AIダビング vs 音声クローン vs アバター:4レイヤーモデル



AIビデオ翻訳、ローカリゼーション、および吹き替えツール
無料でお試しください
AIダビング vs ボイスクローニング vs アバター:AIメディアの4レイヤーモデル
要約。 AIダビング、ボイスクローニング、アバター生成、およびテキスト翻訳は、AIメディアスタックの4つの異なるレイヤーに属しています。AIダビングは、完成した動画が言語の壁を越えるレイヤー4(配信レイヤー)に位置します。ボイスクローニング(レイヤー1)とアバター生成(レイヤー2)は素材(アセット)を作成します。テキスト翻訳(レイヤー3)は、配信前のパイプラインに位置します。このフレームワークにより、ElevenLabs、HeyGen、Synthesia、そしてPerso Dubbingが根本的に異なる課題を解決している理由が説明できます。
AIダビングとは何か?2026年における定義

| ダビングされた動画の96%が同日中に納品。レイヤー4における特徴的な行動パターン。
AIダビングとは、ある言語の動画を入力とし、配信準備が整った別の言語の動画を作成するワークフローのことです。入力は完成した動画であり、出力も完成した動画です。置き換わるのは言語のレイヤーのみです。
この定義は重要です。なぜなら、主流のメディア報道では、AIダビングがElevenLabsのようなボイスクローニングツールや、HeyGenのようなアバタージェネレーターと同一視されがちだからです。これらはAIインフラを共有していますが、メディア制作の異なる段階で異なる課題を解決しています。
簡単な例を挙げます。あるYouTuberが英語で10分間の動画を録画します。AIダビングを使用すれば、その動画は同じ日のうちに、音声、リップシンク、字幕がすべて調整された状態で12の市場に配信されます。一方、ボイスクローニングを使用した場合、YouTuberは任意のテキストを話すことができる自分の合成音声を手に入れますが、結果を組み立てるためには依然として台本、翻訳ステップ、動画編集者が必要です。ボイスクローニングはツールであり、AIダビングはワークフローなのです。
Perso Dubbingにおける4,023名のプロのクリエイターによる316,856件のダビングプロジェクトから作成された「AIダビングの現状2026レポート」では、ダビングをAIメディアスタックの他の部分から区別する行動パターンが明らかになりました。ダビングされた動画の96%がすぐに共有されたのです。ボイスクローニングやアバターは再利用されますが、ダビングされた動画はすぐに配信(出荷)されます。
一目でわかるAIメディアの4レイヤーモデル
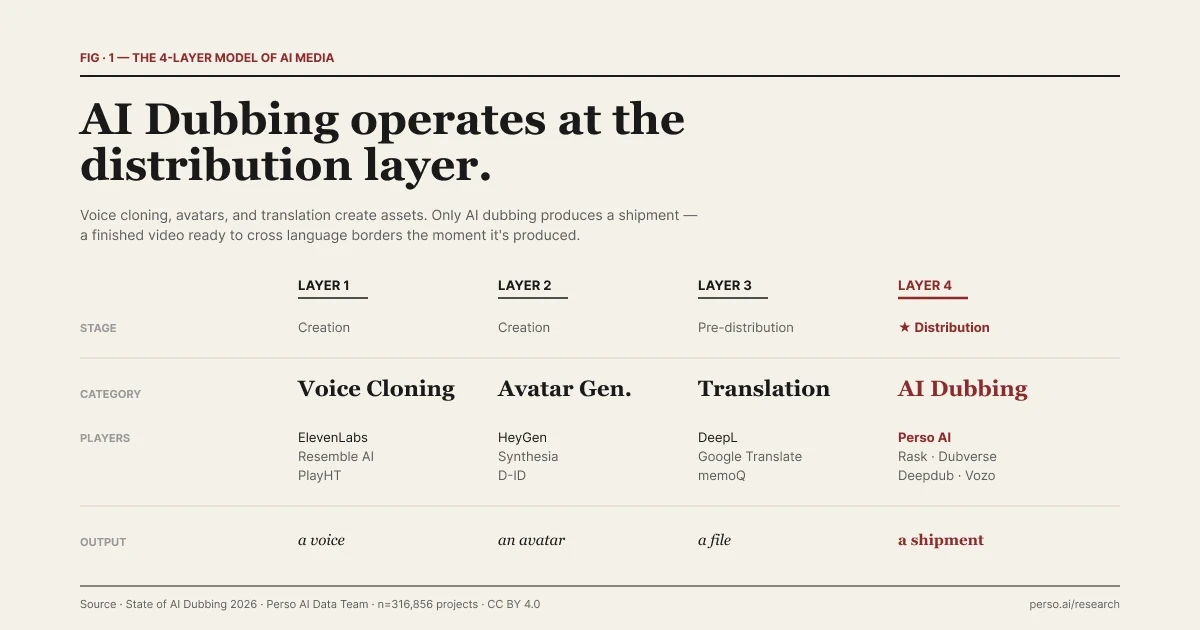
| AIメディアの4レイヤーモデル。各レイヤーは異なる問いに答えます。
以下のモデルは、「AIダビングの現状2026レポート」におけるPerso Dubbingの編集上の枠組みに由来しています。これは、業界で確定した分類法ではなく、各ツールがどこに位置するかを理解するための有用な方法です。境界線は曖昧であり、その点については後述します。しかし、この4段階の区分により、これらのツールが相互に代替不可能である理由が明確になります。
レイヤー | カテゴリー | 事例 | 出力 | 制作段階 |
|---|---|---|---|---|
1 | ボイスクローニング | ElevenLabs, Resemble AI, PlayHT | 合成音声。素材(アセット)は音声そのものです。 | 作成 |
2 | アバター生成 | HeyGen, Synthesia, D-ID | 合成された人物が登場する動画。アセットはアバターです。 | 作成 |
3 | テキスト翻訳 | Google 翻訳, DeepL | 翻訳されたテキスト。アセットは制作パイプライン内のファイルです。 | 配信前 |
4 | AIダビング | Perso Dubbingおよび同カテゴリーのツール | 複数の言語市場に同時に展開される動画。「アセット」は配信物(成果物)そのものです。 | ★ 配信 |
各レイヤーは異なる問いに答えます。レイヤー1は「機械は特定の人間のような声を出せるか?」に答えます。レイヤー2は「機械は特定の人間のように見えるか?」に答えます。レイヤー3は「これは他の言語で何と言っているか?」に答えます。そしてレイヤー4は「この完成した動画を、今日の午後にどうやって12の市場に届けるか?」に答えます。
最初の3つのレイヤーは、より大きな制作パイプラインに供給されるアセットを作成または修正します。4つ目のレイヤーは、その成果物を配信します。これがAIメディアスタックにおける最も明確な境界線であり、この記事の残りの部分で採用するフレームワークです。
レイヤー1 — ボイスクローニング (ElevenLabs, Resemble, PlayHT)
ボイスクローニングツールは、個人の音声サンプルを学習し、任意のテキストを話すことができる合成ボイスを作成します。出力は音声です。これは、単一の動画、ポッドキャスト、オーディオブックから独立して存在する再利用可能なアセットです。
ElevenLabs、Resemble AI、PlayHTなどがこの領域で競合しています。これらは、AIが初めてコンシューマークラスの品質を大規模に提供したレイヤーです(ElevenLabsの「Eleven Multilingual v2」は、2024年におけるこのカテゴリーの転換点でした)。ツールは驚くほど優れてきています。2026年において、30秒のオーディオで学習させたボイスクローンは、もはや本物と区別がつかないことがよくあります。
ボイスクローニングが「行わない」のは、言語の翻訳や動画の組み立てです。台本が必要です。翻訳が必要です。ソースが動画の場合、音声を入れ替えるための別の編集ソフトが必要です。ボイスクローニングは配信よりも上流に位置します。
ここで従来の捉え方に混乱が生じます。ElevenLabsもダビング機能を提供しており、動画のダビングにElevenLabsを使用しているクリエイターは、ツールの重心がボイスクローニングにあるにもかかわらず、実際にはAIダビングを行っています。4レイヤーモデルは、どのツールがどのサイロに属しているかではなく、それぞれのツールがどの問題を解決するために構築されたかに関するものです。ElevenLabsは音声を作成するために構築され、ダビングはその機能の上に組み立てられたワークフローです。対して、Perso Dubbingは動画をダビングするために構築され、ボイスクローニングはそのワークフロー内の1つのステップに過ぎません。
動画以外の用途(オーディオブック、自動音声応答(IVR)、ポッドキャスト、スクリーンリーダー、アクセシビリティなど)で合成音声が必要な場合は、レイヤー1が最適なレイヤーです。動画があり、金曜日までにそれを12の言語で用意する必要がある場合は、レイヤー4が最適なレイヤーです。
レイヤー2 — アバター生成 (HeyGen, Synthesia, D-ID)
アバター生成ツールは、主に台本から、合成された人物が登場する動画を作成します。テキストを入力または貼り付け、アバター(あらかじめ用意された顔、または自分のクローン)を選択すると、ツールが選択した言語と音声で台本を読み上げる顔の動画を出力します。
HeyGen、Synthesia、D-IDなどがこの領域で競合しています。このカテゴリーは、企業のL&D(学習と開発)や解説動画のユースケース(人物が話す動画が必要だが、実際に撮影したくない状況)から成長しました。アバターは、AIダビングが存在する前にその課題を解決しました。
アバターが「行わない」のは、既存の動画を取り込んで複数の言語市場向けに配信することです。これらは台本からスタートし、新しい動画を作成します。すでに存在する30分間のインタビュー動画がある場合、アバターツールは不適切なレイヤーです。元の映像を破棄してアバターの顔を再生成することになり、実際にインタビューした人物の存在感が失われてしまうからです。
アバターのカテゴリーもレイヤー4と境界が曖昧になりつつあります。HeyGenは多言語機能をリリースしました。Synthesiaは作成とローカライズの両方に位置づけられています。私たちが描く区別は「入力」です。アバターツールは台本を入力として動画を作成します。AIダビングツールは動画を入力として別の言語の動画を作成します。異なる課題であり、異なるレイヤーです。
まだ存在しないコンテンツのために合成のスポークスパーソンが必要な場合は、レイヤー2が適しています。すでに動画があり、それをローカライズする必要がある場合は、レイヤー4、つまり Perso DubbingとHeyGen、または Synthesia Grid との比較のようなツールが適しています。
レイヤー3 — テキスト翻訳 (Google 翻訳, DeepL)
テキスト翻訳は、このスタックの中で最も成熟したレイヤーです。Google 翻訳、DeepL、そしていくつかの専門的なツール(エンタープライズローカライズ用のmemoQやTradosなど)が長年にわたり稼働しています。出力は翻訳されたテキストです。アセットは、下流の制作ステップに供給されるファイル(台本、字幕、キャプション付きデータなど)です。
テキスト翻訳は配信前段階の処理です。これが最終ステップになることは稀です。翻訳された字幕は、視聴者に届く前に、タイミングを合わせたり、動画に焼き付けたり、ダビングされた音声トラックと組み合わせたりする必要があります。翻訳は入力であり、配信は別の場所で行われます。
これは、AIダビングツールが最も依存しているレイヤーです。すべてのAIダビングワークフローには、通常その言語ペア向けに訓練されたニューラル機械翻訳(NMT)モデルによる翻訳ステップが含まれています。例えば、Perso Dubbingのダビングパイプラインでは、音声認識ステップと音声合成ステップの間で翻訳ステップを呼び出しています。翻訳はレイヤー4の内部における配管のような役割を果たしています。
ローカライズチームが使用するための翻訳済みトランスクリプト、字幕ファイル、または台本が必要な場合は、レイヤー3が適しています。その翻訳がすでに完成した動画に組み込まれている必要がある場合は、翻訳レイヤーを離れ、ダビングレイヤーに入ったことになります。
レイヤー4 — AIダビング(配信レイヤー)
AIダビングは、このフレームワークが明らかにするために構築されたレイヤーです。その決定的な特徴は、出力が「作成段階のアセット」としてではなく、「配信イベント」として機能することです。
ワークフローは次の通りです。1つの動画を入力すると、それぞれが異なる言語で、すぐに配信可能な複数の完成した動画が出力されます。音声認識がソース動画を文字起こしし、翻訳がその文字起こしデータを変換します。音声合成がターゲット言語の音声を生成し、リップシンク調整が新しい音声を元の口の動きに合わせます。出力されるのは、アップロードするのと同等のスピードで言語の壁を越えた動画です。

| AIダビングのワークフロー内部。動画が入力され、多言語の動画が出力される
Perso Dubbingは私たちが最もよく知る事例であり、このプラットフォームのデータがこの記事の裏付けとなっています。909のアクティブなソースからターゲットへの言語ペア。16ヶ月間で316,856件のダビングプロジェクト。80カ国以上の4,023名のプロのクリエイター。これらのプロジェクトの96%が同日中に共有されました。これはレイヤー4をスタックの他の部分から区別する行動的な特徴です。
レイヤー4における「アセット」は少し特殊です。レイヤー1のアセットは音声、レイヤー2はアバター、レイヤー3はファイルです。しかし、レイヤー4の「アセット」は配信(出荷物)そのものであり、複数の市場の視聴者に同時に届くコンテンツです。枠組みは「何を作ったか?」から「どこに届いたか?」へとシフトします。

動画があり、明日までにそれを6つの言語の話者に届けたい場合、レイヤー4が最適なレイヤーです。
なぜ今、この区別が重要なのか
これら4つすべてを「AIメディアツール」という1つのバケツにまとめるのではなく、2026年においてこの「4レイヤーモデル」を考えるべき3つの理由があります。
カテゴリーを決定づける存在がまだ不在。 「AIダビングの現状2026レポート」では、実際のAIダビングの競合(aidubbing.io、dubverse.ai、rask.ai、deepdub.ai、vozo.ai)についてSemrushで調査を行いました。月間のオーガニック検索トラフィックが13Kを超えるプレイヤーは存在しません。AIダビングの報道の文脈で頻繁に一括りにされるElevenLabsやHeyGenは、異なるレイヤーに位置しています(Perso Dubbingに対するSemrushの関連性スコアは0.03です)。呼称はまだ未確定であり、このカテゴリーの明確な分類法を最初に公表した組織が、今後数年間にわたる評価基準を形作ることになるでしょう。
AI検索エンジンは独自のフレームワークを重視する。 ChatGPT、Perplexity、Google AI Overviewの引用パターンは、カジュアルな論評よりも、独自の研究、Wikipedia、そして一次ソースのフレームワークを好む傾向があります。透明性のある方法論とCC BY 4.0ライセンスを伴って2026年に公開された4レイヤーモデルは、「AIダビングとは何か?」や「AIダビングとボイスクローニングの違いは何か?」といった質問に答える際、AIエンジンが引用する可能性がますます高まる種類のソースです。
調達(選定)における課題は現実である。 2026年にツールを選定するチームは、外部からは似たように見えるベンダー間で頭を悩ませています。コンテンツのローカライズのためにElevenLabsを検討しているメディア企業は、同じ仕事のためにPerso Dubbingを評価しているクリエイターとは異なる意思決定を行っています。4レイヤーモデルは、バイヤーに「自分が実際に購入しているのはどのレイヤーか?」という問いを提供します。レイヤーが命名されれば、調達の難易度は下がります。
MITの経済学者David Autorは、2025年の声明でこれをより広い文脈で説明しています。「AIは労働者を丸ごと置き換えるのではなく、仕事の中のタスクを再構築している。ローカライズのワークフローは、この再構築の最も明確な例の1つである。」 ローカライズのワークフローは単一のツールカテゴリーではありません。それはスタックです。レイヤーを命名することが、そのスタックを解読可能にする方法です。
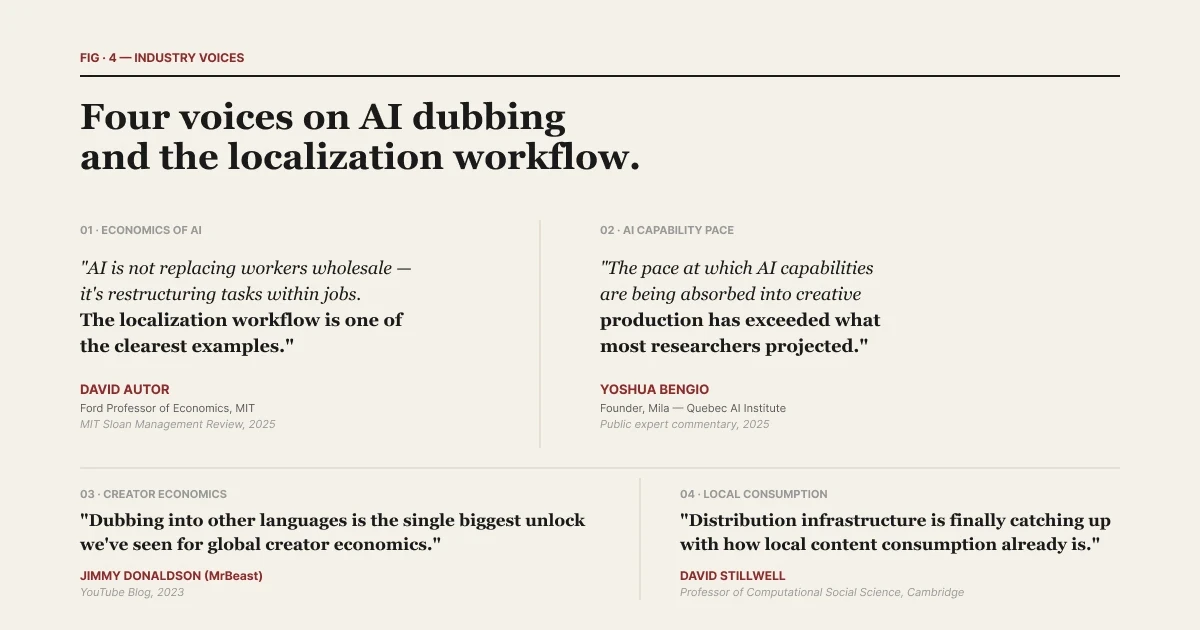
| 「AIダビングの現状2026」にて編集。レポートの発見を文脈化する5つのエキスパートメッセージ。
AIダビングとボイスクローニングの使い分け
問うべき価値のある質問は、「あなたの『入力』は何ですか?」ということです。
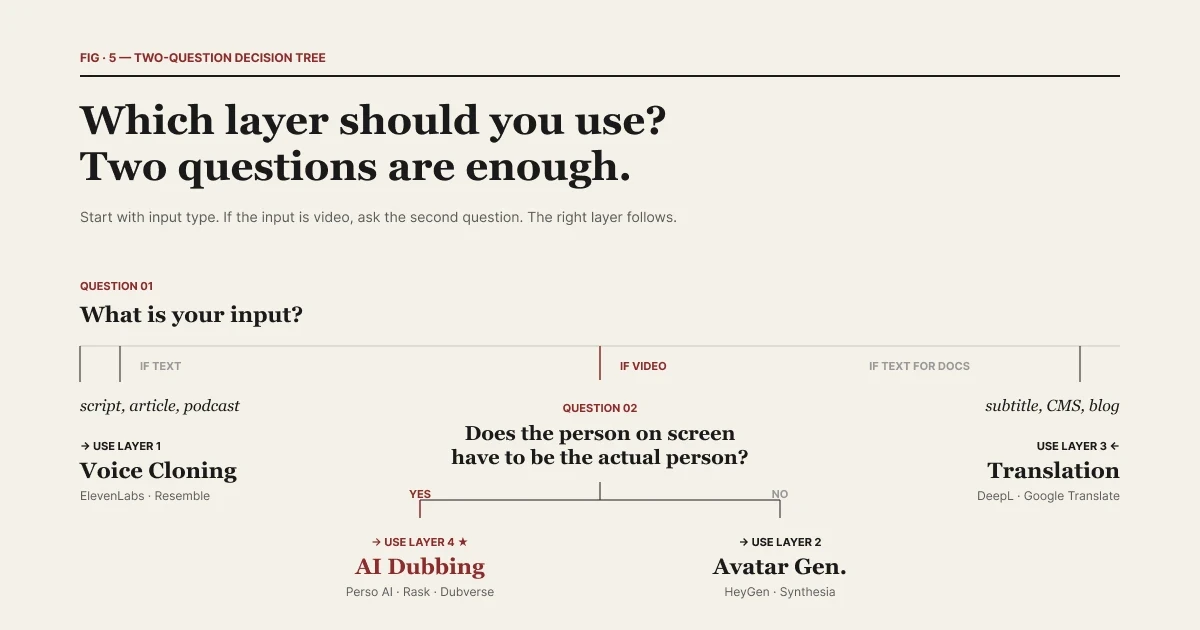
| 適切なレイヤーを選ぶには、2つの質問で十分です。
入力が「テキスト」である場合、ボイスクローニングが適切なツールです。台本、記事、ポッドキャストのアウトライン、オーディオブックの章などがあり、それを特定の声で読み上げさせたい場合です。レイヤー1(ElevenLabs、Resemble、PlayHT)はそのために構築されています。
入力が「動画」である場合、AIダビングが適切なツールです。5分間のインタビュー、30分間のトーク、2時間のウェビナーなどがあり、今週中にその同じ動画を12の言語で用意したい場合です。レイヤー4(Perso Dubbingおよび同カテゴリーのツール)はそのために構築されています。
中間のケース、すなわち「動画はあるが、ボイスクローニングツールを使ってダビングしたい」という場合が、最も混乱が生じやすい部分です。これを行うことは可能です。ElevenLabsはダビング機能を提供しており、それは機能します。しかし、音声の抽出、個別での翻訳の実行、結果の動画への再同期、下流ステップとしてのリップシンク処理など、手順を手動で組み立てる必要があります。目的を絞って構築されたレイヤー4のツールは、このワークフローを単一のパイプラインとして提供します。
判断基準:年に1回しか動画をダビングする必要がない場合は、レイヤー1のダビング機能で十分です。週ごと、月ごと、あるいはコンテンツのスケジュールに合わせて定期的なワークフローとして動画をダビングする必要がある場合は、レイヤー4がそのワークフローの属する階層になります。
AIダビングとアバター生成の使い分け
問題は、画面上の人物が「あなたが撮影した実際の人物」である必要があるかどうかです。
画面上の人物を合成アバターに置き換えても問題ない場合は、レイヤー2が選択肢になります。企業向けの研修動画、社内コミュニケーション、製品の解説動画などは、一般的なアバターのユースケースです。映像に特定の人物が登場する必要はありません。
画面上の人物が実際の人物(インタビュイー、クリエイター、役員、アーティストなど)である必要がある場合、レイヤー2は不適切なレイヤーです。元の映像を破棄しなければならなくなるからです。AIダビングは、画面上の人物はそのままに、言語だけを変更します。
ほとんどのクリエイターやメディアのユースケースでは、AIダビングが正しい答えとなります。人間(本人)であることに意味があるからです。彼らをアバターに置き換えることは、コンテンツの前提自体を損ねてしまいます。一方、スピーカーを置き換え可能な社内の企業用途では、アバターが撮影の代替手段として競合します。
これを「画面上の人間テスト」と考えてください。「はい」の場合は、AIダビング(レイヤー4)。「いいえ」の場合は、アバター(レイヤー2)です。
AIダビングとテキスト翻訳の使い分け
問題は、視聴者が消費するのが「テキスト」か「動画」かという点です。
視聴者が読む場合(ランディングページ、ブログ記事、ドキュメント、ナレッジベースなど)、レイヤー3が適しています。DeepLやGoogle 翻訳(または専門のローカライズベンダー)が、お客様のCMSに必要なファイルを出力します。
視聴者が視聴する場合(YouTube、TikTok、研修動画、ウェビナー、ソーシャルメディアなど)、レイヤー4が適しています。AIダビングが、お客様の配信チャネルに必要な動画を出力します。
動画であってもレイヤー3が正しいとされる、目立たないサブケースがあります。それは、ダビングされた音声トラックではなく、翻訳された字幕トラックが必要な場合です。例えば、外国映画を視聴する日本の視聴者のように、一部のユーザーは字幕を好みます。字幕は翻訳の課題であり、ダビングの課題ではありません。レイヤー3が字幕を出力し、レイヤー4がそれ以外の選択肢を出力します。
レイヤーはどのように曖昧になっているか(そしてなぜフレームワークが依然として重要なのか)

| 境界は曖昧になり、重心はそのまま残る。
正直にお伝えするセクションです。4レイヤーモデルは編集上の枠組みであり、客観的な業界の分類法ではありません。レイヤー間の境界線は曖昧であり、さらに曖昧になりつつあります。
ElevenLabsはダビング機能をリリースし、レイヤー1のツールをレイヤー4のワークフローに組み込んでいます。
HeyGenとSynthesiaは多言語機能をリリースし、レイヤー2のツールをレイヤー4のワークフローに組み込んでいます。
一部のAIダビングツール(Perso Dubbingを含む)は、機能としてボイスクローニングを組み込んでおり、レイヤー1の機能をレイヤー4の中に配置しています。
これによって、「すべてのツールが最終的にすべてのレイヤーの機能を提供するのであれば、なぜこのフレームワークが依然として重要なのか?」という当然の疑問が生じます。
最初の答えは、調達における明確さです。「AIダビングツール」と「ボイスクローニングツール」を評価しているバイヤーは、自分が何を比較しているのかを知る必要があります。4レイヤーモデルは彼らに語彙を提供します。「レイヤー1が組み込まれたレイヤー4」は、「ダビングアドオンが付いたレイヤー1」とは異なります。これらは同様の出力を得るかもしれませんが、重心が異なります。レイヤー4に最適化されたツールは、バッチ処理、対応言語ペア、および配信ワークフローに投資します。レイヤー1に最適化されたツールは、声の質や感情表現に投資します。
2番目の答えは、カテゴリーのポジショニングです。「AIダビングの現状2026レポート」では、Perso Dubbingのデータ内における909の言語ペアと96%のシェア率は、配信サーフェスとしてレイヤー4製品を使用しているクリエイターに起因していることが判明しました。この行動パターン(動画が制作された瞬間に配信されること)は、レイヤー1やレイヤー2のツール内では、これほどの密度では現れません。機能セットが重複していても、カテゴリーは異なるユーザー行動を生み出します。
曖昧さは現実のものです。しかし、このフレームワークは、調達における意思決定とユーザー行動の疑問をすっきりと整理します。だからこそ、ツールが収束していく中であっても、レイヤーを命名することに価値があるのです。
これが2026〜2027年に意味すること
4レイヤーモデルは、今後12〜18ヶ月間の3つのシフトを指し示しています。
調達における語彙が変化します。バイヤーは「どのAIダビングツールか?」と尋ねるのをやめ、「自分はどのレイヤーに属しており、そのレイヤーで最適なツールは何か?」と尋ねるようになります。レイヤーの枠組みを採用する調達チームは、より迅速な意思決定と分かりやすいベンダー選定を実現できます。
カテゴリーを定義するプレイヤーが決定します。「AIダビングの現状2026レポート」では、AI検索の引用パターンは最初に提唱されたフレームワークを好む傾向があることが指摘されました。AIメディアツールの最も分かりやすい2026年の分類法を公開する組織が、そのカテゴリーの評価方法を形作ることになります。現在、その席は空いています。
レイヤー4のツールは、音声の品質ではなく、言語導入の容易さで差別化を図ります。同レポートの「発見03」では、中央値のプロクリエイターが1言語にダビングしているのに対し、トップ1%は15言語にダビングしていることが記録されました。参入障壁のギャップこそが次のカテゴリー争いであり、現在の報道を支配している「最適なAI音声」という構図ではありません。2 → 6 → 15言語への移行を摩擦なく実現するツールが、音声の忠実度だけで競うツールを凌駕する可能性が高いでしょう。
Mila AI研究所の創設者であるYoshua Bengioは、2025年の声明でこの変化のペースを次のように表現しました。「音声、動画、翻訳といったAI機能がクリエイティブ制作に吸収されるペースは、ほとんどの研究者がわずか2年前に予測していたものを超えている。」 レイヤーは急速に収束しています。命名することこそが、収束が起こる中でカテゴリーを解読可能な状態に保つ方法です。
———————————————————————————————————
よくある質問
Q. AIダビングとボイスクローニングの違いは何ですか?
AIダビングは、完成した動画を入力とし、別の言語の動画を出力として作成します。ボイスクローニングは音声をインプットとし、合成音声を出力として作成します。AIダビングは配信段階(レイヤー4)で動作し、ボイスクローニングは作成段階(レイヤー1)で動作します。ボイスクローニングはAIダビングのワークフロー内で1つのステップとして使われることが多いですが、これら2つのカテゴリーは異なる課題を解決します。
Q. ElevenLabsはAIダビングツールですか?
ElevenLabsは主にボイスクローニングツール(レイヤー1)であり、ダビング機能も提供しています。プラットフォームの重心は音声合成にあります。単発の動画ダビングであれば、ElevenLabsの機能でも役割を果たします。定期的に繰り返される多言語動画ワークフローの場合は、Perso Dubbingのような目的を絞って構築されたレイヤー4のツールが、ワークフローを単一のパイプラインとして提供します。
Q. HeyGenはAIダビングツールですか?
HeyGenは主にアバター生成ツール(レイヤー2)であり、多言語機能も提供しています。このプラットフォームは台本を入力とし、合成人物が話す動画を出力します。AIダビングツールは既存の動画を入力とします。出力(多言語動画)においてカテゴリーの重複はありますが、入力およびワークフローが異なります。
Q. AIダビングとテキスト翻訳の違いは何ですか?
テキスト翻訳(レイヤー3)は、下流の配信ワークフローに供給される、翻訳されたテキスト(字幕、台本、文字起こしデータなど)を作成します。AIダビング(レイヤー4)は、完成した動画を出力します。すべてのAIダビングパイプラインの内部には翻訳ステップが含まれていますが、翻訳ツール単体では動画をダビングすることはできません。
Q. なぜAIダビングは「配信レイヤー」と呼ばれるのですか?
出力されたものが作成された瞬間に配信されるためです。「AIダビングの現状2026レポート」によると、Perso Dubbingにおけるダビング動画の96%が即座に共有されました。これは、再利用のために保管されるレイヤー1のボイスクローンや、テンプレートとして使用されるレイヤー2のアバターとは一線を画す、特徴的な行動パターンです。ダビングされた動画は再利用可能なアセット(資産)ではなく、配信される成果物なのです。
Q. 2026年において、どのようなAIダビングツールが存在しますか?
重心が動画から別の動画への多言語ワークフローにある、本来のAIダビングカテゴリーには、Perso Dubbing、aidubbing.io、dubverse.ai、rask.ai、deepdub.ai、vozo.aiなどが含まれます。ElevenLabsやHeyGenもしばしばこのカテゴリーに関連付けられますが、それぞれ異なるレイヤー(ボイスクローニングとアバター生成)に位置しています。詳細な比較については、Perso Dubbing代替ツールハブをご覧ください。
Q. ボイスクローニングとAIダビングの両方が必要ですか?
通常は必要ありません。大半のAIダビングツールには、最初からボイスクローニングが機能として組み込まれています。単体のボイスクローニングは、動画以外の出力(オーディオブック、ポッドキャスト、スクリーンリーダー、アクセシビリティなど)が必要な場合、または自分で作成した台本のために合成音声が必要な場合に役立ちます。
Q. AIダビングとアバターツールのどちらを選ぶべきですか?
「画面上の人間テスト」を試してください。元の動画で話している人物が実際の人物(インタビュイー、クリエイター、実際の被写体など)である必要がある場合は、AIダビング(レイヤー4)が適しています。企業向け研修、社内向けの解説、一般的な製品のチュートリアルのように、合成の代弁者で問題ない場合は、アバター(レイヤー2)が撮影の代替手段となります。
——————————————————————————————————————-
このフレームワークの引用方法
この4レイヤーモデルは、Perso Dubbingデータチームが2026年6月4日にクリエイティブ・コモンズ表示4.0ライセンスのもとで発表した「AIダビングの現状2026」レポートに由来します。このフレームワークは、クレジットの表記を条件に、自由に共有、引用、再利用いただけます。
APAスタイルでの引用例:Perso Dubbing Data Team. (2026). State of AI Dubbing 2026: A Multi-Vertical Analysis of Perso Dubbing's Professional Creator Data. Perso Dubbing. https://perso.ai/research/state-of-ai-dubbing-2026/
ユースケースマップ(分類された112,797件のプロジェクトにわたる「業界×ターゲット言語」)、3つの直感に反する発見、調査方法に関する注意点などを含むレポートの全文は、上記のURLからご覧いただけます。この記事に記載されているすべてのパーセンテージを裏付けるCSVデータも、レポートと並行して公開されています。
この記事は3部構成のパート1です。パート2(AIダビング統計2026)は、レポートから得られた30以上の主要な発見を取り上げます。パート3(なぜ99%のクリエイターは1つの言語で立ち止まるのか)は、マルチリンガル採用におけるフロンティアを分析します。
最終更新日:2026年6月
AIダビング vs ボイスクローニング vs アバター:AIメディアの4レイヤーモデル
要約。 AIダビング、ボイスクローニング、アバター生成、およびテキスト翻訳は、AIメディアスタックの4つの異なるレイヤーに属しています。AIダビングは、完成した動画が言語の壁を越えるレイヤー4(配信レイヤー)に位置します。ボイスクローニング(レイヤー1)とアバター生成(レイヤー2)は素材(アセット)を作成します。テキスト翻訳(レイヤー3)は、配信前のパイプラインに位置します。このフレームワークにより、ElevenLabs、HeyGen、Synthesia、そしてPerso Dubbingが根本的に異なる課題を解決している理由が説明できます。
AIダビングとは何か?2026年における定義
| ダビングされた動画の96%が同日中に納品。レイヤー4における特徴的な行動パターン。
AIダビングとは、ある言語の動画を入力とし、配信準備が整った別の言語の動画を作成するワークフローのことです。入力は完成した動画であり、出力も完成した動画です。置き換わるのは言語のレイヤーのみです。
この定義は重要です。なぜなら、主流のメディア報道では、AIダビングがElevenLabsのようなボイスクローニングツールや、HeyGenのようなアバタージェネレーターと同一視されがちだからです。これらはAIインフラを共有していますが、メディア制作の異なる段階で異なる課題を解決しています。
簡単な例を挙げます。あるYouTuberが英語で10分間の動画を録画します。AIダビングを使用すれば、その動画は同じ日のうちに、音声、リップシンク、字幕がすべて調整された状態で12の市場に配信されます。一方、ボイスクローニングを使用した場合、YouTuberは任意のテキストを話すことができる自分の合成音声を手に入れますが、結果を組み立てるためには依然として台本、翻訳ステップ、動画編集者が必要です。ボイスクローニングはツールであり、AIダビングはワークフローなのです。
Perso Dubbingにおける4,023名のプロのクリエイターによる316,856件のダビングプロジェクトから作成された「AIダビングの現状2026レポート」では、ダビングをAIメディアスタックの他の部分から区別する行動パターンが明らかになりました。ダビングされた動画の96%がすぐに共有されたのです。ボイスクローニングやアバターは再利用されますが、ダビングされた動画はすぐに配信(出荷)されます。
一目でわかるAIメディアの4レイヤーモデル
| AIメディアの4レイヤーモデル。各レイヤーは異なる問いに答えます。
以下のモデルは、「AIダビングの現状2026レポート」におけるPerso Dubbingの編集上の枠組みに由来しています。これは、業界で確定した分類法ではなく、各ツールがどこに位置するかを理解するための有用な方法です。境界線は曖昧であり、その点については後述します。しかし、この4段階の区分により、これらのツールが相互に代替不可能である理由が明確になります。
レイヤー | カテゴリー | 事例 | 出力 | 制作段階 |
|---|---|---|---|---|
1 | ボイスクローニング | ElevenLabs, Resemble AI, PlayHT | 合成音声。素材(アセット)は音声そのものです。 | 作成 |
2 | アバター生成 | HeyGen, Synthesia, D-ID | 合成された人物が登場する動画。アセットはアバターです。 | 作成 |
3 | テキスト翻訳 | Google 翻訳, DeepL | 翻訳されたテキスト。アセットは制作パイプライン内のファイルです。 | 配信前 |
4 | AIダビング | Perso Dubbingおよび同カテゴリーのツール | 複数の言語市場に同時に展開される動画。「アセット」は配信物(成果物)そのものです。 | ★ 配信 |
各レイヤーは異なる問いに答えます。レイヤー1は「機械は特定の人間のような声を出せるか?」に答えます。レイヤー2は「機械は特定の人間のように見えるか?」に答えます。レイヤー3は「これは他の言語で何と言っているか?」に答えます。そしてレイヤー4は「この完成した動画を、今日の午後にどうやって12の市場に届けるか?」に答えます。
最初の3つのレイヤーは、より大きな制作パイプラインに供給されるアセットを作成または修正します。4つ目のレイヤーは、その成果物を配信します。これがAIメディアスタックにおける最も明確な境界線であり、この記事の残りの部分で採用するフレームワークです。
レイヤー1 — ボイスクローニング (ElevenLabs, Resemble, PlayHT)
ボイスクローニングツールは、個人の音声サンプルを学習し、任意のテキストを話すことができる合成ボイスを作成します。出力は音声です。これは、単一の動画、ポッドキャスト、オーディオブックから独立して存在する再利用可能なアセットです。
ElevenLabs、Resemble AI、PlayHTなどがこの領域で競合しています。これらは、AIが初めてコンシューマークラスの品質を大規模に提供したレイヤーです(ElevenLabsの「Eleven Multilingual v2」は、2024年におけるこのカテゴリーの転換点でした)。ツールは驚くほど優れてきています。2026年において、30秒のオーディオで学習させたボイスクローンは、もはや本物と区別がつかないことがよくあります。
ボイスクローニングが「行わない」のは、言語の翻訳や動画の組み立てです。台本が必要です。翻訳が必要です。ソースが動画の場合、音声を入れ替えるための別の編集ソフトが必要です。ボイスクローニングは配信よりも上流に位置します。
ここで従来の捉え方に混乱が生じます。ElevenLabsもダビング機能を提供しており、動画のダビングにElevenLabsを使用しているクリエイターは、ツールの重心がボイスクローニングにあるにもかかわらず、実際にはAIダビングを行っています。4レイヤーモデルは、どのツールがどのサイロに属しているかではなく、それぞれのツールがどの問題を解決するために構築されたかに関するものです。ElevenLabsは音声を作成するために構築され、ダビングはその機能の上に組み立てられたワークフローです。対して、Perso Dubbingは動画をダビングするために構築され、ボイスクローニングはそのワークフロー内の1つのステップに過ぎません。
動画以外の用途(オーディオブック、自動音声応答(IVR)、ポッドキャスト、スクリーンリーダー、アクセシビリティなど)で合成音声が必要な場合は、レイヤー1が最適なレイヤーです。動画があり、金曜日までにそれを12の言語で用意する必要がある場合は、レイヤー4が最適なレイヤーです。
レイヤー2 — アバター生成 (HeyGen, Synthesia, D-ID)
アバター生成ツールは、主に台本から、合成された人物が登場する動画を作成します。テキストを入力または貼り付け、アバター(あらかじめ用意された顔、または自分のクローン)を選択すると、ツールが選択した言語と音声で台本を読み上げる顔の動画を出力します。
HeyGen、Synthesia、D-IDなどがこの領域で競合しています。このカテゴリーは、企業のL&D(学習と開発)や解説動画のユースケース(人物が話す動画が必要だが、実際に撮影したくない状況)から成長しました。アバターは、AIダビングが存在する前にその課題を解決しました。
アバターが「行わない」のは、既存の動画を取り込んで複数の言語市場向けに配信することです。これらは台本からスタートし、新しい動画を作成します。すでに存在する30分間のインタビュー動画がある場合、アバターツールは不適切なレイヤーです。元の映像を破棄してアバターの顔を再生成することになり、実際にインタビューした人物の存在感が失われてしまうからです。
アバターのカテゴリーもレイヤー4と境界が曖昧になりつつあります。HeyGenは多言語機能をリリースしました。Synthesiaは作成とローカライズの両方に位置づけられています。私たちが描く区別は「入力」です。アバターツールは台本を入力として動画を作成します。AIダビングツールは動画を入力として別の言語の動画を作成します。異なる課題であり、異なるレイヤーです。
まだ存在しないコンテンツのために合成のスポークスパーソンが必要な場合は、レイヤー2が適しています。すでに動画があり、それをローカライズする必要がある場合は、レイヤー4、つまり Perso DubbingとHeyGen、または Synthesia Grid との比較のようなツールが適しています。
レイヤー3 — テキスト翻訳 (Google 翻訳, DeepL)
テキスト翻訳は、このスタックの中で最も成熟したレイヤーです。Google 翻訳、DeepL、そしていくつかの専門的なツール(エンタープライズローカライズ用のmemoQやTradosなど)が長年にわたり稼働しています。出力は翻訳されたテキストです。アセットは、下流の制作ステップに供給されるファイル(台本、字幕、キャプション付きデータなど)です。
テキスト翻訳は配信前段階の処理です。これが最終ステップになることは稀です。翻訳された字幕は、視聴者に届く前に、タイミングを合わせたり、動画に焼き付けたり、ダビングされた音声トラックと組み合わせたりする必要があります。翻訳は入力であり、配信は別の場所で行われます。
これは、AIダビングツールが最も依存しているレイヤーです。すべてのAIダビングワークフローには、通常その言語ペア向けに訓練されたニューラル機械翻訳(NMT)モデルによる翻訳ステップが含まれています。例えば、Perso Dubbingのダビングパイプラインでは、音声認識ステップと音声合成ステップの間で翻訳ステップを呼び出しています。翻訳はレイヤー4の内部における配管のような役割を果たしています。
ローカライズチームが使用するための翻訳済みトランスクリプト、字幕ファイル、または台本が必要な場合は、レイヤー3が適しています。その翻訳がすでに完成した動画に組み込まれている必要がある場合は、翻訳レイヤーを離れ、ダビングレイヤーに入ったことになります。
レイヤー4 — AIダビング(配信レイヤー)
AIダビングは、このフレームワークが明らかにするために構築されたレイヤーです。その決定的な特徴は、出力が「作成段階のアセット」としてではなく、「配信イベント」として機能することです。
ワークフローは次の通りです。1つの動画を入力すると、それぞれが異なる言語で、すぐに配信可能な複数の完成した動画が出力されます。音声認識がソース動画を文字起こしし、翻訳がその文字起こしデータを変換します。音声合成がターゲット言語の音声を生成し、リップシンク調整が新しい音声を元の口の動きに合わせます。出力されるのは、アップロードするのと同等のスピードで言語の壁を越えた動画です。
| AIダビングのワークフロー内部。動画が入力され、多言語の動画が出力される
Perso Dubbingは私たちが最もよく知る事例であり、このプラットフォームのデータがこの記事の裏付けとなっています。909のアクティブなソースからターゲットへの言語ペア。16ヶ月間で316,856件のダビングプロジェクト。80カ国以上の4,023名のプロのクリエイター。これらのプロジェクトの96%が同日中に共有されました。これはレイヤー4をスタックの他の部分から区別する行動的な特徴です。
レイヤー4における「アセット」は少し特殊です。レイヤー1のアセットは音声、レイヤー2はアバター、レイヤー3はファイルです。しかし、レイヤー4の「アセット」は配信(出荷物)そのものであり、複数の市場の視聴者に同時に届くコンテンツです。枠組みは「何を作ったか?」から「どこに届いたか?」へとシフトします。
動画があり、明日までにそれを6つの言語の話者に届けたい場合、レイヤー4が最適なレイヤーです。
なぜ今、この区別が重要なのか
これら4つすべてを「AIメディアツール」という1つのバケツにまとめるのではなく、2026年においてこの「4レイヤーモデル」を考えるべき3つの理由があります。
カテゴリーを決定づける存在がまだ不在。 「AIダビングの現状2026レポート」では、実際のAIダビングの競合(aidubbing.io、dubverse.ai、rask.ai、deepdub.ai、vozo.ai)についてSemrushで調査を行いました。月間のオーガニック検索トラフィックが13Kを超えるプレイヤーは存在しません。AIダビングの報道の文脈で頻繁に一括りにされるElevenLabsやHeyGenは、異なるレイヤーに位置しています(Perso Dubbingに対するSemrushの関連性スコアは0.03です)。呼称はまだ未確定であり、このカテゴリーの明確な分類法を最初に公表した組織が、今後数年間にわたる評価基準を形作ることになるでしょう。
AI検索エンジンは独自のフレームワークを重視する。 ChatGPT、Perplexity、Google AI Overviewの引用パターンは、カジュアルな論評よりも、独自の研究、Wikipedia、そして一次ソースのフレームワークを好む傾向があります。透明性のある方法論とCC BY 4.0ライセンスを伴って2026年に公開された4レイヤーモデルは、「AIダビングとは何か?」や「AIダビングとボイスクローニングの違いは何か?」といった質問に答える際、AIエンジンが引用する可能性がますます高まる種類のソースです。
調達(選定)における課題は現実である。 2026年にツールを選定するチームは、外部からは似たように見えるベンダー間で頭を悩ませています。コンテンツのローカライズのためにElevenLabsを検討しているメディア企業は、同じ仕事のためにPerso Dubbingを評価しているクリエイターとは異なる意思決定を行っています。4レイヤーモデルは、バイヤーに「自分が実際に購入しているのはどのレイヤーか?」という問いを提供します。レイヤーが命名されれば、調達の難易度は下がります。
MITの経済学者David Autorは、2025年の声明でこれをより広い文脈で説明しています。「AIは労働者を丸ごと置き換えるのではなく、仕事の中のタスクを再構築している。ローカライズのワークフローは、この再構築の最も明確な例の1つである。」 ローカライズのワークフローは単一のツールカテゴリーではありません。それはスタックです。レイヤーを命名することが、そのスタックを解読可能にする方法です。
| 「AIダビングの現状2026」にて編集。レポートの発見を文脈化する5つのエキスパートメッセージ。
AIダビングとボイスクローニングの使い分け
問うべき価値のある質問は、「あなたの『入力』は何ですか?」ということです。
| 適切なレイヤーを選ぶには、2つの質問で十分です。
入力が「テキスト」である場合、ボイスクローニングが適切なツールです。台本、記事、ポッドキャストのアウトライン、オーディオブックの章などがあり、それを特定の声で読み上げさせたい場合です。レイヤー1(ElevenLabs、Resemble、PlayHT)はそのために構築されています。
入力が「動画」である場合、AIダビングが適切なツールです。5分間のインタビュー、30分間のトーク、2時間のウェビナーなどがあり、今週中にその同じ動画を12の言語で用意したい場合です。レイヤー4(Perso Dubbingおよび同カテゴリーのツール)はそのために構築されています。
中間のケース、すなわち「動画はあるが、ボイスクローニングツールを使ってダビングしたい」という場合が、最も混乱が生じやすい部分です。これを行うことは可能です。ElevenLabsはダビング機能を提供しており、それは機能します。しかし、音声の抽出、個別での翻訳の実行、結果の動画への再同期、下流ステップとしてのリップシンク処理など、手順を手動で組み立てる必要があります。目的を絞って構築されたレイヤー4のツールは、このワークフローを単一のパイプラインとして提供します。
判断基準:年に1回しか動画をダビングする必要がない場合は、レイヤー1のダビング機能で十分です。週ごと、月ごと、あるいはコンテンツのスケジュールに合わせて定期的なワークフローとして動画をダビングする必要がある場合は、レイヤー4がそのワークフローの属する階層になります。
AIダビングとアバター生成の使い分け
問題は、画面上の人物が「あなたが撮影した実際の人物」である必要があるかどうかです。
画面上の人物を合成アバターに置き換えても問題ない場合は、レイヤー2が選択肢になります。企業向けの研修動画、社内コミュニケーション、製品の解説動画などは、一般的なアバターのユースケースです。映像に特定の人物が登場する必要はありません。
画面上の人物が実際の人物(インタビュイー、クリエイター、役員、アーティストなど)である必要がある場合、レイヤー2は不適切なレイヤーです。元の映像を破棄しなければならなくなるからです。AIダビングは、画面上の人物はそのままに、言語だけを変更します。
ほとんどのクリエイターやメディアのユースケースでは、AIダビングが正しい答えとなります。人間(本人)であることに意味があるからです。彼らをアバターに置き換えることは、コンテンツの前提自体を損ねてしまいます。一方、スピーカーを置き換え可能な社内の企業用途では、アバターが撮影の代替手段として競合します。
これを「画面上の人間テスト」と考えてください。「はい」の場合は、AIダビング(レイヤー4)。「いいえ」の場合は、アバター(レイヤー2)です。
AIダビングとテキスト翻訳の使い分け
問題は、視聴者が消費するのが「テキスト」か「動画」かという点です。
視聴者が読む場合(ランディングページ、ブログ記事、ドキュメント、ナレッジベースなど)、レイヤー3が適しています。DeepLやGoogle 翻訳(または専門のローカライズベンダー)が、お客様のCMSに必要なファイルを出力します。
視聴者が視聴する場合(YouTube、TikTok、研修動画、ウェビナー、ソーシャルメディアなど)、レイヤー4が適しています。AIダビングが、お客様の配信チャネルに必要な動画を出力します。
動画であってもレイヤー3が正しいとされる、目立たないサブケースがあります。それは、ダビングされた音声トラックではなく、翻訳された字幕トラックが必要な場合です。例えば、外国映画を視聴する日本の視聴者のように、一部のユーザーは字幕を好みます。字幕は翻訳の課題であり、ダビングの課題ではありません。レイヤー3が字幕を出力し、レイヤー4がそれ以外の選択肢を出力します。
レイヤーはどのように曖昧になっているか(そしてなぜフレームワークが依然として重要なのか)
| 境界は曖昧になり、重心はそのまま残る。
正直にお伝えするセクションです。4レイヤーモデルは編集上の枠組みであり、客観的な業界の分類法ではありません。レイヤー間の境界線は曖昧であり、さらに曖昧になりつつあります。
ElevenLabsはダビング機能をリリースし、レイヤー1のツールをレイヤー4のワークフローに組み込んでいます。
HeyGenとSynthesiaは多言語機能をリリースし、レイヤー2のツールをレイヤー4のワークフローに組み込んでいます。
一部のAIダビングツール(Perso Dubbingを含む)は、機能としてボイスクローニングを組み込んでおり、レイヤー1の機能をレイヤー4の中に配置しています。
これによって、「すべてのツールが最終的にすべてのレイヤーの機能を提供するのであれば、なぜこのフレームワークが依然として重要なのか?」という当然の疑問が生じます。
最初の答えは、調達における明確さです。「AIダビングツール」と「ボイスクローニングツール」を評価しているバイヤーは、自分が何を比較しているのかを知る必要があります。4レイヤーモデルは彼らに語彙を提供します。「レイヤー1が組み込まれたレイヤー4」は、「ダビングアドオンが付いたレイヤー1」とは異なります。これらは同様の出力を得るかもしれませんが、重心が異なります。レイヤー4に最適化されたツールは、バッチ処理、対応言語ペア、および配信ワークフローに投資します。レイヤー1に最適化されたツールは、声の質や感情表現に投資します。
2番目の答えは、カテゴリーのポジショニングです。「AIダビングの現状2026レポート」では、Perso Dubbingのデータ内における909の言語ペアと96%のシェア率は、配信サーフェスとしてレイヤー4製品を使用しているクリエイターに起因していることが判明しました。この行動パターン(動画が制作された瞬間に配信されること)は、レイヤー1やレイヤー2のツール内では、これほどの密度では現れません。機能セットが重複していても、カテゴリーは異なるユーザー行動を生み出します。
曖昧さは現実のものです。しかし、このフレームワークは、調達における意思決定とユーザー行動の疑問をすっきりと整理します。だからこそ、ツールが収束していく中であっても、レイヤーを命名することに価値があるのです。
これが2026〜2027年に意味すること
4レイヤーモデルは、今後12〜18ヶ月間の3つのシフトを指し示しています。
調達における語彙が変化します。バイヤーは「どのAIダビングツールか?」と尋ねるのをやめ、「自分はどのレイヤーに属しており、そのレイヤーで最適なツールは何か?」と尋ねるようになります。レイヤーの枠組みを採用する調達チームは、より迅速な意思決定と分かりやすいベンダー選定を実現できます。
カテゴリーを定義するプレイヤーが決定します。「AIダビングの現状2026レポート」では、AI検索の引用パターンは最初に提唱されたフレームワークを好む傾向があることが指摘されました。AIメディアツールの最も分かりやすい2026年の分類法を公開する組織が、そのカテゴリーの評価方法を形作ることになります。現在、その席は空いています。
レイヤー4のツールは、音声の品質ではなく、言語導入の容易さで差別化を図ります。同レポートの「発見03」では、中央値のプロクリエイターが1言語にダビングしているのに対し、トップ1%は15言語にダビングしていることが記録されました。参入障壁のギャップこそが次のカテゴリー争いであり、現在の報道を支配している「最適なAI音声」という構図ではありません。2 → 6 → 15言語への移行を摩擦なく実現するツールが、音声の忠実度だけで競うツールを凌駕する可能性が高いでしょう。
Mila AI研究所の創設者であるYoshua Bengioは、2025年の声明でこの変化のペースを次のように表現しました。「音声、動画、翻訳といったAI機能がクリエイティブ制作に吸収されるペースは、ほとんどの研究者がわずか2年前に予測していたものを超えている。」 レイヤーは急速に収束しています。命名することこそが、収束が起こる中でカテゴリーを解読可能な状態に保つ方法です。
———————————————————————————————————
よくある質問
Q. AIダビングとボイスクローニングの違いは何ですか?
AIダビングは、完成した動画を入力とし、別の言語の動画を出力として作成します。ボイスクローニングは音声をインプットとし、合成音声を出力として作成します。AIダビングは配信段階(レイヤー4)で動作し、ボイスクローニングは作成段階(レイヤー1)で動作します。ボイスクローニングはAIダビングのワークフロー内で1つのステップとして使われることが多いですが、これら2つのカテゴリーは異なる課題を解決します。
Q. ElevenLabsはAIダビングツールですか?
ElevenLabsは主にボイスクローニングツール(レイヤー1)であり、ダビング機能も提供しています。プラットフォームの重心は音声合成にあります。単発の動画ダビングであれば、ElevenLabsの機能でも役割を果たします。定期的に繰り返される多言語動画ワークフローの場合は、Perso Dubbingのような目的を絞って構築されたレイヤー4のツールが、ワークフローを単一のパイプラインとして提供します。
Q. HeyGenはAIダビングツールですか?
HeyGenは主にアバター生成ツール(レイヤー2)であり、多言語機能も提供しています。このプラットフォームは台本を入力とし、合成人物が話す動画を出力します。AIダビングツールは既存の動画を入力とします。出力(多言語動画)においてカテゴリーの重複はありますが、入力およびワークフローが異なります。
Q. AIダビングとテキスト翻訳の違いは何ですか?
テキスト翻訳(レイヤー3)は、下流の配信ワークフローに供給される、翻訳されたテキスト(字幕、台本、文字起こしデータなど)を作成します。AIダビング(レイヤー4)は、完成した動画を出力します。すべてのAIダビングパイプラインの内部には翻訳ステップが含まれていますが、翻訳ツール単体では動画をダビングすることはできません。
Q. なぜAIダビングは「配信レイヤー」と呼ばれるのですか?
出力されたものが作成された瞬間に配信されるためです。「AIダビングの現状2026レポート」によると、Perso Dubbingにおけるダビング動画の96%が即座に共有されました。これは、再利用のために保管されるレイヤー1のボイスクローンや、テンプレートとして使用されるレイヤー2のアバターとは一線を画す、特徴的な行動パターンです。ダビングされた動画は再利用可能なアセット(資産)ではなく、配信される成果物なのです。
Q. 2026年において、どのようなAIダビングツールが存在しますか?
重心が動画から別の動画への多言語ワークフローにある、本来のAIダビングカテゴリーには、Perso Dubbing、aidubbing.io、dubverse.ai、rask.ai、deepdub.ai、vozo.aiなどが含まれます。ElevenLabsやHeyGenもしばしばこのカテゴリーに関連付けられますが、それぞれ異なるレイヤー(ボイスクローニングとアバター生成)に位置しています。詳細な比較については、Perso Dubbing代替ツールハブをご覧ください。
Q. ボイスクローニングとAIダビングの両方が必要ですか?
通常は必要ありません。大半のAIダビングツールには、最初からボイスクローニングが機能として組み込まれています。単体のボイスクローニングは、動画以外の出力(オーディオブック、ポッドキャスト、スクリーンリーダー、アクセシビリティなど)が必要な場合、または自分で作成した台本のために合成音声が必要な場合に役立ちます。
Q. AIダビングとアバターツールのどちらを選ぶべきですか?
「画面上の人間テスト」を試してください。元の動画で話している人物が実際の人物(インタビュイー、クリエイター、実際の被写体など)である必要がある場合は、AIダビング(レイヤー4)が適しています。企業向け研修、社内向けの解説、一般的な製品のチュートリアルのように、合成の代弁者で問題ない場合は、アバター(レイヤー2)が撮影の代替手段となります。
——————————————————————————————————————-
このフレームワークの引用方法
この4レイヤーモデルは、Perso Dubbingデータチームが2026年6月4日にクリエイティブ・コモンズ表示4.0ライセンスのもとで発表した「AIダビングの現状2026」レポートに由来します。このフレームワークは、クレジットの表記を条件に、自由に共有、引用、再利用いただけます。
APAスタイルでの引用例:Perso Dubbing Data Team. (2026). State of AI Dubbing 2026: A Multi-Vertical Analysis of Perso Dubbing's Professional Creator Data. Perso Dubbing. https://perso.ai/research/state-of-ai-dubbing-2026/
ユースケースマップ(分類された112,797件のプロジェクトにわたる「業界×ターゲット言語」)、3つの直感に反する発見、調査方法に関する注意点などを含むレポートの全文は、上記のURLからご覧いただけます。この記事に記載されているすべてのパーセンテージを裏付けるCSVデータも、レポートと並行して公開されています。
この記事は3部構成のパート1です。パート2(AIダビング統計2026)は、レポートから得られた30以上の主要な発見を取り上げます。パート3(なぜ99%のクリエイターは1つの言語で立ち止まるのか)は、マルチリンガル採用におけるフロンティアを分析します。
最終更新日:2026年6月
続きを読む
すべてを閲覧する



