ボイスオーバー翻訳:多言語動画の完全ガイド



AIビデオ翻訳、ローカリゼーション、および吹き替えツール
無料でお試しください
概要: ボイスオーバー翻訳(ナレーション翻訳)とは、既存のボイスオーバー(ナレーション、解説動画の音声、録音された解説など)をもとに、別の言語で同じ内容の音声を作成するプロセスのことです。AIを活用したボイスオーバー翻訳では、音声認識、翻訳、そしてターゲット言語での音声合成という3つのステップが自動化されます。Perso AIを使用すれば、99以上の言語で翻訳できるだけでなく、オリジナルの話し手の声をクローン(コピー)して、まるで本人がその言語を話しているかのように仕上げることも可能です。
ボイスオーバー翻訳とは?
ボイスオーバー翻訳は、録音されたボイスオーバーの音声を別の言語に変換する技術です。インプット(入力)は音声(動画に付随する音声、または音声単体)で、アウトプット(出力)は別言語に変換された音声であり、そのまま素材として使用できます。
この分野の歴史はAIよりも古く、スタジオで何十年もの間、手動で行われてきました。まずターゲット言語の声優を雇い、翻訳された台本を渡し、録音し、動画に音声をミックスする、という流れです。その際の最大のネックは、常にコストと時間でした。かつては、3つの言語で5分の解説動画を作るために、3回のスタジオセッション、3人の声優、そして1週間の納期が必要でした。
AIは、成果の本質を変えることなく、そのワークフローを劇的に変化させました。仕上がりは、以前と同じ別言語のナレーションですが、完成までの時間が、数週間からわずか数分に短縮されたのです。
ボイスオーバー翻訳には、大きく分けて3つのカテゴリがあります:
1つ目は、ローカライズされたナレーション(解説動画、eラーニング教材、ドキュメンタリーのナレーション、オーディオブックなど)です。元の動画は1人のナレーターが全体を担当しており、翻訳版でも同じ声を維持するか、ターゲット言語の同様の別の声に置き換えます。
2つ目は、対話の音声吹き替え(ダビング)です。映画、ドラマ、インタビューなど、複数の話し手を別々に翻訳する必要があるコンテンツがこれに該当します。この領域では、業界用語として複数人の話し手向けを「ダビング」と呼びますが、それもボイスオーバー翻訳の実質的な中心分野となっています。
3つ目は、インターフェース音声です。自動音声応答(IVR)のメニュー画面、アプリの導入向け音声、製品内のナレーションなどが含まれます。規模は小さいですが、その仕組みは同じ翻訳・音声合成の処理プロセスで行われます。
このガイドでは、主に最初の2つのカテゴリ(ナレーション、対話ドキュメンタリー)に焦点を当てています。3つ目も同様のプロセスをより小さい規模で行うものです。
ボイスオーバー翻訳と吹き替え(ダビング)の違いは?
基本的には、ほぼ同じ意味で使われています。これらの違いはAIが登場する以前からあるもので、明確な境界はありませんでした。
業界で一般的に使われる主な区別は以下の通りです:
ボイスオーバー翻訳は通常、ドキュメンタリー、解説動画、オーディオブックなど、1人のナレーターが話すスタイルのコンテンツを指します。音声は口の動き(リップシンク)に合わせるのではなく、動画の上に重ねるナレーション形式になります。
吹き替え(ダビング)は通常、映画やドラマなどの会話や対話を伴い、複数の話し手がいる場合を指します。唇の動きに声を合わせる「リップシンク(口の動きの同期)」が重要視され、映画やドラマではデフォルトでこの用語が使われます。
実際には両者の境界はあいまいです。例えば、自分で解説するYouTube動画をスペイン語でも配信したい場合、それはボイスオーバー翻訳でしょうか、それともダビングでしょうか? どちらの言葉を使っても間違いではありません。どちらも「音声入力 → 翻訳 → 音声出力 → 動画へのミックス」という全く同じプロセスをたどります。
明確なルールで分けるとするなら、ボイスオーバー翻訳は「音声翻訳」全般を指す広い括りで、ダビングは「口の動きに合わせること(リップシンク)」が求められる場合、と捉えるのが分かりやすいでしょう。どちらも同じAIのシステムで処理されます。AIメディアの4レイヤーモデルでは、業界でどう呼ばれるかに関わらず、これを「レイヤー4(配信レイヤー)」として定義しています。
このガイドの残り部分では、総称として「ボイスオーバー翻訳」という言葉を使用します。リップシンクが特に重要な部分については、その都度明記します。
AIボイスオーバー翻訳の仕組み
AIによる処理プロセスは4つのステップに分かれており、一般的なコンテンツであれば各ステップ数十秒〜数分で完了します。
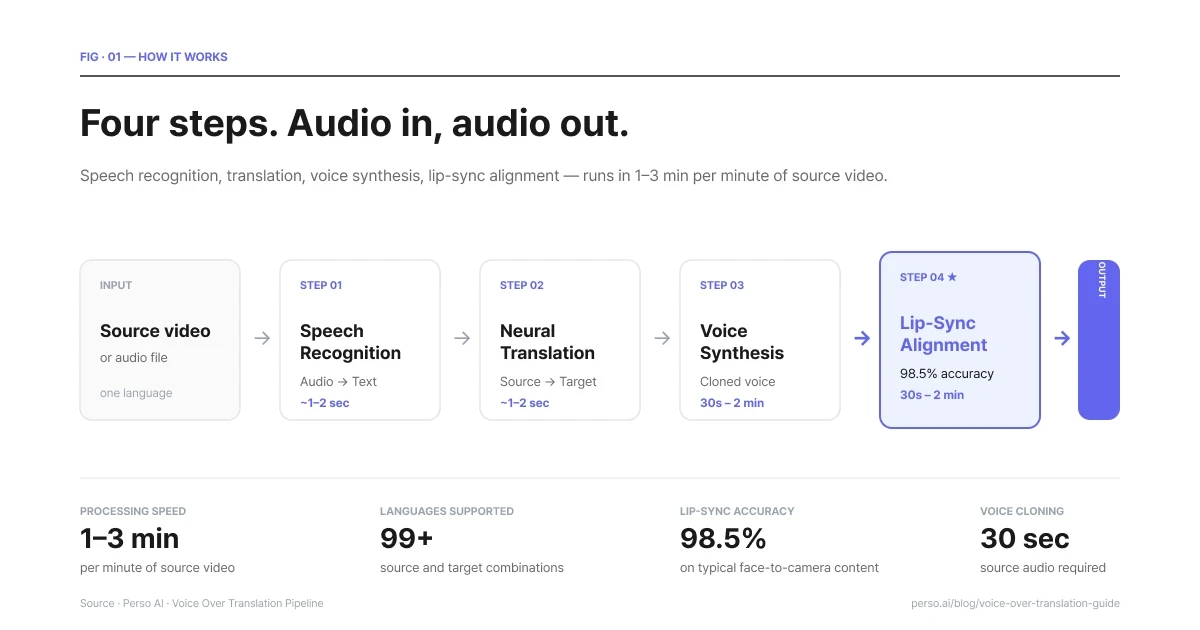
4つのステップ。音声の入力から出力まで、元の動画1分あたり1〜3分で処理。
ステップ1:音声認識 元の音声をテキスト(書き起こし文)に変換します。最新の音声認識は、アクセント、BGM、複数人の話し手、自然な話し方の癖(「あー」「えー」などの不要な言葉遣い、一時停止、言い淀みなど)に対応しています。ここでの書き起こしがその後のすべてのステップの土台となるため、その精度は想像以上に重要です。最初の書き起こしが間違っていると、不正確な翻訳になり、結果として不自然なボイスオーバーが作成されてしまいます。
ステップ2:翻訳 書き起こしたテキストを、書き言葉ではなく話し言葉(口語)に適したニューラル翻訳エンジンで処理します。話し言葉は、書き言葉に比べて短く、慣用表現が多く、文脈に依存しやすい特徴があります。そのため、文書の翻訳では優れた翻訳モデルでも、音声の翻訳には十分でない場合があります。最適化されたモデルを使うことで、元の音声のペース(話す速度やタイミング)に最も近い、ターゲット言語の台本が出力されます。
ステップ3:音声合成 翻訳された台本を音声に変換します。これには次の2つの方法があります。
1つ目は、ストックボイス(合成音声ライブラリ)の使用です。既存の音声リストから選んで適用するだけなので、高速で著作権・ライセンスの問題もありませんが、元の話し手の声とは全く異なる声になります。
2つ目は、ボイスクローニング(音声複製)です。元の話し手の声を学習させ、その声の特長を引き継いだまま別の言語を話しているように音声を合成します。仕上がりは、まるで本人が他国語を喋っているようになります。プロレベルのボイスオーバー翻訳では、この機能が非常に高く評価されています。
ステップ4:リップシンク調整(動画の場合) 元のデータが動画の場合、合成された音声は人物の唇の動き(リップシンク)に合うよう自動調整されます。最新のシステムでは、一般的なコンテンツにおいて約98%の精度を誇ります。このプロセスがないと、元の言語の口の動きと新しく吹き替えられた音声音のタイミングがズレてしまい、視聴者がすぐ違和感を抱く原因になります。
Perso AIは、これらの各ステップを1つのスムーズなワークフローに統合しました。動画をアップロードしてターゲット言語を選択するだけで、完成した動画が出力されます。処理に必要な時間は、元の動画1分あたり約1〜3分(5分の動画なら約5〜15分)です。
ボイスオーバー翻訳が必要となるタイミング
「翻訳が必要か、不要か」というビジネス視点での判断は明らかであることが多いでしょう。重要なのは「どの翻訳形式を選択すべきか」という点です。
ボイスオーバー翻訳が適しているケース:
配信しているコンテンツが動画で、視聴者の大半が動画として消費する場合です。字幕でも内容は伝わりますが、海外の視聴者に対する視聴維持率のデータによると、一貫して「字幕動画」よりも「吹き替え動画(音声あり)」の方が高いパフォーマンスを示しています。「AIダビング市場動向 2026年レポート」によると、AIで吹き替えられた動画の96%が、生成されたその日のうちに共有・配信されています。これは、アーカイブ(保存用)ではなく、多くの人に広めるためにコンテンツが作成された動きを示しています。
独自のキャラクターや、声を用いたブランドを大切にしたい場合。クリエイター自身の「声」はブランド価値の一部であり、企業のナレーターの声もそのブランドアイデンティティの一部です。音声クローン機能を使ったボイスオーバー翻訳であれば、言語が変わっても、そのブランドイメージやアイデンティティを保つことができます。これは、字幕だけの翻訳では失われてしまう価値です。
視聴者が「スマートフォン等で移動中に見る」場合や、「ながら聴き・ながら見」をする場合。字幕付きの動画は、常に画面を見続ける必要があります。一方で、ボイスオーバー翻訳であれば、運転中、料理中、作業中にも「耳から」内容を聴くことができます。モバイル普及率の高い地域(インド、東南アジア、ラテンアメリカなど)では、このような理由から、字幕よりも吹き替えられたコンテンツが広く好まれる傾向にあります。
一度に複数の市場(多国言語圏)に向けて一斉に配信したい場合。字幕の制作は、追加する言語が増えるごとに、タイミングの調整、文字のフォーマット、映像への埋め込みなどの作業が言語の数だけ繰り返されます。一方で、AIボイスオーバー翻訳の処理効率は非常に高く、一度仕組みをセットアップしてしまえば、6つ目や7つ目の言語を追加するのに要する時間はわずか数分のコンピューター処理で済み、エディターが何日も書き出し作業にとらわれる必要はありません。
ボイスオーバー翻訳が不向きなケース:
対象とする視聴者が「字幕」を強く好む場合です。例えば、日本の視聴者が外国映画を鑑賞する際、字幕版を好む傾向がこれにあたります。中には、コストに関わらず字幕が標準とされる分野もあります。制作を決定する前に、まずはターゲット層の好みをテストすることが推奨されます。
動画自体が非常に短く、字幕制作が極めて容易な場合です。例えば、60秒のソーシャルメディア向けショート動画であれば、わざわざボイスオーバーのシステムを使う必要はないかもしれません。
「音声そのもの」に特別な価値がある場合。有名なナレーター、著名な俳優の独特な語り、またはオリジナルの生演奏・生録音の声そのものが重要なコンテンツ価値(資産)である場合、それを吹き替えに置き換えてしまうとコンテンツの価値そのものが変わってしまいます。このようなケースでは、元の音声を残しながら字幕を使用するのが最適です。
ボイスオーバー翻訳 vs 字幕 — 最適なフォーマットの選び方
字幕とボイスオーバー翻訳は、どちらも「他言語の話者にアプローチする」という同じビジネス目的を持っていますが、視聴者の体験は大きく異なります。

字幕とボイスオーバー翻訳 — それぞれが力を発揮するシーンの違い。
項目 | 字幕 | ボイスオーバー翻訳 |
|---|---|---|
1言語あたりのコスト | 低(主に作業時間コストのみ) | 中(システム利用費用+音声ライセンス) |
1言語あたりの制作時間 | 数時間単位 | 数分単位(AI活用時) |
視聴者体験 | 文字を読む必要がある | 母国語で耳から自然に理解できる |
移動中・ながら視聴への適性 | 限定的 | 非常に良く機能する |
ブランド音声の維持 | 可能(元の音声をそのまま使用するため) | 可能(音声クローンを使用した場合) |
アクセビリティ(難聴者向け) | ✅ 必須 | 別途、字幕用トラックの追加が必要 |
最適なターゲット | 短いクリップ、ニッチな視聴者層 | 大規模なフル動画展開 |
実務においては、現在の多くの制作体制で、基本としてボイスオーバー翻訳を採用し、同時にアクセシビリティ(支援技術)用のトラックとして字幕も用意するという方法を選択しています。AIダビングプラットフォームを使用すると、ステップ1と2ですでに文字起こしデータと翻訳結果が得られているため、同じ処理プロセスから両方を同時に作成・出力することが主流です。
AIを使ったボイスオーバー翻訳の方法(ステップ・バイ・ステップ)
以下では、Perso AI上での制作プロセスを説明していきます。他のプラットフォームでもメニュー名や画面構成は異なりますが、基本的な仕組みは同じです。
1. 素材をアップロードする: 使用する動画または音声ファイルをドラッグ&ドロップします。一般的なMP4、MOV、MP3、WAV形式に対応しています。YouTube動画を使用する場合は、動画リンク(URL)を貼り付けるだけで利用可能です。
2. ターゲット言語を選択する: 翻訳を希望する任意の言語を選択します(複数選択可)。Perso AIは、英語をはじめ、日本語、韓国語、スペイン語、ポルトガル語、フランス語、ドイツ語など、さまざまな地域のご要望に対して、計99以上の言語ペアに対応しています。
3. 自動書き起こし文(トランスクリプト)を確認する: 最初に、元の動画の音声をAIが認識して書き起こしたテキストを確認します。翻訳ステップに進む前に、ここで音声認識の誤変換を手動で修正しておくことをお勧めします。初期段階の修正が、仕上がりの信頼性を大きく左右します。
4. 翻訳文を編集する(オプション): 音声合成を開始する前に、翻訳後のターゲット言語の文章を確認・修正します。専門的なブランド名、業界特有の専門用語、または直訳では通じにくい慣用句などは、ここで修正してください。この段階での確認作業が、後からの修正コストを抑える重要なポイントです。
5. 作成・生成する: 音声合成と、映像に合わせたリップシンク同期がバックグラウンドで開始されます。処理に必要な時間は、元の動画1分あたりおよそ1〜3分(5分の動画なら約5〜15分)です。
6. ダウンロードまたは共有する: 処理が完了すると、言語別の動画ファイル(MP4形式)と、字幕ファイル(.srt形式)がエクスポートされます。動画を必要としない「音声のみ」の利用向けに、MP3形式での音声出力設定にも対応しています。
これらすべての一連の動作が一つのプラットフォーム内で完結します。「AIダビング市場動向 2026年レポート」における「AI吹き替えされた動画の96%がその日のうちに共有・配信されている」という調査結果は、異なる様々な処理ツールをバラバラに行き来するやり方ではなく、このように1つのワークフローで完結する仕組みを利用しているクリエイターが多いことを裏付けています。
ボイスオーバー翻訳における「品質」の評価基準
生成される音声の品質は、大きく分けて以下の「3つの要素」で構成されます。これらはすべてが重要であり、どこか1つでも満たされていないと、不自然な印象になってしまいます。
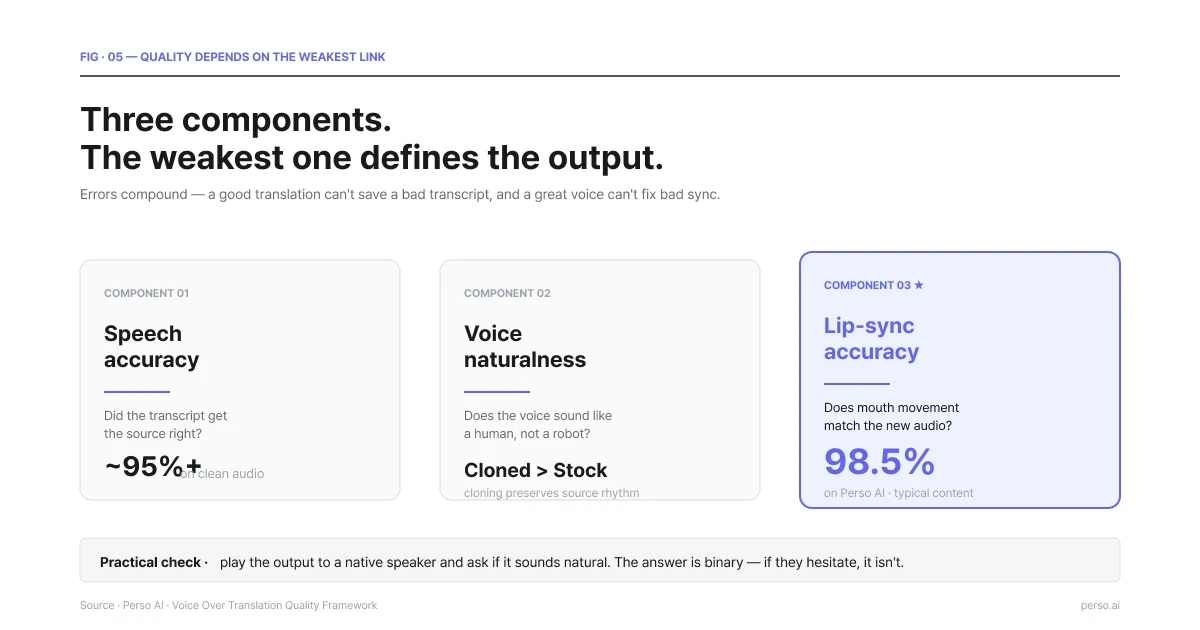
3つの要素。最も劣る部分がそのまま成果物の最終的なクオリティとなります。
音声内容の正確さ(Speech accuracy): 元の動画で語られている内容が正しく翻訳されているかどうかの基準です。専門用語やブランド名の誤訳が最も一般的なエラーとなりやすいため、音声合成を開始する前に翻訳後の台本を一度確認して間違いを防ぐことが重要です。
音声の自然さ(Voice naturalness): 人間のような話し方になっているか、それともロボットが文章をただ読み上げているように聞こえるかという指標です。最新のAI技術により違和感は限りなく低減されていますが、イントネーションや間の取り方など細部に注意を払う必要があります。特に、元の話し手の「音声のクローニング」は、元音声の自然なリズムが活かされるため、ストック音声を使用するよりも滑らかで一貫しやすいメリットがあります。
口の動きとのシンク精度(Lip-sync accuracy ※動画の場合): 映像内の唇の動きと、再生される吹き替え音声がしっかり同期しているかの度合いです。Perso AIは、このプロセスにおいて業界トップクラスのリップシンク同期精度(約98.5%)を公表しています。顔のクローズアップ動画では口元のズレが目立ちやすいため、精度を重視することが極めて重要ですが、離れたアングル(引きのカメラショットなど)では目立ちにくくなります。
品質のベストなセルフチェック方法:完成した動画をターゲット言語のネイティブスピーカーに確認してもらい、違和感がないか尋ねてみる、という方法です。少しでも不自然さを感じた場合は、さらに調整を重ねたほうが良い好機です。
ボイスオーバー翻訳でよく使われる人気の言語
他言語対応のご要望は、均等ではなく一部の特定の言語に集中する傾向があります。Perso AIにて取り扱われた316,856以上の吹き替えプロジェクト、および4,023人以上の専門クリエイターによるデータから分析したところ、グローバル対応を目指すコンテンツの主要な翻訳先(ターゲット言語)の分布が明らかになりました。
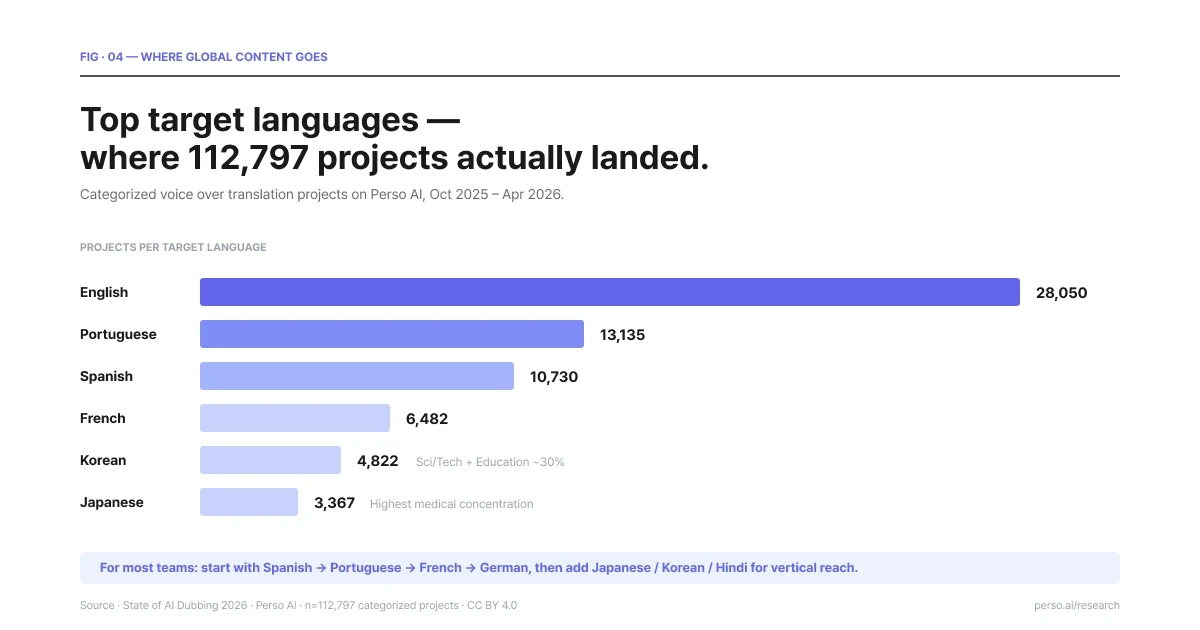
主要なターゲット言語の分布。合計112,797のプロジェクトにおよぶ実績。出典:AIダビング市場動向 2026年レポート
英語は、数万件以上のプロジェクト(28,050件)で不動のシェアを誇るものの、特定の1つの業界に固まるというより、各分野(最大でも14%以下)へ均等に広く分布しているのが特徴です。主に英語圏以外の国のクリエイターが、海外へ幅広く配信する際のハブ言語として機能しています。
ポルトガル語(13,135件)は、エンターテインメント、教育、宗教(特にブラジル向けポルトガル語など)、あらゆるジャンルの多様なニーズに対応しやすい傾向があります。興味深い点として、ポルトガル語は、世界市場において「キリスト教学等の信仰コンテンツ」における英語(25.6%)と並んで非常に多くのシェア(25.2%)を占めていました。これは、中南米向けではスペイン語が主流であるという一般的な予想を覆し、各方面に大きな驚きをもたらした調査結果でした。
スペイン語(10,730件)は、特に教育教育サービスや学習・教養、信仰等のジャンルで中南米を中心に強い需要を確立しています。
韓国語(4,822件)は、その約30%がサイエンス&テクノロジー、そして教育(学び・ナレッジ発信)の2大ジャンルに大きく寄与している点がユニークな特徴です。一般的なエンタメコンテンツの枠を超えて、幅広い知識や技術情報の分野に広く浸透しています。
日本語(3,367件)は、医療やヘルスケア、患者様向けの健康情報の提供など、医療専門領域での翻訳の割合(メディカル分野)が他のターゲット市場に比べて突出して高いという興味深いデータを記録しています。
フランス語(6,482件)は、ドキュメンタリージャンルでの運用が目立ちます。フランスならではの、ドキュメンタリー番組の制作や配信といった豊かな文化事情がここにも反映されています。
初めてのボイスオーバー翻訳で、どの言語から手をつければよいか迷った際の推奨パターンとしては:まずは最も広く利用されやすい「スペイン語 → ポルトガル語 → フランス語 → ドイツ語」の順番で検討し、のちにターゲット市場や特定ジャンルを拡張するタイミングで「日本語、韓国語、ヒンディー語、アラビア語」へとアプローチを広げていく展開が実践的です。
ボイスオーバー翻訳のコスト比較:AI vs 人(Human)
AIの導入で最も大きな変化をもたらした要素は、やはり従来までと比べた圧倒的なコストの違い(コストパフォーマンス)です。
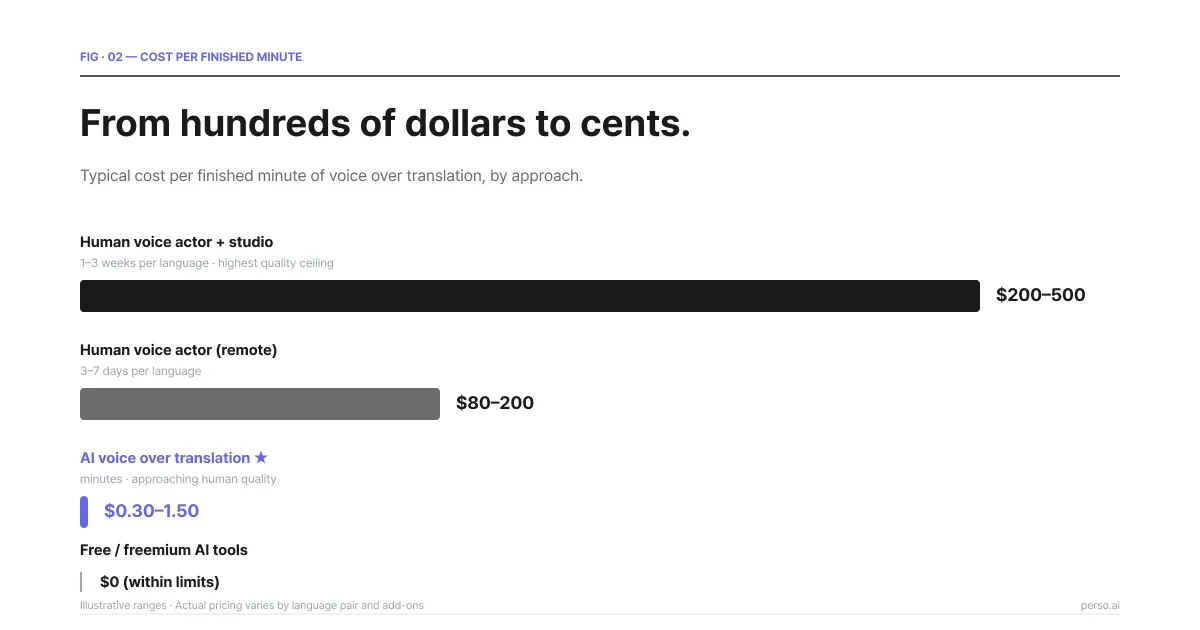
動画1分あたりのコストの比較。AIボイスオーバーは、スタジオによるプロのスタッフや声優を利用した場合と比べ、約100分の1の安価さです。
方法 | 一般的なコスト | 納期(ターンアラウンド) | 品質水準(限界値) |
|---|---|---|---|
プロの声優 + スタジオ収録 | 動画1分あたり $200〜$500 程度 | 1言語ごとに1〜3週間 | 最高峰 |
プロの声優(リモート収録) | 動画1分あたり $80〜$200 程度 | 1言語ごとに3〜7日 | 非常に高い |
AIボイスオーバー翻訳 | 動画1分あたり $0.30〜$1.50 程度 | 数分 | ほぼ人間に近い十分なレベル |
無料/フリープランのAIツール | 制限付きで $0 | 数分 | 品質にはムラがあり、不自然さやノイズが残る場合も多い |
上記は分かりやすい概算の数値例です。実際には言語ペア、追加オプション、プラットフォームによって価格は異なります。なお、Perso AIでは他社のような一律の切り上げ請求ではなく、実際に音声が再生された正確な再生時間に基づく秒単位の従量課金システムを採用しています。例えば、30秒の動画クリップなら「1分」に端数切り上げされることなく、文字通り「30秒分」のみが正しく課金される仕組みをとっています。
この価格メリットは、単一言語だけでなく複数言語の一斉展開でさらに効果を発揮します。人の声優さんを雇って1つの言語から10の言語へ拡大しようとすると、コストはそのまま10倍に跳ね上がりますが、AIをベースにしたボイスオーバーであれば、機械による演算処理が少し増えるだけであるため、初期構築以外のコスト増加を非常に小さく抑えることができます。これがまさに、「AIダビング市場動向 2026年レポート」内で提唱されている「他言語への参入ハードルがゼロに近づいた」とする理由であり、これまで多くの制作者が多額の予算のために多国語展開を断念していましたが、AIワークフローが世界展開への挑戦を後押ししています。
もちろん、映画の劇場用作品、大手コンソール向けAAA級ゲーム、一流ドキュメンタリーなど、「人間の声の非常に繊細な表現(感情表現や語り手の演技)」そのものが最も重要なエンターテインメント・コンテンツにおいては、今後もプロの役者さんや声優さんによる対応が必要であり、これが最高品質の基準であり続けるでしょう。ですが、企業の事業動画、マーケティング、eラーニング教材等のそれ以外の様々な分野においては、AIボイスオーバー翻訳は今やごく普通の選択肢(デファクトスタンダード)になりつつあります。
————————————————————————-
よくあるご質問(FAQ)
Q. ボイスオーバー翻訳と吹き替え(ダビング)は違うものですか?
はい、大きく言うと同じです。「ボイスオーバー翻訳」は、この取り組み全般を包括する広義の表現です。「ダビング(吹き替え)」は、特に会話の比重が高く、話者の唇の動き(リップシンク)に音声をぴったり合わせることが求められる動画に対して用いられる用語です。どちらも同じ裏側のAIシステム(音声認識、翻訳、音声合成、リップシンク同期)を活用して処理されます。
Q. AIで私自身の声をクローン(コピー)して翻訳させることができますか?
はい、可能です。最新のAIボイスオーバー翻訳のサービスでは「ボイスクローニング」機能が提供されています。あらかじめ30秒程度のクリアなノイズの少ない音声を準備して学習させるだけで、あなたの声の特徴を再現したまま、英語や日本語、ドイツ語、スペイン語などの多国言語を学習したあなたの声で喋らせることができます。
Q. AIのボイスオーバー翻訳は、どの程度正確ですか?
主に次の「3点」の精度から構成されます。1つ目は自動書き起こしの音声認識(クリアな音声データに対して約95%以上)、2つ目は翻訳機能(対象の言語ペアにより精度は異なり、英語-ヨーロッパ諸語などは高精度である一方、一部の希少な言語セットではやや低くなることもあります)、3つ目は動画に合わせるリップシンク率(Perso AIは様々なシーンにおいて約98.5%の高水準を公開しています)。これらの精度が組み合わさるため、不完全な部分をなるべく事前のテキスト編集機能などで底上げしておく必要があります。
Q. ボイスオーバー動画が仕上がるまでに、どのくらい時間がかかりますか?
元の動画の再生時間「1分あたり、おおむね1〜3分程度」の時間がかかります。5分間の動画を1つのターゲット言語に翻訳する場合は、約5分〜15分ほどで完成します。複数言語に対応させる際も、同じ処理から並列処理ができる構造であるため、「言語数×元の時間」のように時間が倍々と跳ね上がることはありません。
Q. 音声を実際に出力・生成する前に、翻訳後の文章(台本)を修正することは可能ですか?
はい、ほとんどのプロ向けAIプラットフォームではこのフローを搭載しています。テキストの翻訳処理が終わった段階で、まずは台本の形で文字がプレビューされるため、違和感のある自社の固有名詞や業界特有の表現、変な直訳になってしまっている箇所を「テキスト編集画面」で修正できます。収録されてしまった後の音声を手戻りで直すのは困難であるため、音声出力前に画面をチェックして修正できる仕組みは大変便利です。
Q. ボイスオーバー翻訳を適用するのと、単に「字幕(テロップ)」を付けるだけの違いは何ですか?
「字幕」は画面を目で見て読んでもらうのに対し、「ボイスオーバー(吹替)」は視聴者が耳を通じて理解できる点です。字幕では元のBGMやトーンを保つために音声をそのままにしてテキストを重ねます。一方で、ボイスオーバー翻訳は、完全に翻訳後の現地の言語に変更して吹き替える処理を行います。現代のAI処理プラットフォームでは、音声認識と翻訳が完了しているため、両方をセットで出力(吹き替え動画をメインにしながら、補正・アクセシビリティ用に同じ字幕ファイルを同時に書き出すなど)するやり方が一般的です。
Q. ボイスオーバー翻訳は、生放送(ライブ配信)でも使えますか?
現在のところ、実運用では推奨されません。現在のボイスオーバー翻訳は、主に収録済みの動画などの編集作業(ポストプロダクション)の中で利用される手順を前提としています。AIによるリアルタイムな「同時吹替(ライブダビング)」の技術も近年模索されていますが、「AIダビング市場動向 2026年レポート」でも示されている通り、これらが一般的として利用され始めるのは2026年末から2027年頃の見通しとなっています。そのため、現時点では「当日中に高速で編集するチーム向け」の制作プロセスとしてご活用いただくのが現実的です。
Q. 音声の対応言語は、最初はどのくらいの数を選ぶべきですか?
「AIダビング市場動向 2026年レポート」での調査によると、Perso AIに登録している一般クリエイターの多くは「まずは1つの外国語」から挑戦を始めていますが、実績を出しているトップ層は平均で最大15の言語に対応しています。もし選択肢に迷った際には、まずは既存のフォロワーや市場データでアクセスが多い「上位3〜5言語」を設定してみることを推奨します。その後、視聴維持時間や再生数データを分析しながら、必要に応じて他の言語を追加していくのが最も無駄のないアプローチです。
使ってみる
すでにお手元にあるコンテンツや動画を使ってAIによるボイスオーバー翻訳の効果を体験されたい場合は、まずは手持ちの短いサンプルを1つアップロードし、試しに2〜3の言語で作成してみるのが一番の近道です。多くの専門サービスでは、こうした無料のトライアルや体験用のプランを提供しています。
音声テキストの認識、自動翻訳、話者のクローン、映像とリップの同期までのすべての機能を一挙に完結できる統合ツールについては、ぜひPerso AIの動画翻訳ツールをご確認ください。また、他のさまざまなサービス構成、料金、クオリティを一度に詳しく比較・評価されたいお客様は、オルタナティブ・ハブ(競合比較ページ)も合わせてご覧ください。
なお、このガイド内に掲載されているすべての数値データやグラフィック、詳しい背景情報等は、クリエイティブ・コモンズ(CC BY 4.0)に基づき公表されている、弊社発行の最新調査資料「AIダビング市場動向 2026年レポート」に収録されている公式の内容となります。
概要: ボイスオーバー翻訳(ナレーション翻訳)とは、既存のボイスオーバー(ナレーション、解説動画の音声、録音された解説など)をもとに、別の言語で同じ内容の音声を作成するプロセスのことです。AIを活用したボイスオーバー翻訳では、音声認識、翻訳、そしてターゲット言語での音声合成という3つのステップが自動化されます。Perso AIを使用すれば、99以上の言語で翻訳できるだけでなく、オリジナルの話し手の声をクローン(コピー)して、まるで本人がその言語を話しているかのように仕上げることも可能です。
ボイスオーバー翻訳とは?
ボイスオーバー翻訳は、録音されたボイスオーバーの音声を別の言語に変換する技術です。インプット(入力)は音声(動画に付随する音声、または音声単体)で、アウトプット(出力)は別言語に変換された音声であり、そのまま素材として使用できます。
この分野の歴史はAIよりも古く、スタジオで何十年もの間、手動で行われてきました。まずターゲット言語の声優を雇い、翻訳された台本を渡し、録音し、動画に音声をミックスする、という流れです。その際の最大のネックは、常にコストと時間でした。かつては、3つの言語で5分の解説動画を作るために、3回のスタジオセッション、3人の声優、そして1週間の納期が必要でした。
AIは、成果の本質を変えることなく、そのワークフローを劇的に変化させました。仕上がりは、以前と同じ別言語のナレーションですが、完成までの時間が、数週間からわずか数分に短縮されたのです。
ボイスオーバー翻訳には、大きく分けて3つのカテゴリがあります:
1つ目は、ローカライズされたナレーション(解説動画、eラーニング教材、ドキュメンタリーのナレーション、オーディオブックなど)です。元の動画は1人のナレーターが全体を担当しており、翻訳版でも同じ声を維持するか、ターゲット言語の同様の別の声に置き換えます。
2つ目は、対話の音声吹き替え(ダビング)です。映画、ドラマ、インタビューなど、複数の話し手を別々に翻訳する必要があるコンテンツがこれに該当します。この領域では、業界用語として複数人の話し手向けを「ダビング」と呼びますが、それもボイスオーバー翻訳の実質的な中心分野となっています。
3つ目は、インターフェース音声です。自動音声応答(IVR)のメニュー画面、アプリの導入向け音声、製品内のナレーションなどが含まれます。規模は小さいですが、その仕組みは同じ翻訳・音声合成の処理プロセスで行われます。
このガイドでは、主に最初の2つのカテゴリ(ナレーション、対話ドキュメンタリー)に焦点を当てています。3つ目も同様のプロセスをより小さい規模で行うものです。
ボイスオーバー翻訳と吹き替え(ダビング)の違いは?
基本的には、ほぼ同じ意味で使われています。これらの違いはAIが登場する以前からあるもので、明確な境界はありませんでした。
業界で一般的に使われる主な区別は以下の通りです:
ボイスオーバー翻訳は通常、ドキュメンタリー、解説動画、オーディオブックなど、1人のナレーターが話すスタイルのコンテンツを指します。音声は口の動き(リップシンク)に合わせるのではなく、動画の上に重ねるナレーション形式になります。
吹き替え(ダビング)は通常、映画やドラマなどの会話や対話を伴い、複数の話し手がいる場合を指します。唇の動きに声を合わせる「リップシンク(口の動きの同期)」が重要視され、映画やドラマではデフォルトでこの用語が使われます。
実際には両者の境界はあいまいです。例えば、自分で解説するYouTube動画をスペイン語でも配信したい場合、それはボイスオーバー翻訳でしょうか、それともダビングでしょうか? どちらの言葉を使っても間違いではありません。どちらも「音声入力 → 翻訳 → 音声出力 → 動画へのミックス」という全く同じプロセスをたどります。
明確なルールで分けるとするなら、ボイスオーバー翻訳は「音声翻訳」全般を指す広い括りで、ダビングは「口の動きに合わせること(リップシンク)」が求められる場合、と捉えるのが分かりやすいでしょう。どちらも同じAIのシステムで処理されます。AIメディアの4レイヤーモデルでは、業界でどう呼ばれるかに関わらず、これを「レイヤー4(配信レイヤー)」として定義しています。
このガイドの残り部分では、総称として「ボイスオーバー翻訳」という言葉を使用します。リップシンクが特に重要な部分については、その都度明記します。
AIボイスオーバー翻訳の仕組み
AIによる処理プロセスは4つのステップに分かれており、一般的なコンテンツであれば各ステップ数十秒〜数分で完了します。
4つのステップ。音声の入力から出力まで、元の動画1分あたり1〜3分で処理。
ステップ1:音声認識 元の音声をテキスト(書き起こし文)に変換します。最新の音声認識は、アクセント、BGM、複数人の話し手、自然な話し方の癖(「あー」「えー」などの不要な言葉遣い、一時停止、言い淀みなど)に対応しています。ここでの書き起こしがその後のすべてのステップの土台となるため、その精度は想像以上に重要です。最初の書き起こしが間違っていると、不正確な翻訳になり、結果として不自然なボイスオーバーが作成されてしまいます。
ステップ2:翻訳 書き起こしたテキストを、書き言葉ではなく話し言葉(口語)に適したニューラル翻訳エンジンで処理します。話し言葉は、書き言葉に比べて短く、慣用表現が多く、文脈に依存しやすい特徴があります。そのため、文書の翻訳では優れた翻訳モデルでも、音声の翻訳には十分でない場合があります。最適化されたモデルを使うことで、元の音声のペース(話す速度やタイミング)に最も近い、ターゲット言語の台本が出力されます。
ステップ3:音声合成 翻訳された台本を音声に変換します。これには次の2つの方法があります。
1つ目は、ストックボイス(合成音声ライブラリ)の使用です。既存の音声リストから選んで適用するだけなので、高速で著作権・ライセンスの問題もありませんが、元の話し手の声とは全く異なる声になります。
2つ目は、ボイスクローニング(音声複製)です。元の話し手の声を学習させ、その声の特長を引き継いだまま別の言語を話しているように音声を合成します。仕上がりは、まるで本人が他国語を喋っているようになります。プロレベルのボイスオーバー翻訳では、この機能が非常に高く評価されています。
ステップ4:リップシンク調整(動画の場合) 元のデータが動画の場合、合成された音声は人物の唇の動き(リップシンク)に合うよう自動調整されます。最新のシステムでは、一般的なコンテンツにおいて約98%の精度を誇ります。このプロセスがないと、元の言語の口の動きと新しく吹き替えられた音声音のタイミングがズレてしまい、視聴者がすぐ違和感を抱く原因になります。
Perso AIは、これらの各ステップを1つのスムーズなワークフローに統合しました。動画をアップロードしてターゲット言語を選択するだけで、完成した動画が出力されます。処理に必要な時間は、元の動画1分あたり約1〜3分(5分の動画なら約5〜15分)です。
ボイスオーバー翻訳が必要となるタイミング
「翻訳が必要か、不要か」というビジネス視点での判断は明らかであることが多いでしょう。重要なのは「どの翻訳形式を選択すべきか」という点です。
ボイスオーバー翻訳が適しているケース:
配信しているコンテンツが動画で、視聴者の大半が動画として消費する場合です。字幕でも内容は伝わりますが、海外の視聴者に対する視聴維持率のデータによると、一貫して「字幕動画」よりも「吹き替え動画(音声あり)」の方が高いパフォーマンスを示しています。「AIダビング市場動向 2026年レポート」によると、AIで吹き替えられた動画の96%が、生成されたその日のうちに共有・配信されています。これは、アーカイブ(保存用)ではなく、多くの人に広めるためにコンテンツが作成された動きを示しています。
独自のキャラクターや、声を用いたブランドを大切にしたい場合。クリエイター自身の「声」はブランド価値の一部であり、企業のナレーターの声もそのブランドアイデンティティの一部です。音声クローン機能を使ったボイスオーバー翻訳であれば、言語が変わっても、そのブランドイメージやアイデンティティを保つことができます。これは、字幕だけの翻訳では失われてしまう価値です。
視聴者が「スマートフォン等で移動中に見る」場合や、「ながら聴き・ながら見」をする場合。字幕付きの動画は、常に画面を見続ける必要があります。一方で、ボイスオーバー翻訳であれば、運転中、料理中、作業中にも「耳から」内容を聴くことができます。モバイル普及率の高い地域(インド、東南アジア、ラテンアメリカなど)では、このような理由から、字幕よりも吹き替えられたコンテンツが広く好まれる傾向にあります。
一度に複数の市場(多国言語圏)に向けて一斉に配信したい場合。字幕の制作は、追加する言語が増えるごとに、タイミングの調整、文字のフォーマット、映像への埋め込みなどの作業が言語の数だけ繰り返されます。一方で、AIボイスオーバー翻訳の処理効率は非常に高く、一度仕組みをセットアップしてしまえば、6つ目や7つ目の言語を追加するのに要する時間はわずか数分のコンピューター処理で済み、エディターが何日も書き出し作業にとらわれる必要はありません。
ボイスオーバー翻訳が不向きなケース:
対象とする視聴者が「字幕」を強く好む場合です。例えば、日本の視聴者が外国映画を鑑賞する際、字幕版を好む傾向がこれにあたります。中には、コストに関わらず字幕が標準とされる分野もあります。制作を決定する前に、まずはターゲット層の好みをテストすることが推奨されます。
動画自体が非常に短く、字幕制作が極めて容易な場合です。例えば、60秒のソーシャルメディア向けショート動画であれば、わざわざボイスオーバーのシステムを使う必要はないかもしれません。
「音声そのもの」に特別な価値がある場合。有名なナレーター、著名な俳優の独特な語り、またはオリジナルの生演奏・生録音の声そのものが重要なコンテンツ価値(資産)である場合、それを吹き替えに置き換えてしまうとコンテンツの価値そのものが変わってしまいます。このようなケースでは、元の音声を残しながら字幕を使用するのが最適です。
ボイスオーバー翻訳 vs 字幕 — 最適なフォーマットの選び方
字幕とボイスオーバー翻訳は、どちらも「他言語の話者にアプローチする」という同じビジネス目的を持っていますが、視聴者の体験は大きく異なります。
字幕とボイスオーバー翻訳 — それぞれが力を発揮するシーンの違い。
項目 | 字幕 | ボイスオーバー翻訳 |
|---|---|---|
1言語あたりのコスト | 低(主に作業時間コストのみ) | 中(システム利用費用+音声ライセンス) |
1言語あたりの制作時間 | 数時間単位 | 数分単位(AI活用時) |
視聴者体験 | 文字を読む必要がある | 母国語で耳から自然に理解できる |
移動中・ながら視聴への適性 | 限定的 | 非常に良く機能する |
ブランド音声の維持 | 可能(元の音声をそのまま使用するため) | 可能(音声クローンを使用した場合) |
アクセビリティ(難聴者向け) | ✅ 必須 | 別途、字幕用トラックの追加が必要 |
最適なターゲット | 短いクリップ、ニッチな視聴者層 | 大規模なフル動画展開 |
実務においては、現在の多くの制作体制で、基本としてボイスオーバー翻訳を採用し、同時にアクセシビリティ(支援技術)用のトラックとして字幕も用意するという方法を選択しています。AIダビングプラットフォームを使用すると、ステップ1と2ですでに文字起こしデータと翻訳結果が得られているため、同じ処理プロセスから両方を同時に作成・出力することが主流です。
AIを使ったボイスオーバー翻訳の方法(ステップ・バイ・ステップ)
以下では、Perso AI上での制作プロセスを説明していきます。他のプラットフォームでもメニュー名や画面構成は異なりますが、基本的な仕組みは同じです。
1. 素材をアップロードする: 使用する動画または音声ファイルをドラッグ&ドロップします。一般的なMP4、MOV、MP3、WAV形式に対応しています。YouTube動画を使用する場合は、動画リンク(URL)を貼り付けるだけで利用可能です。
2. ターゲット言語を選択する: 翻訳を希望する任意の言語を選択します(複数選択可)。Perso AIは、英語をはじめ、日本語、韓国語、スペイン語、ポルトガル語、フランス語、ドイツ語など、さまざまな地域のご要望に対して、計99以上の言語ペアに対応しています。
3. 自動書き起こし文(トランスクリプト)を確認する: 最初に、元の動画の音声をAIが認識して書き起こしたテキストを確認します。翻訳ステップに進む前に、ここで音声認識の誤変換を手動で修正しておくことをお勧めします。初期段階の修正が、仕上がりの信頼性を大きく左右します。
4. 翻訳文を編集する(オプション): 音声合成を開始する前に、翻訳後のターゲット言語の文章を確認・修正します。専門的なブランド名、業界特有の専門用語、または直訳では通じにくい慣用句などは、ここで修正してください。この段階での確認作業が、後からの修正コストを抑える重要なポイントです。
5. 作成・生成する: 音声合成と、映像に合わせたリップシンク同期がバックグラウンドで開始されます。処理に必要な時間は、元の動画1分あたりおよそ1〜3分(5分の動画なら約5〜15分)です。
6. ダウンロードまたは共有する: 処理が完了すると、言語別の動画ファイル(MP4形式)と、字幕ファイル(.srt形式)がエクスポートされます。動画を必要としない「音声のみ」の利用向けに、MP3形式での音声出力設定にも対応しています。
これらすべての一連の動作が一つのプラットフォーム内で完結します。「AIダビング市場動向 2026年レポート」における「AI吹き替えされた動画の96%がその日のうちに共有・配信されている」という調査結果は、異なる様々な処理ツールをバラバラに行き来するやり方ではなく、このように1つのワークフローで完結する仕組みを利用しているクリエイターが多いことを裏付けています。
ボイスオーバー翻訳における「品質」の評価基準
生成される音声の品質は、大きく分けて以下の「3つの要素」で構成されます。これらはすべてが重要であり、どこか1つでも満たされていないと、不自然な印象になってしまいます。
3つの要素。最も劣る部分がそのまま成果物の最終的なクオリティとなります。
音声内容の正確さ(Speech accuracy): 元の動画で語られている内容が正しく翻訳されているかどうかの基準です。専門用語やブランド名の誤訳が最も一般的なエラーとなりやすいため、音声合成を開始する前に翻訳後の台本を一度確認して間違いを防ぐことが重要です。
音声の自然さ(Voice naturalness): 人間のような話し方になっているか、それともロボットが文章をただ読み上げているように聞こえるかという指標です。最新のAI技術により違和感は限りなく低減されていますが、イントネーションや間の取り方など細部に注意を払う必要があります。特に、元の話し手の「音声のクローニング」は、元音声の自然なリズムが活かされるため、ストック音声を使用するよりも滑らかで一貫しやすいメリットがあります。
口の動きとのシンク精度(Lip-sync accuracy ※動画の場合): 映像内の唇の動きと、再生される吹き替え音声がしっかり同期しているかの度合いです。Perso AIは、このプロセスにおいて業界トップクラスのリップシンク同期精度(約98.5%)を公表しています。顔のクローズアップ動画では口元のズレが目立ちやすいため、精度を重視することが極めて重要ですが、離れたアングル(引きのカメラショットなど)では目立ちにくくなります。
品質のベストなセルフチェック方法:完成した動画をターゲット言語のネイティブスピーカーに確認してもらい、違和感がないか尋ねてみる、という方法です。少しでも不自然さを感じた場合は、さらに調整を重ねたほうが良い好機です。
ボイスオーバー翻訳でよく使われる人気の言語
他言語対応のご要望は、均等ではなく一部の特定の言語に集中する傾向があります。Perso AIにて取り扱われた316,856以上の吹き替えプロジェクト、および4,023人以上の専門クリエイターによるデータから分析したところ、グローバル対応を目指すコンテンツの主要な翻訳先(ターゲット言語)の分布が明らかになりました。
主要なターゲット言語の分布。合計112,797のプロジェクトにおよぶ実績。出典:AIダビング市場動向 2026年レポート
英語は、数万件以上のプロジェクト(28,050件)で不動のシェアを誇るものの、特定の1つの業界に固まるというより、各分野(最大でも14%以下)へ均等に広く分布しているのが特徴です。主に英語圏以外の国のクリエイターが、海外へ幅広く配信する際のハブ言語として機能しています。
ポルトガル語(13,135件)は、エンターテインメント、教育、宗教(特にブラジル向けポルトガル語など)、あらゆるジャンルの多様なニーズに対応しやすい傾向があります。興味深い点として、ポルトガル語は、世界市場において「キリスト教学等の信仰コンテンツ」における英語(25.6%)と並んで非常に多くのシェア(25.2%)を占めていました。これは、中南米向けではスペイン語が主流であるという一般的な予想を覆し、各方面に大きな驚きをもたらした調査結果でした。
スペイン語(10,730件)は、特に教育教育サービスや学習・教養、信仰等のジャンルで中南米を中心に強い需要を確立しています。
韓国語(4,822件)は、その約30%がサイエンス&テクノロジー、そして教育(学び・ナレッジ発信)の2大ジャンルに大きく寄与している点がユニークな特徴です。一般的なエンタメコンテンツの枠を超えて、幅広い知識や技術情報の分野に広く浸透しています。
日本語(3,367件)は、医療やヘルスケア、患者様向けの健康情報の提供など、医療専門領域での翻訳の割合(メディカル分野)が他のターゲット市場に比べて突出して高いという興味深いデータを記録しています。
フランス語(6,482件)は、ドキュメンタリージャンルでの運用が目立ちます。フランスならではの、ドキュメンタリー番組の制作や配信といった豊かな文化事情がここにも反映されています。
初めてのボイスオーバー翻訳で、どの言語から手をつければよいか迷った際の推奨パターンとしては:まずは最も広く利用されやすい「スペイン語 → ポルトガル語 → フランス語 → ドイツ語」の順番で検討し、のちにターゲット市場や特定ジャンルを拡張するタイミングで「日本語、韓国語、ヒンディー語、アラビア語」へとアプローチを広げていく展開が実践的です。
ボイスオーバー翻訳のコスト比較:AI vs 人(Human)
AIの導入で最も大きな変化をもたらした要素は、やはり従来までと比べた圧倒的なコストの違い(コストパフォーマンス)です。
動画1分あたりのコストの比較。AIボイスオーバーは、スタジオによるプロのスタッフや声優を利用した場合と比べ、約100分の1の安価さです。
方法 | 一般的なコスト | 納期(ターンアラウンド) | 品質水準(限界値) |
|---|---|---|---|
プロの声優 + スタジオ収録 | 動画1分あたり $200〜$500 程度 | 1言語ごとに1〜3週間 | 最高峰 |
プロの声優(リモート収録) | 動画1分あたり $80〜$200 程度 | 1言語ごとに3〜7日 | 非常に高い |
AIボイスオーバー翻訳 | 動画1分あたり $0.30〜$1.50 程度 | 数分 | ほぼ人間に近い十分なレベル |
無料/フリープランのAIツール | 制限付きで $0 | 数分 | 品質にはムラがあり、不自然さやノイズが残る場合も多い |
上記は分かりやすい概算の数値例です。実際には言語ペア、追加オプション、プラットフォームによって価格は異なります。なお、Perso AIでは他社のような一律の切り上げ請求ではなく、実際に音声が再生された正確な再生時間に基づく秒単位の従量課金システムを採用しています。例えば、30秒の動画クリップなら「1分」に端数切り上げされることなく、文字通り「30秒分」のみが正しく課金される仕組みをとっています。
この価格メリットは、単一言語だけでなく複数言語の一斉展開でさらに効果を発揮します。人の声優さんを雇って1つの言語から10の言語へ拡大しようとすると、コストはそのまま10倍に跳ね上がりますが、AIをベースにしたボイスオーバーであれば、機械による演算処理が少し増えるだけであるため、初期構築以外のコスト増加を非常に小さく抑えることができます。これがまさに、「AIダビング市場動向 2026年レポート」内で提唱されている「他言語への参入ハードルがゼロに近づいた」とする理由であり、これまで多くの制作者が多額の予算のために多国語展開を断念していましたが、AIワークフローが世界展開への挑戦を後押ししています。
もちろん、映画の劇場用作品、大手コンソール向けAAA級ゲーム、一流ドキュメンタリーなど、「人間の声の非常に繊細な表現(感情表現や語り手の演技)」そのものが最も重要なエンターテインメント・コンテンツにおいては、今後もプロの役者さんや声優さんによる対応が必要であり、これが最高品質の基準であり続けるでしょう。ですが、企業の事業動画、マーケティング、eラーニング教材等のそれ以外の様々な分野においては、AIボイスオーバー翻訳は今やごく普通の選択肢(デファクトスタンダード)になりつつあります。
————————————————————————-
よくあるご質問(FAQ)
Q. ボイスオーバー翻訳と吹き替え(ダビング)は違うものですか?
はい、大きく言うと同じです。「ボイスオーバー翻訳」は、この取り組み全般を包括する広義の表現です。「ダビング(吹き替え)」は、特に会話の比重が高く、話者の唇の動き(リップシンク)に音声をぴったり合わせることが求められる動画に対して用いられる用語です。どちらも同じ裏側のAIシステム(音声認識、翻訳、音声合成、リップシンク同期)を活用して処理されます。
Q. AIで私自身の声をクローン(コピー)して翻訳させることができますか?
はい、可能です。最新のAIボイスオーバー翻訳のサービスでは「ボイスクローニング」機能が提供されています。あらかじめ30秒程度のクリアなノイズの少ない音声を準備して学習させるだけで、あなたの声の特徴を再現したまま、英語や日本語、ドイツ語、スペイン語などの多国言語を学習したあなたの声で喋らせることができます。
Q. AIのボイスオーバー翻訳は、どの程度正確ですか?
主に次の「3点」の精度から構成されます。1つ目は自動書き起こしの音声認識(クリアな音声データに対して約95%以上)、2つ目は翻訳機能(対象の言語ペアにより精度は異なり、英語-ヨーロッパ諸語などは高精度である一方、一部の希少な言語セットではやや低くなることもあります)、3つ目は動画に合わせるリップシンク率(Perso AIは様々なシーンにおいて約98.5%の高水準を公開しています)。これらの精度が組み合わさるため、不完全な部分をなるべく事前のテキスト編集機能などで底上げしておく必要があります。
Q. ボイスオーバー動画が仕上がるまでに、どのくらい時間がかかりますか?
元の動画の再生時間「1分あたり、おおむね1〜3分程度」の時間がかかります。5分間の動画を1つのターゲット言語に翻訳する場合は、約5分〜15分ほどで完成します。複数言語に対応させる際も、同じ処理から並列処理ができる構造であるため、「言語数×元の時間」のように時間が倍々と跳ね上がることはありません。
Q. 音声を実際に出力・生成する前に、翻訳後の文章(台本)を修正することは可能ですか?
はい、ほとんどのプロ向けAIプラットフォームではこのフローを搭載しています。テキストの翻訳処理が終わった段階で、まずは台本の形で文字がプレビューされるため、違和感のある自社の固有名詞や業界特有の表現、変な直訳になってしまっている箇所を「テキスト編集画面」で修正できます。収録されてしまった後の音声を手戻りで直すのは困難であるため、音声出力前に画面をチェックして修正できる仕組みは大変便利です。
Q. ボイスオーバー翻訳を適用するのと、単に「字幕(テロップ)」を付けるだけの違いは何ですか?
「字幕」は画面を目で見て読んでもらうのに対し、「ボイスオーバー(吹替)」は視聴者が耳を通じて理解できる点です。字幕では元のBGMやトーンを保つために音声をそのままにしてテキストを重ねます。一方で、ボイスオーバー翻訳は、完全に翻訳後の現地の言語に変更して吹き替える処理を行います。現代のAI処理プラットフォームでは、音声認識と翻訳が完了しているため、両方をセットで出力(吹き替え動画をメインにしながら、補正・アクセシビリティ用に同じ字幕ファイルを同時に書き出すなど)するやり方が一般的です。
Q. ボイスオーバー翻訳は、生放送(ライブ配信)でも使えますか?
現在のところ、実運用では推奨されません。現在のボイスオーバー翻訳は、主に収録済みの動画などの編集作業(ポストプロダクション)の中で利用される手順を前提としています。AIによるリアルタイムな「同時吹替(ライブダビング)」の技術も近年模索されていますが、「AIダビング市場動向 2026年レポート」でも示されている通り、これらが一般的として利用され始めるのは2026年末から2027年頃の見通しとなっています。そのため、現時点では「当日中に高速で編集するチーム向け」の制作プロセスとしてご活用いただくのが現実的です。
Q. 音声の対応言語は、最初はどのくらいの数を選ぶべきですか?
「AIダビング市場動向 2026年レポート」での調査によると、Perso AIに登録している一般クリエイターの多くは「まずは1つの外国語」から挑戦を始めていますが、実績を出しているトップ層は平均で最大15の言語に対応しています。もし選択肢に迷った際には、まずは既存のフォロワーや市場データでアクセスが多い「上位3〜5言語」を設定してみることを推奨します。その後、視聴維持時間や再生数データを分析しながら、必要に応じて他の言語を追加していくのが最も無駄のないアプローチです。
使ってみる
すでにお手元にあるコンテンツや動画を使ってAIによるボイスオーバー翻訳の効果を体験されたい場合は、まずは手持ちの短いサンプルを1つアップロードし、試しに2〜3の言語で作成してみるのが一番の近道です。多くの専門サービスでは、こうした無料のトライアルや体験用のプランを提供しています。
音声テキストの認識、自動翻訳、話者のクローン、映像とリップの同期までのすべての機能を一挙に完結できる統合ツールについては、ぜひPerso AIの動画翻訳ツールをご確認ください。また、他のさまざまなサービス構成、料金、クオリティを一度に詳しく比較・評価されたいお客様は、オルタナティブ・ハブ(競合比較ページ)も合わせてご覧ください。
なお、このガイド内に掲載されているすべての数値データやグラフィック、詳しい背景情報等は、クリエイティブ・コモンズ(CC BY 4.0)に基づき公表されている、弊社発行の最新調査資料「AIダビング市場動向 2026年レポート」に収録されている公式の内容となります。
続きを読む
すべてを閲覧する



