AIビデオ文字起こし: マルチスピーカーの吹き替えが簡単に



AIビデオ翻訳、ローカリゼーション、および吹き替えツール
無料でお試しください
チームで座談会を録画したとします。プロダクトマネージャーがロードマップを説明し、営業リーダーが顧客のインサイトを共有し、ゲストのエキスパートが技術的な詳細を補足します。会話は英語で自然に進みます。
今、スペイン語、ドイツ語、日本語のバージョンをリリースする必要があります。翻訳は正確で、声もクリアです。しかし、再生中にどこか不安定さを感じます。セリフが重なっている箇所があったり、前の話し手が話し終える前に、次の話し手が答えているように聞こえる声があったりします。
複数人のスピーカーによるコンテンツは、他のどの形式よりも、文字起こしとタイミングの弱点を浮き彫りにします。
ここで強力なビデオ文字起こしツール(Video Transcriber)が不可欠になります。まさにこの段階において、ダビングされた音声を生成する前に、チームがスピーカーの交代順を整理するためにPerso Dubbingを頼ることが多いのです。ビデオ文字起こしツールは、音声をテキストに変換する以上の役割を果たします。Perso Dubbingにおいて、これはスピーカーとタイミングを整理し、その後のすべてのプロセスを安定させるための基礎ステップとして位置づけられています。
スピーカーの交代順を構成し、タイムスタンプを安定させ、ダビング(Dubbing)、自動ダビング(Automatic Dubbing)、およびビデオ翻訳ワークフローのためのクリーンな台本基盤を整えます。このガイドでは、複数人のスピーカーによるダビングをシームレスにする機能を探索し、クリエイターやチームが信頼できる結果を得るためにどのようにワークフローを構成できるかを紹介します。
この記事は、インタビュー、ウェビナー、ディスカッション形式のコンテンツを制作するクリエイター、ポッドキャストのホスト、SaaSマーケティングチーム、およびトレーニング部門に向けて書かれています。
クリーンな文字起こしなしでは、複数人のダビングが破綻する理由
単一スピーカーのナレーションは予測可能です。複数人のコンテンツはそうではありません。割り込み、重なるフレーズ、素早い応答のやり取りにより、タイミングが複雑になります。
文字起こしデータが声を誤って統合してしまうと、ダビングが不安定になります。一般的な問題には以下が含まれます。
スピーカーのセリフが別の人に割り当てられる
発話のタイミングが早すぎる、または遅すぎるように感じられる
重なりによって音声が重複して聞こえる
文脈の断絶による翻訳エラー
クリーンなスピーカー検出により、翻訳を開始する前に会話の構造を損なわずに保つことができます。Perso Dubbingでは、最初の2〜3分間でスピーカーのラベルを確認する簡単なパスをチームが行うのが一般的です。なぜなら、そこでの小さなエラーはエピソード全体で繰り返される傾向があるからです。
再現可能なワークフローを構築するチームにとって、文字起こしの品質こそが複数人のダビングを安定させる鍵であり、Perso Dubbingはスピーカーの構造、編集、エクスポートを1つのフローで完結できるため便利です。参考情報として、AIダビングは、文字起こしの構造が最終的な出力にどのように影響するかについての便利な概要です。
複数人のダビングを改善するビデオ文字起こし機能
パネルディスカッション、インタビュー、またはポッドキャスト用のツールを評価する際は、以下のコアとなる機能に注目してください。
正確な話者分離(スピーカー・ダイアライゼーション)
正確な話者分離が基盤となります。文字起こしツールは、素早いやり取りの最中にも発話順を確実に識別し、スピーカーを誤認した場合にはタグを簡単に修正できる方法を提供する必要があります。ここでの小さなミスは、その後の翻訳や音声生成のステップで何倍にも膨れ上がります。
以下の点を確認してください:
スピーカーセグメントの明確なラベリング
素早いやり取りにおいても安定したセグメンテーション
必要に応じてスピーカータグを手動で調整できる機能
この基盤は、ダビングの精度を直接高め、タイミングのズレを軽減します。
クリーンなタイムスタンプ管理
討論形式のコンテンツでは、シンプルなナレーションよりもタイミングの正確さが重要になります。
ビデオ文字起こしツールが満たすべき要件:
字幕ブロックの重複を避ける
会話ブロックを簡潔に保つ
スピーカーの交代間の間隔を一貫して維持する
安定したタイムスタンプは、同期の問題を減らし、会話のキャッチボールを自然に保ちます。Perso Dubbingでは、タイムスタンプが整理されていることで、ファイル全体を再処理する代わりに、変更したセグメントだけをプレビューするのも容易になります。
編集可能な台本コントロール
優れた検出機能があっても、一部のセリフは微調整が必要になる場合があります。クリーンな編集レイヤーがあれば、すべての音声を再生成する必要はありません。
字幕&台本エディター(Subtitle & Script Editor)により、チームは以下を行うことができます:
セグメンテーションの調整
言い回しの修正
対話の切り替えの安定化
編集は、トーンやスピーカーの個性を守るための作業です。特に、小さと言葉の変化が声の印象に影響を与える、会話の多いビデオで重要になります。Perso Dubbingでは、チームがいくつかの繰り返されるフレーズ(導入部、セグメントの切り替え、スポンサーの読み上げなど)を標準化して、すべての言語バージョンで一貫性を保てるようにすることがよくあります。標準化すべき項目の詳細については、一貫したブランドボイスを参照してください。
ビデオ翻訳のワークフローはどのようにスピーカー構造に依存するか?
構造化されたビデオ翻訳ワークフローは、多くの場合、以下の流れに従います。
複数人のコンテンツを文字起こしする
各スピーカーのセリフを翻訳する
スピーカーごとに音声出力を生成する
同期(シンクロ)を確認する
最終的な多言語バージョンをエクスポートする
最初の段階でビデオ文字起こしツールがスピーカーを誤ってマージしてしまうと、翻訳エラーが連鎖します。音声クローニング(Voice Cloning)の出力が一致しなくなったり、対話のリズムが不自然になったりします。
実践的な例として、あるチームが30〜45分の座談会をPerso Dubbingに通し、ホストとゲストのスピーカーラベルを確認し、いくつかの重なりセグメントを修正してから、現地語バージョンを生成します。時間の大部分は音声の作り直しではなく、最初の確認(スピーカータグとタイミング)に費やされます。
グローバルチームにとって、文字起こし、編集、およびダビングが1つの場所で行えることは、スピーカーのタイミング、用語、およびエクスポートの一貫性を保つ上で役立ちます。比較検討する選択肢の1つとして、ビデオ翻訳プラットフォーム(video translation platform)をチェックリストに加えることができます。
複数人ビデオにおける自動ダビングとコントロールされたダビングの比較

自動ダビングは、スピーカーのやり取りが整理され、最小限である場合に効果的です。ただし、台本のない自然な会話には、より多くのレビューが必要になります。
自動ダビングがうまく機能するケース
発話順が明確に調整されたウェビナー
重なりが最小限のインタビュー形式
構造化された質疑応答セッション
コントロールされたダビングの方が安全なケース
ポッドキャスト形式の会話
感情的であったりペースが早かったりするディベート
複数のゲストが参加するパネルディスカッション
ライブイベントの録画
このようなケースでは、最終エクスポートの前にセグメンテーションを微調整することで、混乱を防ぎ、ペースを保護することができます。
複数人のローカライズにおける音声クローニングの役割
音声クローニングは、各声が独自の個性を持つインタビューやパネルディスカッションで特に威力を発揮します。
単一の一般的なナレーターを使用する代わりに、音声クローニングは以下の要素を保存するのに役立ちます:
個々人の話し方のスタイル
ホストとゲストの間の権威の差
ストーリーテリング中の感情のトーン
ビデオ文字起こしツールによる正確なスピーカー検出と組み合わせることで、音声クローニングは多言語ダビングをより本物らしく感じさせます。
複数人ワークフローの比較表
ワークフローステージ | 構造化された文字起こしがない場合 | 強力なビデオ文字起こしツールを使用した場合 |
スピーカー検出 | セリフが誤って統合される | スピーカーが明確に分離される |
タイミングの位置合わせ | セグメントが重なる | きれいなタイムスタンプの間隔 |
翻訳の明瞭さ | 文脈の乱れ | 構造化された対話の流れ |
音声生成 | ミスマッチな話者トーン | 安定した音声の割り当て |
編集コントロール | 全面的な再処理が必要 | 軽微な調整のみ |
この比較は、なぜビデオ文字起こしの段階がその後に続くすべての品質を決定づけるのかを浮き彫りにしています。
複数人プロジェクトにおける字幕&台本エディター
文字起こしの後、通常は細かい部分で編集が必要になります。字幕&台本エディターを使用することで、チームは軽微な問題を素早く修正できます。
以下の機能をサポートします:
スピーカーラベルの再割り当て
長い対話ブロックの分割
切り替えタイミングの調整
翻訳された言い回しの微調整
このステップにより、ビデオ翻訳の安定性が向上し、スムーズな自動ダビングのためのプロジェクトが準備されます。
YouTubeで座談会やインタビューを公開する場合、解決のために何時間も費やすことなく、複数の言語にわたってスピーカーの一貫性を保つことが重要です。YouTubeダビングは、クリエイターがよく使用するワークフローを示しています。
複数人のダビングにおける一般的な問題
経験豊富なチームであっても、繰り返される課題に直面することがあります。
翻訳中の音声の重複:2人のスピーカーが互いに口を挟んだ際、セグメンテーションが不十分だと、最終的なダビングで音声が重なってしまいます。
不正確な感情トーン:翻訳で文脈が損なわれると、音声クローニングの出力が一本調子に聞こえたり、一致しなくなったりすることがあります。
スピーカー間のズレ:軽微なタイミングのズレが蓄積し、対話の応答が遅れているように感じられるようになります。
過度な手動修正の負担:クリーンな文字起こしがないと、チームはコンテンツの洗練ではなく、個々のセグメントの修正に莫大な時間を費やすことになります。
安定した複数人ビデオ翻訳ワークフローを構築するには?
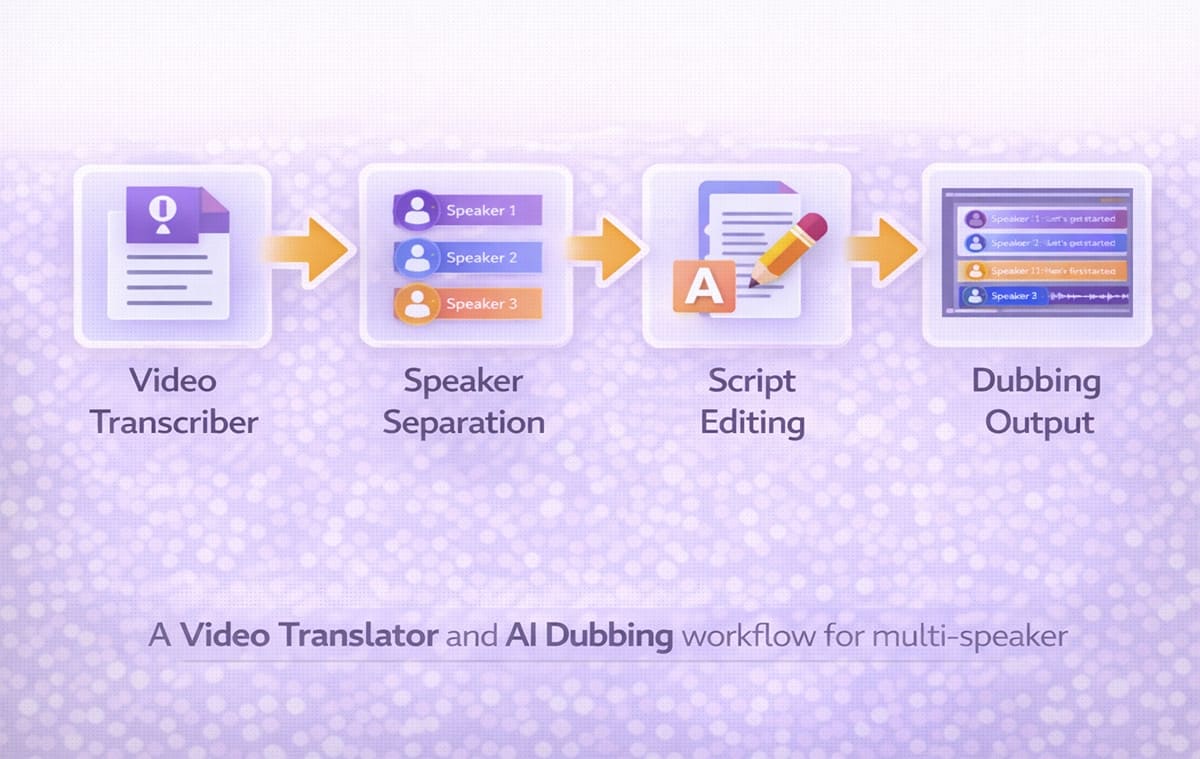
再現可能なシステムにより、複雑さが軽減されます。
スピーカー検出付きの文字起こしデータを生成する
セグメンテーションを確認し修正する
対話ブロックを明確に翻訳する
適切な音声を割り当てる
ダビング出力を実行する
簡単な同期確認を実行する
文字起こしがクリーンであれば、自動ダビングの精度は格段に高まり、スケールしやすくなります。
よくある質問
なぜ複数人のダビングにビデオ文字起こしツールが不可欠なのですか?
複数人のコンテンツは、タイミングの複雑さを増大させます。構造化されたビデオ文字起こしツールは、翻訳や音声生成のステップに進む前に、対話の流れを安定させます。
自動ダビングは、パネルディスカッションにも対応できますか?
構造化された会話には対応可能ですが、ペースが速いディスカッションや重複する対話では、追加で台本の確認を行うことでより良い結果が得られます。
インタビューにおいて、音声クローニングはどのように役立ちますか?
異なる言語を使用しても、個人のアイデンティティや話し方のスタイルが維持され、信頼性が高まります。
台本の編集は常に必要ですか?
常に必要というわけではありませんが、大半の複数人のプロジェクトは、最終エクスポートの前に軽微な微調整を行うことで品質が向上します。
結論
複数人のコンテンツは、シンプルなナレーションにはないタイミングや構造上の複雑さをもたらします。強力なビデオ文字起こしツールは、対話の流れを保護し、クリーンなセグメンテーションをサポートし、ダビングプロセス全体のパイプラインを強化します。これを構造化されたビデオ翻訳ワークフローやコントロールされた自動ダビングと組み合わせることで、チームは明瞭さやスピーカーの個性を損なうことなく、インタビュー、ウェビナー、パネルディスカッションを多言語にスケール展開できます。
チームで座談会を録画したとします。プロダクトマネージャーがロードマップを説明し、営業リーダーが顧客のインサイトを共有し、ゲストのエキスパートが技術的な詳細を補足します。会話は英語で自然に進みます。
今、スペイン語、ドイツ語、日本語のバージョンをリリースする必要があります。翻訳は正確で、声もクリアです。しかし、再生中にどこか不安定さを感じます。セリフが重なっている箇所があったり、前の話し手が話し終える前に、次の話し手が答えているように聞こえる声があったりします。
複数人のスピーカーによるコンテンツは、他のどの形式よりも、文字起こしとタイミングの弱点を浮き彫りにします。
ここで強力なビデオ文字起こしツール(Video Transcriber)が不可欠になります。まさにこの段階において、ダビングされた音声を生成する前に、チームがスピーカーの交代順を整理するためにPerso Dubbingを頼ることが多いのです。ビデオ文字起こしツールは、音声をテキストに変換する以上の役割を果たします。Perso Dubbingにおいて、これはスピーカーとタイミングを整理し、その後のすべてのプロセスを安定させるための基礎ステップとして位置づけられています。
スピーカーの交代順を構成し、タイムスタンプを安定させ、ダビング(Dubbing)、自動ダビング(Automatic Dubbing)、およびビデオ翻訳ワークフローのためのクリーンな台本基盤を整えます。このガイドでは、複数人のスピーカーによるダビングをシームレスにする機能を探索し、クリエイターやチームが信頼できる結果を得るためにどのようにワークフローを構成できるかを紹介します。
この記事は、インタビュー、ウェビナー、ディスカッション形式のコンテンツを制作するクリエイター、ポッドキャストのホスト、SaaSマーケティングチーム、およびトレーニング部門に向けて書かれています。
クリーンな文字起こしなしでは、複数人のダビングが破綻する理由
単一スピーカーのナレーションは予測可能です。複数人のコンテンツはそうではありません。割り込み、重なるフレーズ、素早い応答のやり取りにより、タイミングが複雑になります。
文字起こしデータが声を誤って統合してしまうと、ダビングが不安定になります。一般的な問題には以下が含まれます。
スピーカーのセリフが別の人に割り当てられる
発話のタイミングが早すぎる、または遅すぎるように感じられる
重なりによって音声が重複して聞こえる
文脈の断絶による翻訳エラー
クリーンなスピーカー検出により、翻訳を開始する前に会話の構造を損なわずに保つことができます。Perso Dubbingでは、最初の2〜3分間でスピーカーのラベルを確認する簡単なパスをチームが行うのが一般的です。なぜなら、そこでの小さなエラーはエピソード全体で繰り返される傾向があるからです。
再現可能なワークフローを構築するチームにとって、文字起こしの品質こそが複数人のダビングを安定させる鍵であり、Perso Dubbingはスピーカーの構造、編集、エクスポートを1つのフローで完結できるため便利です。参考情報として、AIダビングは、文字起こしの構造が最終的な出力にどのように影響するかについての便利な概要です。
複数人のダビングを改善するビデオ文字起こし機能
パネルディスカッション、インタビュー、またはポッドキャスト用のツールを評価する際は、以下のコアとなる機能に注目してください。
正確な話者分離(スピーカー・ダイアライゼーション)
正確な話者分離が基盤となります。文字起こしツールは、素早いやり取りの最中にも発話順を確実に識別し、スピーカーを誤認した場合にはタグを簡単に修正できる方法を提供する必要があります。ここでの小さなミスは、その後の翻訳や音声生成のステップで何倍にも膨れ上がります。
以下の点を確認してください:
スピーカーセグメントの明確なラベリング
素早いやり取りにおいても安定したセグメンテーション
必要に応じてスピーカータグを手動で調整できる機能
この基盤は、ダビングの精度を直接高め、タイミングのズレを軽減します。
クリーンなタイムスタンプ管理
討論形式のコンテンツでは、シンプルなナレーションよりもタイミングの正確さが重要になります。
ビデオ文字起こしツールが満たすべき要件:
字幕ブロックの重複を避ける
会話ブロックを簡潔に保つ
スピーカーの交代間の間隔を一貫して維持する
安定したタイムスタンプは、同期の問題を減らし、会話のキャッチボールを自然に保ちます。Perso Dubbingでは、タイムスタンプが整理されていることで、ファイル全体を再処理する代わりに、変更したセグメントだけをプレビューするのも容易になります。
編集可能な台本コントロール
優れた検出機能があっても、一部のセリフは微調整が必要になる場合があります。クリーンな編集レイヤーがあれば、すべての音声を再生成する必要はありません。
字幕&台本エディター(Subtitle & Script Editor)により、チームは以下を行うことができます:
セグメンテーションの調整
言い回しの修正
対話の切り替えの安定化
編集は、トーンやスピーカーの個性を守るための作業です。特に、小さと言葉の変化が声の印象に影響を与える、会話の多いビデオで重要になります。Perso Dubbingでは、チームがいくつかの繰り返されるフレーズ(導入部、セグメントの切り替え、スポンサーの読み上げなど)を標準化して、すべての言語バージョンで一貫性を保てるようにすることがよくあります。標準化すべき項目の詳細については、一貫したブランドボイスを参照してください。
ビデオ翻訳のワークフローはどのようにスピーカー構造に依存するか?
構造化されたビデオ翻訳ワークフローは、多くの場合、以下の流れに従います。
複数人のコンテンツを文字起こしする
各スピーカーのセリフを翻訳する
スピーカーごとに音声出力を生成する
同期(シンクロ)を確認する
最終的な多言語バージョンをエクスポートする
最初の段階でビデオ文字起こしツールがスピーカーを誤ってマージしてしまうと、翻訳エラーが連鎖します。音声クローニング(Voice Cloning)の出力が一致しなくなったり、対話のリズムが不自然になったりします。
実践的な例として、あるチームが30〜45分の座談会をPerso Dubbingに通し、ホストとゲストのスピーカーラベルを確認し、いくつかの重なりセグメントを修正してから、現地語バージョンを生成します。時間の大部分は音声の作り直しではなく、最初の確認(スピーカータグとタイミング)に費やされます。
グローバルチームにとって、文字起こし、編集、およびダビングが1つの場所で行えることは、スピーカーのタイミング、用語、およびエクスポートの一貫性を保つ上で役立ちます。比較検討する選択肢の1つとして、ビデオ翻訳プラットフォーム(video translation platform)をチェックリストに加えることができます。
複数人ビデオにおける自動ダビングとコントロールされたダビングの比較
自動ダビングは、スピーカーのやり取りが整理され、最小限である場合に効果的です。ただし、台本のない自然な会話には、より多くのレビューが必要になります。
自動ダビングがうまく機能するケース
発話順が明確に調整されたウェビナー
重なりが最小限のインタビュー形式
構造化された質疑応答セッション
コントロールされたダビングの方が安全なケース
ポッドキャスト形式の会話
感情的であったりペースが早かったりするディベート
複数のゲストが参加するパネルディスカッション
ライブイベントの録画
このようなケースでは、最終エクスポートの前にセグメンテーションを微調整することで、混乱を防ぎ、ペースを保護することができます。
複数人のローカライズにおける音声クローニングの役割
音声クローニングは、各声が独自の個性を持つインタビューやパネルディスカッションで特に威力を発揮します。
単一の一般的なナレーターを使用する代わりに、音声クローニングは以下の要素を保存するのに役立ちます:
個々人の話し方のスタイル
ホストとゲストの間の権威の差
ストーリーテリング中の感情のトーン
ビデオ文字起こしツールによる正確なスピーカー検出と組み合わせることで、音声クローニングは多言語ダビングをより本物らしく感じさせます。
複数人ワークフローの比較表
ワークフローステージ | 構造化された文字起こしがない場合 | 強力なビデオ文字起こしツールを使用した場合 |
スピーカー検出 | セリフが誤って統合される | スピーカーが明確に分離される |
タイミングの位置合わせ | セグメントが重なる | きれいなタイムスタンプの間隔 |
翻訳の明瞭さ | 文脈の乱れ | 構造化された対話の流れ |
音声生成 | ミスマッチな話者トーン | 安定した音声の割り当て |
編集コントロール | 全面的な再処理が必要 | 軽微な調整のみ |
この比較は、なぜビデオ文字起こしの段階がその後に続くすべての品質を決定づけるのかを浮き彫りにしています。
複数人プロジェクトにおける字幕&台本エディター
文字起こしの後、通常は細かい部分で編集が必要になります。字幕&台本エディターを使用することで、チームは軽微な問題を素早く修正できます。
以下の機能をサポートします:
スピーカーラベルの再割り当て
長い対話ブロックの分割
切り替えタイミングの調整
翻訳された言い回しの微調整
このステップにより、ビデオ翻訳の安定性が向上し、スムーズな自動ダビングのためのプロジェクトが準備されます。
YouTubeで座談会やインタビューを公開する場合、解決のために何時間も費やすことなく、複数の言語にわたってスピーカーの一貫性を保つことが重要です。YouTubeダビングは、クリエイターがよく使用するワークフローを示しています。
複数人のダビングにおける一般的な問題
経験豊富なチームであっても、繰り返される課題に直面することがあります。
翻訳中の音声の重複:2人のスピーカーが互いに口を挟んだ際、セグメンテーションが不十分だと、最終的なダビングで音声が重なってしまいます。
不正確な感情トーン:翻訳で文脈が損なわれると、音声クローニングの出力が一本調子に聞こえたり、一致しなくなったりすることがあります。
スピーカー間のズレ:軽微なタイミングのズレが蓄積し、対話の応答が遅れているように感じられるようになります。
過度な手動修正の負担:クリーンな文字起こしがないと、チームはコンテンツの洗練ではなく、個々のセグメントの修正に莫大な時間を費やすことになります。
安定した複数人ビデオ翻訳ワークフローを構築するには?
再現可能なシステムにより、複雑さが軽減されます。
スピーカー検出付きの文字起こしデータを生成する
セグメンテーションを確認し修正する
対話ブロックを明確に翻訳する
適切な音声を割り当てる
ダビング出力を実行する
簡単な同期確認を実行する
文字起こしがクリーンであれば、自動ダビングの精度は格段に高まり、スケールしやすくなります。
よくある質問
なぜ複数人のダビングにビデオ文字起こしツールが不可欠なのですか?
複数人のコンテンツは、タイミングの複雑さを増大させます。構造化されたビデオ文字起こしツールは、翻訳や音声生成のステップに進む前に、対話の流れを安定させます。
自動ダビングは、パネルディスカッションにも対応できますか?
構造化された会話には対応可能ですが、ペースが速いディスカッションや重複する対話では、追加で台本の確認を行うことでより良い結果が得られます。
インタビューにおいて、音声クローニングはどのように役立ちますか?
異なる言語を使用しても、個人のアイデンティティや話し方のスタイルが維持され、信頼性が高まります。
台本の編集は常に必要ですか?
常に必要というわけではありませんが、大半の複数人のプロジェクトは、最終エクスポートの前に軽微な微調整を行うことで品質が向上します。
結論
複数人のコンテンツは、シンプルなナレーションにはないタイミングや構造上の複雑さをもたらします。強力なビデオ文字起こしツールは、対話の流れを保護し、クリーンなセグメンテーションをサポートし、ダビングプロセス全体のパイプラインを強化します。これを構造化されたビデオ翻訳ワークフローやコントロールされた自動ダビングと組み合わせることで、チームは明瞭さやスピーカーの個性を損なうことなく、インタビュー、ウェビナー、パネルディスカッションを多言語にスケール展開できます。
続きを読む
すべてを閲覧する




