Voiceover-Übersetzung: Die vollständige Anleitung für mehrsprachige Videos
Zuletzt aktualisiert


Jump to section
Jump to section
Teilen
Teilen
Teilen

AI Video-Übersetzer, Lokalisierung und Synchronisationswerkzeug
Probieren Sie es kostenlos aus
Kurze Antwort. Voiceover-Übersetzung ist der Workflow, bei dem ein bestehendes Voiceover – eine Erzählung, ein Erklärvideo-Audio oder ein aufgezeichneter Kommentar – übernommen und in einer anderen Sprache neu erstellt wird. Die KI-gestützte Voiceover-Übersetzung übernimmt drei Schritte automatisch: Spracherkennung, Übersetzung und Sprachsynthese in der Zielsprache. Mit Perso Dubbing können Sie in über 99 Sprachen übersetzen und die Stimme des Originalsprechers klonen, sodass die neue Sprache wie dieselbe Person klingt.
Was ist eine Voiceover-Übersetzung?
Die Voiceover-Übersetzung konvertiert eine aufgezeichnete Sprachaufnahme von einer Sprache in eine andere. Der Input ist Audio – manchmal an ein Video gekoppelt, manchmal eigenständig – und der Output ist Audio in einer anderen Sprache, bereit zur Veröffentlichung.
Diese Kategorie ist älter als KI. Studios haben dies jahrzehntelang manuell gemacht: einen Synchronsprecher in der Zielsprache engagieren, ihm ein übersetztes Skript in die Hand drücken, aufnehmen und wieder in das Video einmischen. Der Engpass waren immer die Kosten und die Zeit. Ein 5-minütiges Erklärvideo in drei Sprachen bedeutete früher drei Studiositzungen, drei Synchronsprecher und eine Woche Bearbeitungszeit.
KI hat den Arbeitsablauf verändert, ohne das Ziel zu ändern. Das Ergebnis ist immer noch ein Voiceover in einer anderen Sprache. Der Weg dorthin dauert jetzt jedoch Minuten statt Wochen.
Drei Arbeitsbereiche fallen unter die Voiceover-Übersetzung:
Der erste Bereich ist die lokalisierte Erzählung – Erklärvideos, E-Learning-Kurse, Dokumentarsprecher, Hörbuchkapitel. Das Original besteht aus einer einzigen Stimme über die gesamte Produktion hinweg. Das übersetzte Ergebnis behält dieselbe Stimme bei oder ersetzt sie durch ein Äquivalent in der Zielsprache.
Der zweite Bereich ist das Dialog-Dubbing – Filme, Dramen, Interview-Inhalte, bei denen mehrere Sprecher separat übersetzt werden müssen. Die Voiceover-Übersetzung ist hier das Arbeitstier, auch wenn die Branche es ab dem Moment, in dem mehrere Sprecher involviert sind, als „Dubbing“ (Synchronisation) bezeichnet.
Der dritte Bereich ist das Schnittstellen-Audio – IVR-Menüs, Stimmen zur App-Einführung, In-Produkt-Erzählungen. Ein kleinerer Umfang, aber im Hintergrund läuft dieselbe Übersetzungs- und Synthese-Pipeline.
Der Rest dieses Leitfadens konzentriert sich auf die ersten beiden Bereiche. Der dritte Bereich folgt demselben Workflow in kleinerem Maßstab.
Voiceover-Übersetzung vs. Dubbing – ist das dasselbe?
Größtenteils ja. Die Unterscheidung ist älter als der KI-Workflow und war noch nie ganz trennscharf.
Branchenüblicher Gebrauch:
Voiceover-Übersetzung bezieht sich in der Regel auf Inhalte im Erzählstil. Ein Sprecher. Dokumentation. Erklärvideo. Das Hörbuch. Das Voiceover liegt über dem Video, anstatt synchron zu den Mundbewegungen zu verlaufen.
Dubbing bezieht sich meist auf Dialoge. Mehrere Sprecher. Lippensynchronität ist wichtig. Film und Drama greifen standardmäßig auf diesen Begriff zurück.
In der Praxis ist die Grenze fließend. Wenn ein Ersteller ein YouTube-Video einspricht und dasselbe Video auf Spanisch haben möchte – ist das dann eine Voiceover-Übersetzung oder Dubbing? Beide Begriffe passen. Der Workflow ist identisch: Sprache rein → Übersetzung → Sprache raus → Einmischen ins Video.
Eine einfache Faustregel lautet: Betrachten Sie die Voiceover-Übersetzung als die übergeordnete Kategorie und Dubbing als den Fall, bei dem die lippensynchrone Ausrichtung Teil des Ergebnisses ist. Beide nutzen dieselbe KI-Pipeline. Das 4-Layer-Modell von KI-Medien ordnet dies dem Layer 4 – dem Distribution-Layer – zu, unabhängig davon, welchen Branchenbegriff Sie verwenden.
Der Rest dieses Leitfadens verwendet „Voiceover-Übersetzung“ als Oberbegriff. Wo Lippensynchronität eine Rolle spielt, weisen wir explizit darauf hin.
Wie KI-gestützte Voiceover-Übersetzung funktioniert
Die Pipeline besteht aus vier Schritten. Jeder Schritt dauert bei typischen Inhalten nur Sekunden oder wenige Minuten.
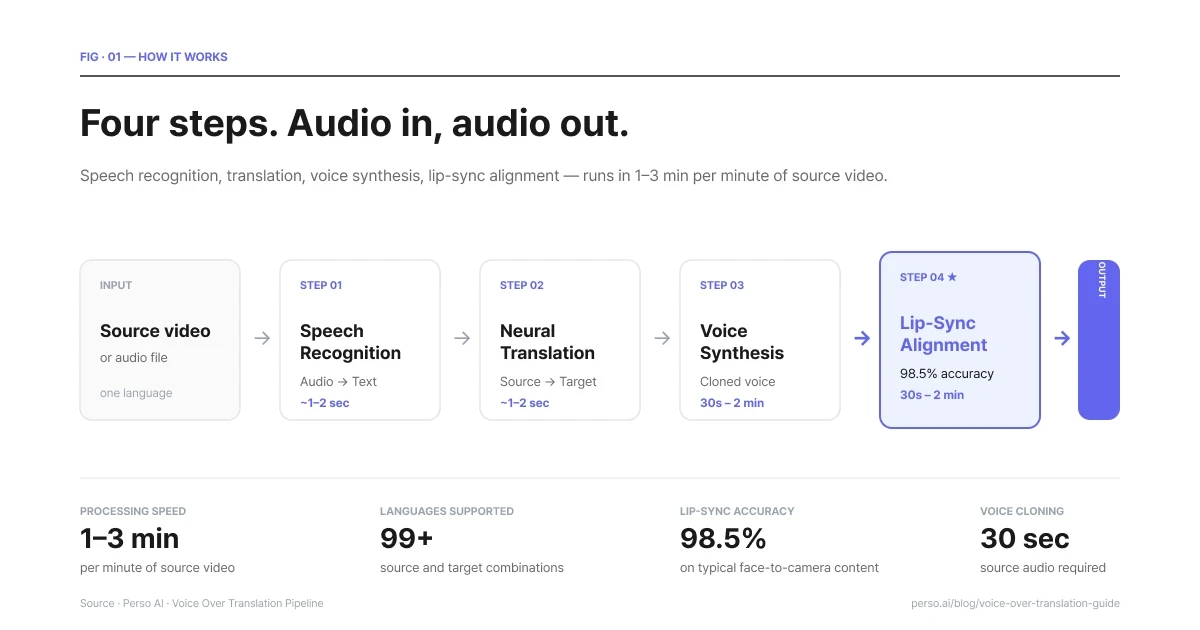
Vier Schritte. Audio rein, Audio raus. 1–3 Min. pro Minute des Quellvideos.
Schritt 1 – Spracherkennung. Das System transkribiert das Quellaudio in Text. Moderne Spracherkennung verarbeitet Akzente, Hintergrundmusik, mehrere Sprecher und natürliche Sprachmuster (Füllwörter, Pausen, Fehlstarts). Das Transkript ist das Fundament für jeden nachfolgenden Schritt, daher ist die Genauigkeit hier wichtiger, als den meisten bewusst ist. Ein schlechtes Transkript führt zu einer schlechten Übersetzung, was wiederum zu einem schlechten Voiceover führt.
Schritt 2 – Übersetzung. Das Transkript durchläuft eine neuronale Übersetzung, die auf gesprochene Sprache und nicht auf geschriebene Prosa abgestimmt ist. Gesprochene Sprache ist kürzer, idiomatischer und kontextabhängiger als geschriebener Text. Ein Übersetzungsmodell, das bei Dokumenten gut abschneidet, kann bei gesprochener Sprache versagen und umgekehrt. Das Ergebnis ist ein Skript in der Zielsprache, dessen Timing so genau wie möglich an das Tempo des Originals angepasst ist.
Schritt 3 – Sprachsynthese. Das übersetzte Skript wird in Sprache synthetisiert. Hierbei gibt es zwei Wege.
Der erste ist die Nutzung von Stock-Stimmen – wählen Sie eine Stimme aus einer Bibliothek aus und verwenden Sie sie. Das geht schnell und ist frei von Lizenzfragen, aber die neue Stimme klingt überhaupt nicht wie der Originalsprecher.
Der zweite Weg ist das Stimmenklonen (Voice Cloning) – trainieren Sie ein Modell mit der Stimme des Originalsprechers und synthetisieren Sie die Zielsprache in genau dieser Stimme. Das Ergebnis klingt wie dieselbe Person, die nun die neue Sprache spricht. Dies ist der Weg, den die meisten professionellen Arbeitsabläufe bei der Voiceover-Übersetzung bevorzugen.
Schritt 4 – Lippensynchronisation (wenn Video involviert ist). Wenn der Input ein Video ist, wird das synthetisierte Audio an die ursprünglichen Mundbewegungen angepasst. Moderne Systeme erreichen bei typischen Inhalten eine Genauigkeit von etwa 98 %. Ohne diesen Schritt läuft die neue Stimme über Mundbewegungen, die auf die Originalsprache abgestimmt sind, was die meisten Zuschauer innerhalb von Sekunden als unangenehm empfinden.
Perso Dubbing führt diese gesamte Pipeline als einen einzigen Workflow aus. Video hochladen, Zielsprachen auswählen, fertiges Video zurückbekommen. Die Gesamtbearbeitungszeit beträgt etwa 1 bis 3 Minuten pro Minute Quellvideo – ein 5-minütiges Video wird in etwa 5 bis 15 Minuten übersetzt.
Wann man eine Voiceover-Übersetzung benötigt
Die Entscheidung ist selten die Frage „Brauche ich überhaupt eine Übersetzung?“ – das ergibt sich meistens aus dem Business Case. Die Frage ist vielmehr, welches Übersetzungsformat man wählen sollte.
Eine Voiceover-Übersetzung ist sinnvoll, wenn:
Der Inhalt ein Video ist und Ihre Zielgruppe Videos konsumiert. Untertitel funktionieren für einige Zuschauergruppen, aber Analysen der Wiedergabezeit zeigen durchweg, dass synchronisierte Videos bei Nicht-Muttersprachlern besser abschneiden als untertitelte Videos. Der „State of AI Dubbing 2026“-Bericht stellte fest, dass 96 % der KI-synchronisierten Videos noch am selben Tag geteilt wurden, an dem sie erstellt wurden – das typische Verhaltensmuster von Inhalten, die für die Verbreitung und nicht für das Archiv bestimmt sind.
Sie bereits eine etablierte Stimme und Marke haben. Die Stimme eines Erstellers ist Teil seiner Marke. Die Stimme des Sprechers eines Unternehmens ist Teil seiner Identität. Eine Voiceover-Übersetzung mit Stimmenklonen hält diese Identität über verschiedene Sprachen hinweg aufrecht. Workflows mit Untertiteln verlieren diese Identität.
Ihre Zielgruppe mobil-first oder abgelenkt ist. Untertitelte Inhalte erfordern ungeteilte visuelle Aufmerksamkeit. Einer Voiceover-Übersetzung kann man im Auto, beim Kochen oder bei der Arbeit zuhören. Mobile-First-Märkte (Indien, Südostasien, Lateinamerika) bevorzugen aus diesem Grund tendenziell synchronisierte Inhalte.
Sie mehrere Märkte gleichzeitig bedienen. Die Erstellung von Untertiteln skaliert linear – jede neue Sprache erfordert eine weitere Runde für Timing, Formatierung und das Einbrennen der Untertitel. Eine Voiceover-Übersetzung skaliert sublinear – sobald die Pipeline eingerichtet ist, kostet das Hinzufügen einer 6. oder 7. Sprache nur noch Minuten an Rechenzeit anstelle von Tagen an Editor-Arbeitszeit.
Eine Voiceover-Übersetzung ist weniger sinnvoll, wenn:
Das Publikum Untertitel bevorzugt. Japanische Zuschauer, die ausländische Filme ansehen, sind das klassische Beispiel dafür. Einige Nischen greifen unabhängig von den Kosten standardmäßig auf Untertitel zurück. Testen Sie dies, bevor Sie Annahmen treffen.
Das Video so kurz ist, dass die Erstellung von Untertiteln trivial ist. Ein 60-sekündiger Social-Media-Clip rechtfertigt möglicherweise keinen Voiceover-Workflow.
Das Voiceover selbst der eigentliche Inhalt ist. Ein berühmter Sprecher, die spezifische Darbietung eines Schauspielers, eine Live-Aufnahme, bei der die Stimme das tragende Element ist – das Ersetzen durch eine Übersetzung verändert das, was geliefert wird. In diesen Fällen bewahren Untertitel das Originalwerk.
Voiceover-Übersetzung vs. Untertitel – die Wahl des richtigen Formats
Untertitel und Voiceover-Übersetzung beantworten dieselbe geschäftliche Frage – wie erreiche ich Sprecher einer anderen Sprache –, bieten den Zuschauern jedoch unterschiedliche Erlebnisse.

Untertitel vs. Voiceover-Übersetzung – wann welches Format gewinnt.
Dimension | Untertitel | Voiceover-Übersetzung |
|---|---|---|
Kosten pro Sprache | Gering (hauptsächlich Editor-Arbeitszeit) | Mittel (Rechenleistung + Stimmlizenzierung) |
Zeitaufwand pro Sprache | Stunden | Minuten (KI-gestützt) |
Zuschauererlebnis | Erfordert Mitlesen | Zuhören in der Muttersprache |
Mobile / abgelenkte Nutzung | Eingeschränkt | Funktioniert |
Markenstimme bleibt erhalten | Ja (Original-Audio bleibt erhalten) | Ja (durch Stimmenklonen) |
Barrierefreiheit (Gehörlose / Schwerhörige) | ✅ Essenziell | Benötigt zusätzliche Untertitelspur |
Bestens geeignet für | Kurze Clips, Nischenpublikum | Komplette Videos in großem Stil |
In der Praxis erstellen die meisten modernen Workflows beides – die Voiceover-Übersetzung als primäres Format und Untertitel als Barrierefreiheitsspur. KI-Synchronisationsplattformen geben in der Regel beides aus derselben Pipeline aus, da das Transkript und die Übersetzung ohnehin bereits in Schritt 1 und 2 erstellt wurden.
Wie man ein Voiceover mit KI übersetzt (Schritt für Schritt)
Die folgenden Schritte beschreiben den Workflow bei Perso Dubbing. Andere Plattformen unterscheiden sich in der Benutzeroberfläche, folgen aber derselben Logik.
1. Quelle hochladen. Ziehen Sie die Video- oder Audiodatei hinein. Die meisten Plattformen akzeptieren MP4, MOV, MP3, WAV. Wenn die Quelle ein YouTube-Link ist, fügen Sie die URL ein.
2. Zielsprachen auswählen. Wählen Sie eine oder mehrere aus. Perso Dubbing unterstützt über 99 Sprachen in Quell- und Zielkombinationen. Beliebte Optionen für den Einstieg: Spanisch, Portugiesisch, Französisch, Deutsch, Japanisch, Koreanisch.
3. Das automatische Transkript überprüfen. Das System zeigt das Transkript der Quellsprache an. Bearbeiten Sie eventuelle Spracherkennungsfehler, bevor der Übersetzungsschritt startet – jede Korrektur hier wirkt sich positiv auf alle folgenden Schritte aus.
4. Die Übersetzung bearbeiten (optional). Überprüfen Sie das zielsprachige Skript, bevor die Sprachsynthese startet. Korrigieren Sie Redewendungen, Markennamen und Fachbegriffe. In diesem Schritt fangen Teams Fehler ab, die später fast unmöglich zu korrigieren sind.
5. Generieren. Die Sprachsynthese und die Lippensynchronisation werden ausgeführt. Die Bearbeitung dauert etwa 1 bis 3 Minuten pro Minute Quellvideo – ein 5-minütiges Video ist in etwa 5 bis 15 Minuten fertig.
6. Herunterladen oder teilen. Das Ergebnis sind fertige MP4-Videodateien pro Sprache sowie Untertitelspuren (.srt) für die Barrierefreiheit. Einige Plattformen geben auch MP3-Audiodateien aus, wenn Sie nur das Voiceover ohne Video benötigen.
Die gesamte Sequenz ist ein einziger Workflow auf einer einzigen Plattform. Die Nutzungsdaten des „State of AI Dubbing 2026“-Berichts – 96 % Weiterweitergabe am selben Tag – resultieren aus dieser Art von Single-Workflow-Setup und nicht aus der manuellen Übergabe zwischen verschiedenen Tools.
Qualität der Voiceover-Übersetzung – worauf man achten sollte
Qualität besteht aus drei Komponenten. Alle drei sind wichtig, und die schwächste bestimmt, wie das Gesamtergebnis wirkt.
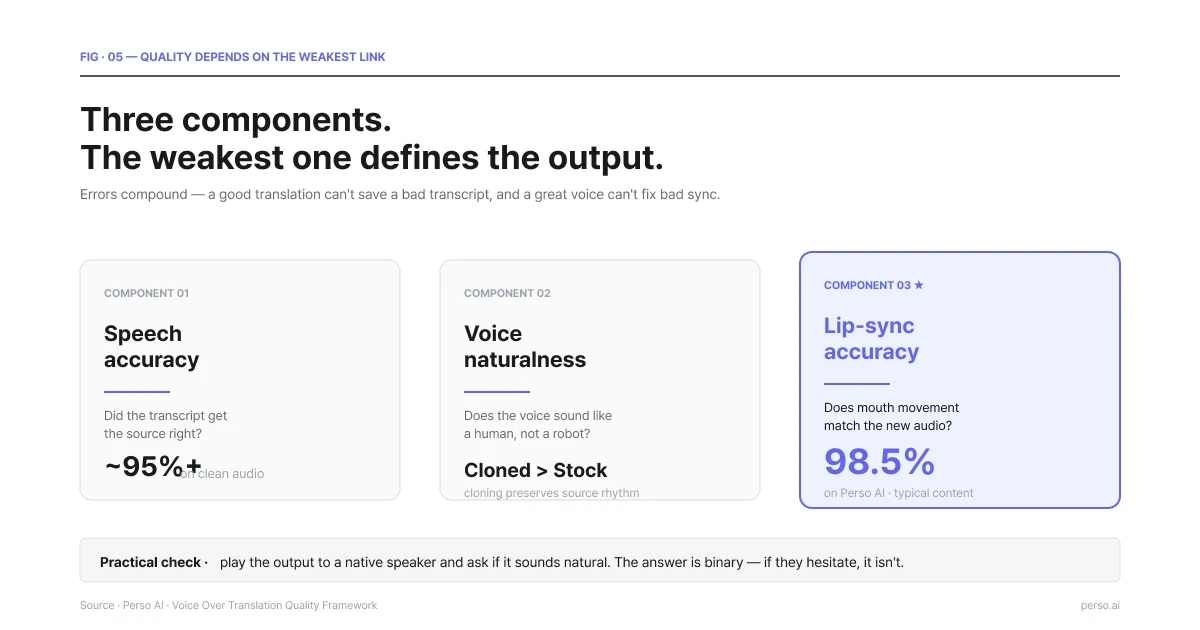
Drei Komponenten. Das schwächste Glied bestimmt das Ergebnis.
Sprachgenauigkeit. Sagt die übersetzte Stimme das, was in der Quelle gesagt wurde? Fehlübersetzungen von Markennamen, Fachbegriffen oder fachspezifischen Formulierungen gehören zu den häufigsten Fehlern. Abhilfe: Überprüfen Sie das übersetzte Skript, bevor die Sprachsynthese startet.
Natürlichkeit der Stimme. Klingt die Stimme wie ein Mensch, der die Sprache spricht, oder wie ein Roboter, der ein Skript vorliest? Moderne KI-Stimmen haben einen Großteil der Lücke geschlossen, aber der Unterschied ist nicht gleich null. Achten Sie auf Intonation, Satzrhythmus und natürliche Pausenlängen. Das Stimmenklonen des Originalsprechers schneidet in dieser Dimension im Allgemeinen besser ab als Stock-Stimmen, da das Modell den natürlichen Rhythmus der Quelle als Grundlage nutzen kann.
Genauigkeit der Lippensynchronisation (nur bei Video). Passt die Mundbewegung zum neuen Audio? Perso Dubbing meldet eine Lippensynchronisations-Genauigkeit von 98,5 % über seine gesamte Pipeline hinweg, was einer der höchsten öffentlich bekannten Werte in dieser Kategorie ist. Die verbleibende Abweichung von 1,5 % macht sich am ehesten in Nahaufnahmen von Gesichtern bemerkbar. Bei Weitwinkelaufnahmen sinkt die Empfindlichkeit für die Lippensynchronität, da der Mund im Bildausschnitt kleiner ist.
Ein praktischer Qualitätstest: Spielen Sie das Ergebnis einem Muttersprachler der Zielsprache vor und fragen Sie ihn, ob es natürlich klingt. Die Antwort ist binär. Wenn er zögert, ist es das nicht.
Häufig gefragte Sprachen für Voiceover-Übersetzungen
Die Nachfrage ist nicht gleichmäßig verteilt. Die Daten von Perso Dubbing, die 316.856 Synchronisationsprojekte und 4.023 professionelle Ersteller umfassen, zeigen anhand der am häufigsten gewählten Zielsprachen, wohin globaler Content tatsächlich fließt.
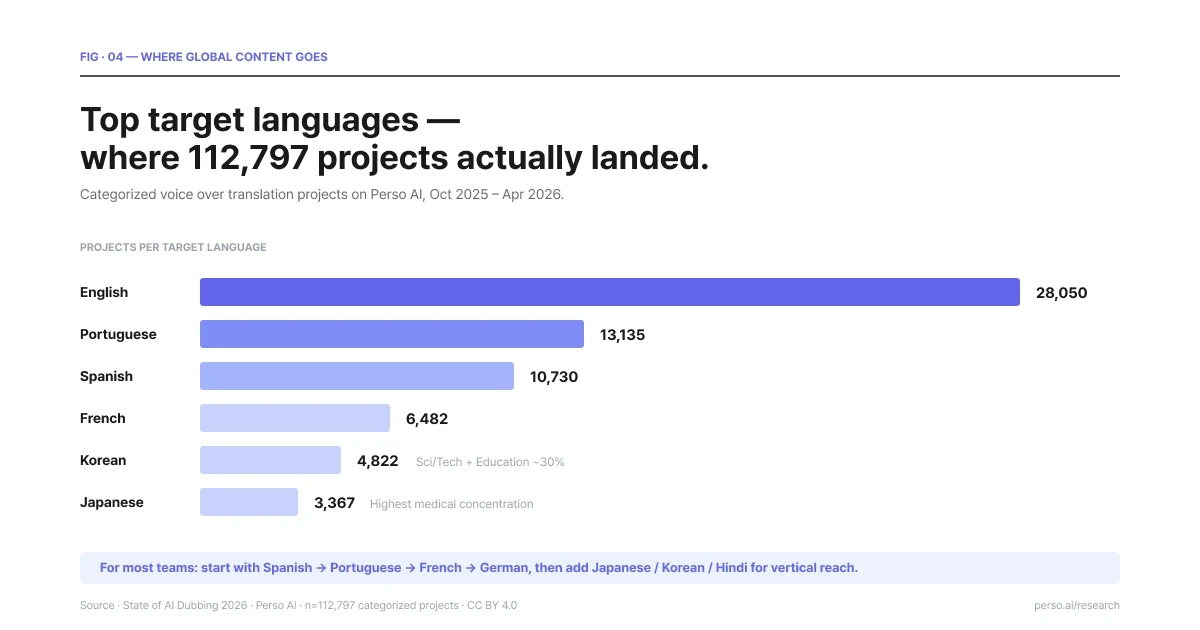
Top-Zielsprachen – wohin 112.797 Voiceover-Übersetzungsprojekte tatsächlich geflossen sind. Quelle: State of AI Dubbing 2026.
Englisch dominiert als Zielsprache (28.050 kategorisierte Projekte), ist aber am breitesten gefächert – keine einzelne Branche macht mehr als 14 % des Outputs mit englischem Ziel aus. Englisch ist die Standard-Zielsprache für nicht-englischsprachige Creator.
Portugiesisch (13.135 Projekte) ist der ausgewogenste Markt über mehrere Branchen hinweg, wobei Animation, Religion und Bildung jeweils nahe bei oder über 10 % liegen. Insbesondere brasilianisches Portugiesisch ist neben Englisch das zweite Zentrum für religiöse Inhalte – der „State of AI Dubbing 2026“-Bericht dokumentierte eine annähernde Parität von 25,6 % Englisch zu 25,2 % Portugiesisch bei religiösen Projekten. Ein Ergebnis, das alle überraschte, die davon ausgingen, dass Spanisch der Standard in Lateinamerika für Glaubensinhalte sei.
Spanisch (10.730 Projekte) ist führend in den Bereichen Bildung und Religion und dominiert in ganz Lateinamerika.
Koreanisch (4.822 Projekte) sticht heraus – 30 % des Volumens mit koreanischer Zielsprache entfallen auf den Wissensbereich (Wissenschaft/Technik + Bildung kombiniert). Dies passt zum Trend des Überspringens von K-Content in angrenzende Bereiche außerhalb des reinen Entertainments.
Japanisch (3.367 Projekte) weist unter den großen Zielmärkten die höchste Konzentration im Medizinbereich auf – Patientenaufklärung und Gesundheitsinhalte werden überproportional häufig ins Japanische lokalisiert.
Französisch (6.482 Projekte) wird stark von Dokumentationen dominiert, was zur starken französischen Tradition in der Produktion von Dokumentarfilmen passt.
Für erste Voiceover-Übersetzungsprojekte empfiehlt sich standardmäßig die Reihenfolge Spanisch → Portugiesisch → Französisch → Deutsch für eine breite Reichweite, gefolgt von Japanisch → Koreanisch → Hindi → Arabisch für eine thematische oder regionale Expansion.
Kosten der Voiceover-Übersetzung – KI vs. Mensch
Der Kostenunterschied zwischen KI-gestützter und menschlicher Voiceover-Übersetzung ist die größte Einzelveränderung, die diese Branche je erlebt hat.
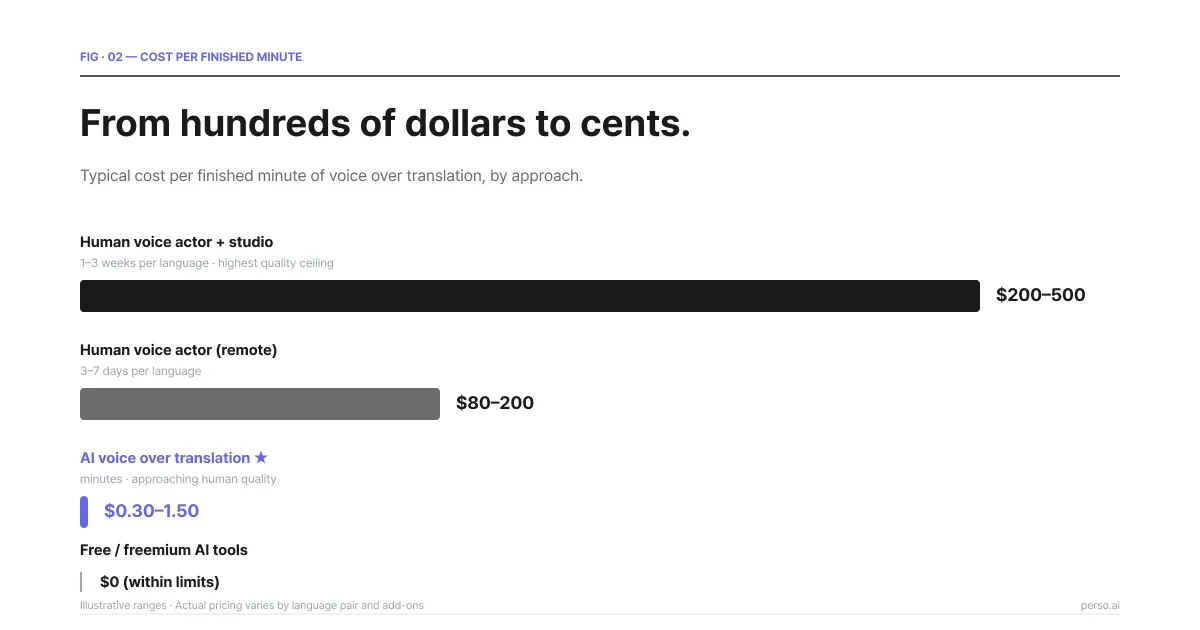
Kosten pro fertiger Minute nach Ansatz. KI-Voiceover ist rund 100-mal günstiger als die menschliche Sprachaufnahme in Studioqualität.
Ansatz | Typische Kosten | Bearbeitungszeit | Qualitative Obergrenze |
|---|---|---|---|
Menschlicher Sprecher + Studio | 200–500 $ pro fertige Minute | 1–3 Wochen pro Sprache | Höchste |
Menschlicher Sprecher (Remote) | 80–200 $ pro fertige Minute | 3–7 Tage pro Sprache | Hoch |
KI-Voiceover-Übersetzung | 0,30–1,50 $ pro fertige Minute | Minuten | Kommt in den meisten Punkten nah an den Menschen heran |
Kostenlose / Freemium-KI-Tools | 0 $ innerhalb der Limits | Minuten | Variabel, oft mit hörbaren Störgeräuschen |
Die oben genannten Zahlen dienen der Veranschaulichung – die tatsächlichen Preise variieren je nach Sprachpaar, Zusatzoptionen für das Stimmenklonen und der jeweiligen Plattform. Das sekundengenaue Abrechnungsmodell von Perso Dubbing stellt nur die tatsächliche Dauer des generierten Audios in Rechnung, sodass ein 30-sekündiger Clip auch nur für 30 Sekunden abgerechnet wird – anstatt auf eine Minute aufzurunden, wie es bei den meisten minutengestützten Modellen üblich ist.
Die Kostenschere macht sich bei mehrsprachigen Projekten noch deutlicher bemerkbar als bei einsprachigen. Die Skalierung von einer auf zehn Sprachen vervielfacht die Kosten bei menschlichen Sprechern auf das Zehnfache. Bei der KI-Voiceover-Übersetzung verdoppeln sich die Kosten von einer auf zehn Sprachen in etwa (jede Sprache benötigt Rechenleistung, aber die meisten Gemeinkosten bleiben fix). Dies untermauert die These über den leichteren Zugang zu neuen Sprachen aus dem „State of AI Dubbing 2026“-Bericht – die meisten Creator beschränken sich auf eine Sprache, weil die Erweiterung zu teuer ist. KI-Workflows verändern diese Kalkulation grundlegend.
Für Premium-Inhalte, bei denen es auf kleinste stimmliche Nuancen ankommt – Spielfilme, AAA-Games, anspruchsvolle Dokumentationen –, setzen menschliche Sprecher nach wie vor den Qualitätsmaßstab. Für alles andere ist die KI-Voiceover-Übersetzung mittlerweile der Standard für neue Projekte.
————————————————————————-
Häufig gestellte Fragen
F. Ist eine Voiceover-Übersetzung dasselbe wie Dubbing?
Weitgehend ja. Die Voiceover-Übersetzung ist der allgemeinere Oberbegriff. Dubbing bezieht sich meist auf dialoglastige Inhalte, bei denen die lippensynchrone Anpassung Teil des Ergebnisses ist. Beide nutzen dieselbe KI-Pipeline – Spracherkennung, Übersetzung, Sprachsynthese und (bei Videos) Lippensynchronisation.
F. Kann die KI meine Stimme für eine Voiceover-Übersetzung klonen?
Ja. Moderne Plattformen für KI-Voiceover-Übersetzungen unterstützen das Klonen von Stimmen. Eine saubere, 30-sekündige Sprachprobe reicht dafür meist völlig aus. Die geklonte Stimme spricht dann jede Zielsprache in Ihrem Projekt, sodass es so wirkt, als würde dieselbe Person das Video auf Spanisch, Japanisch, Deutsch usw. einsprechen.
F. Wie genau ist die KI-Voiceover-Übersetzung?
Drei Werte für die Genauigkeit sind entscheidend: die Spracherkennung (~95 %+ bei sauberem Audio), die Übersetzung (stark abhängig vom Sprachpaar, wobei europäische Sprachpaare genauer sind als seltene Sprachen) und die Lippensynchronisation (~98,5 % bei Perso Dubbing für typische Inhalte). Fehler potenzieren sich, weshalb der schwächste Schritt das Endergebnis maßgeblich bestimmt.
F. Wie lange dauert eine KI-Voiceover-Übersetzung?
Etwa 1 bis 3 Minuten pro Minute des Quellvideos. Ein 5-minütiges Video wird bei einer einzelnen Zielsprache in etwa 5 bis 15 Minuten übersetzt. Mehrsprachige Projekte skalieren sublinear – die Übersetzung in 5 Sprachen dauert insgesamt eher 5 Minuten als das Fünffache von 3 Minuten.
F. Kann ich die Übersetzung bearbeiten, bevor die Stimme generiert wird?
Ja, auf den meisten professionellen Plattformen. Das übersetzte Skript wird nach dem Übersetzungsschritt und vor dem Start der Sprachsynthese angezeigt. Das Korrigieren von Markennamen, Fachbegriffen und Redewendungen in dieser Phase ist wesentlich einfacher, als das Audio nachträglich anzupassen.
F. Was ist der Unterschied zwischen einer Voiceover-Übersetzung und dem bloßen Hinzufügen von Untertiteln?
Untertitel werden gelesen, ein Voiceover wird gehört. Untertitel behalten das originale Audio bei und fügen eine Textspur in der Zielsprache hinzu. Die Voiceover-Übersetzung ersetzt das Audio durch die Zielsprache. Die meisten modernen KI-Workflows erstellen beides – das Voiceover als primäres Ergebnis und Untertitel als Barrierefreiheitsspur aus demselben Transkript.
F. Funktioniert die Voiceover-Übersetzung auch für Live-Inhalte?
Derzeit noch nicht – die Voiceover-Übersetzung ist ein Postproduktions-Workflow. Echtes KI-Live-Dubbing ist ein neuer, entstehender Bereich. Der „State of AI Dubbing 2026“-Bericht nennt dies als einen der drei Trends, die voraussichtlich bis Ende 2026 / 2027 in Endkundenprodukten ankommen werden. Betrachten Sie die Voiceover-Übersetzung vorerst als Postproduktionsschritt für denselben Tag und nicht als Live-Lösung.
F. In wie viele Sprachen sollte ich übersetzen?
Der „State of AI Dubbing 2026“-Bericht stellte fest, dass der durchschnittliche professionelle Creator auf Perso Dubbing sein Video in eine einzige Sprache synchronisiert, während die Top 1 % im Schnitt 15 Sprachen nutzen. Diese Schere existiert, weil viele Creator Potenziale ungenutzt lassen, selbst wenn ihre Inhalte global funktionieren würden. Eine sinnvolle erste Erweiterung sind 3–5 Sprachen, die Ihre größten Märkte außerhalb des Ursprungslandes abdecken. Bauen Sie darauf basierend auf den Daten zur Wiedergabezeit pro Sprache weiter auf.
Erste Schritte
Wenn Sie die Voiceover-Übersetzung an einem bestehenden Video testen möchten, laden Sie am besten eine Quelle hoch und überprüfen Sie das Ergebnis in 2–3 Zielsprachen. Die meisten professionellen Plattformen bieten für diese Art von Test kostenlose Pakete an.
Für eine Komplettlösung, die den gesamten Workflow von der Spracherkennung, Übersetzung und dem Stimmenklonen bis hin zur Lippensynchronisation abdeckt, werfen Sie einen Blick auf den Video-Übersetzer von Perso Dubbing oder vergleichen Sie verschiedene Anbieter im Alternativen-Hub.
Die vollständigen Daten hinter jeder Statistik in diesem Leitfaden sind im „State of AI Dubbing 2026“-Bericht veröffentlicht, der unter der Creative Commons Attribution 4.0-Lizenz steht.
Kurze Antwort. Voiceover-Übersetzung ist der Workflow, bei dem ein bestehendes Voiceover – eine Erzählung, ein Erklärvideo-Audio oder ein aufgezeichneter Kommentar – übernommen und in einer anderen Sprache neu erstellt wird. Die KI-gestützte Voiceover-Übersetzung übernimmt drei Schritte automatisch: Spracherkennung, Übersetzung und Sprachsynthese in der Zielsprache. Mit Perso Dubbing können Sie in über 99 Sprachen übersetzen und die Stimme des Originalsprechers klonen, sodass die neue Sprache wie dieselbe Person klingt.
Was ist eine Voiceover-Übersetzung?
Die Voiceover-Übersetzung konvertiert eine aufgezeichnete Sprachaufnahme von einer Sprache in eine andere. Der Input ist Audio – manchmal an ein Video gekoppelt, manchmal eigenständig – und der Output ist Audio in einer anderen Sprache, bereit zur Veröffentlichung.
Diese Kategorie ist älter als KI. Studios haben dies jahrzehntelang manuell gemacht: einen Synchronsprecher in der Zielsprache engagieren, ihm ein übersetztes Skript in die Hand drücken, aufnehmen und wieder in das Video einmischen. Der Engpass waren immer die Kosten und die Zeit. Ein 5-minütiges Erklärvideo in drei Sprachen bedeutete früher drei Studiositzungen, drei Synchronsprecher und eine Woche Bearbeitungszeit.
KI hat den Arbeitsablauf verändert, ohne das Ziel zu ändern. Das Ergebnis ist immer noch ein Voiceover in einer anderen Sprache. Der Weg dorthin dauert jetzt jedoch Minuten statt Wochen.
Drei Arbeitsbereiche fallen unter die Voiceover-Übersetzung:
Der erste Bereich ist die lokalisierte Erzählung – Erklärvideos, E-Learning-Kurse, Dokumentarsprecher, Hörbuchkapitel. Das Original besteht aus einer einzigen Stimme über die gesamte Produktion hinweg. Das übersetzte Ergebnis behält dieselbe Stimme bei oder ersetzt sie durch ein Äquivalent in der Zielsprache.
Der zweite Bereich ist das Dialog-Dubbing – Filme, Dramen, Interview-Inhalte, bei denen mehrere Sprecher separat übersetzt werden müssen. Die Voiceover-Übersetzung ist hier das Arbeitstier, auch wenn die Branche es ab dem Moment, in dem mehrere Sprecher involviert sind, als „Dubbing“ (Synchronisation) bezeichnet.
Der dritte Bereich ist das Schnittstellen-Audio – IVR-Menüs, Stimmen zur App-Einführung, In-Produkt-Erzählungen. Ein kleinerer Umfang, aber im Hintergrund läuft dieselbe Übersetzungs- und Synthese-Pipeline.
Der Rest dieses Leitfadens konzentriert sich auf die ersten beiden Bereiche. Der dritte Bereich folgt demselben Workflow in kleinerem Maßstab.
Voiceover-Übersetzung vs. Dubbing – ist das dasselbe?
Größtenteils ja. Die Unterscheidung ist älter als der KI-Workflow und war noch nie ganz trennscharf.
Branchenüblicher Gebrauch:
Voiceover-Übersetzung bezieht sich in der Regel auf Inhalte im Erzählstil. Ein Sprecher. Dokumentation. Erklärvideo. Das Hörbuch. Das Voiceover liegt über dem Video, anstatt synchron zu den Mundbewegungen zu verlaufen.
Dubbing bezieht sich meist auf Dialoge. Mehrere Sprecher. Lippensynchronität ist wichtig. Film und Drama greifen standardmäßig auf diesen Begriff zurück.
In der Praxis ist die Grenze fließend. Wenn ein Ersteller ein YouTube-Video einspricht und dasselbe Video auf Spanisch haben möchte – ist das dann eine Voiceover-Übersetzung oder Dubbing? Beide Begriffe passen. Der Workflow ist identisch: Sprache rein → Übersetzung → Sprache raus → Einmischen ins Video.
Eine einfache Faustregel lautet: Betrachten Sie die Voiceover-Übersetzung als die übergeordnete Kategorie und Dubbing als den Fall, bei dem die lippensynchrone Ausrichtung Teil des Ergebnisses ist. Beide nutzen dieselbe KI-Pipeline. Das 4-Layer-Modell von KI-Medien ordnet dies dem Layer 4 – dem Distribution-Layer – zu, unabhängig davon, welchen Branchenbegriff Sie verwenden.
Der Rest dieses Leitfadens verwendet „Voiceover-Übersetzung“ als Oberbegriff. Wo Lippensynchronität eine Rolle spielt, weisen wir explizit darauf hin.
Wie KI-gestützte Voiceover-Übersetzung funktioniert
Die Pipeline besteht aus vier Schritten. Jeder Schritt dauert bei typischen Inhalten nur Sekunden oder wenige Minuten.
Vier Schritte. Audio rein, Audio raus. 1–3 Min. pro Minute des Quellvideos.
Schritt 1 – Spracherkennung. Das System transkribiert das Quellaudio in Text. Moderne Spracherkennung verarbeitet Akzente, Hintergrundmusik, mehrere Sprecher und natürliche Sprachmuster (Füllwörter, Pausen, Fehlstarts). Das Transkript ist das Fundament für jeden nachfolgenden Schritt, daher ist die Genauigkeit hier wichtiger, als den meisten bewusst ist. Ein schlechtes Transkript führt zu einer schlechten Übersetzung, was wiederum zu einem schlechten Voiceover führt.
Schritt 2 – Übersetzung. Das Transkript durchläuft eine neuronale Übersetzung, die auf gesprochene Sprache und nicht auf geschriebene Prosa abgestimmt ist. Gesprochene Sprache ist kürzer, idiomatischer und kontextabhängiger als geschriebener Text. Ein Übersetzungsmodell, das bei Dokumenten gut abschneidet, kann bei gesprochener Sprache versagen und umgekehrt. Das Ergebnis ist ein Skript in der Zielsprache, dessen Timing so genau wie möglich an das Tempo des Originals angepasst ist.
Schritt 3 – Sprachsynthese. Das übersetzte Skript wird in Sprache synthetisiert. Hierbei gibt es zwei Wege.
Der erste ist die Nutzung von Stock-Stimmen – wählen Sie eine Stimme aus einer Bibliothek aus und verwenden Sie sie. Das geht schnell und ist frei von Lizenzfragen, aber die neue Stimme klingt überhaupt nicht wie der Originalsprecher.
Der zweite Weg ist das Stimmenklonen (Voice Cloning) – trainieren Sie ein Modell mit der Stimme des Originalsprechers und synthetisieren Sie die Zielsprache in genau dieser Stimme. Das Ergebnis klingt wie dieselbe Person, die nun die neue Sprache spricht. Dies ist der Weg, den die meisten professionellen Arbeitsabläufe bei der Voiceover-Übersetzung bevorzugen.
Schritt 4 – Lippensynchronisation (wenn Video involviert ist). Wenn der Input ein Video ist, wird das synthetisierte Audio an die ursprünglichen Mundbewegungen angepasst. Moderne Systeme erreichen bei typischen Inhalten eine Genauigkeit von etwa 98 %. Ohne diesen Schritt läuft die neue Stimme über Mundbewegungen, die auf die Originalsprache abgestimmt sind, was die meisten Zuschauer innerhalb von Sekunden als unangenehm empfinden.
Perso Dubbing führt diese gesamte Pipeline als einen einzigen Workflow aus. Video hochladen, Zielsprachen auswählen, fertiges Video zurückbekommen. Die Gesamtbearbeitungszeit beträgt etwa 1 bis 3 Minuten pro Minute Quellvideo – ein 5-minütiges Video wird in etwa 5 bis 15 Minuten übersetzt.
Wann man eine Voiceover-Übersetzung benötigt
Die Entscheidung ist selten die Frage „Brauche ich überhaupt eine Übersetzung?“ – das ergibt sich meistens aus dem Business Case. Die Frage ist vielmehr, welches Übersetzungsformat man wählen sollte.
Eine Voiceover-Übersetzung ist sinnvoll, wenn:
Der Inhalt ein Video ist und Ihre Zielgruppe Videos konsumiert. Untertitel funktionieren für einige Zuschauergruppen, aber Analysen der Wiedergabezeit zeigen durchweg, dass synchronisierte Videos bei Nicht-Muttersprachlern besser abschneiden als untertitelte Videos. Der „State of AI Dubbing 2026“-Bericht stellte fest, dass 96 % der KI-synchronisierten Videos noch am selben Tag geteilt wurden, an dem sie erstellt wurden – das typische Verhaltensmuster von Inhalten, die für die Verbreitung und nicht für das Archiv bestimmt sind.
Sie bereits eine etablierte Stimme und Marke haben. Die Stimme eines Erstellers ist Teil seiner Marke. Die Stimme des Sprechers eines Unternehmens ist Teil seiner Identität. Eine Voiceover-Übersetzung mit Stimmenklonen hält diese Identität über verschiedene Sprachen hinweg aufrecht. Workflows mit Untertiteln verlieren diese Identität.
Ihre Zielgruppe mobil-first oder abgelenkt ist. Untertitelte Inhalte erfordern ungeteilte visuelle Aufmerksamkeit. Einer Voiceover-Übersetzung kann man im Auto, beim Kochen oder bei der Arbeit zuhören. Mobile-First-Märkte (Indien, Südostasien, Lateinamerika) bevorzugen aus diesem Grund tendenziell synchronisierte Inhalte.
Sie mehrere Märkte gleichzeitig bedienen. Die Erstellung von Untertiteln skaliert linear – jede neue Sprache erfordert eine weitere Runde für Timing, Formatierung und das Einbrennen der Untertitel. Eine Voiceover-Übersetzung skaliert sublinear – sobald die Pipeline eingerichtet ist, kostet das Hinzufügen einer 6. oder 7. Sprache nur noch Minuten an Rechenzeit anstelle von Tagen an Editor-Arbeitszeit.
Eine Voiceover-Übersetzung ist weniger sinnvoll, wenn:
Das Publikum Untertitel bevorzugt. Japanische Zuschauer, die ausländische Filme ansehen, sind das klassische Beispiel dafür. Einige Nischen greifen unabhängig von den Kosten standardmäßig auf Untertitel zurück. Testen Sie dies, bevor Sie Annahmen treffen.
Das Video so kurz ist, dass die Erstellung von Untertiteln trivial ist. Ein 60-sekündiger Social-Media-Clip rechtfertigt möglicherweise keinen Voiceover-Workflow.
Das Voiceover selbst der eigentliche Inhalt ist. Ein berühmter Sprecher, die spezifische Darbietung eines Schauspielers, eine Live-Aufnahme, bei der die Stimme das tragende Element ist – das Ersetzen durch eine Übersetzung verändert das, was geliefert wird. In diesen Fällen bewahren Untertitel das Originalwerk.
Voiceover-Übersetzung vs. Untertitel – die Wahl des richtigen Formats
Untertitel und Voiceover-Übersetzung beantworten dieselbe geschäftliche Frage – wie erreiche ich Sprecher einer anderen Sprache –, bieten den Zuschauern jedoch unterschiedliche Erlebnisse.
Untertitel vs. Voiceover-Übersetzung – wann welches Format gewinnt.
Dimension | Untertitel | Voiceover-Übersetzung |
|---|---|---|
Kosten pro Sprache | Gering (hauptsächlich Editor-Arbeitszeit) | Mittel (Rechenleistung + Stimmlizenzierung) |
Zeitaufwand pro Sprache | Stunden | Minuten (KI-gestützt) |
Zuschauererlebnis | Erfordert Mitlesen | Zuhören in der Muttersprache |
Mobile / abgelenkte Nutzung | Eingeschränkt | Funktioniert |
Markenstimme bleibt erhalten | Ja (Original-Audio bleibt erhalten) | Ja (durch Stimmenklonen) |
Barrierefreiheit (Gehörlose / Schwerhörige) | ✅ Essenziell | Benötigt zusätzliche Untertitelspur |
Bestens geeignet für | Kurze Clips, Nischenpublikum | Komplette Videos in großem Stil |
In der Praxis erstellen die meisten modernen Workflows beides – die Voiceover-Übersetzung als primäres Format und Untertitel als Barrierefreiheitsspur. KI-Synchronisationsplattformen geben in der Regel beides aus derselben Pipeline aus, da das Transkript und die Übersetzung ohnehin bereits in Schritt 1 und 2 erstellt wurden.
Wie man ein Voiceover mit KI übersetzt (Schritt für Schritt)
Die folgenden Schritte beschreiben den Workflow bei Perso Dubbing. Andere Plattformen unterscheiden sich in der Benutzeroberfläche, folgen aber derselben Logik.
1. Quelle hochladen. Ziehen Sie die Video- oder Audiodatei hinein. Die meisten Plattformen akzeptieren MP4, MOV, MP3, WAV. Wenn die Quelle ein YouTube-Link ist, fügen Sie die URL ein.
2. Zielsprachen auswählen. Wählen Sie eine oder mehrere aus. Perso Dubbing unterstützt über 99 Sprachen in Quell- und Zielkombinationen. Beliebte Optionen für den Einstieg: Spanisch, Portugiesisch, Französisch, Deutsch, Japanisch, Koreanisch.
3. Das automatische Transkript überprüfen. Das System zeigt das Transkript der Quellsprache an. Bearbeiten Sie eventuelle Spracherkennungsfehler, bevor der Übersetzungsschritt startet – jede Korrektur hier wirkt sich positiv auf alle folgenden Schritte aus.
4. Die Übersetzung bearbeiten (optional). Überprüfen Sie das zielsprachige Skript, bevor die Sprachsynthese startet. Korrigieren Sie Redewendungen, Markennamen und Fachbegriffe. In diesem Schritt fangen Teams Fehler ab, die später fast unmöglich zu korrigieren sind.
5. Generieren. Die Sprachsynthese und die Lippensynchronisation werden ausgeführt. Die Bearbeitung dauert etwa 1 bis 3 Minuten pro Minute Quellvideo – ein 5-minütiges Video ist in etwa 5 bis 15 Minuten fertig.
6. Herunterladen oder teilen. Das Ergebnis sind fertige MP4-Videodateien pro Sprache sowie Untertitelspuren (.srt) für die Barrierefreiheit. Einige Plattformen geben auch MP3-Audiodateien aus, wenn Sie nur das Voiceover ohne Video benötigen.
Die gesamte Sequenz ist ein einziger Workflow auf einer einzigen Plattform. Die Nutzungsdaten des „State of AI Dubbing 2026“-Berichts – 96 % Weiterweitergabe am selben Tag – resultieren aus dieser Art von Single-Workflow-Setup und nicht aus der manuellen Übergabe zwischen verschiedenen Tools.
Qualität der Voiceover-Übersetzung – worauf man achten sollte
Qualität besteht aus drei Komponenten. Alle drei sind wichtig, und die schwächste bestimmt, wie das Gesamtergebnis wirkt.
Drei Komponenten. Das schwächste Glied bestimmt das Ergebnis.
Sprachgenauigkeit. Sagt die übersetzte Stimme das, was in der Quelle gesagt wurde? Fehlübersetzungen von Markennamen, Fachbegriffen oder fachspezifischen Formulierungen gehören zu den häufigsten Fehlern. Abhilfe: Überprüfen Sie das übersetzte Skript, bevor die Sprachsynthese startet.
Natürlichkeit der Stimme. Klingt die Stimme wie ein Mensch, der die Sprache spricht, oder wie ein Roboter, der ein Skript vorliest? Moderne KI-Stimmen haben einen Großteil der Lücke geschlossen, aber der Unterschied ist nicht gleich null. Achten Sie auf Intonation, Satzrhythmus und natürliche Pausenlängen. Das Stimmenklonen des Originalsprechers schneidet in dieser Dimension im Allgemeinen besser ab als Stock-Stimmen, da das Modell den natürlichen Rhythmus der Quelle als Grundlage nutzen kann.
Genauigkeit der Lippensynchronisation (nur bei Video). Passt die Mundbewegung zum neuen Audio? Perso Dubbing meldet eine Lippensynchronisations-Genauigkeit von 98,5 % über seine gesamte Pipeline hinweg, was einer der höchsten öffentlich bekannten Werte in dieser Kategorie ist. Die verbleibende Abweichung von 1,5 % macht sich am ehesten in Nahaufnahmen von Gesichtern bemerkbar. Bei Weitwinkelaufnahmen sinkt die Empfindlichkeit für die Lippensynchronität, da der Mund im Bildausschnitt kleiner ist.
Ein praktischer Qualitätstest: Spielen Sie das Ergebnis einem Muttersprachler der Zielsprache vor und fragen Sie ihn, ob es natürlich klingt. Die Antwort ist binär. Wenn er zögert, ist es das nicht.
Häufig gefragte Sprachen für Voiceover-Übersetzungen
Die Nachfrage ist nicht gleichmäßig verteilt. Die Daten von Perso Dubbing, die 316.856 Synchronisationsprojekte und 4.023 professionelle Ersteller umfassen, zeigen anhand der am häufigsten gewählten Zielsprachen, wohin globaler Content tatsächlich fließt.
Top-Zielsprachen – wohin 112.797 Voiceover-Übersetzungsprojekte tatsächlich geflossen sind. Quelle: State of AI Dubbing 2026.
Englisch dominiert als Zielsprache (28.050 kategorisierte Projekte), ist aber am breitesten gefächert – keine einzelne Branche macht mehr als 14 % des Outputs mit englischem Ziel aus. Englisch ist die Standard-Zielsprache für nicht-englischsprachige Creator.
Portugiesisch (13.135 Projekte) ist der ausgewogenste Markt über mehrere Branchen hinweg, wobei Animation, Religion und Bildung jeweils nahe bei oder über 10 % liegen. Insbesondere brasilianisches Portugiesisch ist neben Englisch das zweite Zentrum für religiöse Inhalte – der „State of AI Dubbing 2026“-Bericht dokumentierte eine annähernde Parität von 25,6 % Englisch zu 25,2 % Portugiesisch bei religiösen Projekten. Ein Ergebnis, das alle überraschte, die davon ausgingen, dass Spanisch der Standard in Lateinamerika für Glaubensinhalte sei.
Spanisch (10.730 Projekte) ist führend in den Bereichen Bildung und Religion und dominiert in ganz Lateinamerika.
Koreanisch (4.822 Projekte) sticht heraus – 30 % des Volumens mit koreanischer Zielsprache entfallen auf den Wissensbereich (Wissenschaft/Technik + Bildung kombiniert). Dies passt zum Trend des Überspringens von K-Content in angrenzende Bereiche außerhalb des reinen Entertainments.
Japanisch (3.367 Projekte) weist unter den großen Zielmärkten die höchste Konzentration im Medizinbereich auf – Patientenaufklärung und Gesundheitsinhalte werden überproportional häufig ins Japanische lokalisiert.
Französisch (6.482 Projekte) wird stark von Dokumentationen dominiert, was zur starken französischen Tradition in der Produktion von Dokumentarfilmen passt.
Für erste Voiceover-Übersetzungsprojekte empfiehlt sich standardmäßig die Reihenfolge Spanisch → Portugiesisch → Französisch → Deutsch für eine breite Reichweite, gefolgt von Japanisch → Koreanisch → Hindi → Arabisch für eine thematische oder regionale Expansion.
Kosten der Voiceover-Übersetzung – KI vs. Mensch
Der Kostenunterschied zwischen KI-gestützter und menschlicher Voiceover-Übersetzung ist die größte Einzelveränderung, die diese Branche je erlebt hat.
Kosten pro fertiger Minute nach Ansatz. KI-Voiceover ist rund 100-mal günstiger als die menschliche Sprachaufnahme in Studioqualität.
Ansatz | Typische Kosten | Bearbeitungszeit | Qualitative Obergrenze |
|---|---|---|---|
Menschlicher Sprecher + Studio | 200–500 $ pro fertige Minute | 1–3 Wochen pro Sprache | Höchste |
Menschlicher Sprecher (Remote) | 80–200 $ pro fertige Minute | 3–7 Tage pro Sprache | Hoch |
KI-Voiceover-Übersetzung | 0,30–1,50 $ pro fertige Minute | Minuten | Kommt in den meisten Punkten nah an den Menschen heran |
Kostenlose / Freemium-KI-Tools | 0 $ innerhalb der Limits | Minuten | Variabel, oft mit hörbaren Störgeräuschen |
Die oben genannten Zahlen dienen der Veranschaulichung – die tatsächlichen Preise variieren je nach Sprachpaar, Zusatzoptionen für das Stimmenklonen und der jeweiligen Plattform. Das sekundengenaue Abrechnungsmodell von Perso Dubbing stellt nur die tatsächliche Dauer des generierten Audios in Rechnung, sodass ein 30-sekündiger Clip auch nur für 30 Sekunden abgerechnet wird – anstatt auf eine Minute aufzurunden, wie es bei den meisten minutengestützten Modellen üblich ist.
Die Kostenschere macht sich bei mehrsprachigen Projekten noch deutlicher bemerkbar als bei einsprachigen. Die Skalierung von einer auf zehn Sprachen vervielfacht die Kosten bei menschlichen Sprechern auf das Zehnfache. Bei der KI-Voiceover-Übersetzung verdoppeln sich die Kosten von einer auf zehn Sprachen in etwa (jede Sprache benötigt Rechenleistung, aber die meisten Gemeinkosten bleiben fix). Dies untermauert die These über den leichteren Zugang zu neuen Sprachen aus dem „State of AI Dubbing 2026“-Bericht – die meisten Creator beschränken sich auf eine Sprache, weil die Erweiterung zu teuer ist. KI-Workflows verändern diese Kalkulation grundlegend.
Für Premium-Inhalte, bei denen es auf kleinste stimmliche Nuancen ankommt – Spielfilme, AAA-Games, anspruchsvolle Dokumentationen –, setzen menschliche Sprecher nach wie vor den Qualitätsmaßstab. Für alles andere ist die KI-Voiceover-Übersetzung mittlerweile der Standard für neue Projekte.
————————————————————————-
Häufig gestellte Fragen
F. Ist eine Voiceover-Übersetzung dasselbe wie Dubbing?
Weitgehend ja. Die Voiceover-Übersetzung ist der allgemeinere Oberbegriff. Dubbing bezieht sich meist auf dialoglastige Inhalte, bei denen die lippensynchrone Anpassung Teil des Ergebnisses ist. Beide nutzen dieselbe KI-Pipeline – Spracherkennung, Übersetzung, Sprachsynthese und (bei Videos) Lippensynchronisation.
F. Kann die KI meine Stimme für eine Voiceover-Übersetzung klonen?
Ja. Moderne Plattformen für KI-Voiceover-Übersetzungen unterstützen das Klonen von Stimmen. Eine saubere, 30-sekündige Sprachprobe reicht dafür meist völlig aus. Die geklonte Stimme spricht dann jede Zielsprache in Ihrem Projekt, sodass es so wirkt, als würde dieselbe Person das Video auf Spanisch, Japanisch, Deutsch usw. einsprechen.
F. Wie genau ist die KI-Voiceover-Übersetzung?
Drei Werte für die Genauigkeit sind entscheidend: die Spracherkennung (~95 %+ bei sauberem Audio), die Übersetzung (stark abhängig vom Sprachpaar, wobei europäische Sprachpaare genauer sind als seltene Sprachen) und die Lippensynchronisation (~98,5 % bei Perso Dubbing für typische Inhalte). Fehler potenzieren sich, weshalb der schwächste Schritt das Endergebnis maßgeblich bestimmt.
F. Wie lange dauert eine KI-Voiceover-Übersetzung?
Etwa 1 bis 3 Minuten pro Minute des Quellvideos. Ein 5-minütiges Video wird bei einer einzelnen Zielsprache in etwa 5 bis 15 Minuten übersetzt. Mehrsprachige Projekte skalieren sublinear – die Übersetzung in 5 Sprachen dauert insgesamt eher 5 Minuten als das Fünffache von 3 Minuten.
F. Kann ich die Übersetzung bearbeiten, bevor die Stimme generiert wird?
Ja, auf den meisten professionellen Plattformen. Das übersetzte Skript wird nach dem Übersetzungsschritt und vor dem Start der Sprachsynthese angezeigt. Das Korrigieren von Markennamen, Fachbegriffen und Redewendungen in dieser Phase ist wesentlich einfacher, als das Audio nachträglich anzupassen.
F. Was ist der Unterschied zwischen einer Voiceover-Übersetzung und dem bloßen Hinzufügen von Untertiteln?
Untertitel werden gelesen, ein Voiceover wird gehört. Untertitel behalten das originale Audio bei und fügen eine Textspur in der Zielsprache hinzu. Die Voiceover-Übersetzung ersetzt das Audio durch die Zielsprache. Die meisten modernen KI-Workflows erstellen beides – das Voiceover als primäres Ergebnis und Untertitel als Barrierefreiheitsspur aus demselben Transkript.
F. Funktioniert die Voiceover-Übersetzung auch für Live-Inhalte?
Derzeit noch nicht – die Voiceover-Übersetzung ist ein Postproduktions-Workflow. Echtes KI-Live-Dubbing ist ein neuer, entstehender Bereich. Der „State of AI Dubbing 2026“-Bericht nennt dies als einen der drei Trends, die voraussichtlich bis Ende 2026 / 2027 in Endkundenprodukten ankommen werden. Betrachten Sie die Voiceover-Übersetzung vorerst als Postproduktionsschritt für denselben Tag und nicht als Live-Lösung.
F. In wie viele Sprachen sollte ich übersetzen?
Der „State of AI Dubbing 2026“-Bericht stellte fest, dass der durchschnittliche professionelle Creator auf Perso Dubbing sein Video in eine einzige Sprache synchronisiert, während die Top 1 % im Schnitt 15 Sprachen nutzen. Diese Schere existiert, weil viele Creator Potenziale ungenutzt lassen, selbst wenn ihre Inhalte global funktionieren würden. Eine sinnvolle erste Erweiterung sind 3–5 Sprachen, die Ihre größten Märkte außerhalb des Ursprungslandes abdecken. Bauen Sie darauf basierend auf den Daten zur Wiedergabezeit pro Sprache weiter auf.
Erste Schritte
Wenn Sie die Voiceover-Übersetzung an einem bestehenden Video testen möchten, laden Sie am besten eine Quelle hoch und überprüfen Sie das Ergebnis in 2–3 Zielsprachen. Die meisten professionellen Plattformen bieten für diese Art von Test kostenlose Pakete an.
Für eine Komplettlösung, die den gesamten Workflow von der Spracherkennung, Übersetzung und dem Stimmenklonen bis hin zur Lippensynchronisation abdeckt, werfen Sie einen Blick auf den Video-Übersetzer von Perso Dubbing oder vergleichen Sie verschiedene Anbieter im Alternativen-Hub.
Die vollständigen Daten hinter jeder Statistik in diesem Leitfaden sind im „State of AI Dubbing 2026“-Bericht veröffentlicht, der unter der Creative Commons Attribution 4.0-Lizenz steht.
Weiterlesen
Alle durchsuchen



