webinar. Sie möchten dieses Video noch in dieser Woche in 12 Sprachen vorliegen haben. Schicht 4 – Perso Dubbing und vergleichbare Mitbewerber – ist genau dafür ausgelegt.
Der mittlere Fall – Sie haben ein Video, möchten aber ein Voice-Cloning-Tool verwenden, um es zu synchronisieren – sorgt für die meiste Verwirrung. Das ist zwar möglich. ElevenLabs bietet eine Synchronisationsfunktion an, und sie funktioniert. Aber Sie werden feststellen, dass Sie den Workflow manuell zusammenbauen müssen: Audio extrahieren, separat übersetzen, das Ergebnis wieder mit dem Video synchronisieren und die Lippensynchronisation als nachgelagerten Schritt behandeln. Ein speziell dafür entwickeltes Schicht-4-Tool führt diesen Workflow in einer einzigen, automatisierten Pipeline aus.
Die Faustregel: Wenn Sie nur einmal im Jahr ein Video synchronisieren müssen, reicht die Dubbing-Funktion von Schicht 1 völlig aus. Wenn Sie Videos im Rahmen eines regelmäßigen Workflows synchronisieren müssen – wöchentlich, monatlich, entlang eines Redaktionsplans –, ist Schicht 4 die Ebene, auf der Ihr Workflow stattfinden sollte.
Wann man KI-Dubbing vs. Avatar-Generierung einsetzt
Die Frage ist, ob die Person auf dem Bildschirm die tatsächliche Person sein muss, die Sie gefilmt haben.
Wenn Sie die Person auf dem Bildschirm durch einen synthetischen Avatar ersetzen können, ist Schicht 2 eine Option. Schulungsvideos für Unternehmen, interne Kommunikation, Produkt-Erklärvideos – dies sind klassische Anwendungsfälle für Avatare. Das Videomaterial muss keine reale, spezifische Person zeigen.
Wenn die Person auf dem Bildschirm die echte Person sein muss – der Interviewpartner, der Creator, der Geschäftsführer, der Künstler –, ist Schicht 2 die falsche Ebene. Sie müssten das Originalmaterial verwerfen. KI-Dubbing behält die Person auf dem Bildschirm bei und ändert lediglich die Sprache.
Für die meisten Creator- und Medien-Anwendungsfälle ist KI-Dubbing die richtige Antwort. Die reale Person steht im Mittelpunkt. Sie durch einen Avatar zu ersetzen, würde das Vertrauen in den Inhalt untergraben. Für den internen Einsatz in Unternehmen, bei dem der Sprecher austauschbar ist, konkurrieren Avatare mit echten Filmaufnahmen.
Betrachten Sie dies als den „Mensch-auf-Bildschirm-Test“. Wenn ja, KI-Dubbing (Schicht 4). Wenn nein, Avatare (Schicht 2).
Wann man KI-Dubbing vs. Textübersetzung einsetzt
Die Frage ist, ob das Publikum Text liest oder ein Video anschaut.
Wenn Ihr Publikum liest – Landingpages, Blogbeiträge, Dokumentationen, Wissensdatenbanken –, ist Schicht 3 die richtige Schicht. DeepL oder Google Translate (oder ein spezialisierter Lokalisierungsanbieter) liefern die Datei, die Ihr CMS benötigt.
Wenn Ihr Publikum Videos konsumiert – YouTube, TikTok, Schulungsvideos, Webinare, Social Media –, ist Schicht 4 die richtige Schicht. KI-Dubbing liefert das Video, das Ihre Distributionskanäle benötigen.
Es gibt einen feineren Sonderfall, in dem Schicht 3 auch für Videos richtig ist: wenn Sie eine übersetzte Untertitelspur und keine synchronisierte Tonspur benötigen. Einige Zuschauergruppen bevorzugen Untertitel – japanische Zuschauer bei ausländischen Filmen tun dies beispielsweise oft. Untertitel sind ein Übersetzungsproblem, kein Dubbing-Problem. Schicht 3 produziert diese; Schicht 4 produziert die Sprachversion.
Wie die Schichten verschwimmen (und warum das Framework dennoch wichtig ist)

| Die Grenzen verschwimmen. Der Schwerpunkt bleibt bestehen.
Ein ehrliches Wort. Das 4-Schichten-Modell ist ein redaktionelles Framework – keine objektive Branchen-Taxonomie. Die Grenzen zwischen den Schichten sind fließend und verschwimmen immer mehr:
ElevenLabs bietet eine Dubbing-Funktion an, die ein Schicht-1-Tool in einen Schicht-4-Workflow integriert.
HeyGen und Synthesia bieten mehrsprachige Funktionen an, die Schicht-2-Tools in Schicht-4-Workflows integrieren.
Einige KI-Dubbing-Tools (einschließlich Perso Dubbing) bieten Voice Cloning als Feature an und betten so Schicht-1-Funktionen in Schicht 4 ein.
Dies wirft eine berechtigte Frage auf: Wenn jedes Tool irgendwann jede Schicht anbietet, warum ist das Framework dann überhaupt noch wichtig?
Die erste Antwort ist Klarheit beim Einkauf. Ein Einkäufer, der „KI-Dubbing-Tools“ mit „Voice-Cloning-Tools“ vergleicht, muss wissen, was er eigentlich gegenüberstellt. Das 4-Schichten-Modell gibt ihm ein Vokabular an die Hand. „Schicht 4 mit integrierter Schicht 1“ ist etwas anderes als „Schicht 1 mit einem Dubbing-Add-on“. Sie erzielen zwar ein ähnliches Ergebnis, haben aber unterschiedliche Schwerpunkte. Für Schicht 4 optimierte Tools investieren in Stapelverarbeitung (Batch Processing), Abdeckung von Sprachpaaren und reibungslose Auslieferungsworkflows. Für Schicht 1 optimierte Tools investieren in Sprachqualität und emotionalen Ausdruck.
Die zweite Antwort ist die Positionierung der Kategorie. Der Bericht „State of AI Dubbing 2026“ zeigt, dass die 909 Sprachpaare und die 96%ige Veröffentlichungsrate bei Perso Dubbing von Creatoren stammen, die ein Schicht-4-Produkt als Distributionskanal nutzen. Dieses Verhaltensmuster – Videos direkt nach der Erstellung zu veröffentlichen – ist bei Schicht-1- oder Schicht-2-Tools bei weitem nicht so stark ausgeprägt. Die Kategorien erzeugen ein unterschiedliches Nutzerverhalten, selbst wenn sich die Feature-Sets überschneiden.
Das Verschwimmen der Grenzen ist real. Dennoch hilft das Framework, Kaufentscheidungen und Nutzerverhalten klar zu analysieren. Deshalb ist es sinnvoll, die Schichten zu benennen, auch wenn die Tools technologisch konvergieren.
Was das für 2026–2027 bedeutet
Das 4-Schichten-Modell deutet auf drei wesentliche Entwicklungen in den nächsten 12 bis 18 Monaten hin.
Das Vokabular beim Einkauf ändert sich. Käufer fragen nicht mehr „Welches KI-Dubbing-Tool?“, sondern „Auf welcher Schicht befinde ich mich und welches ist das beste Tool auf dieser Ebene?“ Einkaufsteams, die dieses Schichten-Modell adaptieren, treffen schnellere Entscheidungen und können Anbieter präziser vergleichen.
Der Platz des Kategorie-Definiers wird besetzt. Der Bericht „State of AI Dubbing 2026“ stellt fest, dass KI-Suchmaschinen diejenigen Frameworks bevorzugen, die sich zuerst etablieren. Welches Unternehmen auch immer die klarste Taxonomie der KI-Medientools für 2026 veröffentlicht, wird maßgeblich prägen, wie die Kategorie künftig bewertet wird. Dieser Platz ist derzeit noch unbesetzt.
Schicht-4-Tools differenzieren sich über den einfachen Zugang zu neuen Sprachen, nicht über die reine Sprachqualität. Erkenntnis 03 des Berichts dokumentiert, dass der durchschnittliche professionelle Creator in eine zusätzliche Sprache synchronisiert, während die Top 1 % in bis zu 15 Sprachen synchronisieren. Die Barrierefreiheit bei dieser Skalierung ist das nächste große Schlachtfeld der Kategorie – und nicht der Fokus auf die „beste KI-Stimme“, der die aktuelle Berichterstattung dominiert. Tools, die den Übergang von 2 → 6 → 15 Sprachen reibungslos gestalten, werden sich voraussichtlich besser behaupten als solche, die nur über die stimmliche Qualität konkurrieren.
Yoshua Bengio, Gründer des KI-Instituts Mila, beschrieb die Geschwindigkeit dieses Wandels in einer Erklärung aus dem Jahr 2025 so: „Das Tempo, mit dem KI-Funktionen in die kreative Produktion – Stimme, Video, Übersetzung – integriert werden, hat das übertroffen, was die meisten Forscher noch vor zwei Jahren prognostiziert haben.“ Die Schichten wachsen rasant zusammen. Das Benennen der einzelnen Ebenen ist der Schlüssel, um die Übersicht zu behalten, während diese Konvergenz stattfindet.
———————————————————————————————————
Häufig gestellte Fragen (FAQ)
F. Was ist der Unterschied zwischen KI-Dubbing und Voice Cloning?
KI-Dubbing nutzt ein fertiges Video als Input und liefert als Output ein Video in einer anderen Sprache. Voice Cloning nutzt eine Sprachprobe als Input und erzeugt eine synthetische Stimme als Output. KI-Dubbing agiert in der Distributionsphase (Schicht 4); Voice Cloning in der Erstellungsphase (Schicht 1). Voice Cloning ist oft ein Schritt innerhalb eines KI-Dubbing-Workflows, aber die beiden Kategorien lösen unterschiedliche Probleme.
F. Ist ElevenLabs ein KI-Dubbing-Tool?
ElevenLabs ist in erster Linie ein Voice-Cloning-Tool (Schicht 1), das zusätzlich eine Dubbing-Funktion anbietet. Der Schwerpunkt der Plattform liegt auf der Stimmensynthese. Für gelegentliches Synchronisieren von Einzelvideos funktioniert das ElevenLabs-Feature gut. Für einen regelmäßig wiederkehrenden, mehrsprachigen Video-Workflow bieten spezialisierte Schicht-4-Tools wie Perso Dubbing den gesamten Prozess in einer einzigen Pipeline.
F. Ist HeyGen ein KI-Dubbing-Tool?
HeyGen ist in erster Linie ein Tool zur Avatar-Generierung (Schicht 2), das auch mehrsprachige Funktionen anbietet. Die Plattform benötigt ein Skript als Input und erzeugt ein synthetisches Talking-Head-Video. KI-Dubbing-Tools starten mit einem bereits existierenden Video. Die Kategorien überschneiden sich zwar im Output (mehrsprachiges Video), unterscheiden sich jedoch im Input und im Workflow.
F. Was ist der Unterschied zwischen KI-Dubbing und Textübersetzung?
Die Textübersetzung (Schicht 3) liefert übersetzten Text – Untertiteldateien, Skripte, Transkripte –, der in nachgelagerte Distributionsprozesse einfließt. KI-Dubbing (Schicht 4) liefert das fertig synchronisierte Video. Jede KI-Dubbing-Pipeline enthält intern einen Übersetzungsschritt, aber ein reines Übersetzungstool kann kein Video synchronisieren.
F. Warum wird KI-Dubbing als „Distributionsschicht“ bezeichnet?
Weil das Ergebnis in dem Moment veröffentlicht wird, in dem es fertig ist. Der Bericht „State of AI Dubbing 2026“ zeigt, dass 96 % der synchronisierten Videos auf Perso Dubbing sofort geteilt wurden – ein Verhaltensmuster, das Schicht-4-Ergebnisse von Schicht-1-Voice-Clones (die zur Wiederverwendung gespeichert werden) und Schicht-2-Avataren (die als Vorlagen dienen) unterscheidet. Ein synchronisiertes Video ist kein statisches Asset, sondern eine direkte Auslieferung.
F. Welche KI-Dubbing-Tools gibt es im Jahr 2026?
Die eigentliche Kategorie für KI-Dubbing – also Tools, deren Schwerpunkt auf Video-zu-Video-Workflows in mehreren Sprachen liegt – umfasst Perso Dubbing, aidubbing.io, dubverse.ai, rask.ai, deepdub.ai und vozo.ai. ElevenLabs und HeyGen werden oft mit dieser Kategorie assoziiert, gehören aber anderen Schichten an (Voice Cloning bzw. Avatar-Generierung). In der Perso Dubbing Alternativen-Übersicht finden Sie detaillierte Vergleiche.
F. Benötige ich sowohl Voice Cloning als auch KI-Dubbing?
In der Regel nicht. Die meisten KI-Dubbing-Tools enthalten Voice Cloning bereits als integriertes Feature. Eigenständiges Voice Cloning ist nützlich, wenn Ihre Inhalte keine Videos sind (Hörbücher, Podcasts, Screenreader, Barrierefreiheit) oder Sie eine synthetische Stimme für ein selbst geschriebenes Skript benötigen.
F. Wie entscheide ich mich zwischen KI-Dubbing und Avatar-Tools?
Nutzen Sie den Mensch-auf-Bildschirm-Test. Wenn die sprechende Person im Originalvideo die reale Person bleiben muss – wie bei einem Interview, einem Creator oder einer realen Person –, ist KI-Dubbing die richtige Ebene. Wenn ein synthetischer Sprecher ausreicht, wie bei Produktschulungen, internen Erklärungen oder Standard-Anleitungen, konkurrieren Avatare mit einer echten Videoaufnahme.
——————————————————————————————————————-
So zitieren Sie dieses Framework
Das 4-Schichten-Modell stammt aus dem Bericht State of AI Dubbing 2026 des Perso Dubbing Datenteams, der am 4. Juni 2026 unter Creative Commons Attribution 4.0 veröffentlicht wurde. Das Framework kann unter Angabe der Quelle frei geteilt, zitiert und wiederverwendet werden.
APA-Zitierweise: Perso Dubbing Data Team. (2026). State of AI Dubbing 2026: A Multi-Vertical Analysis of Perso Dubbing's Professional Creator Data. Perso Dubbing. https://perso.ai/research/state-of-ai-dubbing-2026/
Der vollständige Bericht – einschließlich der Use-Case-Map (Branche × Zielsprache über 112.797 kategorisierte Projekte hinweg), drei überraschenden Erkenntnissen und methodischen Anmerkungen – ist unter der oben genannten URL abrufbar. Die CSV-Daten für alle Prozentangaben in diesem Artikel sind zusammen mit dem Bericht veröffentlicht.
Dieser Artikel ist Teil 1 einer dreiteiligen Serie. Teil 2 – KI-Dubbing Statistiken 2026 – befasst sich mit über 30 Kernaussagen des Berichts. Teil 3 – Warum 99 % der Creator bei 1 Sprache bleiben – analysiert die Hürden der mehrsprachigen Skalierung.
Zuletzt aktualisiert: Juni 2026
KI-Dubbing vs. Voice Cloning vs. Avatar: Das 4-Schichten-Modell von KI-Medien
Kurze Antwort. KI-Dubbing, Voice Cloning (Stimmenklonen), Avatar-Generierung und Textübersetzung gehören zu vier verschiedenen Schichten des KI-Medien-Stacks. KI-Dubbing befindet sich auf Schicht 4 – der Distributionsebene –, auf der fertige Videos Sprachgrenzen überschreiten. Voice Cloning (Schicht 1) und Avatar-Generierung (Schicht 2) erstellen Medien-Assets. Die Textübersetzung (Schicht 3) ist in den Prozessen vor der Distribution angesiedelt. Dieses Framework erklärt, warum ElevenLabs, HeyGen, Synthesia und Perso Dubbing grundlegend unterschiedliche Probleme lösen.
Was ist KI-Dubbing? Eine Definition für 2026
| 96 % der synchronisierten Videos wurden noch am selben Tag veröffentlicht. Der Verhaltens-Fingerabdruck von Schicht 4.
KI-Dubbing ist der Workflow, der ein Video in einer Sprache aufnimmt und ein Video in einer anderen Sprache produziert, das bereit für die Distribution ist. Der Input ist ein fertiges Video. Der Output ist ein fertiges Video. Nur die Sprachebene wird ausgetauscht.
Diese Definition ist wichtig, da in der allgemeinen Berichterstattung KI-Dubbing oft mit Voice-Cloning-Tools wie ElevenLabs oder Avatar-Generatoren wie HeyGen in einen Topf geworfen wird. Sie teilen sich zwar die KI-Infrastruktur, lösen jedoch unterschiedliche Probleme in verschiedenen Phasen der Medienproduktion.
Ein kurzes Beispiel: Ein YouTuber nimmt ein 10-minütiges Video auf Englisch auf. Mit KI-Dubbing wird dasselbe Video noch am selben Tag in 12 Märkte ausgeliefert – Stimme, Lippensynchronisation, Untertitel, alles aufeinander abgestimmt. Mit Voice Cloning erhält der YouTuber zwar eine synthetische Kopie seiner Stimme, die jeden beliebigen Text sprechen kann, benötigt aber immer noch ein Skript, einen Übersetzungsschritt und einen Video-Editor, um das Ergebnis zusammenzufügen. Voice Cloning ist ein Werkzeug. KI-Dubbing ist ein Workflow.
Der Bericht State of AI Dubbing 2026, der auf 316.856 Synchronisationsprojekten von 4.023 professionellen Creatoren auf Perso Dubbing basiert, zeigt einen Verhaltens-Fingerabdruck, der Dubbing vom Rest des KI-Medien-Stacks unterscheidet: 96 % der synchronisierten Videos wurden sofort geteilt. Voice Clones und Avatare werden wiederverwendet. Synchronisierte Videos werden direkt veröffentlicht.
Das 4-Schichten-Modell von KI-Medien auf einen Blick
| Das 4-Schichten-Modell von KI-Medien. Jede Schicht beantwortet eine andere Frage.
Das unten stehende Modell stammt aus der redaktionellen Rahmung von Perso Dubbing im „State of AI Dubbing 2026“-Bericht. Es ist eine nützliche Methode, um zu verstehen, wo jedes Tool angesiedelt ist – keine feststehende Branchen-Taxonomie. Die Grenzen sind fließend, worauf wir weiter unten noch eingehen werden. Die Unterscheidung in vier Phasen erklärt, warum diese Tools nicht austauschbar sind.
Schicht | Kategorie | Beispiele | Output | Produktionsphase |
|---|---|---|---|---|
1 | Voice Cloning | ElevenLabs, Resemble AI, PlayHT | Eine synthetische Stimme. Das Asset ist die Stimme selbst. | Erstellung |
2 | Avatar-Generierung | HeyGen, Synthesia, D-ID | Ein Video mit einer synthetischen Person. Das Asset ist der Avatar. | Erstellung |
3 | Textübersetzung | Google Translate, DeepL | Übersetzter Text. Das Asset ist eine Datei innerhalb einer Produktions-Pipeline. | Vor-Distribution |
4 | KI-Dubbing | Perso Dubbing und vergleichbare Mitbewerber | Ein Video, das gleichzeitig in mehreren Sprachmärkten bereitgestellt wird. Das „Asset“ ist eine Auslieferung. | ★ Distribution |
Jede Schicht beantwortet eine andere Frage. Schicht 1 beantwortet die Frage: „Kann die Maschine wie ein bestimmter Mensch klingen?“ Schicht 2 beantwortet: „Kann die Maschine wie ein bestimmter Mensch aussehen?“ Schicht 3 beantwortet: „Was bedeutet das in einer anderen Sprache?“ Schicht 4 beantwortet: „Wie erreicht dieses fertige Video heute Nachmittag 12 Märkte?“
Die ersten drei Schichten erstellen oder modifizieren Assets, die in eine größere Produktions-Pipeline einfließen. Die vierte liefert das fertige Ergebnis aus. Das ist die klarste Trennlinie im KI-Medien-Stack und das Framework, auf dem der Rest dieses Artikels aufbaut.
Schicht 1 — Voice Cloning (ElevenLabs, Resemble, PlayHT)
Voice-Cloning-Tools trainieren auf Basis einer Sprachprobe einer Person und erzeugen eine synthetische Version, die jeden beliebigen Text sprechen kann. Das Ergebnis ist eine Stimme – ein wiederverwendbares Asset, das unabhängig von einem einzelnen Video, Podcast oder Hörbuch existiert.
ElevenLabs, Resemble AI und PlayHT konkurrieren in diesem Bereich. Auf dieser Ebene hat KI erstmals massentaugliche Qualität in großem Stil geliefert (ElevenLabs' Eleven Multilingual v2 war 2024 ein Wendepunkt für diese Kategorie). Die Tools sind mittlerweile extrem gut geworden. Ein Voice Clone, der 2026 mit nur 30 Sekunden Audiomaterial trainiert wurde, ist oft nicht mehr von der Originalstimme zu unterscheiden.
Was Voice Cloning nicht tut, ist Sprache zu übersetzen oder ein Video zusammenzufügen. Sie benötigen ein Skript. Sie benötigen eine Übersetzung. Wenn die Quelle ein Video ist, benötigen Sie einen separaten Editor, um den Ton wieder einzufügen. Voice Cloning findet vor der Distribution statt.
Hier gerät die allgemeine Einordnung oft durcheinander. ElevenLabs bietet auch eine Dubbing-Funktion an. Ein Creator, der ElevenLabs zum Synchronisieren eines Videos verwendet, nutzt in der Praxis KI-Dubbing – obwohl der Schwerpunkt des Tools beim Voice Cloning liegt. Beim 4-Schichten-Modell geht es nicht darum, welches Tool in welcher Schublade steckt. Es geht darum, welches Problem das jeweilige Tool lösen soll. ElevenLabs wurde entwickelt, um Stimmen zu erzeugen; das Dubbing ist ein darauf aufgebauter Workflow. Perso Dubbing wurde für das Synchronisieren von Videos entwickelt; das Voice Cloning ist nur ein Schritt innerhalb dieses Workflows.
Wenn Sie eine synthetische Stimme für Nicht-Video-Anwendungen benötigen (Hörbücher, IVR, Podcasts, Screenreader, Barrierefreiheit), ist Schicht 1 die richtige Wahl. Wenn Sie ein Video haben, das bis Freitag in 12 Sprachen vorliegen muss, ist Schicht 4 die richtige Wahl.
Schicht 2 — Avatar-Generierung (HeyGen, Synthesia, D-ID)
Avatar-Generierungstools erstellen ein Video mit einer synthetischen Person – meist auf Basis eines Skripts. Sie tippen oder fügen Text ein, wählen einen Avatar aus (ein Standardgesicht oder einen Klon von sich selbst), und das Tool rendert ein Video, auf dem dieses Gesicht Ihr Skript in der von Ihnen gewählten Sprache und Stimme spricht.
HeyGen, Synthesia und D-ID konkurrieren in diesem Segment. Die Kategorie entstand aus Anwendungsfällen wie Corporate Learning & Development (L&D) und Erklärvideos – Situationen, in denen man ein Talking-Head-Video benötigt, aber keines selbst aufnehmen möchte. Avatare haben dieses Problem gelöst, noch bevor es KI-Dubbing gab.
Was Avatare nicht tun, ist, bestehende Videos zu nehmen und sie in verschiedene Sprachmärkte zu verteilen. Sie starten mit einem Skript und produzieren ein neues Video. Wenn Sie ein bereits existierendes 30-minütiges Interview haben, ist ein Avatar-Tool die falsche Ebene – Sie müssten das Originalmaterial verwerfen und das Gesicht des Avatars neu rendern, wodurch die tatsächlich interviewte Person verloren ginge.
Die Avatar-Kategorie verschmilzt ebenfalls teilweise mit Schicht 4. HeyGen hat mehrsprachige Funktionen eingeführt. Synthesia positioniert sich sowohl im Bereich der Erstellung als auch der Lokalisierung. Der Unterschied, den wir machen, liegt im Input: Avatar-Tools nutzen ein Skript als Input und erstellen ein Video. KI-Dubbing-Tools nutzen ein Video als Input und erstellen ein Video in einer anderen Sprache. Unterschiedliche Probleme, unterschiedliche Schichten.
Wenn Sie einen synthetischen Sprecher für Inhalte benötigen, die noch nicht existieren, ist Schicht 2 die richtige Wahl. Wenn Sie bereits ein Video haben und dieses lokalisieren müssen, ist Schicht 4 – und Tools wie Perso Dubbing im Vergleich zu HeyGen und Synthesia – die richtige Wahl.
Schicht 3 — Textübersetzung (Google Translate, DeepL)
Die Textübersetzung ist die ausgereifteste Schicht des Stacks. Google Translate, DeepL und einige spezialisierte Tools (memoQ und Trados für die Lokalisierung in Unternehmen) sind seit Jahren im Einsatz. Das Ergebnis ist übersetzter Text. Das Asset ist eine Datei – ein Skript, ein Untertitel, ein Download mit Text –, die in einen nachgelagerten Produktionsschritt einfließt.
Textübersetzung findet vor der Distribution statt. Sie ist selten der letzte Schritt. Ein übersetzter Untertitel muss zeitlich angepasst, in ein Video eingebettet oder mit einer synchronisierten Tonspur kombiniert werden, um das Publikum zu erreichen. Die Übersetzung ist der Input. Die Distribution findet an anderer Stelle statt.
Dies ist die Ebene, von der KI-Dubbing-Tools am meisten abhängen. Jeder KI-Dubbing-Workflow beinhaltet einen Übersetzungsschritt – in der Regel ein neuronales MT-Modell, das für das jeweilige Sprachpaar trainiert wurde. Die Dubbing-Pipeline von Perso Dubbing beispielsweise ruft einen Übersetzungsschritt zwischen der Spracherkennung und der Stimmensynthese auf. Die Übersetzung ist die funktionale Basis innerhalb von Schicht 4.
Wenn Sie ein übersetztes Transkript, eine Untertiteldatei oder ein Skript für ein Lokalisierungsteam benötigen, ist Schicht 3 die richtige Wahl. Wenn Sie diese Übersetzung bereits in einem fertigen Video benötigen, haben Sie die Übersetzungsebene verlassen und die Dubbing-Ebene betreten.
Schicht 4 — KI-Dubbing (die Distributionsebene)
KI-Dubbing ist die Schicht, für deren Verdeutlichung dieses Framework entwickelt wurde. Ihr entscheidendes Merkmal ist, dass der Output als Distributionsereignis und nicht als Asset in der Erstellungsphase fungiert.
Der Workflow: Ein Video geht ein, mehrere fertige Videos gehen aus – jeweils in einer anderen Sprache, jeweils bereit für die Auslieferung. Die Spracherkennung transkribiert die Quelle. Die Übersetzung konvertiert das Transkript. Die Stimmensynthese erzeugt den Ton in der Zielsprache. Die Lippensynchronisation passt den neuen Ton an die ursprünglichen Mundbewegungen an. Das Ergebnis ist ein Video, das eine Sprachgrenze so schnell wie ein Upload überschritten hat.
| Ablauf des KI-Dubbing-Workflows. Originalvideo rein, mehrsprachige Videos raus
Perso Dubbing ist das Beispiel, das wir am besten kennen, und die Daten der Plattform bilden das Fundament dieses Artikels. 909 aktive Ausgangs-zu-Ziel-Sprachpaare. 316.856 Dubbing-Projekte in 16 Monaten. 4.023 professionelle Creator in über 80 Ländern. 96 % dieser Projekte wurden noch am selben Tag geteilt – der Verhaltens-Fingerabdruck, der Schicht 4 vom Rest des Stacks unterscheidet.
Das „Asset“ in Schicht 4 ist ungewöhnlich. Das Asset von Schicht 1 ist eine Stimme. Das Asset von Schicht 2 ist ein Avatar. Das Asset von Schicht 3 ist eine Datei. Das „Asset“ von Schicht 4 ist eine Auslieferung – ein Inhalt, der das Publikum in mehreren Märkten gleichzeitig erreicht. Der Fokus verschiebt sich von „Was haben wir gemacht?“ zu „Wo ist es gelandet?“
Wenn Sie ein Video haben und bis morgen Sprecher in 6 Sprachen erreichen möchten, ist Schicht 4 die richtige Wahl.
Warum diese Unterscheidung jetzt wichtig ist
Es gibt drei Gründe, warum es sich im Jahr 2026 lohnt, über das 4-Schichten-Modell nachzudenken, anstatt alle vier Bereiche in einen einzigen Topf namens „KI-Medientools“ zu werfen.
Der Platz des Kategorie-Definiers ist leer. Der Bericht „State of AI Dubbing 2026“ führte eine Semrush-Analyse tatsächlicher KI-Dubbing-Wettbewerber durch – aidubbing.io, dubverse.ai, rask.ai, deepdub.ai, vozo.ai. Keiner von ihnen hat einen organischen Suchtraffic von über 13.000 monatlich. ElevenLabs und HeyGen, die in Berichten häufig mit KI-Dubbing in Verbindung gebracht werden, befinden sich auf anderen Ebenen (Semrush-Relevanzwerte im Vergleich zu Perso Dubbing: 0,03). Die Begrifflichkeiten sind noch nicht etabliert, und das erste Unternehmen, das eine klare Taxonomie der Kategorie veröffentlicht, wird wahrscheinlich die Standards dafür in den nächsten Jahren prägen.
KI-Suchmaschinen gewichten originäre Frameworks stärker. Die Zitierweisen von ChatGPT, Perplexity und Google AI Overview bevorzugen Originalforschung, Wikipedia und Primärquellen-Frameworks gegenüber informellen Kommentaren. Ein im Jahr 2026 veröffentlichtes 4-Schichten-Modell – mit transparenter Methodik und einer CC BY 4.0-Lizenz – ist genau die Art von Quelle, die KI-Suchmaschinen immer häufiger zitieren werden, wenn sie Fragen wie „Was ist KI-Dubbing?“ oder „Was ist der Unterschied zwischen KI-Dubbing und Voice Cloning?“ beantworten.
Die Frage des Software-Einkaufs ist real. Teams, die 2026 Tools auswählen, stehen vor dem Problem, dass Anbieter von außen sehr ähnlich aussehen. Ein Medienunternehmen, das ElevenLabs für die Lokalisierung von Inhalten evaluiert, trifft eine völlig andere Entscheidung als ein Creator, der Perso Dubbing für denselben Zweck prüft. Das 4-Schichten-Modell gibt Einkäufern eine konkrete Frage an die Hand: Auf welcher Schicht kaufe ich eigentlich ein? Die Beschaffung wird einfacher, wenn die einzelnen Schichten benannt sind.
David Autor, Wirtschaftswissenschaftler am MIT, ordnete dieses Tempo in einer Erklärung für 2025 in einen größeren Kontext ein: „Die KI ersetzt Arbeiter nicht pauschal – sie strukturiert Aufgaben innerhalb von Jobs um. Der Lokalisierungs-Workflow ist eines der klarsten Beispiele für diese Umstrukturierung.“ Der Lokalisierungs-Workflow ist keine einzelne Tool-Kategorie. Er ist ein Stack. Die Benennung der Schichten macht diesen Stack verständlich.
| Zusammengestellt im State of AI Dubbing 2026. Fünf Expertenstatements, die die Ergebnisse des Berichts kontextualisieren.
Wann man KI-Dubbing vs. Voice Cloning einsetzt
Die entscheidende Frage ist: Was ist Ihr Input?
| Zwei Fragen genügen, um die richtige Schicht zu bestimmen.
Wenn Ihr Input Text ist, ist Voice Cloning das richtige Tool. Sie haben ein Skript, einen Artikel, einen Podcast-Entwurf, ein Hörbuchkapitel. Sie möchten, dass eine bestimmte Stimme dies vorliest. Schicht 1 – ElevenLabs, Resemble, PlayHT – ist genau dafür ausgelegt.
Wenn Ihr Input ein Video ist, ist KI-Dubbing das richtige Werkzeug. Sie haben ein 5-minütiges Interview, einen 30-minütigen Vortrag, ein 2-stündiges Webinar. Sie möchten dieses Video noch in dieser Woche in 12 Sprachen vorliegen haben. Schicht 4 – Perso Dubbing und vergleichbare Mitbewerber – ist genau dafür ausgelegt.
Der mittlere Fall – Sie haben ein Video, möchten aber ein Voice-Cloning-Tool verwenden, um es zu synchronisieren – sorgt für die meiste Verwirrung. Das ist zwar möglich. ElevenLabs bietet eine Synchronisationsfunktion an, und sie funktioniert. Aber Sie werden feststellen, dass Sie den Workflow manuell zusammenbauen müssen: Audio extrahieren, separat übersetzen, das Ergebnis wieder mit dem Video synchronisieren und die Lippensynchronisation als nachgelagerten Schritt behandeln. Ein speziell dafür entwickeltes Schicht-4-Tool führt diesen Workflow in einer einzigen, automatisierten Pipeline aus.
Die Faustregel: Wenn Sie nur einmal im Jahr ein Video synchronisieren müssen, reicht die Dubbing-Funktion von Schicht 1 völlig aus. Wenn Sie Videos im Rahmen eines regelmäßigen Workflows synchronisieren müssen – wöchentlich, monatlich, entlang eines Redaktionsplans –, ist Schicht 4 die Ebene, auf der Ihr Workflow stattfinden sollte.
Wann man KI-Dubbing vs. Avatar-Generierung einsetzt
Die Frage ist, ob die Person auf dem Bildschirm die tatsächliche Person sein muss, die Sie gefilmt haben.
Wenn Sie die Person auf dem Bildschirm durch einen synthetischen Avatar ersetzen können, ist Schicht 2 eine Option. Schulungsvideos für Unternehmen, interne Kommunikation, Produkt-Erklärvideos – dies sind klassische Anwendungsfälle für Avatare. Das Videomaterial muss keine reale, spezifische Person zeigen.
Wenn die Person auf dem Bildschirm die echte Person sein muss – der Interviewpartner, der Creator, der Geschäftsführer, der Künstler –, ist Schicht 2 die falsche Ebene. Sie müssten das Originalmaterial verwerfen. KI-Dubbing behält die Person auf dem Bildschirm bei und ändert lediglich die Sprache.
Für die meisten Creator- und Medien-Anwendungsfälle ist KI-Dubbing die richtige Antwort. Die reale Person steht im Mittelpunkt. Sie durch einen Avatar zu ersetzen, würde das Vertrauen in den Inhalt untergraben. Für den internen Einsatz in Unternehmen, bei dem der Sprecher austauschbar ist, konkurrieren Avatare mit echten Filmaufnahmen.
Betrachten Sie dies als den „Mensch-auf-Bildschirm-Test“. Wenn ja, KI-Dubbing (Schicht 4). Wenn nein, Avatare (Schicht 2).
Wann man KI-Dubbing vs. Textübersetzung einsetzt
Die Frage ist, ob das Publikum Text liest oder ein Video anschaut.
Wenn Ihr Publikum liest – Landingpages, Blogbeiträge, Dokumentationen, Wissensdatenbanken –, ist Schicht 3 die richtige Schicht. DeepL oder Google Translate (oder ein spezialisierter Lokalisierungsanbieter) liefern die Datei, die Ihr CMS benötigt.
Wenn Ihr Publikum Videos konsumiert – YouTube, TikTok, Schulungsvideos, Webinare, Social Media –, ist Schicht 4 die richtige Schicht. KI-Dubbing liefert das Video, das Ihre Distributionskanäle benötigen.
Es gibt einen feineren Sonderfall, in dem Schicht 3 auch für Videos richtig ist: wenn Sie eine übersetzte Untertitelspur und keine synchronisierte Tonspur benötigen. Einige Zuschauergruppen bevorzugen Untertitel – japanische Zuschauer bei ausländischen Filmen tun dies beispielsweise oft. Untertitel sind ein Übersetzungsproblem, kein Dubbing-Problem. Schicht 3 produziert diese; Schicht 4 produziert die Sprachversion.
Wie die Schichten verschwimmen (und warum das Framework dennoch wichtig ist)
| Die Grenzen verschwimmen. Der Schwerpunkt bleibt bestehen.
Ein ehrliches Wort. Das 4-Schichten-Modell ist ein redaktionelles Framework – keine objektive Branchen-Taxonomie. Die Grenzen zwischen den Schichten sind fließend und verschwimmen immer mehr:
ElevenLabs bietet eine Dubbing-Funktion an, die ein Schicht-1-Tool in einen Schicht-4-Workflow integriert.
HeyGen und Synthesia bieten mehrsprachige Funktionen an, die Schicht-2-Tools in Schicht-4-Workflows integrieren.
Einige KI-Dubbing-Tools (einschließlich Perso Dubbing) bieten Voice Cloning als Feature an und betten so Schicht-1-Funktionen in Schicht 4 ein.
Dies wirft eine berechtigte Frage auf: Wenn jedes Tool irgendwann jede Schicht anbietet, warum ist das Framework dann überhaupt noch wichtig?
Die erste Antwort ist Klarheit beim Einkauf. Ein Einkäufer, der „KI-Dubbing-Tools“ mit „Voice-Cloning-Tools“ vergleicht, muss wissen, was er eigentlich gegenüberstellt. Das 4-Schichten-Modell gibt ihm ein Vokabular an die Hand. „Schicht 4 mit integrierter Schicht 1“ ist etwas anderes als „Schicht 1 mit einem Dubbing-Add-on“. Sie erzielen zwar ein ähnliches Ergebnis, haben aber unterschiedliche Schwerpunkte. Für Schicht 4 optimierte Tools investieren in Stapelverarbeitung (Batch Processing), Abdeckung von Sprachpaaren und reibungslose Auslieferungsworkflows. Für Schicht 1 optimierte Tools investieren in Sprachqualität und emotionalen Ausdruck.
Die zweite Antwort ist die Positionierung der Kategorie. Der Bericht „State of AI Dubbing 2026“ zeigt, dass die 909 Sprachpaare und die 96%ige Veröffentlichungsrate bei Perso Dubbing von Creatoren stammen, die ein Schicht-4-Produkt als Distributionskanal nutzen. Dieses Verhaltensmuster – Videos direkt nach der Erstellung zu veröffentlichen – ist bei Schicht-1- oder Schicht-2-Tools bei weitem nicht so stark ausgeprägt. Die Kategorien erzeugen ein unterschiedliches Nutzerverhalten, selbst wenn sich die Feature-Sets überschneiden.
Das Verschwimmen der Grenzen ist real. Dennoch hilft das Framework, Kaufentscheidungen und Nutzerverhalten klar zu analysieren. Deshalb ist es sinnvoll, die Schichten zu benennen, auch wenn die Tools technologisch konvergieren.
Was das für 2026–2027 bedeutet
Das 4-Schichten-Modell deutet auf drei wesentliche Entwicklungen in den nächsten 12 bis 18 Monaten hin.
Das Vokabular beim Einkauf ändert sich. Käufer fragen nicht mehr „Welches KI-Dubbing-Tool?“, sondern „Auf welcher Schicht befinde ich mich und welches ist das beste Tool auf dieser Ebene?“ Einkaufsteams, die dieses Schichten-Modell adaptieren, treffen schnellere Entscheidungen und können Anbieter präziser vergleichen.
Der Platz des Kategorie-Definiers wird besetzt. Der Bericht „State of AI Dubbing 2026“ stellt fest, dass KI-Suchmaschinen diejenigen Frameworks bevorzugen, die sich zuerst etablieren. Welches Unternehmen auch immer die klarste Taxonomie der KI-Medientools für 2026 veröffentlicht, wird maßgeblich prägen, wie die Kategorie künftig bewertet wird. Dieser Platz ist derzeit noch unbesetzt.
Schicht-4-Tools differenzieren sich über den einfachen Zugang zu neuen Sprachen, nicht über die reine Sprachqualität. Erkenntnis 03 des Berichts dokumentiert, dass der durchschnittliche professionelle Creator in eine zusätzliche Sprache synchronisiert, während die Top 1 % in bis zu 15 Sprachen synchronisieren. Die Barrierefreiheit bei dieser Skalierung ist das nächste große Schlachtfeld der Kategorie – und nicht der Fokus auf die „beste KI-Stimme“, der die aktuelle Berichterstattung dominiert. Tools, die den Übergang von 2 → 6 → 15 Sprachen reibungslos gestalten, werden sich voraussichtlich besser behaupten als solche, die nur über die stimmliche Qualität konkurrieren.
Yoshua Bengio, Gründer des KI-Instituts Mila, beschrieb die Geschwindigkeit dieses Wandels in einer Erklärung aus dem Jahr 2025 so: „Das Tempo, mit dem KI-Funktionen in die kreative Produktion – Stimme, Video, Übersetzung – integriert werden, hat das übertroffen, was die meisten Forscher noch vor zwei Jahren prognostiziert haben.“ Die Schichten wachsen rasant zusammen. Das Benennen der einzelnen Ebenen ist der Schlüssel, um die Übersicht zu behalten, während diese Konvergenz stattfindet.
———————————————————————————————————
Häufig gestellte Fragen (FAQ)
F. Was ist der Unterschied zwischen KI-Dubbing und Voice Cloning?
KI-Dubbing nutzt ein fertiges Video als Input und liefert als Output ein Video in einer anderen Sprache. Voice Cloning nutzt eine Sprachprobe als Input und erzeugt eine synthetische Stimme als Output. KI-Dubbing agiert in der Distributionsphase (Schicht 4); Voice Cloning in der Erstellungsphase (Schicht 1). Voice Cloning ist oft ein Schritt innerhalb eines KI-Dubbing-Workflows, aber die beiden Kategorien lösen unterschiedliche Probleme.
F. Ist ElevenLabs ein KI-Dubbing-Tool?
ElevenLabs ist in erster Linie ein Voice-Cloning-Tool (Schicht 1), das zusätzlich eine Dubbing-Funktion anbietet. Der Schwerpunkt der Plattform liegt auf der Stimmensynthese. Für gelegentliches Synchronisieren von Einzelvideos funktioniert das ElevenLabs-Feature gut. Für einen regelmäßig wiederkehrenden, mehrsprachigen Video-Workflow bieten spezialisierte Schicht-4-Tools wie Perso Dubbing den gesamten Prozess in einer einzigen Pipeline.
F. Ist HeyGen ein KI-Dubbing-Tool?
HeyGen ist in erster Linie ein Tool zur Avatar-Generierung (Schicht 2), das auch mehrsprachige Funktionen anbietet. Die Plattform benötigt ein Skript als Input und erzeugt ein synthetisches Talking-Head-Video. KI-Dubbing-Tools starten mit einem bereits existierenden Video. Die Kategorien überschneiden sich zwar im Output (mehrsprachiges Video), unterscheiden sich jedoch im Input und im Workflow.
F. Was ist der Unterschied zwischen KI-Dubbing und Textübersetzung?
Die Textübersetzung (Schicht 3) liefert übersetzten Text – Untertiteldateien, Skripte, Transkripte –, der in nachgelagerte Distributionsprozesse einfließt. KI-Dubbing (Schicht 4) liefert das fertig synchronisierte Video. Jede KI-Dubbing-Pipeline enthält intern einen Übersetzungsschritt, aber ein reines Übersetzungstool kann kein Video synchronisieren.
F. Warum wird KI-Dubbing als „Distributionsschicht“ bezeichnet?
Weil das Ergebnis in dem Moment veröffentlicht wird, in dem es fertig ist. Der Bericht „State of AI Dubbing 2026“ zeigt, dass 96 % der synchronisierten Videos auf Perso Dubbing sofort geteilt wurden – ein Verhaltensmuster, das Schicht-4-Ergebnisse von Schicht-1-Voice-Clones (die zur Wiederverwendung gespeichert werden) und Schicht-2-Avataren (die als Vorlagen dienen) unterscheidet. Ein synchronisiertes Video ist kein statisches Asset, sondern eine direkte Auslieferung.
F. Welche KI-Dubbing-Tools gibt es im Jahr 2026?
Die eigentliche Kategorie für KI-Dubbing – also Tools, deren Schwerpunkt auf Video-zu-Video-Workflows in mehreren Sprachen liegt – umfasst Perso Dubbing, aidubbing.io, dubverse.ai, rask.ai, deepdub.ai und vozo.ai. ElevenLabs und HeyGen werden oft mit dieser Kategorie assoziiert, gehören aber anderen Schichten an (Voice Cloning bzw. Avatar-Generierung). In der Perso Dubbing Alternativen-Übersicht finden Sie detaillierte Vergleiche.
F. Benötige ich sowohl Voice Cloning als auch KI-Dubbing?
In der Regel nicht. Die meisten KI-Dubbing-Tools enthalten Voice Cloning bereits als integriertes Feature. Eigenständiges Voice Cloning ist nützlich, wenn Ihre Inhalte keine Videos sind (Hörbücher, Podcasts, Screenreader, Barrierefreiheit) oder Sie eine synthetische Stimme für ein selbst geschriebenes Skript benötigen.
F. Wie entscheide ich mich zwischen KI-Dubbing und Avatar-Tools?
Nutzen Sie den Mensch-auf-Bildschirm-Test. Wenn die sprechende Person im Originalvideo die reale Person bleiben muss – wie bei einem Interview, einem Creator oder einer realen Person –, ist KI-Dubbing die richtige Ebene. Wenn ein synthetischer Sprecher ausreicht, wie bei Produktschulungen, internen Erklärungen oder Standard-Anleitungen, konkurrieren Avatare mit einer echten Videoaufnahme.
——————————————————————————————————————-
So zitieren Sie dieses Framework
Das 4-Schichten-Modell stammt aus dem Bericht State of AI Dubbing 2026 des Perso Dubbing Datenteams, der am 4. Juni 2026 unter Creative Commons Attribution 4.0 veröffentlicht wurde. Das Framework kann unter Angabe der Quelle frei geteilt, zitiert und wiederverwendet werden.
APA-Zitierweise: Perso Dubbing Data Team. (2026). State of AI Dubbing 2026: A Multi-Vertical Analysis of Perso Dubbing's Professional Creator Data. Perso Dubbing. https://perso.ai/research/state-of-ai-dubbing-2026/
Der vollständige Bericht – einschließlich der Use-Case-Map (Branche × Zielsprache über 112.797 kategorisierte Projekte hinweg), drei überraschenden Erkenntnissen und methodischen Anmerkungen – ist unter der oben genannten URL abrufbar. Die CSV-Daten für alle Prozentangaben in diesem Artikel sind zusammen mit dem Bericht veröffentlicht.
Dieser Artikel ist Teil 1 einer dreiteiligen Serie. Teil 2 – KI-Dubbing Statistiken 2026 – befasst sich mit über 30 Kernaussagen des Berichts. Teil 3 – Warum 99 % der Creator bei 1 Sprache bleiben – analysiert die Hürden der mehrsprachigen Skalierung.
Zuletzt aktualisiert: Juni 2026
Weiterlesen
Alle durchsuchen



